




 本文分享了一支参赛队伍在电商风控赛事中的解决方案,包括赛题理解、数据理解、调优策略与工程实践。他们通过数据增广、特征筛选、算法优化(如DeepWRN网络)和工程优化(如推理前预热)提升模型性能,并讨论了模型解释和工程挑战。最终,他们在比赛中取得了亚军的成绩。
本文分享了一支参赛队伍在电商风控赛事中的解决方案,包括赛题理解、数据理解、调优策略与工程实践。他们通过数据增广、特征筛选、算法优化(如DeepWRN网络)和工程优化(如推理前预热)提升模型性能,并讨论了模型解释和工程挑战。最终,他们在比赛中取得了亚军的成绩。
Datawhale干货
作者:许汝超,广州大学,Datawhale成员
本次 Apache Flink 极客挑战赛暨 AAIG CUP——电商推荐“抱大腿”攻击识别 赛题以电商推荐反作弊为背景,要求选手在少样本、半监督、隐私保护的场景下搭建风控模型来实时预测用户点击商品的行为是否恶意,实现对恶意流量的实时识别。下面分享一下我们队伍对本次比赛的理解和详细方案。
代码开源地址:
https://github.com/rickyxume/TianChi_RecSys_AntiSpam
实践背景
1.1 思路简述
本赛题属于结构化数据二分类任务,虽然是风控竞赛,但思考方向不局限于欺诈检测或异常检测,还可以参考推荐系统里的CTR预估、交互序列建模和图建模等方向,可能会有更多启发。Apache Flink 极客挑战赛毕竟是个算法和工程并重的比赛,所涉及到的技术点也主要是在算法和工程两个方面。
算法上涉及数据增广、降噪、类别不平衡、半监督学习、增量训练、模型剪枝、压缩和加速等。
工程上涉及写 FlinkSQL 在线特征工程、Flink 性能调优、Ai Flow 工作流定义、Occlum 搭建TEE、Analytics Zoo Cluster Serving 分布式推理调用、模型pb文件冻结和 Docker 的使用等。
1.2 赛题理解
电商风控业务背景
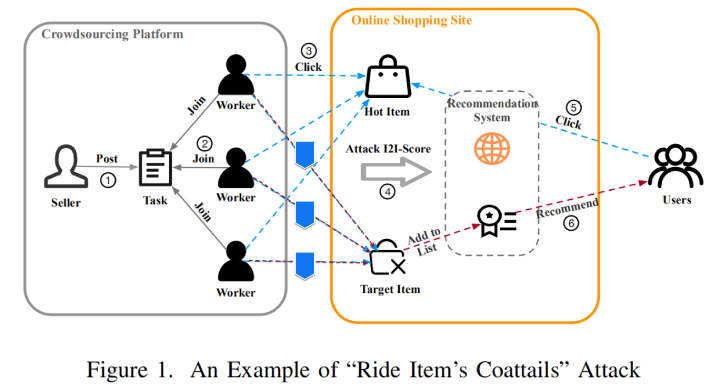
众所周知,电商平台会基于用户点击商品的行为来做个性化推荐,而一些不怀好意的商家可能想要推销自己的低质量商品,就在黑产市场买一个提高商品流量曝光的服务,具体操作就是雇佣一批黑产用户(可能是机器,也可能是肉鸡)去协同点击目标商品(即商家想要提升曝光度的商品)和爆款商品来提高电商平台推荐系统中两商品间的I2I关联分,用大白话来说就是“蹭流量”,通过这种方式干扰推荐系统来给恶意商家的商品更多曝光,极易误导消费者以爆款心理购买到劣质商品,影响平台治理,有损用户利益,所以需要风控系统去实时识别用户行为来过滤恶意流量。
恶意点击判定逻辑
理解打标签的逻辑对于理解赛题数据至关重要。
对于本赛题中的数据标签,仅当 user 和 item 满足均为恶意的条件,即恶意用户点击恶意商家的商品时,该点击行为才是恶意的,也就是图例中间三条红线才是恶意点击(label = 1),而其余情况,包括图中剩下的三条蓝线,都不算恶意点击(label = 0)。
评估指标及风控要求
本赛题对风控系统的安全和性能都有较高要求,需要在保证模型和数据安全的前提下,及时并准确地拦截恶意流量,实现实时风控。
环境要求:Occlum HW 模式(即在TEE下运行)
技术组件要求:必须使用 AI Flow 定义整个工作流,预测过程必须使用 Flink 作为实时计算引擎,其核心预测过程使用 Cluster Serving 完成。
时间限制:第一阶段训练推理时间不限,第二阶段训练推理限时15min,总时长不超过2h。
评估指标:,即两阶段F1得分与延迟符合要求(500ms以内)的数据占比的乘积之和
1.3 数据理解
数据描述
赛方提供匿名处理后的结构化数据,以供选手程序用于离线训练和在线推理,包含uuid、用户访问商品时间、用户id、商品id、商品及用户属性特征和标签,各字段描述如下:
| 字段 | 含义 |
|---|---|
| uuid | 数据集中唯一确认每条数据的id。 |
| visit_time | 该条行为数据的发生时间。实时预测过程中提供的数据的该值基本是单调递增的。 |
| user_id | 该条数据对应的用户的id |
| item_id | 该条数据对应的商品的id |
| features | 该数据的特征,复赛中,包含152个用空格分隔的浮点数。其中,第1 ~ 72个数字代表商品的特征,第73 ~ 152个数字代表用户的特征。 |
| label | 值为0、1或-1,1代表该数据为恶意行为数据,0为正常,-1则表示数据未标注。 |
数据量及业务场景模拟
为模拟实际业务中的模型迭代场景,工作流分为两个阶段。
第一阶段可以使用100w条数据,其中10w条有标签用于离线训练,5w条测试数据用于实时推理;
第二阶段可以使用第一阶段所有数据以及100w条新增数据,其中1w条有标签,5w条测试数据。
1.4 数据分析
特征相关性分析
首先,对给定的152维匿名的商品和用户的属性特征做拆分,其中商品特征为前72维,用户特征为后80维,分别对其按字母前缀和序号逐个命名,做特征相关性可视化分析。

可以发现,特征相关系数矩阵热力图中有很多深色方块,表明其存在多重共线性特征,特征冗余较多,商品特征热力图的颜色大体上更深,说明商品特征与行为标签更相关(侧面表明商品可以表征商家),而在用户特征中(观察右图中空白处)存在三列全部值都一样的无效特征(u77、u78、u79)。
数据分布差异分析
选取前面得到的与目标相关性较高的12个特征,分别绘制其在第一阶段的训练集、测试集和全部数据上的密度分布曲线,图中红色的曲线是测试集的,可以明显发现分布差异。
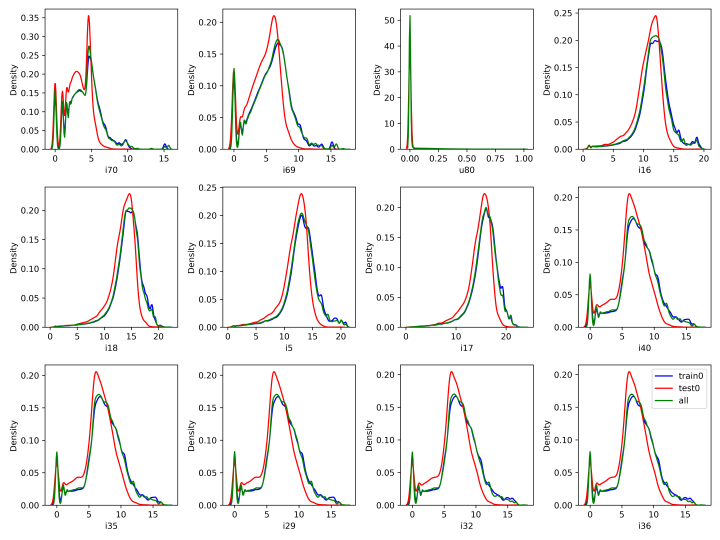 目标相关性top12特征在各集合上的数据密度分布曲线
目标相关性top12特征在各集合上的数据密度分布曲线
进一步地,我们简单使用 CatBoost 模型去区分训练集和测试集,在训练集和测试集中随机采样部分数据,逐个去除特征重要性高的特征,反复试验做对抗验证。
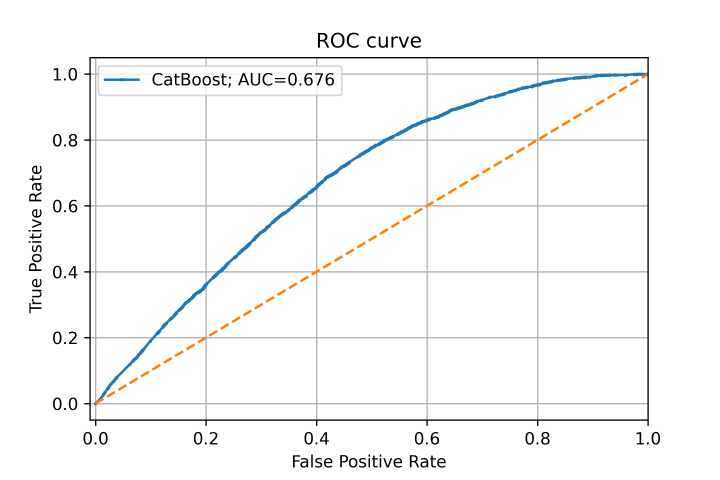 对抗验证模型ROC曲线与基线对比图
对抗验证模型ROC曲线与基线对比图
我们发现,逐个去除u80、i69、i70、i72、i5、i16、i71、i17、i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1608
1608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









