




 本文介绍了PipeDream模型划分的方法,包括关键变量Ak和Tk的定义及其计算方式,并详细解释了模型划分过程中的核心算法。
本文介绍了PipeDream模型划分的方法,包括关键变量Ak和Tk的定义及其计算方式,并详细解释了模型划分过程中的核心算法。
关于PipeDream的模型划分
模型划分,是利用profiling阶段产生的profile文件作为输入,将模型进行划分,其中profile文件中包含的内容有Tl,al,wl。分别代表了第l层的正向计算与反向传播的时间、第l层的参数大小、第l层的激活activation大小(都是以字节为单位)
首先介绍两个变量,AkA^kAk(i -> j,m) ,TkT^kTk(i -> j,m).
AkA^kAk(i -> j,m) :从layer i到layer j使用mkm_kmk个worker,作为一个最优管道,这其中最慢stage的执行时间就是AkA^kAk(i -> j,m) ,这个管道中可能有多个stage,也可能只有一个stage。
TkT^kTk(i -> j,m) :把layer i到layer j作为一个stage,使用mkm_kmk个worker进行数据并行所需的时间(包括计算时间和参数同步时间)
关于TkT^kTk(i -> j,m)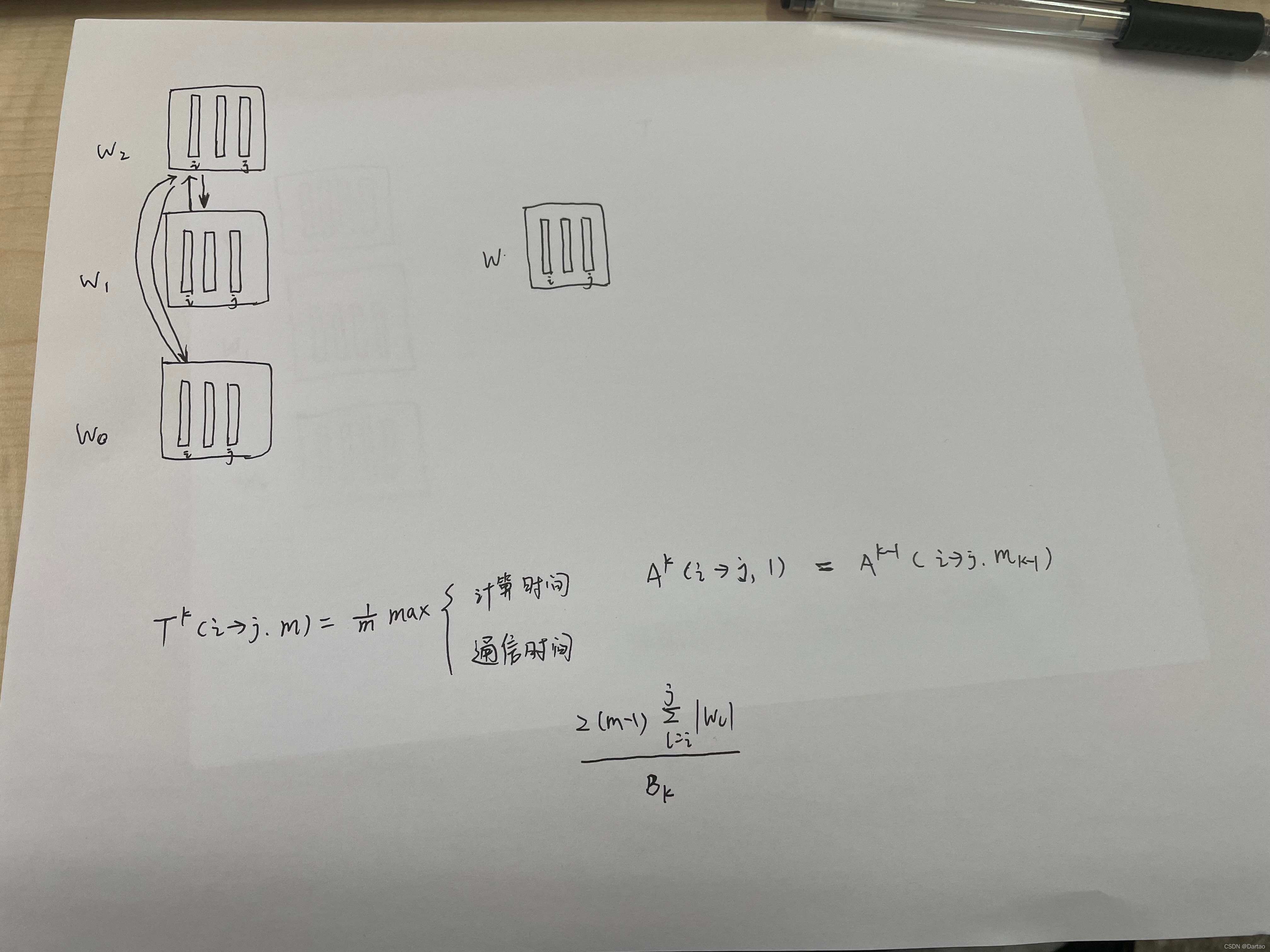
max里面的第一项是从i->j的计算时间,第二项则是参数同步,即通信的时间。关于第一项计算时间,可以用AkA^kAk(i -> j,1)代替的原因是,这里i->j使用一个worker的最优管道的最慢stage,可以理解为把i->j作为一个stage放到一个worker上!之后又可以使用Ak−1A^{k-1}Ak−1(i -> j,mk−1m_{k-1}mk−1) 代替AkA^kAk(i -> j,1),最后就得到了上述的公式!
关于AkA^kAk(i -> j,m)
这里表示的是最优管道划分的最慢stage的执行时间,那么可以用双重循环来实现
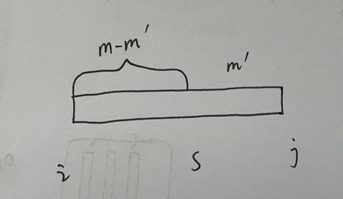
考虑layer i -> layer s -> layer j,然后把layer s -> layer j当作是一个stage,而layer i -> layer s作为一个最佳子管道. 另外还需要给新分配出来的stage m’个workers. 那么前面那段还剩m - m’个workers. 于是就有了上式. 需要遍历所有s的位置(i <= s < j),还需要遍历所有m’ ( 1 <= m’ < m).
max里的第一项代表的是i->s的最佳子管道中最慢stage的执行时间,第二项代表的是从s->s+1传递激活/梯度的时间,第三项则是s->j这个单独stage的执行时间。这三项的最慢时间,也就代表了从layer i -> layer j的最慢stage的时间!
算法目标:求解

按照上述的过程进行迭代。
初始化:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









