




 本文详细介绍了AlphaGo和AlphaZero的工作原理和技术细节,包括输入编码、训练流程、模仿学习、策略网络训练、价值网络训练及蒙特卡洛树搜索算法等。同时提供了策略网络和状态价值网络的具体实现代码。
本文详细介绍了AlphaGo和AlphaZero的工作原理和技术细节,包括输入编码、训练流程、模仿学习、策略网络训练、价值网络训练及蒙特卡洛树搜索算法等。同时提供了策略网络和状态价值网络的具体实现代码。
强化学习(五)—— AlphaGo与Alpha Zero
1. AlphaGo
1.1 论文链接
1.2 输入编码(State)
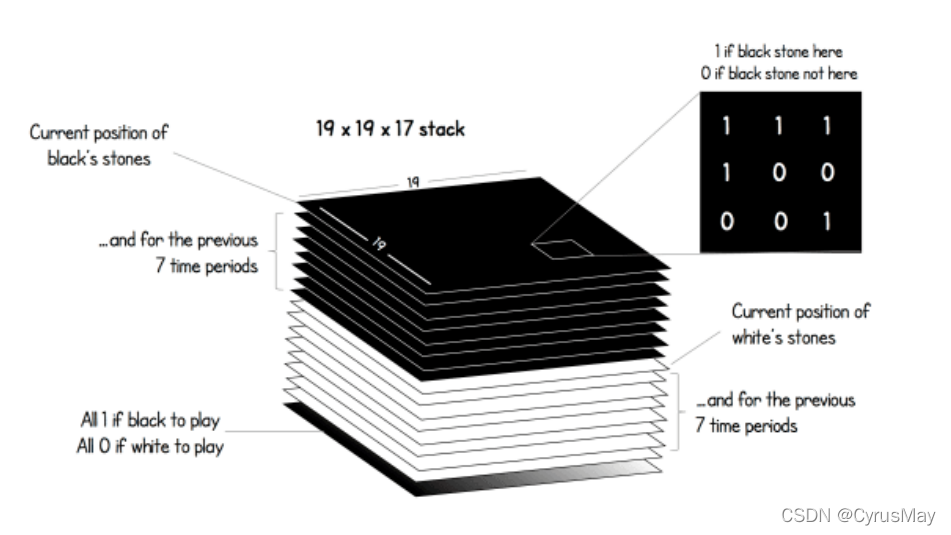
- 棋盘大小:[19,19]的矩阵, 落子则为1,反之为0。
- Input Shape:[19,19,17]。
- 白棋当前状态及其过去7步的状态:[19,19,1]与[19,19,7]。
- 黑棋当前状态及其过去7步的状态:[19,19,1]与[19,19,7]。
- 当前到谁落子:[19,19,1] (黑棋全为1,白棋全为0)
1.3 训练及评估流程
- 使用behavior cloning 对策略网络进行初步训练;
- 两个策略网络互相对弈,并使用策略梯度对策略网络进行更新;
- 使用策略网络去训练状态价值网络;
- 基于策略网络和价值网络,使用蒙特卡洛树(Monte Carlo Tree Search, MCTS)进行搜索。
1.4 模仿学习(Behavior Cloning)
通过Behavior Cloning从人的经验中初始化策略网络的参数,策略网络的结构为: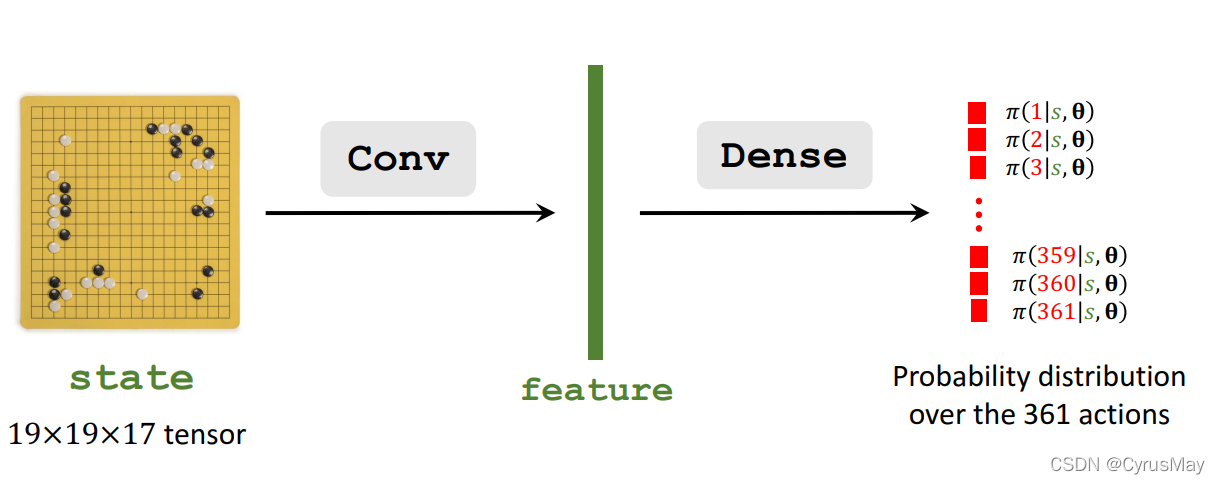
随机初始化网络参数后,基于人类对弈的落子序列数据,进行模仿学习(分类任务),使用交叉熵作为损失函数进行参数更新:
- 观测得到状态: s t s_t st
- 使用策略网络进行预测 p t = [ π ( 1 ∣ s t ; θ ) , π ( 2 ∣ s t ; θ ) , . . . , π ( 361 ∣ s t ; θ ) ] p_t=[\pi(1|s_t;\theta),\pi(2|s_t;\theta),...,\pi(361|s_t;\theta)] pt=[π(1∣st;θ),π(2∣st;θ),...,π(361∣st;θ)]
- 高级人类玩家采取的动作为 a t ∗ a_t^* at∗
- 策略网络的预测进行one-hot编码后,和人类玩家的动作进行交叉熵计算,并更新网络参数。
模仿学习可认为是循规蹈矩。
1.5 策略网络依据策略梯度进行学习

- 两个策略网络进行对弈直到游戏结束。Player V.S. Opponent,Player 使用策略网络最新的参数,Opponent随机选用过去迭代中的网络参数。
- 得到对弈的序列数据: s 1 , a 1 , s 2 , a 2 , s 3 , a 3 , . . . , s T , a T s_1,a_1,s_2,a_2,s_3,a_3,...,s_T,a_T s1,a1,s2,a2,s3,a3,...,sT,aT
- Player获得的回报为: u 1 = u 2 = u 3 = u T ( 赢 了 为 1 , 输 了 为 − 1 ) u_1=u_2=u_3=u_T(赢了为1,输了为-1) u1=u2=u3=uT(赢了为1,输了为−1)
- 近似策略梯度(连加) g θ = ∑ t = 1 T ∂ l o g ( π ( ⋅ ∣ s t ; θ ) ) ∂ θ ⋅ u t g_\theta=\sum_{t=1}^T \frac{\partial log(\pi(\cdot|s_t;\theta))}{\partial\theta}\cdot u_t gθ=t=1∑T∂θ∂log(π(⋅∣st;θ))⋅ut
- 参数更新 θ ← θ + β ⋅ g θ \theta\gets\theta+\beta\cdot g_{\theta} θ←θ+β⋅gθ
1.6 价值网络训练
- 状态价值函数: V π ( S ) = E ( U t ∣ S t = s ) U t = 1 ( w i n ) U t = − 1 ( f a i l ) V_\pi(S)=E(U_t|S_t=s)\\U_t=1(win)\\U_t=-1(fail) Vπ(S)=E(Ut
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2239
2239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









