




 本文详细介绍了Spark在大数据计算领域的应用,特别是在DataMagic平台中的实践。作者分享了如何快速掌握Spark,包括理解关键术语、配置、并行计算和代码优化。在DataMagic平台,Spark用于日志分析,每天处理的数据量达到了千亿到万亿级别。文章还讨论了快速部署、资源配置、动态调整Executor、异常处理和集群管理等关键点。
本文详细介绍了Spark在大数据计算领域的应用,特别是在DataMagic平台中的实践。作者分享了如何快速掌握Spark,包括理解关键术语、配置、并行计算和代码优化。在DataMagic平台,Spark用于日志分析,每天处理的数据量达到了千亿到万亿级别。文章还讨论了快速部署、资源配置、动态调整Executor、异常处理和集群管理等关键点。
原文链接:https://blog.youkuaiyun.com/D55dffdh/article/details/82423831
本文主要是通过作者在搭建使用计算平台的过程中,写出对于Spark的理解,并且介绍了Spark在当前的DataMagic是如何使用的,当前平台已经用于架平离线分析,每天计算分析的数据量已经达到千亿~万亿级别。
一、前言
Spark作为大数据计算引擎,凭借其快速、稳定、简易等特点,快速的占领了大数据计算的领域。本文主要为作者在搭建使用计算平台的过程中,对于Spark的理解,希望能给读者一些学习的思路。文章内容为介绍Spark在DataMagic平台扮演的角色、如何快速掌握Spark以及DataMagic平台是如何使用好Spark的。
二、Spark在DataMagic平台中的角色
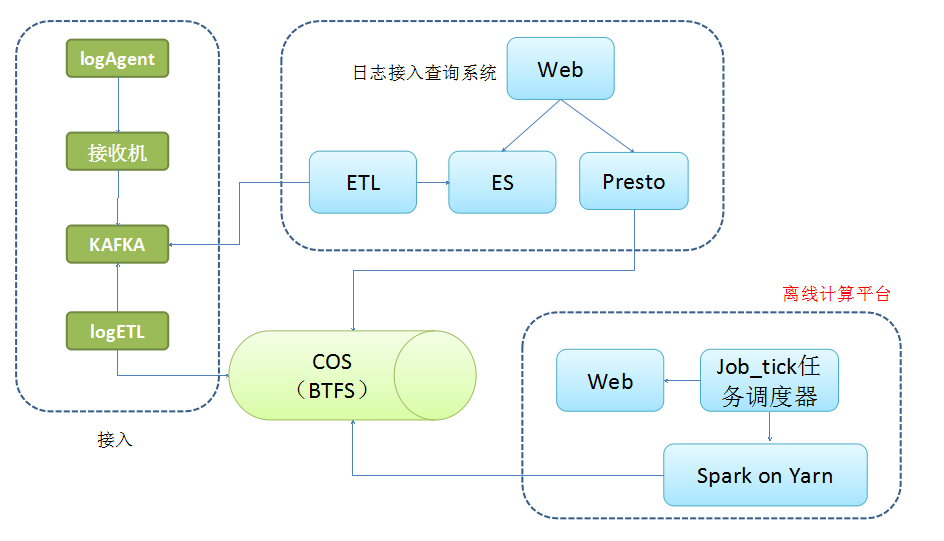
图 2-1
整套架构的主要功能为日志接入、查询(实时和离线)、计算。离线计算平台主要负责计算这一部分,系统的存储用的是COS(公司内部存储),而非HDFS。
下面将主要介绍Spark on Yarn这一架构,抽取出来即图2-2所示,可以看到Spark on yarn的运行流程。
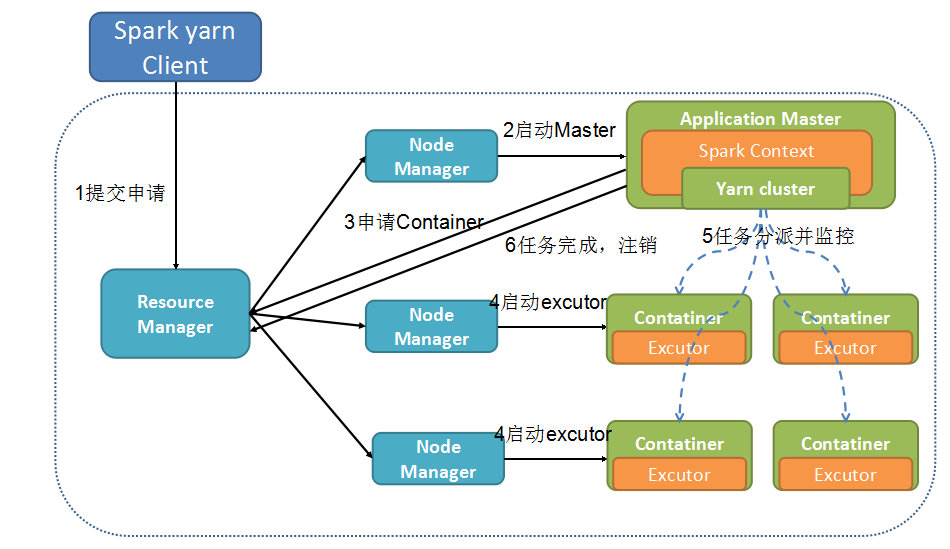
图2-2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2977
2977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









