



一、背景
业务同学正日益习惯用自然语言直接进行数据分析。然而,随着“听懂”不再是唯一挑战,“问准”成为了新的关键瓶颈。用户一句看似简单的“看下高价值用户的近30天复购率”,背后可能隐藏着多重歧义(如“高价值”定义、“近30天”口径、“复购”统计方式),导致各类数据Agent理解存在偏差
1.1 用户核心痛点
我们以常见的歧义表述“看下高价值用户的近30天复购率”为例,来说明当前流程下用户的核心痛点。
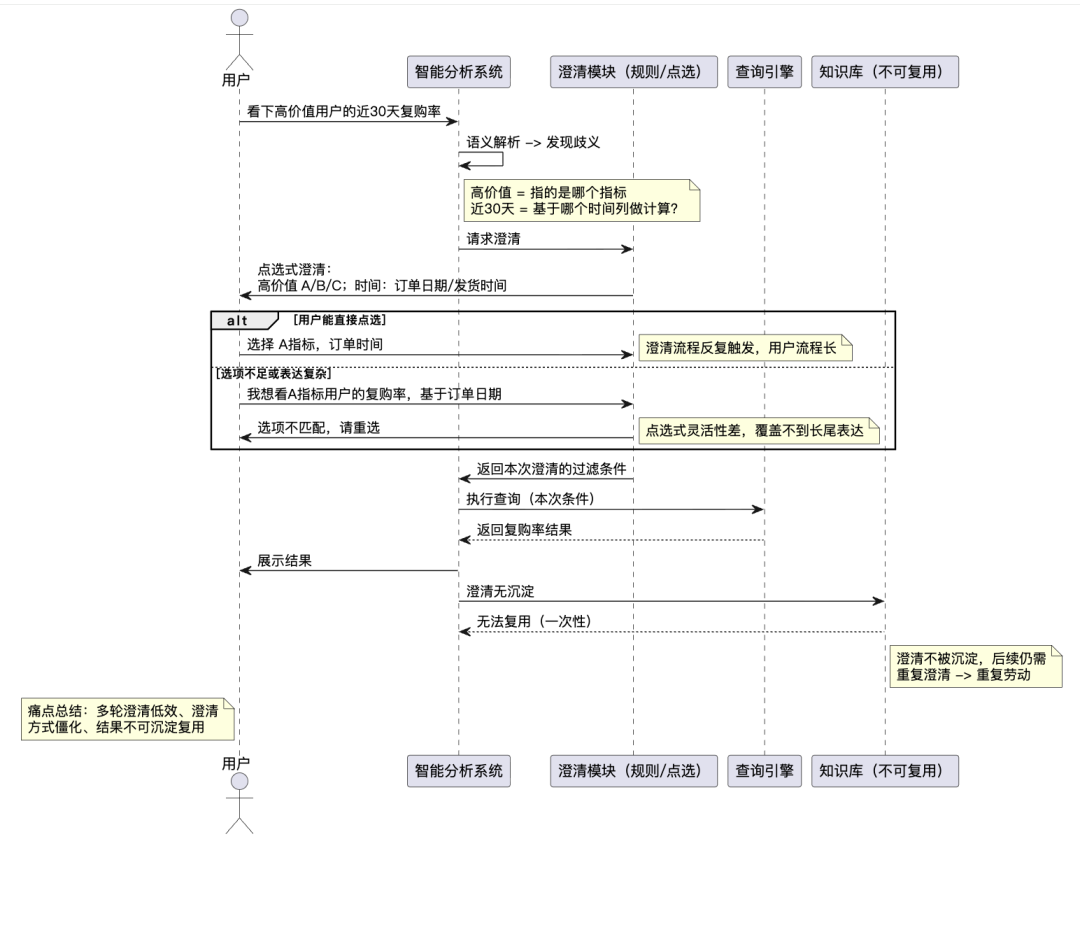
总结:当前自然语言分析产品在解决语义歧义时,普遍存在以下问题,严重阻碍用户体验和效率:

1.歧义识别依赖多轮对话,效率低下:用户初始表达常存在歧义,系统无法精准理解意图,需要用户反复解释澄清,导致沟通成本高、查询流程冗长。
2.澄清方式僵化,准确率与灵活性不足:现有解决方案主要依赖预设规则和点选式选项进行澄清。这种方式识别准确率低,难以覆盖复杂多变的业务语境和长尾表达,灵活性差,无法提供贴合上下文的动态澄清。
3.澄清结果无法沉淀复用,导致重复劳动:每次澄清都是“一次性”的,系统缺乏将用户确认的澄清结果(如特定术语定义、时间口径、用户习惯)沉淀为可复用知识的能力。用户在不同查询中遇到相同歧义时,仍需重复进行澄清操作,体验割裂且低效
1.2 结果与核心诉求
用户被迫去适应系统,需要记忆“系统希望我怎么问”,而非系统理解“我习惯怎么说”。这直接导致了操作繁琐、效率低下和体验中断。让系统真正理解用户的自然表达习惯,实现“问得准、答得对”的流畅体验,正是我们急需解决的核心问题。
二、解决方案:从“能回答”到“会澄清、会记忆、会复用”
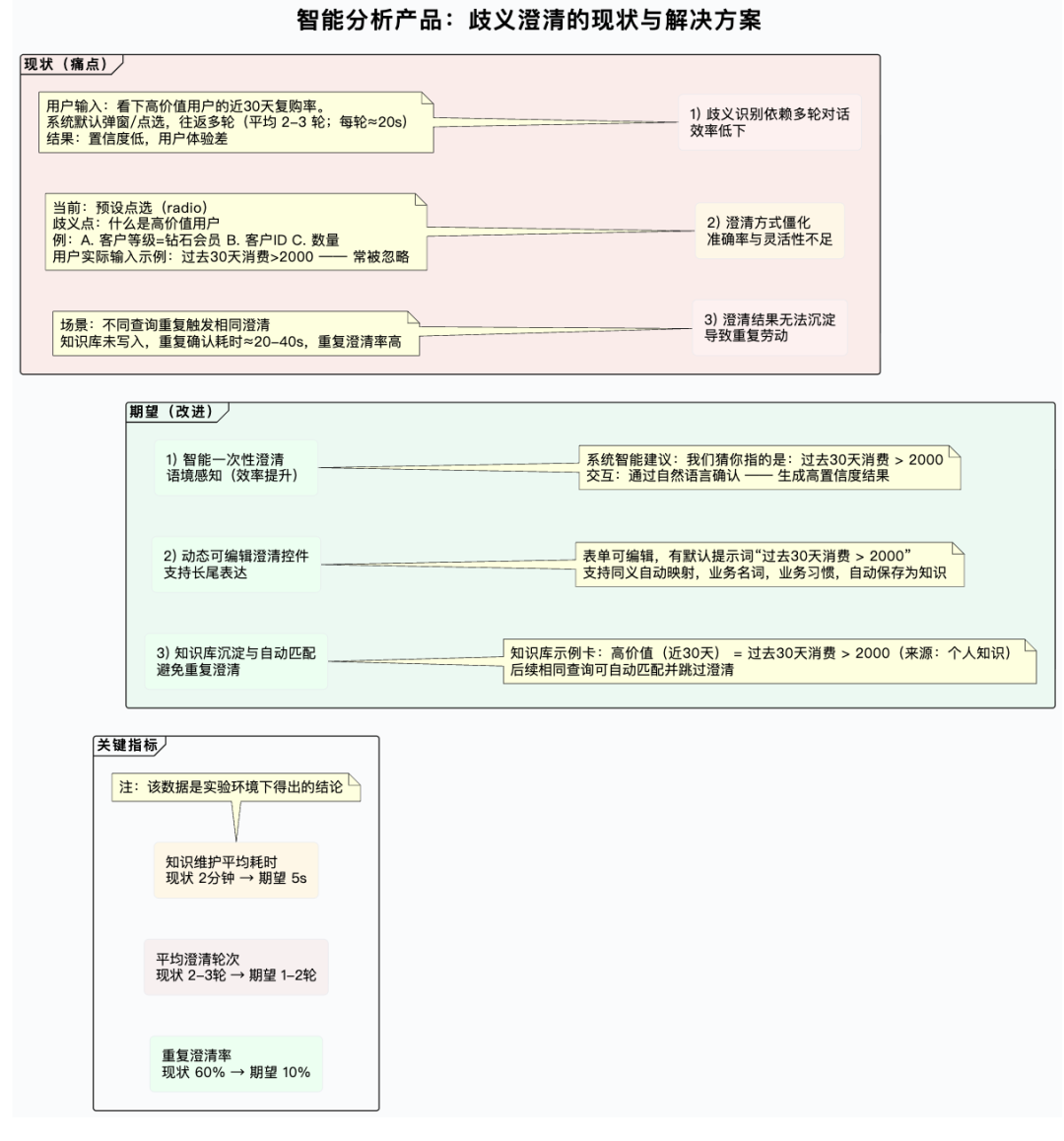
我们构建了“歧义识别—精准澄清—知识沉淀—智能召回”的闭环,实现“一次澄清,长期收益”:
-
智能澄清:当识别出用户输入存在歧义时,系统不再给出含糊的结果或单向提示,而是以最少、最关键的问题进行强制澄清。
1.个人知识沉淀:用户澄清的答案自动转化为结构化知识。当相似歧义再现,系统自动召回应用,无需用户重复解释。
2.公共知识复用:对通用术语(如“高价值用户”、“复购率”),支持标准化定义,形成可继承、可复用的公共知识库。
三、智能消歧与知识沉淀设计
3.1 核心概念
-
二次澄清:当用户输入存在语义歧义时,系统主动触发的补充信息获取机制。它不是“多问一步”的机械追问,而是基于上下文的定制化引导。
-
知识沉淀:识别用户补全的歧义问题,并自动转化为结构化知识,存入个人知识库,供后续查询直接调用。
-
智能召回:在判断是否需要反问时,优先利用已沉淀的知识进行自动消歧,减少无谓交互。
-
个人知识与公共知识:个人知识由用户在互动中自然形成,优先服务个人习惯;公共知识由业务域owner统一维护,保障标准口径的统一。
-
动态示例:根据当前问题与数据上下文实时生成“填空式参考”,把用户引导到关键决策点上,而不是让其在开放式输入里反复试错。

3.2 三大核心能力:识别准,问得少,记得牢
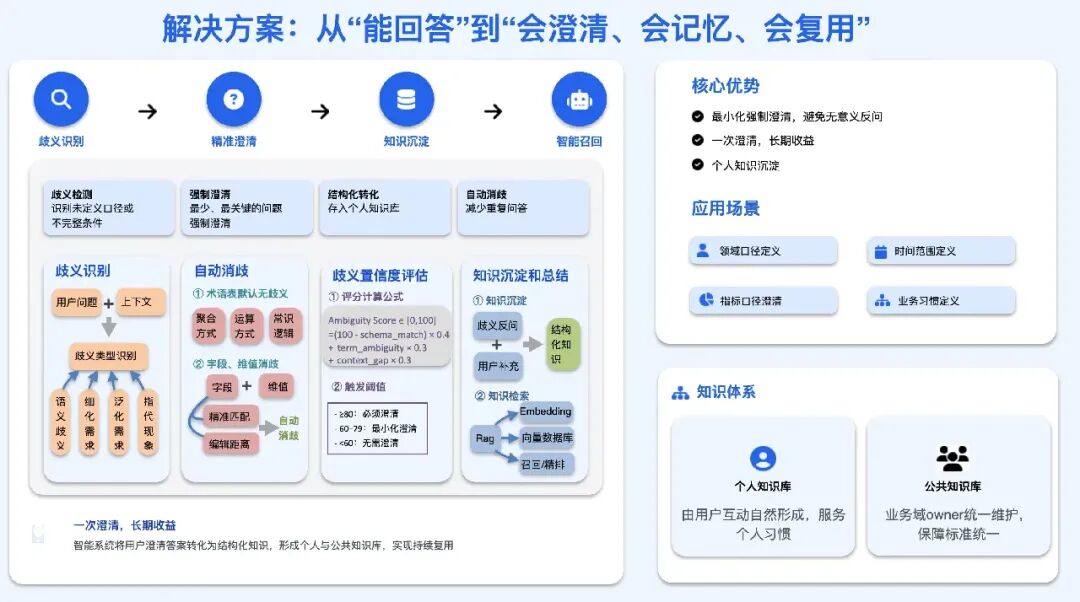
3.2.1 智能歧义识别
-
在自然语言取数场景中,系统不只看关键词,还识别歧义类型,包括语义歧义、细化需求、泛化需求、指代现象等。
-
引入置信度机制:只有当系统对“这一步需要澄清”的判断足够有把握时,才触发澄清,避免过度反问。
-
结合数据表结构与字段分布进行自动消歧:当可通过上下文推断或Schema匹配确定的内容,系统不打扰用户,直接完成消歧。
3.2.2 澄清-沉淀-召回 自闭环
-
每次澄清都不仅为当前问题服务,澄清结果会被总结为知识,自动进入个人知识库。
-
后续对话在相同或相似上下文中,系统优先召回个人知识,实现“问一次、长期生效”。
3.2.3 多粒度知识关联
-
按照个人、公共两类知识进行分层管理,便于在不同使用者、不同业务域之间取得平衡。
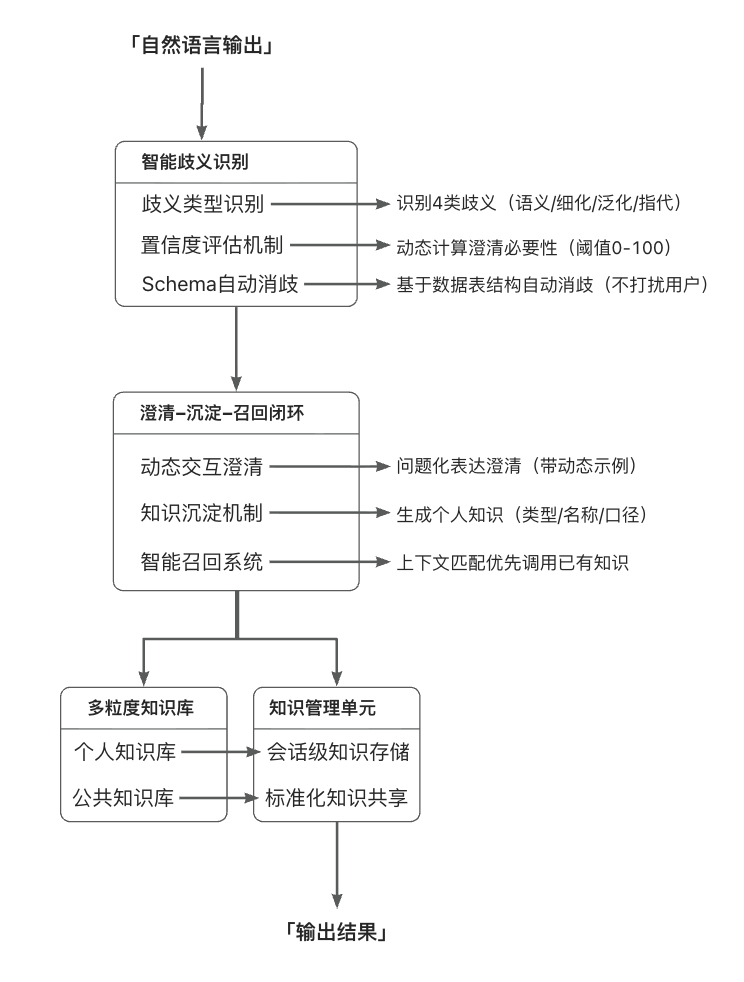
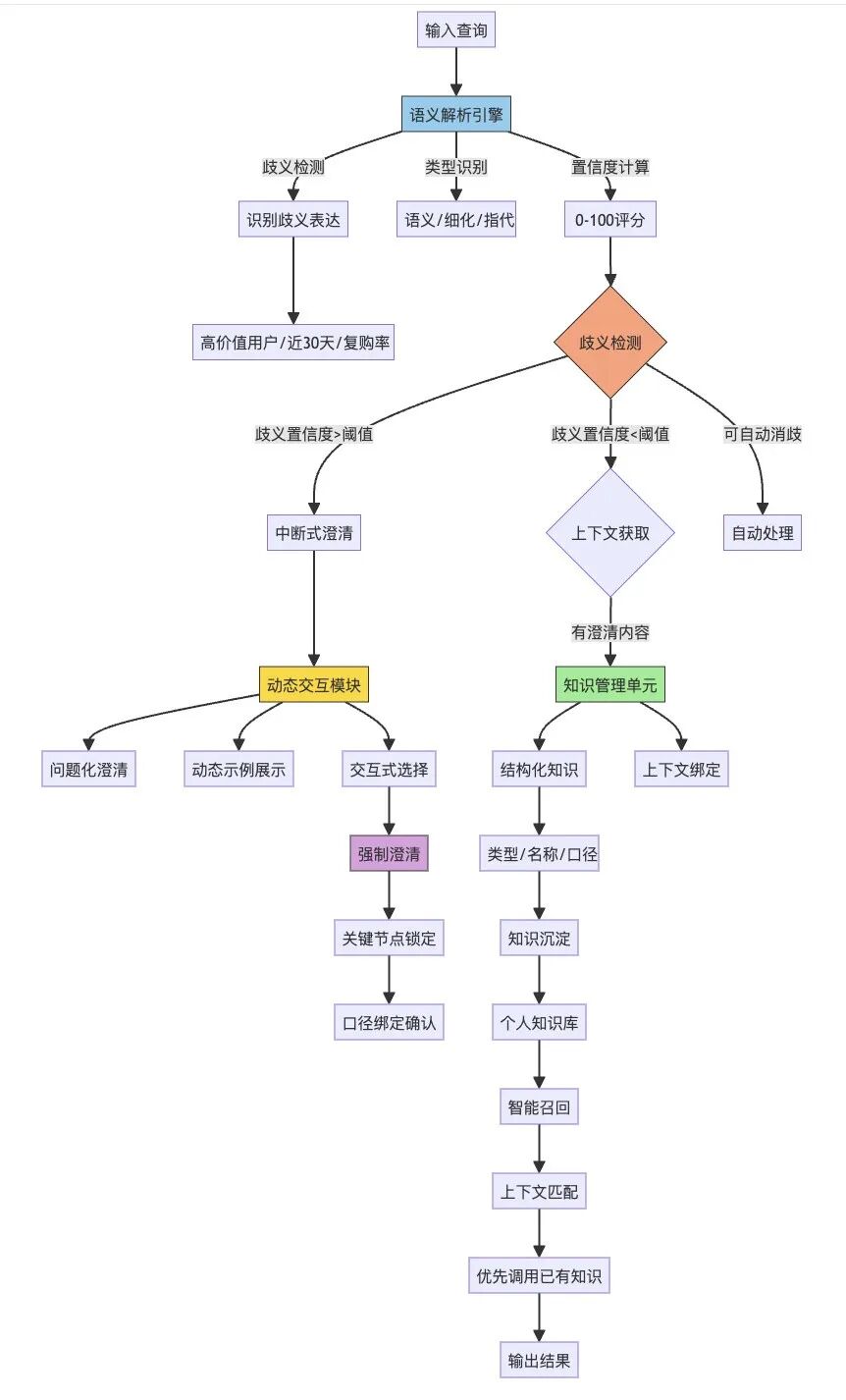
3.3 流程设计
整体由三部分构成:
-
语义解析引擎:实时判断输入的歧义度,识别歧义类型,计算澄清置信度。
-
动态交互模块:当需要澄清时,以问题化的方式呈现关键选项,并提供动态示例作为参考。
-
知识管理单元:把澄清结果转换为结构化知识(包括类型、知识名称、口径等),与查询上下文绑定,并提供可视化标识与编辑入口。
主要流程如下:
-
歧义检测:识别比如“高价值用户”“近30天”“复购率”中的未定义口径或不完整条件。
-
澄清决策:基于置信度阈值判断是否需要中断式澄清;当存在可自动消歧的条件时,优先自动完成。
-
强制澄清:对关键节点进行一次性澄清,确保后续查询在正确口径上进行。
-
知识沉淀:系统将本次澄清总结为规则,写入个人知识库;当满足标准化条件时,可建议升级为公共知识。
-
智能召回:新的查询触发同类歧义点时,优先引用既有知识,避免重复问答。
3.3.1 系统流程
3.3.2 用户交互示例
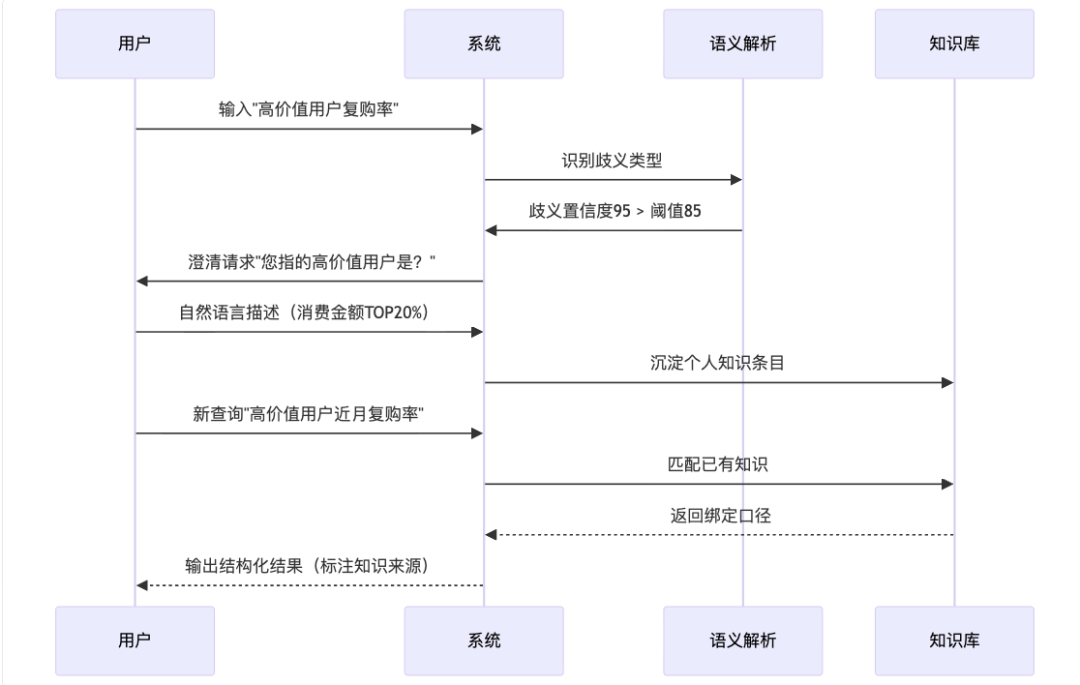
3.4 澄清体验优化:问的清、答得快、不打断思路
我们在交互上坚持两个原则:少而准、轻而快。
-
单条知识场景:直接给出动态示例。如用户输入“最近下单的客户”,系统会展示“最近=近7天/近30天/自定义”等提示,并展示示例口径,帮助快速确定。
-
多条知识场景:按优先级逐一提示关键字段。例如先确定时间范围,再确认歧义筛选或指标,确保每一步都围绕“最影响结果正确性”的信息展开。
-
多任务处理:当多个子问题存在依赖关系时,只在根任务触发澄清;对于多个独立歧义点,合并成单次澄清流完成,避免用户被“拉扯式”问答打断
3.5 产品效果
在我们的实验环境下:
-
澄清准确率达到88%,显著减少“问错方向”的情况。
-
单个歧义问题从人工识别、配置知识规则的5-10分钟,缩短为秒级响应,效率提升超过90%。
-
复杂场景交互轮次减少50-67%(2-3轮降到1轮);复杂歧义场景减少60-67%(3-5轮降到1-2轮)。
3.6 典型应用场景:把“业务语言”变成“可计算的知识”
3.6.1 用户分层
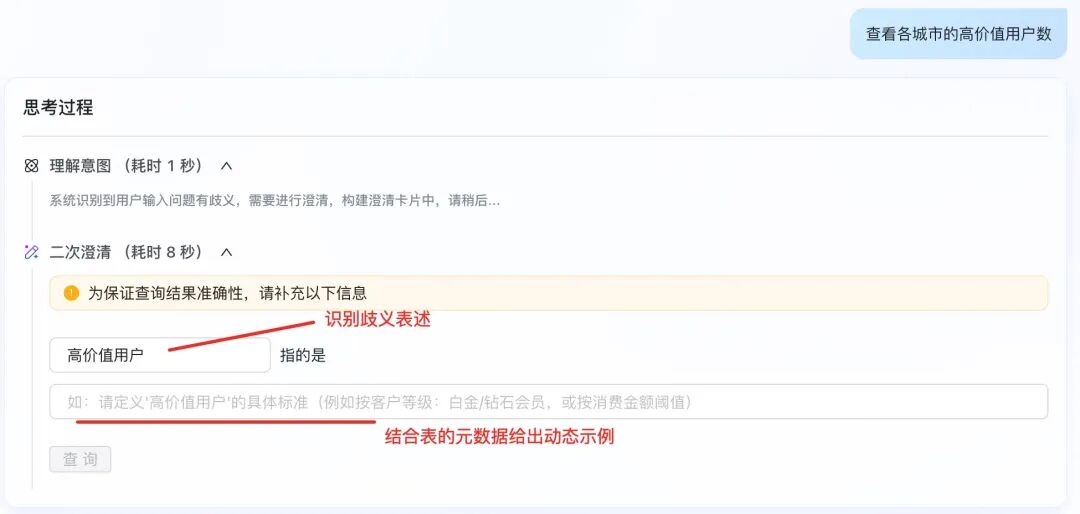
不同团队对“高价值用户”的定义不同,有的看近90天客单价,有的看最近三次订单总额。系统在首次识别到该歧义时引导澄清,随后在该业务主题下自动复用,避免重复解释。
3.6.1.1 识别用户歧义问题
3.6.1.2 用户澄清后,知识自动沉淀并通过多轮对话完成取数
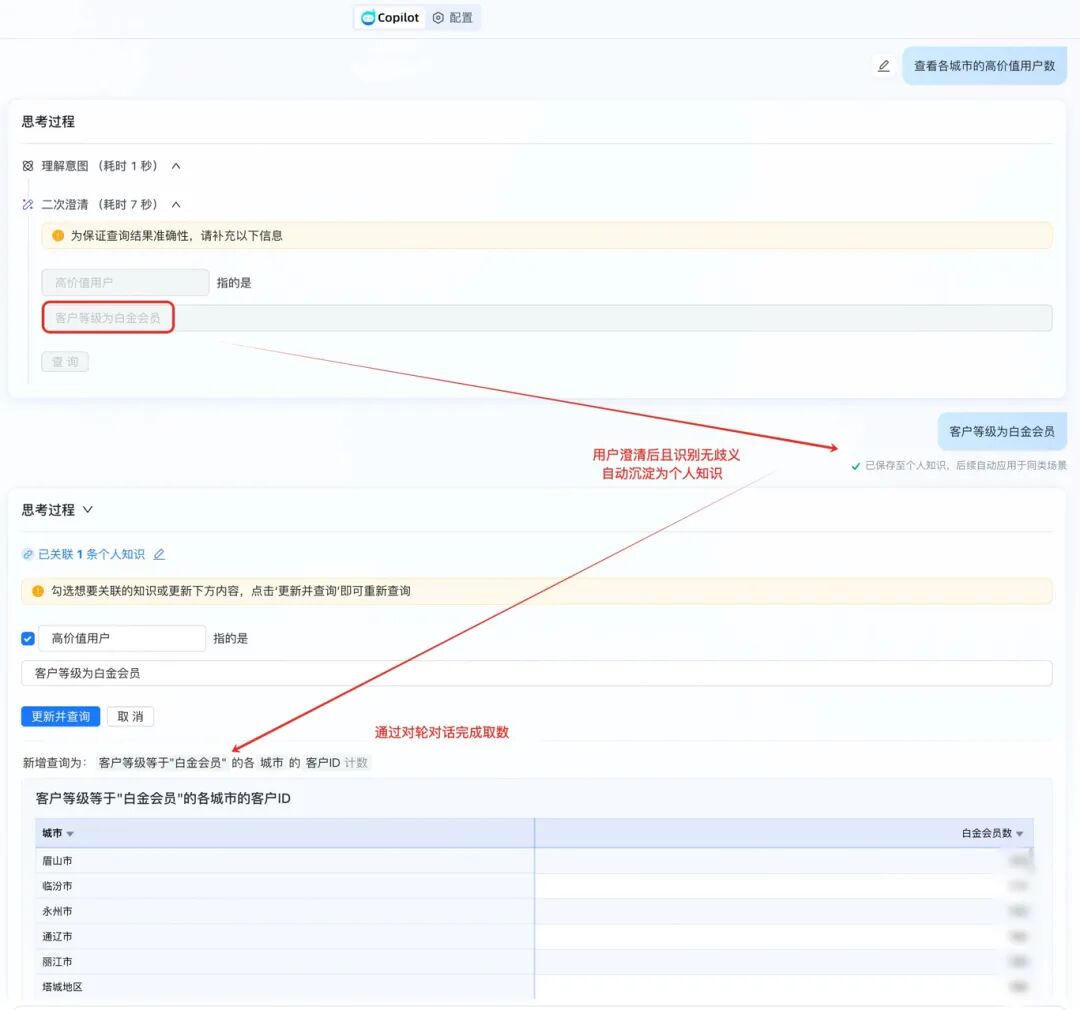
3.6.1.3. 用户澄清后,知识自动沉淀并通过多轮对话完成取数
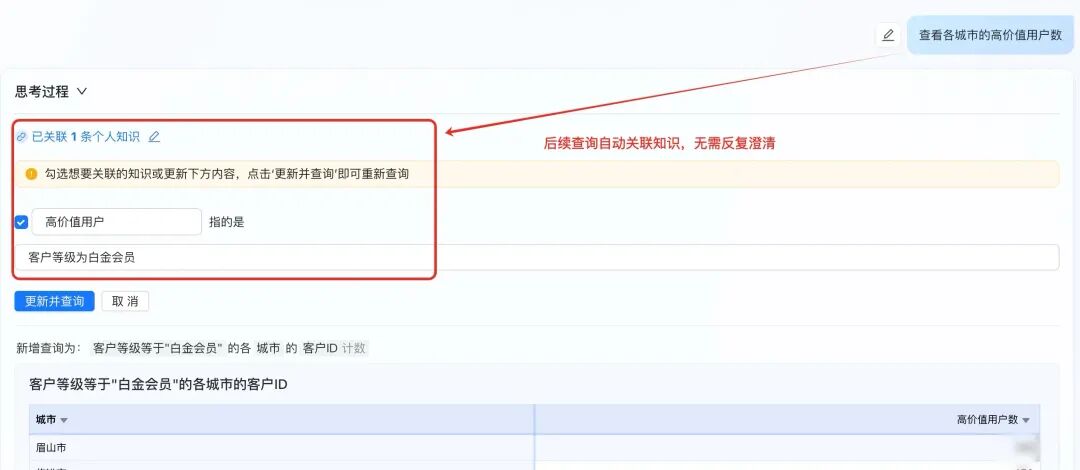
3.6.1.4 后续也可以继续维护个人知识
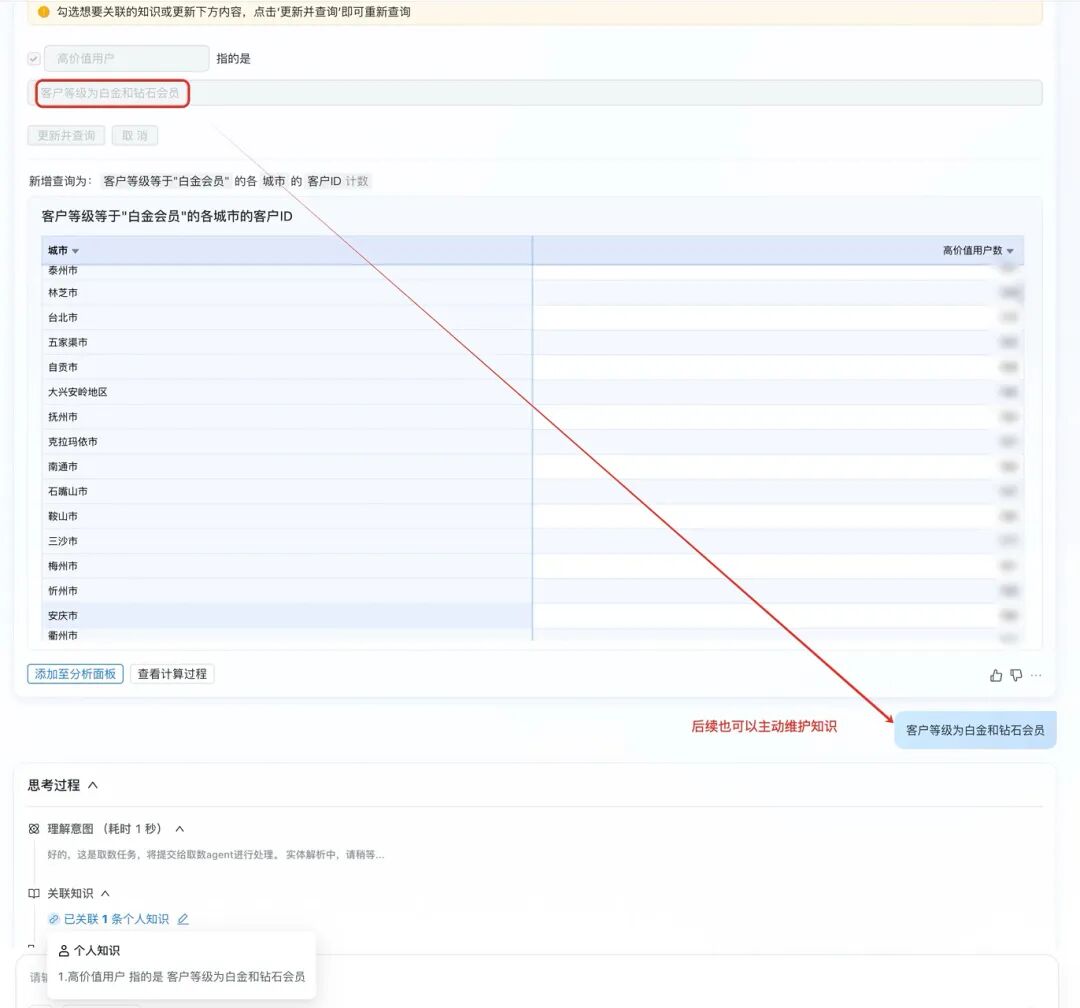
3.6.2 时间口径
-
近7天、近30天、结算周期等口径复杂;系统基于历史选择与公共规则优先级,自动给出贴合上下文的建议,并在必要时强制澄清确认。
-
示例略,同3.6.1
3.6.3 指标口径
-
复购率是按“下单数/用户数”还是“复购用户/活跃用户”?系统将澄清的指标计算方式做成知识条目,与该指标、该主题绑定。
-
示例略,同3.6.1
3.6.4 指代消解
-
当用户说“看这个客户的趋势”,系统结合上下文推断“这个”指代的是上一条查询中的客户群或具体实体,尽量消除重复选择。
-
示例略,同3.6.1
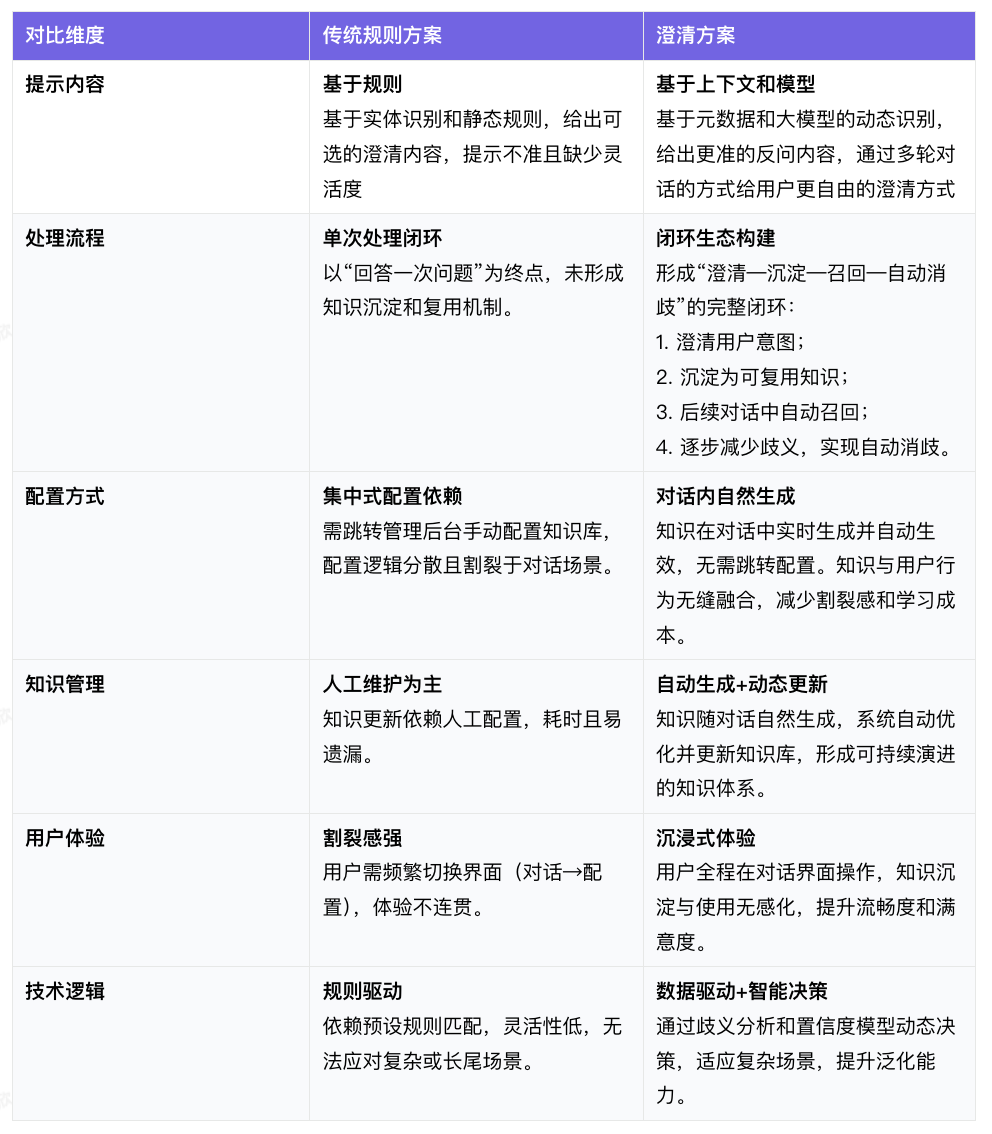
3.7 与传统澄清方案的区别
3.8 核心算法方法
3.8.1 歧义类型识别
-
面向ChatBI场景,系统将歧义归类为语义歧义、细化需求、泛化需求、指代现象等,以便采用不同策略处置。
技术实现:
1.LLM时代之前,大多使用标注数据进行训练微调,以在提供模糊问题作为输入的情况下,生成澄清问题
a.基于知识的澄清问题生成,将实体文本和当前问题串起来作为模型的输入
2.后LLM时代的最新研究越来越多的关注LLM提示方法,如少样本提示、思维链
本文的主要工作是,将歧义的分类整合到CoT推理中,扩展现有的用于生成澄清LLM提示的研究方法。
以往用于分析目的的歧义类型分类法
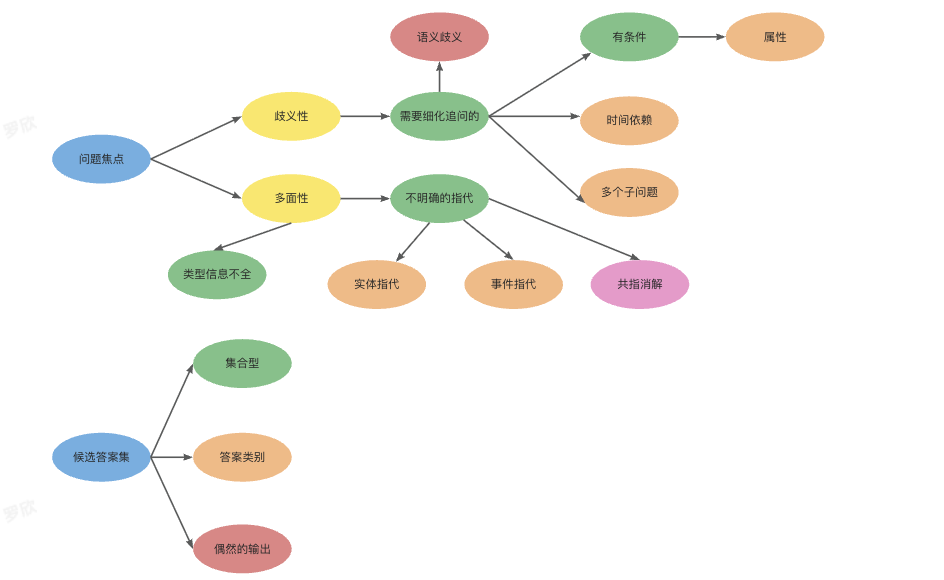
本方案的分类法
与以往的分类法相比,现有的优势在于:a. 现有的分类标准大多是在LLM时代之前提出的,不适用于LLM提示方法。b. 现有的优势在于它的双重功能:每个类型不仅可以帮助LLM理解潜在的歧义,还可以很容易的解释为LLM应该采取的行动。

3.8.2 置信度机制
-
通过多维信号构建置信度,仅在高置信度下触发澄清;对低置信度场景,优先给出不打断的提示或自动消歧建议。
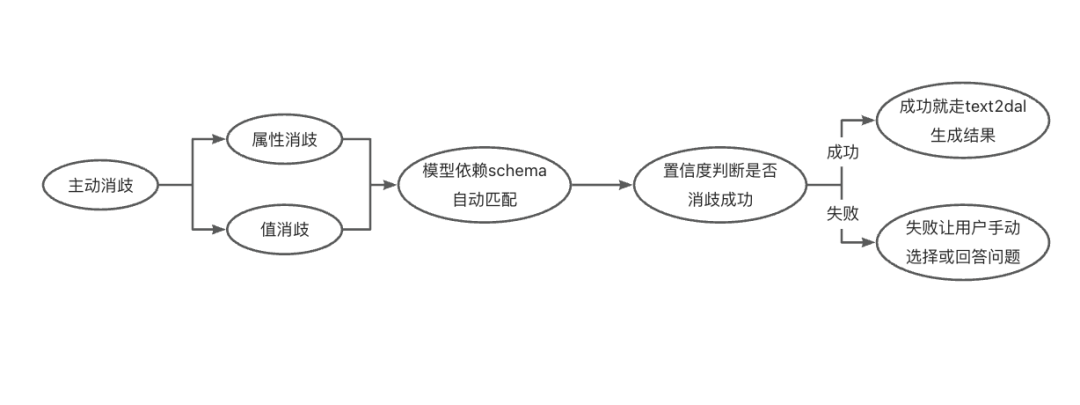
3.8.3 主动消歧
- 基于Schema匹配与上下文线索,通过编辑距离算法来校验相似度,当存在明显的字段-值对应或唯一选择时自动完成,避免无意义的反问。
3.8.4 知识捕获
-
将用户的澄清输入抽取为结构化规则,记录类型、知识关键字、口径,通过向量检索保障后续召回的准确性。
四、未来方向
-
知识粒度更细:支持更多类型的知识条目(比如度量、计算列等)与更丰富的上下文绑定方式。
-
团队级知识运营:当个人知识广泛被团队使用时,可平滑升级为公共知识,统一口径、保留版本记录,并允许个体在不影响公共口径的前提下覆盖个人偏好。
-
可视化知识管理:提供更直观的知识关系图谱与影响范围评估,帮助治理者评估变更带来的影响。
-
跨场景复用:把在分析场景中沉淀的知识,延伸到报表构建、告警订阅等更多工作流中。

















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









