




SENet 和 Bilinear 交叉这两种模型用在排序上都有收益。
SENet:
根据所有的特征,自动判断每一个field的特征重要性。对离散特征做field-wise 加权。

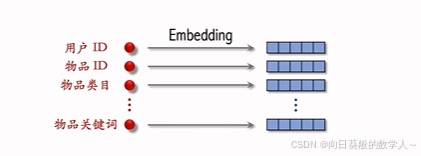
embedding向量维度相同
离散特征的处理:表示成K维的向量,m个特征
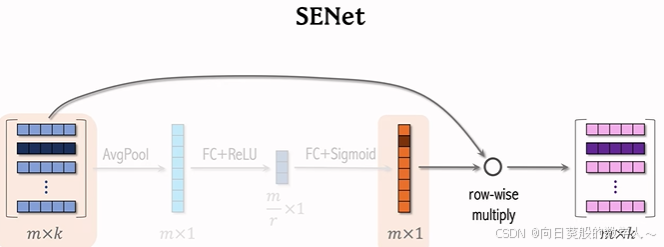
对矩阵的行做avgpooling得到一个向量,向量每个元素对应一个离散特征。
再用一个全连接层和relu激活函数把m维向量压缩成m/r维向量。r是压缩比例,一个大于1的数。
再用一个全连接层和sigmoid函数恢复成m维向量,元素介于0-1之间欸。
把向量成行乘到最初的mxk矩阵上,得到新的矩阵。新矩阵第二行是原矩阵第二行乘以m维向量第二个元素。
中间m维向量的作用就是对特征对加权。
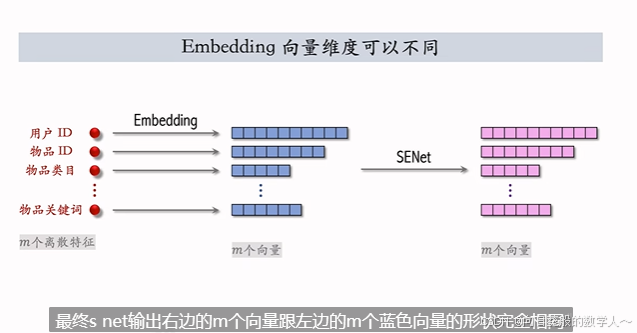
embedding向量维度不同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6485
6485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









