






 本文介绍了如何将Hive的执行引擎从MR切换到Tez,详细讲解了版本匹配、HDFS上的jar包部署、配置文件修改等步骤,并通过测试数据表明,Tez在处理大规模数据时比MR更具优势。
本文介绍了如何将Hive的执行引擎从MR切换到Tez,详细讲解了版本匹配、HDFS上的jar包部署、配置文件修改等步骤,并通过测试数据表明,Tez在处理大规模数据时比MR更具优势。
参考
http://tez.apache.org/install.html
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Tez
https://cwiki.apache.org/confluence/display/Hive/Hive-Tez+Compatibility
https://github.com/apache/incubator-tez/blob/branch-0.2.0/INSTALL.txt
前言
每次运行HiveQL的时候都会有这么一条警告【WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.】
说明Hive-on-mr在Hive2中是不被推荐的,并且在将来的版本中可能不可用,那我们就考虑使用Tez来代替MR,前提是你已经有了Hive的运行环境,Tez的源码编译详见我的另一篇博客【https://blog.youkuaiyun.com/DataIntel_XiAn/article/details/99321925】
接下来看一下版本匹配问题,所以我使用hive2.3.2和tez0.9.1
在HDFS上新建一个目录,然后将编译好的tez的所有jar包上传上去
hdfs dfs -put tez-0.9.1 /tez
在hadoop下新建配置文件【tez-site.xml】如下,说明:因为不会递归查找,所以官方建议分别配置base和lib并用逗号隔开
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.9.1,${fs.defaultFS}/tez/tez-0.9.1/lib</value>
</property>
</configuration>修改mapred-site.xml如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn-tez</value>
</property>
</configuration>在hadoop-env.sh最后追加以下配置
# tez
export TEZ_CONF_DIR=/home/hadoop/hadoop-2.7.7/etc/hadoop/tez.site.xml
export TEZ_JARS=/home/hadoop/tez-0.9.1
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$TEZ_CONF_DIR:$TEZ_JARS/*:$TEZ_JARS/lib/*测试之前记得重启hadoop【计算引擎切换使用:set hive.execution.engine=tez;】
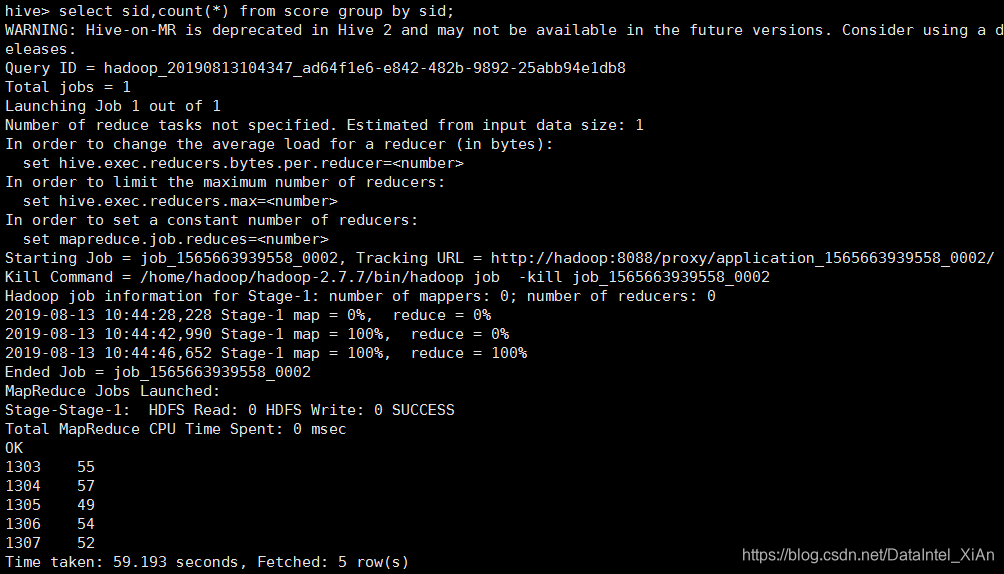
mr耗时59秒
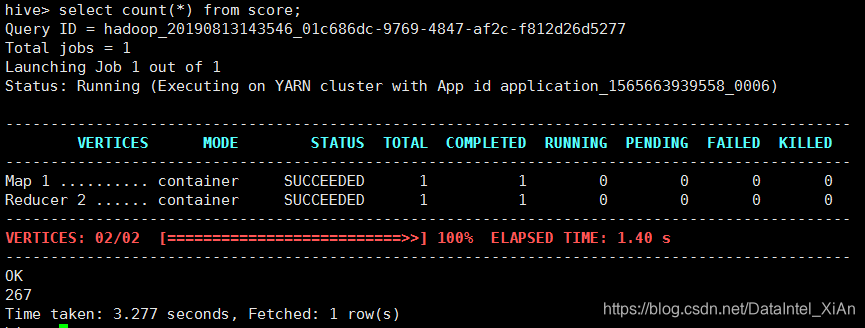
tez耗时3秒
好像区别不是很明显,那我们增加数据量到1000万条
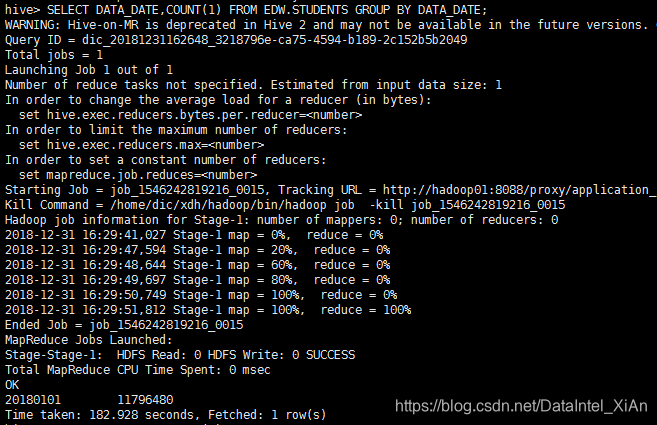
mr耗时182.9秒
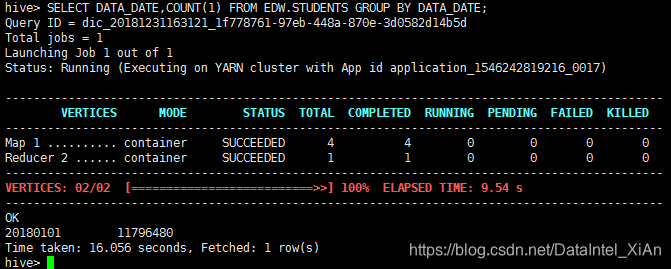

















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









