



 提出一种基于奖励和惩罚的协调激励机制,旨在优化众包平台上的工人、任务发布者及平台三者之间的利益平衡。该机制通过评估工人提交的二元组(任务解决方式及其信任度)来决定奖励或惩罚,从而提升数据质量、降低成本、减少延迟并改善平台性能。
提出一种基于奖励和惩罚的协调激励机制,旨在优化众包平台上的工人、任务发布者及平台三者之间的利益平衡。该机制通过评估工人提交的二元组(任务解决方式及其信任度)来决定奖励或惩罚,从而提升数据质量、降低成本、减少延迟并改善平台性能。
奖励或者惩罚 :众包中收益者的协调激励
(2017年,IEEE Transactions On Mobile Computing)
涉及到众包工人、任务发布者以及平台三方的利益,本文提出4个评价指标,Quality:工人提供的答案质量不同,任务请求者总是想获得高质量的数据;
cost:工人最小化自身成本并最大化自己的报酬,请求者要求付给工人的报酬成本最小;
Latency:由于任务难度较高,大多数工人面对此任务时选择跳过,导致任务无法被及时完成;
improvement of platform:平台可以提高吸引更多的用户以及防止工人恶意行为
本文提出一种协调激励机制,控制任务请求者的报酬成本、保持激励工人的参与度以及提高平台性能。激励机制的基本思想是基于奖励和惩罚,工人需要提交一个二元组(Type,Belief),在Judgement Rule模块根据工人做提交的Type判断是奖励还是惩罚,在Reward and Penalty Rule模块根据提交的Belief值决定奖励或者惩罚的金额,基于Type和Belief决定生成最终任务解决方案
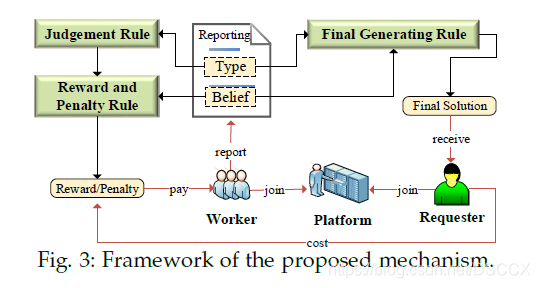
激励机制描述:根据三个模块基于工人提交二元组得出最恰当的reward-penalty函数对,
- Judgement Rule
Type:工人对于任务的解决方式,Yes/No
Belief:工人对所提交的解决方式的信任度
Benchmark solution: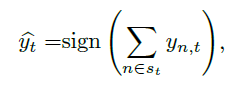
工人提交的Type若与Benchmark solution相等则是奖励,否则是惩罚
- Reward and Penalty Rule
定义Belief值为x,本模块得出Reward-penalty 函数,定义为r(x)以及p(x),二者经过分析得知是x的多项式函数,
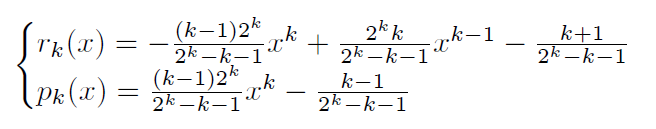
(k表示阶数)
当工人提交数据后平台会根据其不同经验以及专业程度给出一个概率值C,工人提交正确时是C,提交错误率是(1-C),所以可以得到工人的期望收益
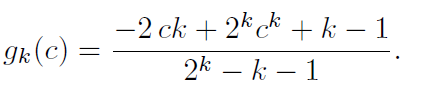
- Final Generating Rule
结合Type和Belief值,得出最终的答案(Yes/No)
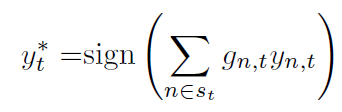
根据对工人提交的report的效用判断得出请求者雇佣表现差的工人的花费并不少于雇佣专业的工人,所以可以起到激励工人好好表现的作用。为了使得奖惩机制生效,平台要求工人提前在平台存入一些钱,这部分钱用于缴纳罚金,当用户退出平台时,平台所剩余的钱还会还给用户。
工人任务的通过率决定他的Personal order value(即k值),Personal order value以及工人提交的Belief值决定工人的r(x)、p(x)以及g(x),工人期望报酬决定最终任务答案,本机制中表现良好的工人可以得高报酬,而通过率低表现差的工人得报酬较低,因此可以吸引专业的工人,挤出并不专业的工人。对于较难的任务,在本机制下,工人提交type和相应的Belief可以获取相应的报酬,提交二元组的不同获取不同数量的报酬,避免了直接跳过的现象。
本文实验数据处理是根据要求生成的数据集,包括工人集合(每个worker的偏离值)、任务集合(Belief、Type)、工人对不同任务的提交数据集合(每个worker对10000个task的type和belief),
本论文所存在的问题:
任务提交类型,本文仅限于Yes/No
安全隐私问题

















 2521
2521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









