



 本文介绍了正则表达式的用途,它由普通字符和元字符组成,用于检查字符是否满足某一格式。还阐述了基础和拓展正则表达式的常见元字符,如转义字符、匹配位置字符等。最后给出查找特定电话号码的两个小实验。
本文介绍了正则表达式的用途,它由普通字符和元字符组成,用于检查字符是否满足某一格式。还阐述了基础和拓展正则表达式的常见元字符,如转义字符、匹配位置字符等。最后给出查找特定电话号码的两个小实验。
一、正则表达式用途
正则表达式通常用于判断语句中,用来检查某一字符是否满足某一格式
正则表达式是由普通字符和元字符组成
普通字符包括大小写字母、数字、标点符号及一些其他符号
元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符或表达式)在目标对象中的出现模式
二、基础正则表达式常见元字符
(支持的工具:grep、egrep、sed、awk)
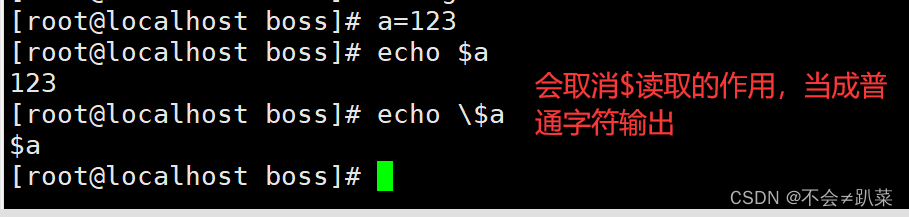
\:转义字符,用于取消特殊符号的含义,例:\!、\n、\$等
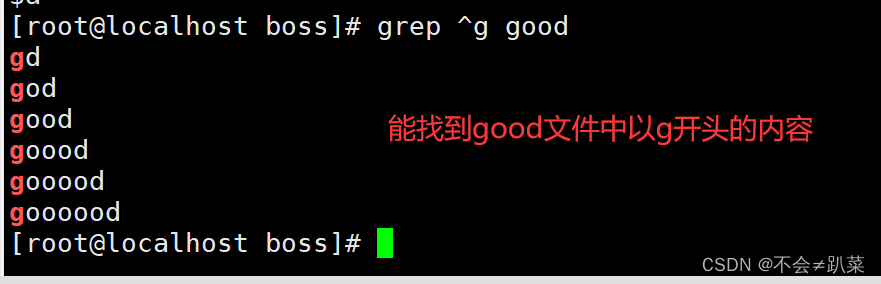
^:匹配字符串开始的为止,例:^a、^the、^#、^[a-z]
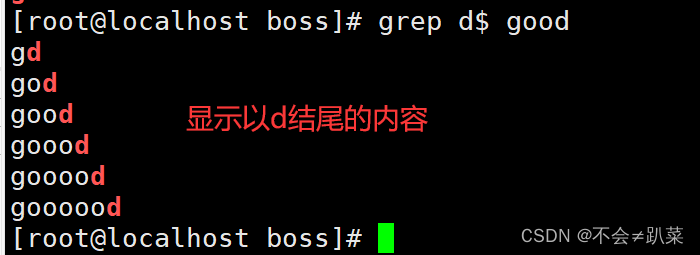
$:匹配字符串结束的位置,例:word$、^$匹配空行
.:匹配除了\n之外的任意一个字符,例:go.d、g..d
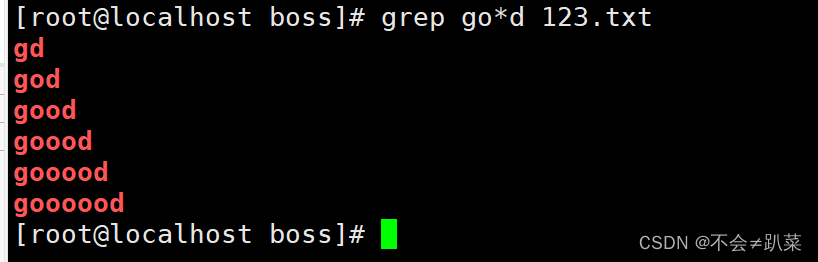
*:匹配前面子表达式0次或者多次,例:goo*d、go.*d
[list]:匹配list列表中的一个字符,例:go[old],[a-z][A-Z][0-9]匹配
[^list]:匹配任意非list列表中的一个字符,例:[^0-9]、[^A-Z]、[a-z]
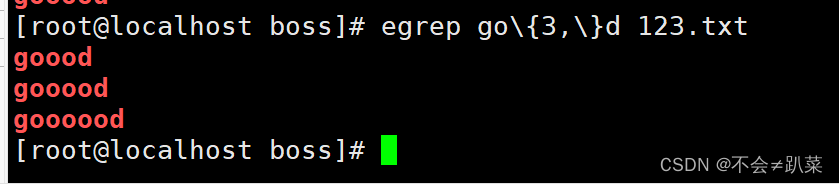
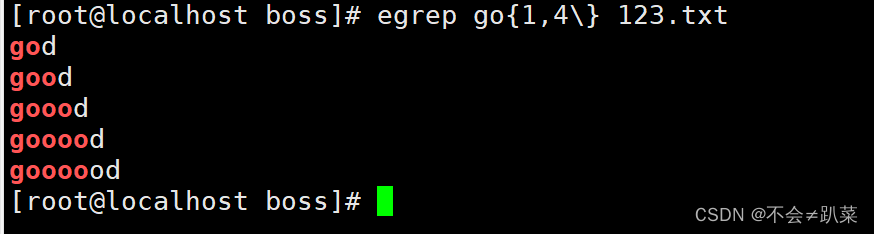
\{n\}:匹配前面的子表达式n次,例:go\{2\}d、'[0-9]\{2,\}'匹配两位数字
\{n,\}:匹配前面的子表达式不少于n次,例:go、{2,\}d、'[0-9]\{2,\}d'、'[0-9]\[2,\]'匹配两位
及两位以上数字
\{n,m\}:匹配前面的子表达式n到m次,例:go\{2,3}d、'[0-9]\{2,3\}‘匹配两位到三位数字
注:egrep、awk使用{n}、{n,}、{n,m}匹配时“{}”前不用加“\”
\w:匹配包括下划线的任何单词字符。
\W:匹配任何非单词字符。等价于"[^A-Za-z0-9]"。
\d:匹配一个数字字符。
\D:匹配一个非数字字符。等价于[^0-9]
\s:空白符
\S:非空白符
\:转义字符,用于取消特殊符号的含义,例:!、\n、$等
^:匹配字符串开始的为止,例:^a、^the、^#、^[a-z]
$:匹配字符串结束的位置,例:word$、^$匹配空行
.:匹配除了\n之外的任意一个字符,例:go.d、g…d

*:匹配前面子表达式0次或者多次,例:goo*d、go.*d
[list]:匹配list列表中的一个字符,例:go[old],[a-z][A-Z][0-9]匹配

[^list]:匹配任意非list列表中的一个字符,例:[0-9]、[A-Z]、[a-z]

\{n}:匹配前面的子表达式n次,例:go{2}d、‘[0-9]{2,}‘匹配两位数字

\{n,}:匹配前面的子表达式不少于n次,例:go、{2,}d、’[0-9]{2,}d’、'[0-9][2,]‘匹配两位及两位以上
{n,m}:匹配前面的子表达式n到m次,例:go{2,3}d、’[0-9]{2,3}‘匹配两位到三位数字
\w:匹配包括下划线的任何单词字符。\w:匹配任何非单词字符。等价于"[^A-Za-z0-9]“。

\W:匹配任何非单词字符。等价于”[^A-Za-z0-9]"。

\d:匹配一个数字字符。

\D:匹配一个非数字字符。等价于[^0-9]

\s:空白符

\S:非空白符

三、拓展正则表达式元字符
(支持的工具:egrep、awk)grep -E,sed -r
+:匹配前面子表达式1次以上,例:go+d,将匹配至少一个o,如god、good、gooood等
?:匹配前面子表达式0次或者1次,例:go?d,将匹配gd或者god
():将括号中的字符串作为一个整体,例:g(oo)+d,将匹配oo整体1次以上,如good、gooood等
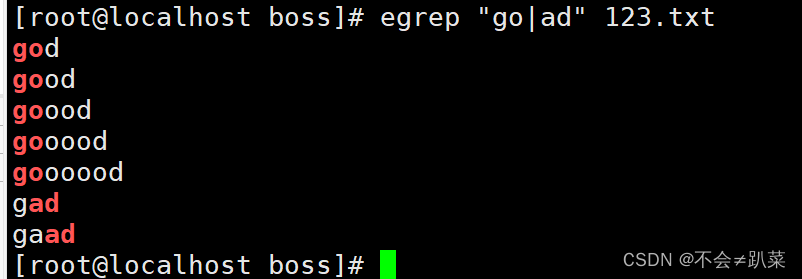
|:以或的方式匹配字符串,例:g(oo|la)d,将匹配good或者glad
+:匹配前面子表达式1次以上,例:go+d,将匹配至少一个o,如god、good、gooood等

?:匹配前面子表达式0次或者1次,例:go?d,将匹配gd或者god

():将括号中的字符串作为一个整体,例:g(oo)+d,将匹配oo整体1次以上,如good、gooood等

|:以或的方式匹配字符串,例:g(oo|la)d,将匹配good或者glad
四、两个小实验
查找出自己想要的电话号码
题目1:
02588888888
025-5555555555
025 12345678
025 54321678
025ABC88888
025-85432109
028-85643210
0251-52765421
区号025开头,号码与区号间可以是空格、-、没有,号码必须是5或者8开头的八位数
答案:

题目2:
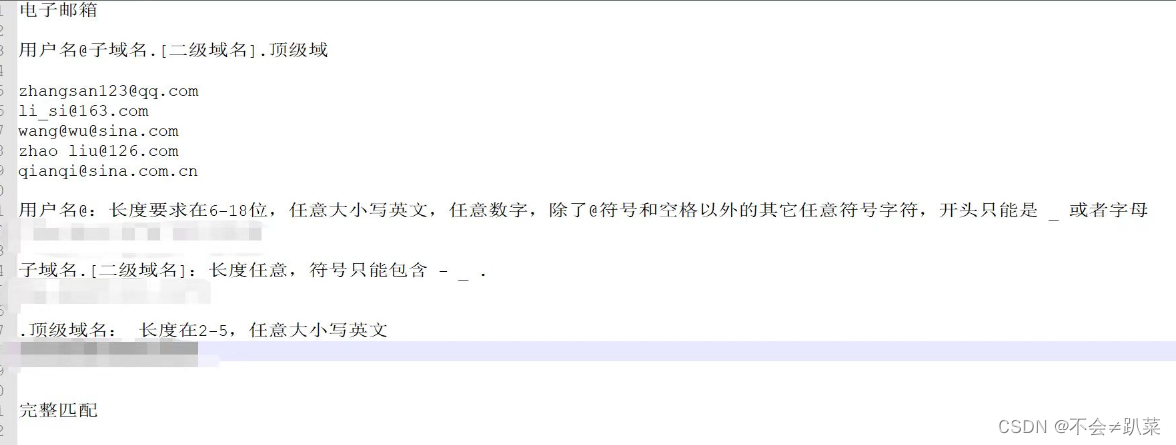
答案:


















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









