




自学所用
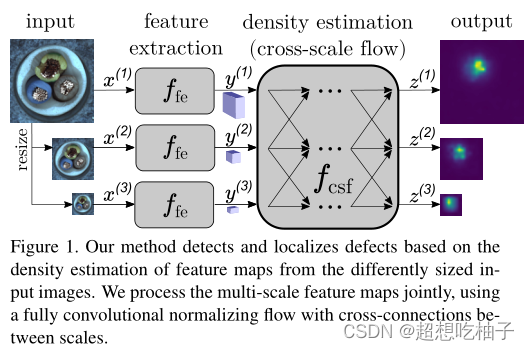
在工业制造过程中,错误经常发生在不可预测的时间和未知的表现形式中。我们解决了自动缺陷检测问题,而不需要任何缺陷部件的图像样本。最近的工作使用强大的统计先验或过度简化的数据表示来模拟无缺陷图像数据的分布。相比之下,我们的方法处理结合全局和局部图像上下文的细粒度表示,同时灵活地估计密度。为此,我们提出了一种新颖的全卷积跨尺度归一化流(CS-Flow),它联合处理不同尺度的多个特征图。使用标准化流程为输入样本分配有意义的可能性允许在图像级别进行有效的缺陷检测。此外,由于保留的空间排列,归一化流的潜在空间是可解释的,这使得能够定位图像中的缺陷区域。
最近的工作依赖于密度估计从ImageNet上预训练的模型获得的图像特征,然而,由于特征图的平均或需要强大的统计先验,信息丢失,限制了它们在密度估计中的灵活性,为了缓解这些问题,提出了一种归一化流,能够处理多尺度特征图以估计其密度。
CS-Flow通过在彼此交互的同时通过NF并行传播它们来同时chuli 不同尺度的图像特征;模型利用局部和全局上下文信息和相关性的全部潜力来精确地学习分布以识别缺陷示例,全卷积架构还保留了空间排列,从而可以可视化图像上的缺陷区域。
异常检测:
最先进的工作可以大致分为基于生成模型和预训练网络的方法。
生成式模型:
许多异常检测方法都基于生成模型,例如自动编码器和GAN,它们经过优化以生成正常数据,这些方法通过生成模型无法重建异常来检测异常;在最简单的情况下,比较自动编码器的输入和重建,在这种情况下,高重建误差被解释为异常的指标;与自动编码器的解码部分类似,GAN的生成器用于异常检测;自动编码器和GAN在缺陷检测任务上表现不佳,由于具有个体大小、形状和结构不同类型的异常在重建误差方面具有不一致的特征。
基于预训练网络的方法:
许多方法不是直接处理图像,而是对预训练网络的特征进行缺陷检测,在ImageNet等大型数据库上进行预训练可确保提取在存在缺陷时预期会有所不同的通用特征,通过这种方式,考虑了无法从无缺陷数据中学习的判别特征,因为它们不一定会出现在其中;我们通过最大似然估计学习真实分布,利用了全尺寸特征图的细粒度信息。
其他方法:
除了生成模型和预训练模型之外,还有其他方法可以执行异常检测,例如一种可学习的超球面分类器,使用示例异常值暴露作为异常替代;通过定义分布内和分布外转换来使用对同一图像增强的对比学习。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 900
900


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








