



 本次论坛聚焦多模态语义理解和学术信息挖掘,微软、山东AI研究院等专家将分享最新研究成果,探讨AI在视觉内容创作、公共安全识别、视觉大数据解析、跨模态学习与预训练、科技情报挖掘等领域的应用与挑战。
本次论坛聚焦多模态语义理解和学术信息挖掘,微软、山东AI研究院等专家将分享最新研究成果,探讨AI在视觉内容创作、公共安全识别、视觉大数据解析、跨模态学习与预训练、科技情报挖掘等领域的应用与挑战。
在人工智能与互联网大数据双重背景下,信息检索技术被广泛应用于各类信息获取场景,包括互联网搜索、推荐、智能问答等应用场景,与人们的生活息息相关,服务于用户的各类信息需求。
2020年,中国中文信息学会信息检索专委会举办了第一届智能信息检索前沿论坛,受到了学界和业界的广泛关注。今年,专委会将于2022年8月19日举办第三届智能信息检索前沿论坛,邀请学术界和产业界的嘉宾前来交流、分享、讨论。本次论坛由DataFountain平台提供支持,将以线上方式开展,并通过腾讯会议平台进行实时直播。
论坛将分为上、下午两个半场,主题为多模态语义理解和学术信息挖掘与检索,共邀请10位在学术界与产业界造诣颇深的专家介绍最新的研究、应用进展与思考,从不同角度碰撞出思想的火花,以促进国内相关领域科研人员、从业者和学生的相互学习和共同提高,推动国内信息检索事业的蓬勃发展。

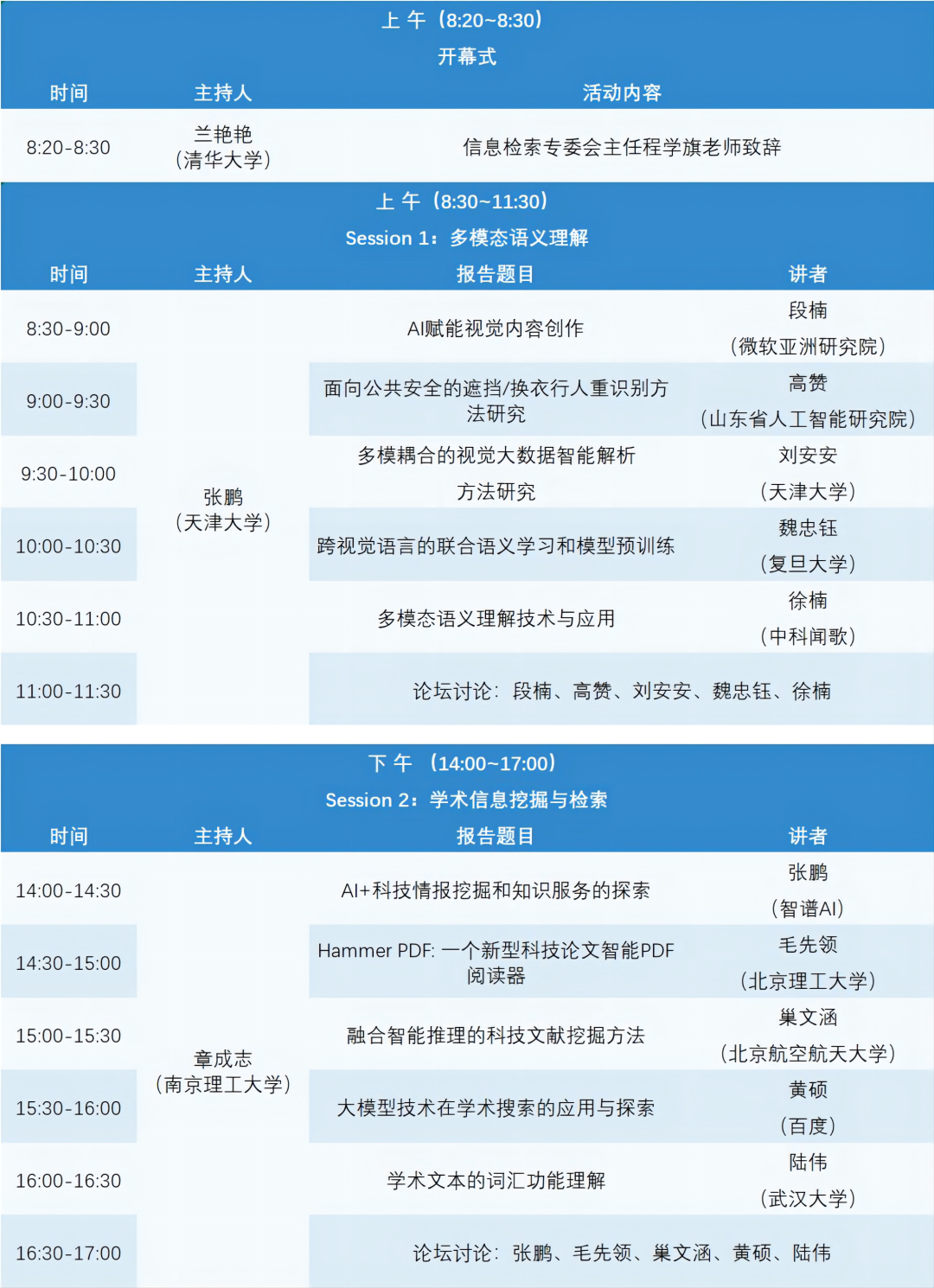
日程安排
嘉宾介绍
☞Session 1:多模态语义理解

嘉宾:段楠
报告题目: AI赋能视觉内容创作
简介:段楠博士,微软亚洲研究院高级研究经理,中国科学技术大学兼职博导,天津大学兼职教授,CCF杰出会员,主要从事自然语言处理、编程语言处理、多模态人工智能、机器推理等研究,多次担任NLP/AI/ML相关国际会议评测主席、高级领域主席和领域主席,发表学术论文100余篇,持有专利20余项,多项研究成果用于微软各类产品。
摘要:本报告将介绍微软亚洲研究院在视觉内容生成方面的最新研究成果:NUWA。通过这些研究,我们希望人工智能技术能够极大降低内容创作的门槛,提升内容创作者的生产力和创造力,从根本上改变内容创作的方式,使得人人都有机会成为优质内容的高效开发者和创作者。

嘉宾:高赞
报告题目:面向公共安全的遮挡/换衣行人重识别方法研究
简介:高赞博士,山东省人工智能研究院教授,博士生导师,国家青年人才计划人选、山东省突贡专家、天津市高校中青年骨干人才,学术带头人,山东省高等学校优秀青年“智能媒体分析与视觉感知”创新团队负责人和济南市高校院所“社交网络虚假媒体智能分析与理解”创新团队负责人,先后获山东省科技进步一等奖和天津市科技进步二等奖各1项。目前兼任计算机学会高级会员,山东省人工智能学会常务理事,计算机学会多媒体技术专委会、计算机视觉专委会、模式识别与人工智能委员会委员,中国图形图象学会多媒体技术专委会委员。近年来,主持或参与包括国家自然基金重点、国家重点研发计划等省部级以上课题20余项。在国际高水平会议和期刊上发表论文100余篇,IEEE/ACM汇刊或CCFA类会议30余篇,其中包括TIP,TMM,TCYBE,TKDE,TNNLS,TCSVT,TOMM,CVPR,SIGIR,ACMMM,WWW和AAAI等,4篇论文入选ESI高被引,1篇入选热点论文,2021年获CCFA类会议SIGIR2021最佳学生论文。
摘要:由于国家安全的需要和公众安全意识的提高,几乎所有城市都安装了大量的摄像头,且国内安防行业市场规模保持稳定增长,其市场前景非常可期,据中商产业研究院数据预测,2020年我国安防行业市场规模将突破1000亿元大关,同时,由于疫情的原因,人们戴口罩已经成为常态,这样,人脸识别技术将面临巨大的困难。为了弥补人脸识别技术的缺陷,行人重识别技术得到了快速的发展。然而,在实际应用中,行人重识别常常发生遮挡、姿态变化以及换衣等问题,这给行人重识别带来了极大的挑战。因此,在本次报告中,将汇报课题组近年来在换衣、遮挡行人重识别上的相关成果。

嘉宾:刘安安
报告题目: 多模耦合的视觉大数据智能解析方法研究
简介:刘安安,天津大学教授/博导,天津大学电视与图像信息研究所所长,入选爱思唯尔高被引学者、天津市“131”创新人才等,IEEE和CCF高级会员。作为负责人承担国家自然科学基金联合重点、国家重点研发计划课题等;以第一完成人获天津市科技进步特等奖和二等奖;发表论文百余篇,其中IEEE/ACM汇刊、CCF-A类会议长文70余篇(T-PAMI、T-IP、CVPR、ACM MM等),ESI热点论文2篇,ESI高被引论文6篇;论文被评为IEEE Journal of Biomedical and Health Informatics亮点论文,获中国多媒体大会最佳论文奖;授权中国发明专利40余项,美国发明专利2项,技术转让1项。
摘要:面对多领域和跨平台的视觉大数据,如何将其自动解析为符合人类认知的自然语言描述,从而满足视频管理、信息检索和自动问答等需求,已成为当前亟待解决的问题。视觉大数据智能解析相关研究尚处于初级阶段,缺乏桥接计算机视觉与自然语言处理的成熟理论来指导人们跨越视觉语义鸿沟。本次报告中,将汇报团队在多模耦合的视觉大数据智能解析近期研究成果,主要包括视觉场景图生成和视觉描述生成两方面。

嘉宾:魏忠钰
报告题目:跨视觉语言的联合语义学习和模型预训练
简介:复旦大学大数据学院副教授,智能复杂体系实验室双聘研究员,博士生导师,复旦大学数据智能与社会计算实验室(Fudan DISC)负责人,香港中文大学博士,美国德州大学达拉斯分校博士后。现任中文信息学会情感计算专委会副秘书长,社交媒体处理专委会常务委员兼秘书,青年工作委员会执委会副主任。在自然语言处理、人工智能领域的国际会议发表学术论文70余篇。担任多个重要国际会议及期刊评审,EMNLP 2020 多模态领域主席,EMNLP 2021 论辩挖掘与情感计算领域主席。曾获得2019年度中国中文信息学会社会媒体处理新锐奖,2020年度华为技术优秀成果奖,2021年上海市启明星计划。
摘要:跨视觉和语言模态的语义理解和生成是结合计算机视觉和自然语言处理的一个重要课题,有广阔的应用需深度学习的发展为跨视觉和语言领域的研究提供了便利,也催生了很多跨模态任务,包括跨模态检索、推理、生成和视觉导航等求,包括图片检索,视力障碍人士的辅助工具以及低龄学童教育支持等。视觉和语言是我们感知外部环境的重要方式,某种程度上说,它们是同一个客观世界的两套表示方法,并且互有侧重。本次报告会介绍课题组在跨模态语义联合学和模型预训练方面的一些工作,并介绍相应方法在不同任务上的表现。

嘉宾:徐楠
报告题目:多模态语义理解技术与应用
简介:徐楠博士,中科闻歌AI中台研发总监,主要研究多模态智能信息处理理论方法及其在社会计算、网络内容安全、媒体传播分析等领域的应用,在人工智能领域学术期刊和国际会议上发表论文10余篇(包括ACL、AAAI、SIGIR、CIKM、EMNLP等);正在承担或参与多项国家自然科学基金、国家重点研发项目等;曾获2020年中国科学院特别研究助理奖。
摘要:人类的信息获取、环境感知、知识学习与表达,都是采用多模态图文音的输入输出方式。多模态语义理解技术研究旨在通过对人类行为的研究,逐步借助AI建模和模拟人类对于多模态环境(数据)的感知和互动能力。近年来,依靠互联网所获取的大规模图文对与视频数据,以及以自监督学习为代表的预训练技术方法的进步,视觉语言多模态预训练模型在很大程度上打破了不同视觉语言任务之间的壁垒,本报告将系统的介绍下多模态语义理解预训练模型近期的研究成果,并介绍多模态内容理解与语义分析技术在中科闻歌的一些典型应用。
☞Session 2:学术信息挖掘与检索

嘉宾:张鹏
报告题目: AI+科技情报挖掘和知识服务的探索
简介:北京智谱华章科技有限公司CTO,清华大学2018创新领军工程博士,毕业于清华大学计算机科学与技术系,研究领域包括文本数据挖掘和语义分析、知识图谱构建和应用等。作为主要研究人员参与欧盟第七合作框架跨语言知识抽取、国家863计划“海量知识库建设与构建关键技术及系统”、科技情报分析挖掘平台AMiner(https://aminer.cn)等项目的研发工作,并参与设计和研发了国内首个中英文平衡的跨语言知识图谱系统XLORE(http://xlore.org),在ICML、ISWC等顶级会议上发表10余篇文章。长期致力于将知识图谱研究理论应用于实际需求,在语义大数据分析、智能问答、辅助决策等应用领域拥有丰富的实践经验。
摘要:科技情报大数据的分析和挖掘是当前科技创新领域非常受关注的研究和应用领域。科技情报大数据挖掘与服务平台AMiner以学者、论文文献、专利、期刊/会议、科技新闻、学术活动等数据为基础,构建数据之间的关联关系,深入分析挖掘,提供如技术发展趋势分析、前沿技术预见、学术评价、专家搜索/推荐、学者地图、学者关系网络分析等专业知识服务。在AMiner平台的研究过程中,我们探索了从传统机器学习到最新认知大模型等多种前沿AI技术,力图用技术实现和改进文献的检索推荐、语义分析和趋势预测,辅助情报分析人员更精准、更快速和更深入地洞悉科技大数据中的核心价值和隐含规律。本报告介绍了AMiner平台在AI+科技情报挖掘和知识服务方面的一些探索,以及在实际应用中的一些案例。

嘉宾:毛先领
报告题目:Hammer PDF: 一个新型科技论文智能PDF阅读器
简介:北京理工大学副教授,博导。主要研究信息检索与数据挖掘。目前担任计算机学会中文信息技术专委会委员、中文信息学会青工委执委以及语言与知识专委会委员;已在SIGIR、AAAI,IJCAI, TOIS, TKDE, CIKM, EMNLP等期刊会议上发表40余篇论文;部分成果获省部级科技进步奖;正在承担或参与国家重点研发计划课题、国家自然科学基金重点项目和面上项目等多项。
摘要:阅读科技论文,是研究者感知学术进展最重要的方式;而科技论文,绝大多数都是PDF格式。然而,现有的PDF阅读器,例如Adobe Acrobat Reader或福昕PDF阅读器等,通常仅仅只能渲染PDF文件以供阅读,没有考虑论文内容本身的多粒度理解。本次报告将介绍Hammer PDF(pdf.hammerscholar.net),一个新型的智能科技论文阅读器,除了提供基本的阅读功能,还提供了如下四大特征:信息抽取、信息扩展、内置Hammer Scholar学术搜索、内置学术对话机器人。该PDF阅读器能有效地帮助研究者提升阅读效能。

嘉宾:巢文涵
报告题目:融合智能推理的科技文献挖掘方法
简介:北京航空航天大学计算机学院副教授、博士,研究兴趣为机器翻译、自然语言处理、科技情报、智能司法等,近年来,分别主持国家级/省部级课题10余项,其中包括科技部重点研发计划课题、国家自然科学基金青年基金、教育部博士点基金新教师基金、工信部科研课题等。在这些课题的支持下,对信息抽取、论证挖掘、机器翻译、智能司法等领域进行了深入研究,在ACL、EMNLP、COLING、NAACL、PAKDD、MT SUMMIT等重要国内外会议及期刊上发表相关论文30余篇。获电子学会科技一等奖1项;发表译著1项,申请及授权专利若干项。担任国内外重要会议和期刊审稿人及中国电力企业联合会人工智能标准化技术委员会委员。
摘要:科技文献作为重要的知识载体,凝聚着全人类的智慧,科技文献挖掘已被广泛应用于把握科技发展脉络、探测科技研究前沿、洞悉科技竞合态势、识别“卡脖子”技术难题及评价学术影响力等众多领域。然而,随着科技文献数量的爆发式增长,真正有用的知识被嵌入和隐藏在大量无关的自然语言表述中,如何高效并且精准地定位、理解和利用这些有用信息,形成“数据+知识+技术+应用”四轮驱动的科技情报服务,成为当前科技文献挖掘面临的挑战。本次报告中将介绍课题组在该方向的最新研究成果,包括科技文献贡献描述分类和细粒度论元信息抽取、基于科技文献论辩结构的多模态对齐,并进一步探讨如何科学有效的验证科技论点等科技文献知识挖掘方法。

嘉宾:黄硕
报告题目: 大模型技术在学术搜索的应用与探索
简介:百度自然语言处理部主任架构师。有十多年搜索、推荐和人工智能技术研发经验,先后在百度、腾讯、Facebook等多家公司从事搜索、个性化推荐、自然语言处理技术研发工作,在人工智能技术应用方面有丰富的实战经验;曾主导百度搜索个性化技术研发并在十多个产品线顺利上线,并深度参与百度深度学习框架在企业中的推广应用。目前在百度负责NLP基础技术研发、AI技术产业化应用等方向。
摘要:百度学术搜索为学术用户提供海量中英文文献的检索服务,其背后依赖着百度十多年搜索技术的发展。近几年来,深度学习预训练大模型发展迅速,颠覆了许多以往使用传统机器学习技术难以解决的任务。得益于大模型技术在百度的发展,学术产品在搜索的多个方面都得到了应用。本次分享将在学术搜索引擎技术的基础上,介绍大模型技术在需求识别、检索、排序等方面的应用,并进一步介绍百度更多创新性AI技术与学术产品结合的尝试及长期探索思路。

嘉宾:陆伟
报告题目:学术文本的词汇功能理解
简介: 陆伟,博士,二级教授,武汉大学信息管理学院院长,信息检索与知识挖掘研究所所长。先后入选教育部新世纪优秀人才、首届长江青年学者、长江学者特聘教授。发表AAAI、SIGIR、CCS、EMNLP、JASIST、IP&M、JOI等论文百余篇,主持国家社科基金重大项目、国家重点研发计划课题等各类纵横向项目50余项。研发问答机器人RobertAI、学术信息智能处理平台ScienceAI、网络舆情大数据系统WHU-POMS系统等,获教育部高等学校科研成果奖(人文社科)、湖北省社科优秀成果奖、湖北省科技信息成果奖等。目前主要研究兴趣为信息检索与可视化、知识图谱与大数据智能、AI人机协同等。
摘要:科技信息服务是创新驱动国家发展战略的重要支撑,未来的科学研究将逐渐人机协同的科研方向发展,这有赖于科技信息服务的智能化和语义化。自然语言处理和人工智能技术的发展为科技信息的智能理解和深度发掘提供了新的技术和方法支撑。在介绍科技信息智能理解框架和现状的基础上,探索词汇功能层面的学术文本智能理解,并讨论其在信息检索和科技评价等方面的潜在应用。
论坛时间:8月19日8:20-17:00
直播平台:腾讯会议

















 2087
2087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









