




 本文探讨深度学习的发展历程,强调其在特征提取方面的优势,同时也指出深度学习的局限性,如鲁棒性和推理能力不足。介绍了语义图像分割的基本概念,对比传统图像分割,语义分割更关注于理解图像内容,实现像素级分类。详细解析了FCN、U-Net、Seg-Net、PSP-Net和Deeplab等前沿模型。
本文探讨深度学习的发展历程,强调其在特征提取方面的优势,同时也指出深度学习的局限性,如鲁棒性和推理能力不足。介绍了语义图像分割的基本概念,对比传统图像分割,语义分割更关注于理解图像内容,实现像素级分类。详细解析了FCN、U-Net、Seg-Net、PSP-Net和Deeplab等前沿模型。
前言(废话)
作为一个深度学习的小白(其实小白都算不上,仅仅是任务需要利用TensorFlow写过一两个浅层的卷积神经网络而已)有幸的参加了CCF举办的深度学习前沿讨论班,整体感受是大家做的都很高大上,具体对一个小白抱着想学一点深度学习日常使用的小技巧的我而言,为期两天的讨论班学习让我显得有点儿格格不入。钱花了,总是要学点东西才对得起自己呀,在第一场报告之后我就明确了专属于自己的学习目标,1⃣️明白深度学习的现状;2⃣️了解目前的前沿热门研究。
所以,LZ将围绕自己定下的目标进行总结和整理。
深度学习发展历程
这个发展历程,你一google就能发现各种各样或简单或详细的介绍。但是在这次讨论班之后对LZ自己而言是对深度学习发展历程的一次全新的认识,不再是几次低谷几次高潮流于文字表面的理解。
不方便透露报告者名字的一位老师在讨论班第二天下午进行了一场关于深度学习宏观的报告,比起前面高大上的报告而言,LZ可能更能接受这样的报告。这位老师幽默风趣讲段子,故事性极强的向大家展示了深度学习的发展历程
背景
在介绍深度学习发展历程之前,先简单介绍一下神经网络的一些基本背景知识。大家一直在讲“机器学习”、“深度学习”。那么,思考这样一个问题,什么是学习?学习的本质是什么? 学习就是基于经验数据进行函数估计,我想这样的回答应该是大家可能都不能反驳的事实吧。所以,神经网络本质也就是一个函数估计问题,只是这个函数可能会比较复杂一点儿罢了。对于不同的算法进行分类常有根据是否是有标签数据分为监督学习和非监督学习,同时我们也能将算法分为“傻瓜”和“专家”类型。这种分类方式类似于照相机,专业型的单反在专业人士手中体现出的效果往往是普通人难以企及的,傻瓜型的学习算法也就是任何人在同样的数据下使用这种算法得到的效果往往是差不多的,(PCA,K近邻等典型代表),反之专家型就是因人而异差距巨大。例如,深度学习,其网络的结构,小技巧的使用,超参数的设定都会影响到算法的效果,所以专家往往能比普通人更好驾驭这类型算法。
深度学习的发展历程(人工智能的发展历程)
深度学习作为人工智能重要的一个部分,其发展历程也直接相关反映出了人工智能的发展历程。提到人工智能发展历程,下面这张图或者类似的图往往被拿出来说人工智能发展几起几落。接下来,LZ将就为什么出现这样的情况进行介绍。

1956年夏天约翰.麦卡锡等人在美国达特茅斯学院开会研讨“如何利用机器模拟人的智慧”大会上提出了人工智能,标志着人工智能的诞生。1958年提出线性感知器算法,这个算法对线性数据进行了很好的拟合,大家也对这样的算法能有效拟合各种函数感到乐观,大量的科研工作者以及政府资金的流入让人工智能进入了第一个高潮。
但是这样的线性感知器很快就被人们发现了其弊端。连最简单的异或和二分类都不能进行有效拟合,本质上多层的线性感知器还是线性的算法。而真实世界中存在的问题更多是非线性的,这样适用范围极小的算法被政府和投资者抛弃。进入第一次低谷。
1982年,Hopfield 网络以及多层的前馈神经网络被提出。相当于,在每层之间加入了非线性变换(Sigmoid函数)激活。这样,神经网络就能适用于更多的非线性场景了,并且在当时成功了进行了手写数字的识别(多分类问题)。万有逼近(如果一个隐藏层包含足够多的神经元,多层前馈神经网络就能以任意精度逼近任意连续函数)定理出现,成功迎来了第二次高潮。

1995年一个牛逼得不行的算法出现,SVM。SVM算法应对于小样本数据效果可以和神经网络媲美,同时它有很强的可解释性,这可是神经网络一直的弊端。没办法,只有被打败,自然的进入了第二次低谷。
知道06年,数据量增大,计算能力提高等让深度学习有了更多数据,这样就能体现出它的优势。但是,为什么之前也有不错数据量的时候为什么也没有让其腾飞呢?究其原因还是一直只适用了3层的结构,毕竟梯度消失问题一直制约着神经网络结构加深(多层sigmiod激活函数求导,链式法则导致梯度消失)。伴随数据量上升,计算能力提高,迫切的解决了梯度消失问题,迎来了第三次高潮。
深度学习能和不能
目前,深度学习已经火爆得应用于各行各业。那么深度学习到底适合做什么,不适合做什么。
深度学习适合做特征提取。这个也是深度学习众多应用中的一种,深度学习本质上是一种端到端的学习模式,自动进行了特征提取然后进行相关任务(分类、预测等)。
我们都知道,机器学习中特征提取是重中之重,能决定一个算法的上限。但是特征提取往往是基于经验知识,反复尝试这样的方法造成提取的特征难以达到最好,深度学习通过所有特征的线性组合,非线性变换得到最适合学习任务的特征。(LZ认为这就是深度学习的最大优势所在吧)既然,深度学习有这样的特性那么它自然适合进行特征提取任务。自编码器就是最好的例子,同时LZ从事的网络表示学习它也取得了重大成就。LZ也将在如何利用深度学习进行更好的图特征提取工作上进行更深一步的研究探索。
反之,深度学习又不适合做什么呢?目前有什么缺点。
- 鲁棒性不足

如上图,人类肉眼可见的两种同类物体,会被深度学习误判。根据深度学习损失函数,进行构造噪声导致深度学习判别失真。这样的鲁棒性不足,导致深度学习可能被各种恶意攻击。这也是目前自动驾驶突然停滞不前的一个重要原因。 - 推理能力不足
- 数据驱动导致的先天不足
从数据中获取到的知识导致深度学习存在偏见。例如,罪犯判别中由于历史数据中有很多黑人犯罪,导致深度学习出现种族歧视。等等 - 可解释差

深度学习小知识
这里,主要介绍一下深度学习目前存在的一些小问题,存在这样问题的原因,以及简单有效的解决方法。
在此之前,根据信号学相关的知识我们知道信息在传递过程中是存在信息损失的。假设有一个系统,在输入层X和输出层Y之间还有n个隐藏层,信息传递的过程就是:
X
⟶
S
1
⟶
S
2
⟶
.
.
.
⟶
S
n
⟶
Y
X\longrightarrow{S_1}\longrightarrow{S_2}\longrightarrow{...}\longrightarrow{S_n}\longrightarrow{Y}
X⟶S1⟶S2⟶...⟶Sn⟶Y。根据根据信息处理不等式
I
(
X
,
S
1
)
≥
I
(
X
,
S
2
)
≥
.
.
.
≥
I
(
X
,
S
n
)
≥
I
(
X
,
Y
)
I(X,S_1)\geq I(X,S_2)\geq...\geq I(X,S_n)\geq I(X,Y)
I(X,S1)≥I(X,S2)≥...≥I(X,Sn)≥I(X,Y)。由此可知数据在系统各层之间传递时候信号量是递减的。如果X层和Y层相同或者类似表明系统的隐层没有或者几乎没有损失信息。此时,每一层都会和X有相同或者相似的信号量,可以看成输入信息的不同表达,也就是机器学习中进行的特征选择和特征提取。深度学习正是一个类似这样的系统,每一层的输出作为下一层的输入,并且要求真个系统的输入和输出相同或者相似,这样得到的特征就是适合于最后任务的特征(信号量损失最小)。所以,深度学习的本质:通过构造深层的网络结构利用海量的数据进行训练,来学习出更有用的特征,这些特征的有用性决定来最终任务的准确性。那么本质上就是怎么学出一个最优秀最有表达能力的特征。
深度学习已经在很多运用中展现出来它的强大,但是我们在使用过程中还是需要注意里面的坑,也就是它可能出现的一些问题和陷阱:
- 梯度扩散:从顶层越往下,梯度就越来越稀疏,用来矫正误差的信号越来越小。可能导致某一层出现较大的信号损失,这样导致整个系统出现较大信号损失,出现特征提取不准确的问题
- 局部最优:由于每次的非线性变换造成深度加深之后整个系统出现高度的非线性特点。高度非线性就是一个非凸优化,这时候很容易造成局部最有现象。
- 过拟合:当深度越深模型的容量越大,需要学习的参数也就越多,越容易造成对训练数据的过拟合。
一些小技巧:
- 从底层开始,逐层向上训练网络,每次训练一个单层网络。链接一篇博客,原理很简单。
- 增加更多的先验知识缩小模型的容量,简单而言就是减少模型中的参数。但是吧,我觉得这些先验知识获取还是一个尝试和积累的过程,像我一样的小白谈什么先验知识。
- 采用大规模的训练数据,数据量不够的话就自己尝试多种数据集的扩充方法。
- 小tracks,如dropout、pooling等
目前前沿研究
语义图像分割
语义图像分割要做什么
在讲语义分割的相关运用之前,作为CV方面的小白先了解一下什么是图像分割,什么又是语义图像分割。度娘一下你就知道: 图像分割定义图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。它是由图像处理到图像分析的关键步骤。现有的图像分割方法主要分以下几类:基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法以及基于特定理论的分割方法等。从数学角度来看,图像分割是将数字图像划分成互不相交的区域的过程。图像分割的过程也是一个标记过程,即把属于同一区域的像索赋予相同的编号。 简单而言图像分割就是设计一些合理的算法从图中找出自己感兴趣的部分。
传统的图像分割
传统的图像分割方式主要是根据图像像素点在灰度或者色彩空间的位置进行聚类分析,直接对像素点进行聚类,达到图像分割的目的。进一步的,也有利用图像的纹理和连通性等信息融合进行图分割。下面的图都是使用传统图像分割技术得到的分割效果。

|

|

|

|

|

|

|

|
可以看见这些传统的图像分割技术已经能够将一些图像进行很好的分割,北极熊、长颈鹿、飞机都取得来令人满意的效果。但是,那只鲜艳的鸟就出现来一些不那么符合人感官的分割,一只鸟因为颜色的区域差异被分成来几个部分。出现这样的原因,主要是因为图片的颜色跨度大,且多。所以,为了分割能更好的满足人多感官提出来语义图像分割 。
语义图像分割的原则是定位和分割出图像中不同类型的目标(语义上的不同物体)。和传统的图像分割有以下几个不同点:
- 所分割的区域能够完整描述某种对象,覆盖的区域上是一个完整的物体,而不是物体的某一部分。
- 对分割的区域有标签分类,即相同的物体是同样的标签。
 语义图像分割 语义图像分割
|
语义图像分割是在像素级别上理解图像内容的任务。不同于图像分类任务对每张图进行分配一个标签,语义图像分割是对一个图像上每个像素点分配一个标签,同时要求不同类别的像素在图像的边缘。下面这个图就能够很形象的展示几种任务的不同。

语义图像分割要怎么做
FCN(全卷积神经网络)
2015年伯克利团队提出来FCN进行语义图像分割,这项工作获得了CVPR2015的最佳论文。CVPR:计算机视觉和模式识别的顶会。
通常cnn网络在卷积之后会接上若干个全连接层,将卷积层产生的特征图(feature map)映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率,如ALexNet网络最后输出一个1000维的向量表示输入图像属于每一类的概率。二FCN是将卷积后接的全连接层也全部转换成了卷积层,只是是进行的反卷积,采用反卷积层对最后一个卷基层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后奇偶在上采样的特征图进行像素的分类。大致流程如下图:

具体的算法是怎么做的,这里LZ重点是介绍,而不是讲解FCN(懒得码字)。阅读了一些文献和博客,最好的推荐当然是去阅读这篇原文咯,这里也推荐一篇博客FCN供大家参考。
FCN总结
FCN采用的本质上还是CNN的结构,前5层是卷积层,第6、7、8层是特殊的卷积层最终形成一个1000维的向量用来进行图像类别预测。语义分割则是从第5层开始进行上采样(反卷积),将像素点的分类结果一次上溯到原始的像素点,达到最后对像素点进行分类的目的。经过多次卷积之后,所得到的图像则是分辨率越来越低,5次卷积造成了分辨率分别缩小了2、4、8、16、32倍。对最后一层进行上采样也需要32倍的上采样这样会造成最后的结果很不精确,一些细节丢失严重。从第4层第3层反卷积就只需要16、8倍上采样相对就精确多了。结果参看下图。

通过总结,FCN的缺点也是很明显了,细节丢失严重,分割过于平滑。
U-Net
在讲到FCN的时候就已经讲到了随着卷积的加深,信号损失越来越严重,进行上采样恢复起来也是越来越不准确。所以,U-Net直接在每次卷积对应反卷积的位置进行短路连接,使用了concat操作取代了FCN中的加和操作。想知道更多详情的小伙伴还是直接去多原文吧链接(还有视频讲解的哟)。

Seg-Net
Seg-Net最主要的特点就是在进行上采样反卷积的过程中使用了和卷积同样的结构,同时SegNet与FCN的主要区别在于,解码层的上采样过程使用了编码层中对应位置最大池化层的池化参数。它的主要结构如下图。同样推荐有兴趣的可以参看原文《SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling》。

PSP-Net
PSP-Net与FCN的主要区别在于,在编码层和解码层的中间添加了并行的金字塔池化层,从而增加了模型对多尺度信息的感知能力。论文截图中的结构描述已经很清晰的描述了整个网络结构,如下图。

Deeplab
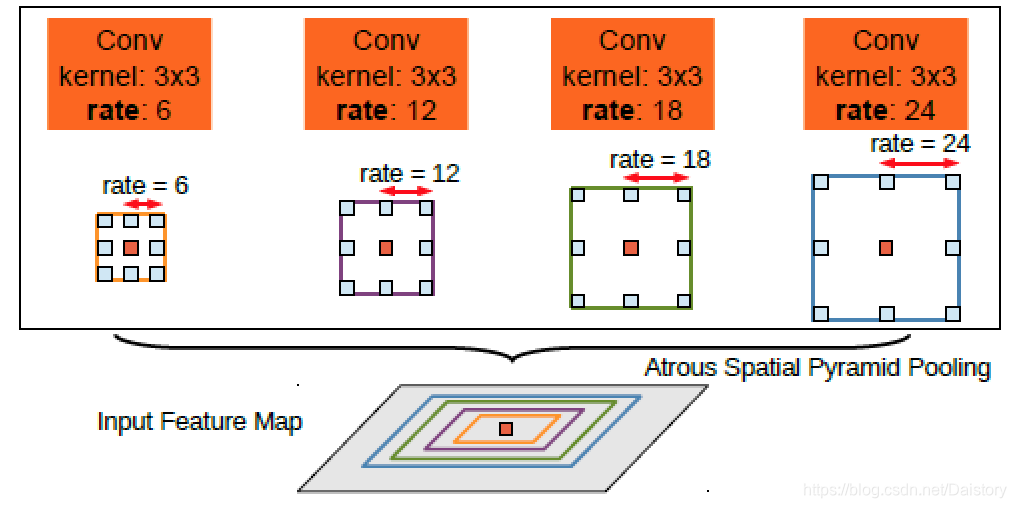
deeplab主要是在FCN上采用了空洞的卷积代替了FCN中的上下采样操作。同时,利用并行金字塔池化层进行多尺度信息的规整。具体为什么使用空洞的卷积层会比使用普通的卷积层效果好呢?还是查看他的原文吧。《DeepLab: Semantic Image Segmentiation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》
|

|


















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









