




下载器中间件
在middlewares.py的文件下
class GuaiDownloaderMiddleware(object)下的def process_request(self, request, spider)函数中添加内容
添加cookies
request.cookies = {
"uuid":"d3bdd02f - e0d2 - 4a63 - d0fd - 4100a4c3d963",
"antipas":"s41587E6229ZE29Y363371M1I82",
"cityDomain":"bj",
"clueSourceCode":"10103000312%2300",
"user_city_id":"12", "preTime":"%7B%22last%22%3A1562651840%2C%22this%22%3A1562651840%2C%22pre%22%3A1562651840%7D",
"ganji_uuid":"8536057584891394286262",
"sessionid":"be2b22ee-cca9-4589-848c-01b5977eed31",
"lg":"1",
"cainfo":"%7B%22ca_s%22%3A%22pz_baidu%22%2C%22ca_n%22%3A%"
"22tbmkbturl%22%2C%22ca_medium%22%3A%22-%22%2C%22ca"
"_term%22%3A%22-%22%2C%22ca_content%22%3A%22%22%2C%22ca"
"_campaign%22%3A%22%22%2C%22ca_kw%22%3A%22-%22%2C%22"
"keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22"
"scode%22%3A%2210103000312%22%2C%22ca_transid%22%3A%22%22%2C%"
"22platform%22%3A%221%22%2C%22version%22%3A1%2C%22ca_i%22%3A%22"
"-%22%2C%22ca_b%22%3A%22-%22%2C%22ca_a%22%3A%22-%22%2C%22display"
"_finance_flag%22%3A%22-%22%2C%22client_ab%22%3A%22-%22%2C%22guid"
"%22%3A%22d3bdd02f-e0d2-4a63-d0fd-4100a4c3d963%22%2C%22sessionid%22"
"%3A%22be2b22ee-cca9-4589-848c-01b5977eed31%22%7D"
}
添加headers
request.headers["User-Agent"]="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
添加代理
#配置代理
#class ProxyMiddleware(object):
#def process_request(self,request,spider):
if request.url.startswith("http://"):
request.meta['proxy']="http://"+'172.104.158.20:9999' # http代理
elif request.url.startswith("https://"):
request.meta['proxy']="https://"+'202.120.38.131:80' # https代理
若是自定义中间件则需要在settings中修改
DOWNLOADER_MIDDLEWARES = {
'guazi.mymiddleware.Guazi': 543,
#"项目名.自定义文件名.类名":优先级参数
'guazi.mymiddleware.ProxyMiddleware': 200
}
将控制台日志打印到指定log文件
在settings中加入以下代码
#是否启用日志
LOG_ENABLE = True
#日志文件名称
LOG_FILE = "MyLogName.log"
#日志文件内容编码
LOG_ENCODING = "utf-8"
#日志级别
LOG_LEVEL = "DEBUG"
日志级别介绍(由低到高)
- DEBUG :详细的信息,通常只出现在诊断问题上
- INFO:确认一切按预期运行
- WARNING:一个迹象表明,一些意想不到的事情发生了,或表明一些问题在不久的将来(例如。磁盘空间低”)。这个软件还能按预期工作。
- ERROR:更严重的问题,软件没能执行一些功能
- CRITICAL :一个严重的错误,这表明程序本身可能无法继续运行
注:这5个等级,也分别对应5种打日志的方法: debug 、info 、warning 、error、critical。默认的是WARNING,当在WARNING或之上时才被跟踪。
日志格式说明
logging.basicConfig函数中,可以指定日志的输出格式format,这个参数可以输出很多有用的信息,如下:
%(levelno)s: 打印日志级别的数值
%(levelname)s: 打印日志级别名称
%(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s: 打印当前执行程序名
%(funcName)s: 打印日志的当前函数
%(lineno)d: 打印日志的当前行号
%(asctime)s: 打印日志的时间
%(thread)d: 打印线程ID
%(threadName)s: 打印线程名称
%(process)d: 打印进程ID
%(message)s: 打印日志信息
以上内容参考链接:https://www.jb51.net/article/165167.htm
Python操作MongoDB数据库
1.打开MongoDB数据库
- CMD---->以管理员身份运行
- 进入安装路径bin目录下,如:
C:\Program Files\MongoDB\Server\3.4\bin> - 在bin目录同级目录下创建data/db文件夹
- 命令提示符状态下输入
mongod --dbpath "C:\Program Files\MongoDB\Server\3.4\data\db"注意:一定要在管理员状态下打开命令行窗口,在输入的绝对地址上加引号 - 再以管理员身份打开CMD并在bin目录下输入mongo即可操作该数据库
C:\Program Files\MongoDB\Server\3.4\bin>mongo
2写入
在scrapy工程下的pipelines.py文件下填写代码
class Meiju100Pipeline(object):
def __init__(self):
#创建数据库对象,并输入要连接的数据库主机ip及数据库端口
self.client = pymongo.MongoClient("localhost", 27017)
#连接指定数据库,有则使用,没有则创建并使用
self.db = self.client["MyDBname"]
def process_item(self, item, spider):
#向数据库中插入数据
self.db.vedio.insert(dict(item))
return item
def close_spider(self, spider):
#关闭数据库
self.client.close()
Python操作Redis数据库
1.连接数据库
- CMD打开命令行窗口
- 输入
redis-server开启redis服务 - 再打开一个命令行窗口输入
redis-cli即可操作数据库
2写入
#导入redis需要的包
from redis import Redis
#创建数据库对象
redis = Redis()
#定义数据
url = "https://www.meijutt.com/new100.html"
#将数据写入redis
redis.lpush("MySpider",url)
#查询指定数据库数据
print(redis.lrange("MySpider",0,-1))
Scrapy-redis分布式初步
分布式爬虫优点:
1、充分利用多机器的带宽进行加速的爬取,一台服务器上的带宽有限。
2、充分利用多机器的IP加速爬取的速度,一台服务器如果爬取过快则可能IP会被封。
scrapy-redis架构
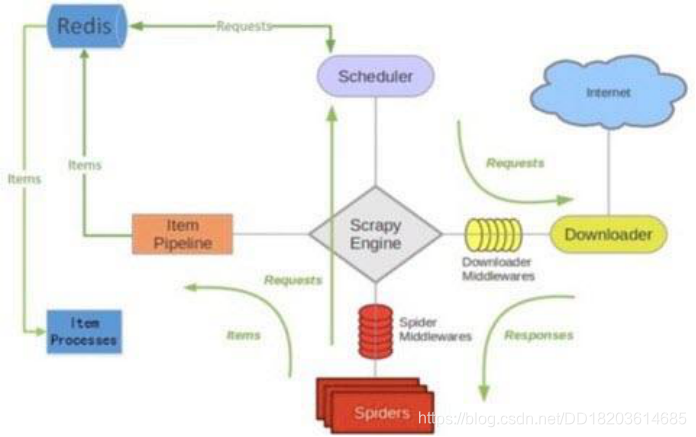
scrapy-redis的总体思路
- 这套组件通过重写scheduler和 spider类,实现了调度、spider启动和redis的交互。
- 实现新的dupefilter和queue类,达到了判重和调度容器和redis 的交互,因为每个主机上的爬虫进程都访问同一个redis数据库, 所以调度和判重都统一进行统一管理,达到了分布式爬虫的目的。
- 当spider被初始化时,同时会初始化一个对应的scheduler对象, 这个调度器对象通过读取settings,配置好自己的调度容器queue 和判重工具dupefilter。
- 每当一个spider产出一个request的时候,scrapy引擎会把这个 reuqest递交给这个spider对应的scheduler对象进行调度, scheduler对象通过访问redis对request进行判重,如果不重复就 把他添加进redis中的调度器队列里。当调度条件满足时,scheduler 对象就从redis的调度器队列中取出一个request发送给spider, 让他爬取。
- 当spider爬取的所有暂时可用url之后,scheduler发现这个spider 对应的redis的调度器队列空了,于是触发信号spider_idle, spider收到这个信号之后,直接连接redis读取start_urls池,拿 去新的一批url入口,然后再次重复上边的工作。
编写分布式爬虫代码
-
创建scrapy项目
-
修改settings文件
调度器重写,去重class替换,解决分布式必须要解决的问题。
在settings文件中加入以下代码
#调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#redis服务器地址
REDIS_HOST = 'localhost'
#redis端口号
REDIS_PORT = 6379
##开启队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
- 编写主程序
#导入scrapy-redis需要的包
from scrapy_redis.spiders import RedisSpider
#()中继承的是的RedisSpider
class MymaoyanSpider(RedisSpider):
#运行时文件的名称
name = 'MySpiderName'
#这个redis_key就是起始url在redis数据库中的键名
redis_key = "**MySpider**"
def parse(self, response):
#对需要的资源进行相关的操作
with open("maoyan.txt","a",encoding="utf-8") as f:
f.write(response.url+"\n")
- 从所需要的url的数据库中拿取url
from redis import Redis
redis = Redis()
for page in range(1,1000):
url = "https://maoyan.com/films?showType=3&offset={}".format(page*30)
#此处的MySpider与从机的redis_key一致
redis.lpush("**MySpide**r",url)
print(url)
注:主机 .py 文件,可以在任何位置 运行,只要是向数据库中写入需要爬取的的url即可
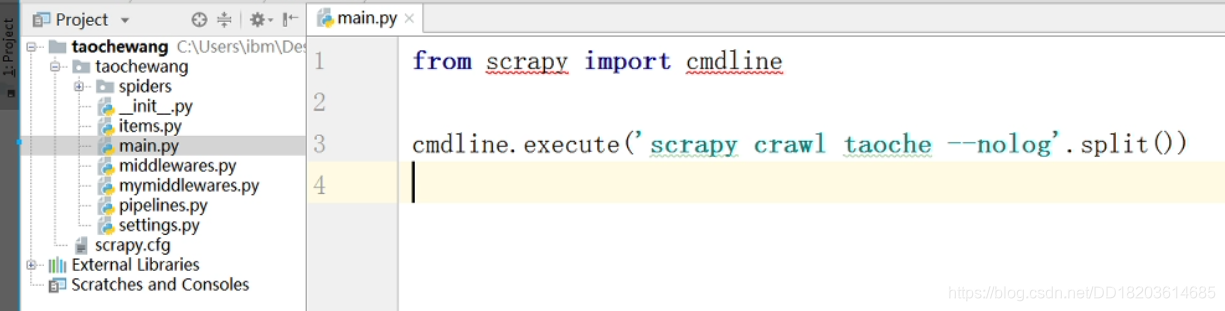
直接运行scrapy框架代码
创建main文件后在main文件中直接写入:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











