



前言
最近参加了 Datawhale AI 夏令营第二期,主题是"让AI学会数学推理"的模型蒸馏实践。通过科大讯飞的星辰 MaaS 平台,完成了从跑通 Baseline 到模型优化的完整流程。整个过程收获颇丰,特此记录分享。
项目背景
本次夏令营聚焦在「基于CoT范式的DeepSeek模型蒸馏驱动数学推理解题优化挑战赛」的模型优化实践。主要目标是:
- 通过星辰 MaaS 平台使用 DeepSeek 模型生成高质量推理数据
- 通过星辰 MaaS 平台完成微调实践
- 掌握将大型模型的知识迁移至小型模型的方法,提升模型的准确性与部署效率
整个学习过程分为三个 Task:
Task1: 跑通 Baseline,体验「让AI学会数学推理」
Task2: 学习「让AI学会数学推理」的重难点
Task3: 学习并持续实践大模型推理,上分
Task1:跑通 Baseline 流程
1.1 环境准备与数据集
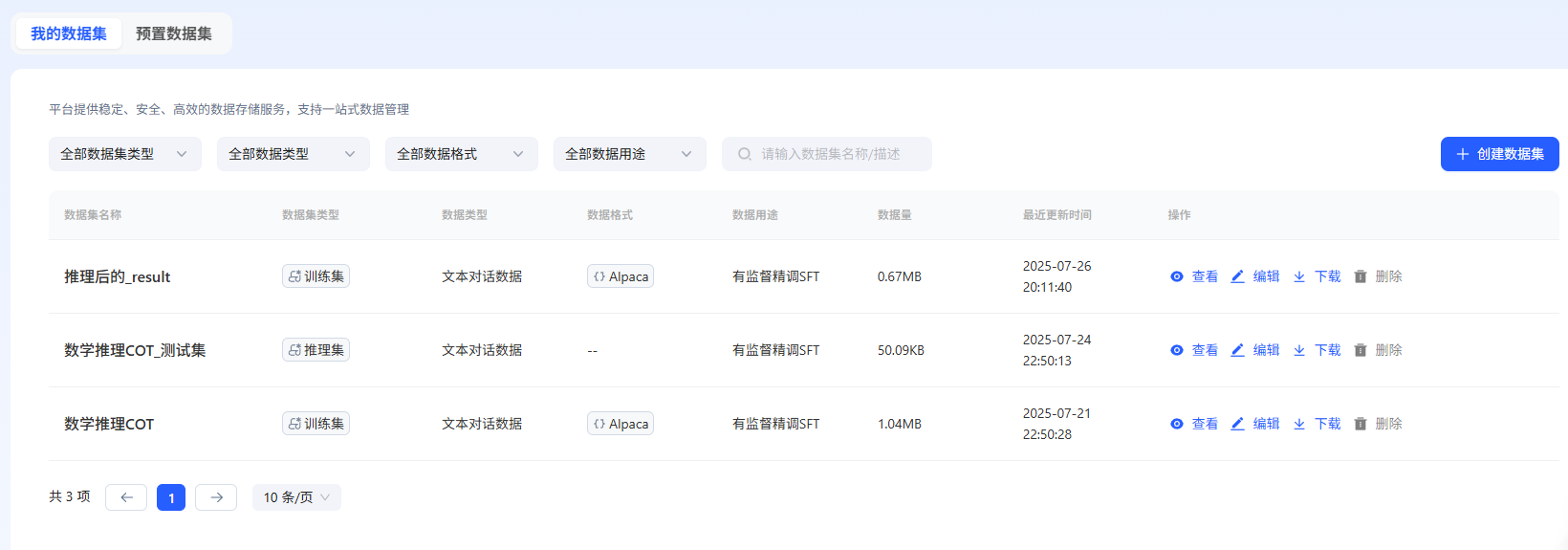
首先需要完成比赛报名,然后下载官方提供的微调数据集。初始的 Baseline 数据集包含 200 条数据,文件大小为1.04MB,格式为 JSONL。
数据集的结构采用 Alpaca 格式:
instruction:数学问题文本
output:包含完整 CoT 推理链的解答过程
1.2 模型选择与配置
在星辰 MaaS 平台上,必须选择 DeepSeek-R1-Distill-Qwen-7B 模型进行微调。这一点在教程中被反复强调,选错模型会不符合题目要求。
创建数据集时需要注意数据映射配置:
prompt 字段映射到:instruction
response 字段映射到:output
1.3 初始模型训练参数
第一次训练使用的参数配置如下:
| 任务类型 | 零代码精调 |
|---|---|
| 训练方法 | LoRA精调 |
| 学习率 | 1e-4 |
| 训练次数 | 3 |
| 输入序列分词后的最大长度 | 2048 |
| 数值精度 | auto |
| LoRA作用模块 | all |
| LoRA秩 | 8 |
| LoRA随机丢弃 | 0.1 |
| LoRA缩放系数 | 16 |
1.4 模型发布与提交
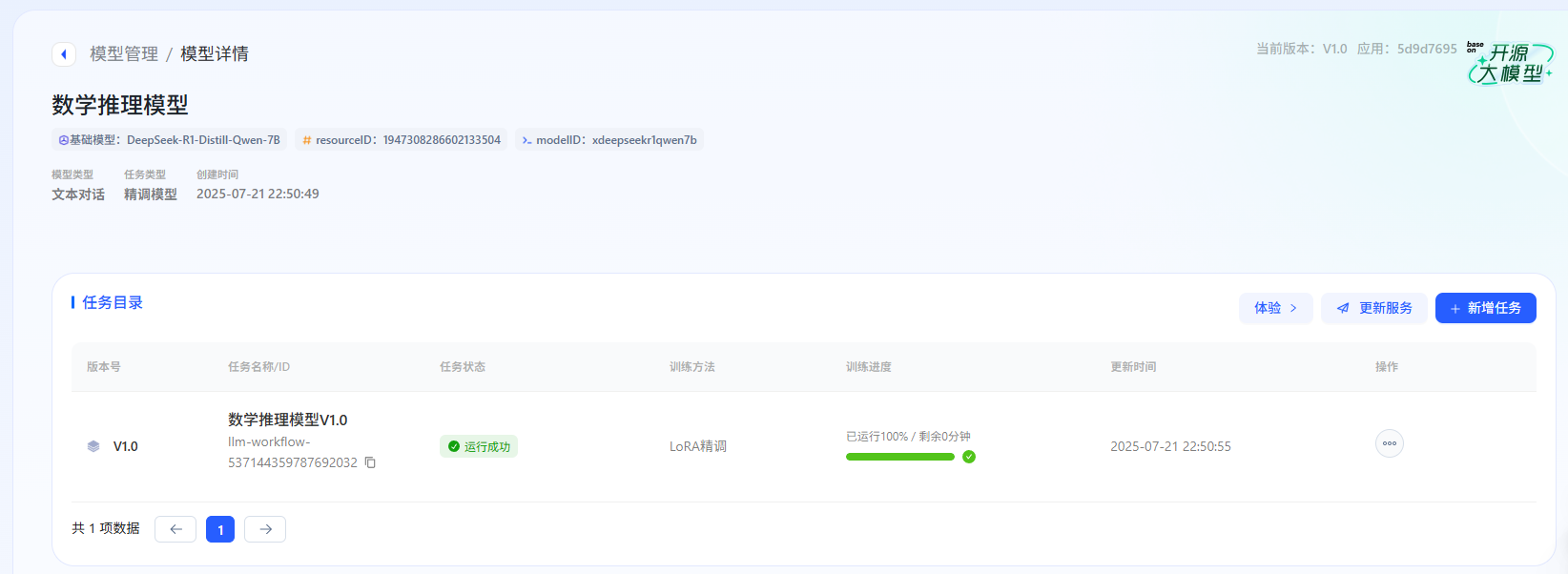
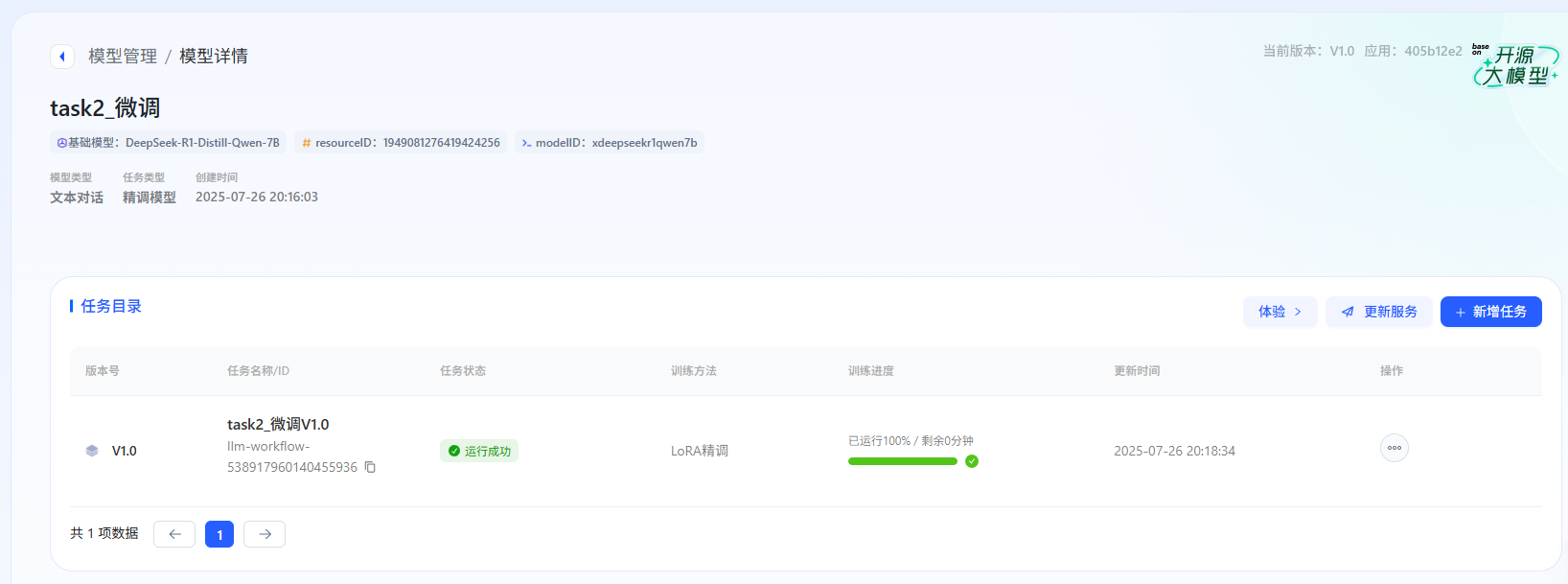
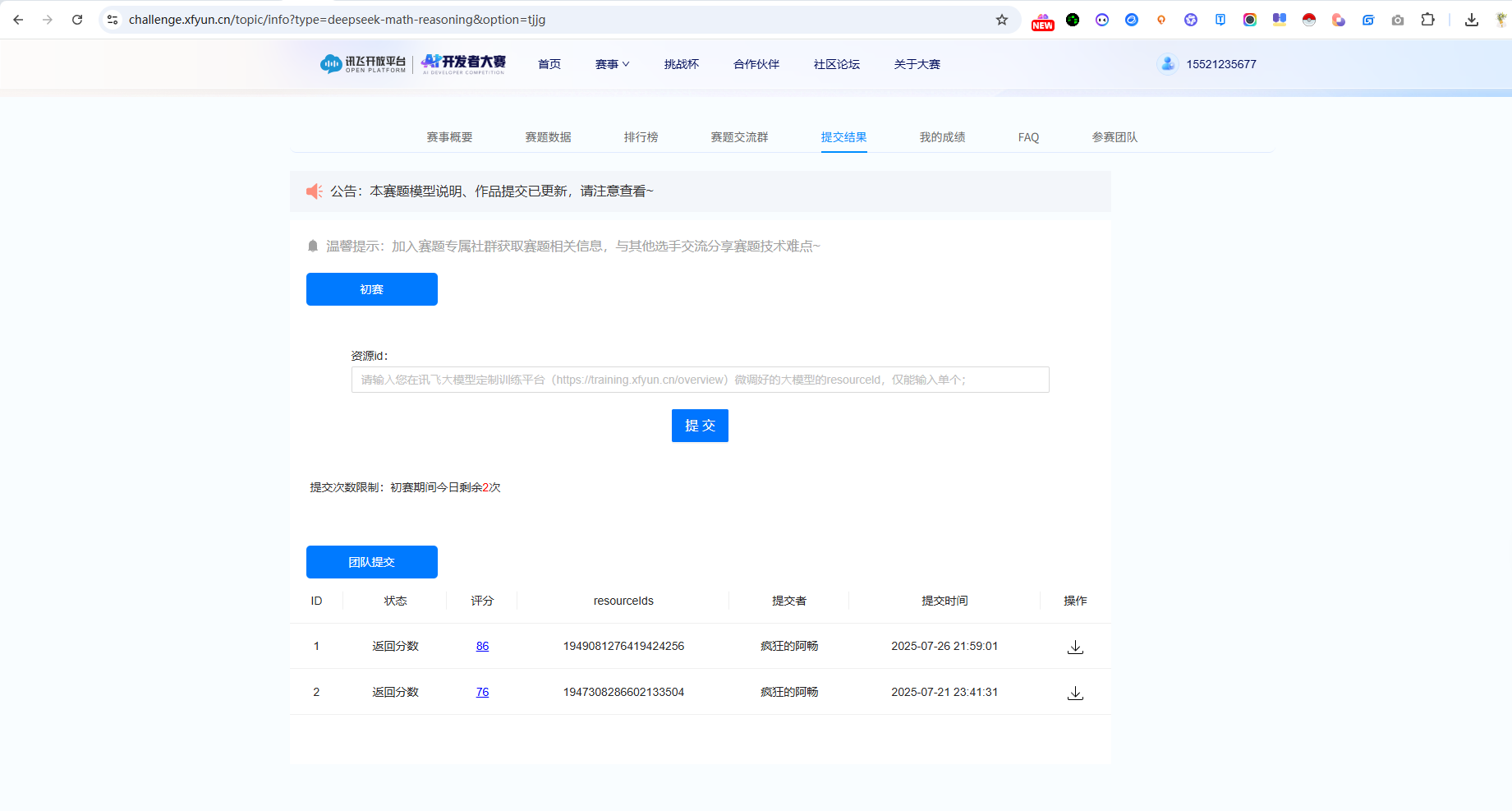
训练完成后,需要点击"发布为服务",获取 resourceId,然后在比赛平台提交结果。
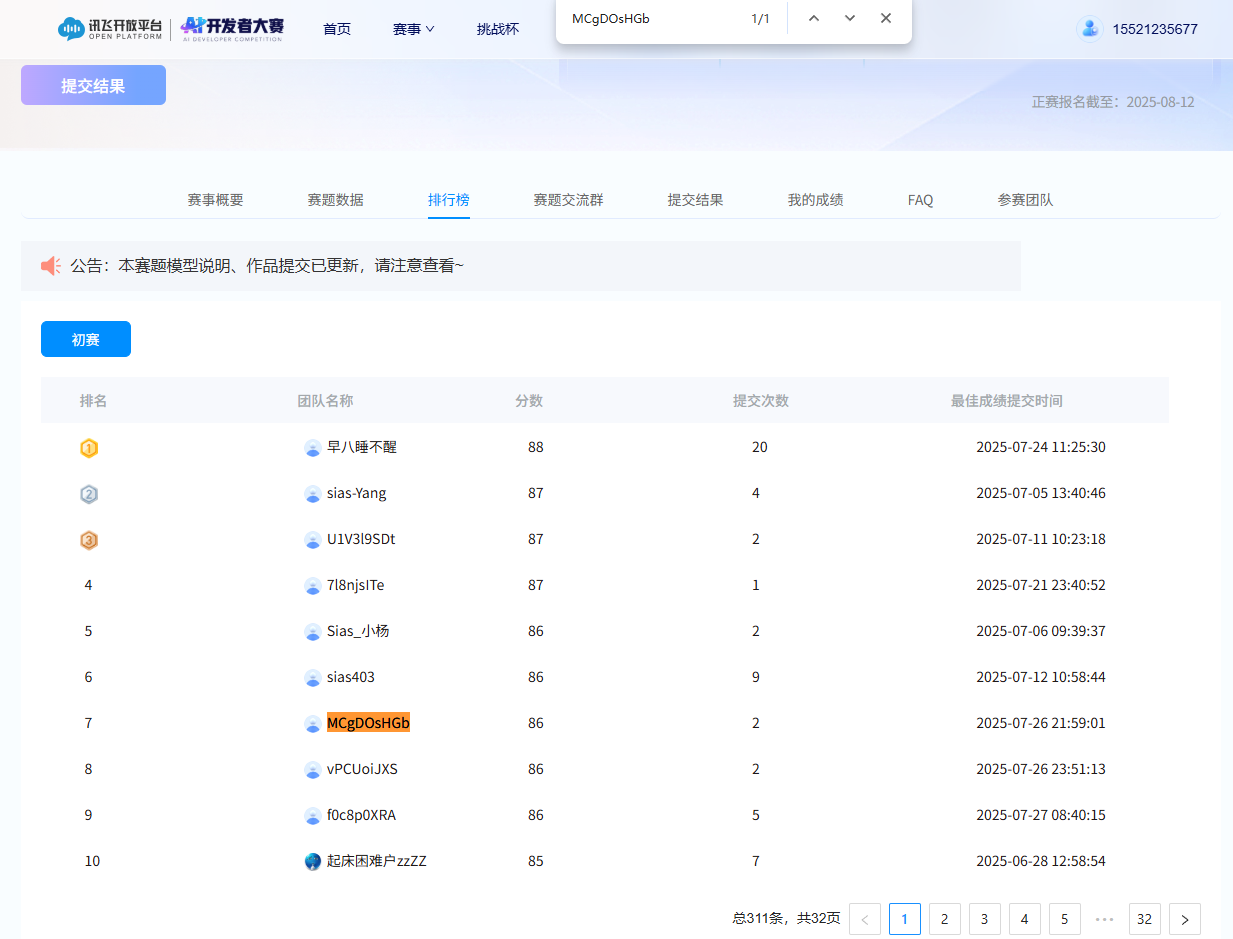
初始结果:评分 76 分
Task2:深入理解与优化策略
2.1 赛题分析
通过 Task2 的学习,我深入理解了模型蒸馏的核心原理:
教师模型生成推理链数据:使用 DeepSeek-R1 生成高质量思维链数据作为训练目标
蒸馏训练学生模型:选择轻量模型进行 LORA 精调
控制训练方式:避免资源浪费,选择 LORA 精调方式
2.2 数据处理优化
在优化过程中,我使用了批量推理功能来扩充数据集。通过教师模型对测试集进行推理,获得了更多高质量的训练数据。
2.3 遇到的问题与解决方案
在数据上传过程中遇到了格式验证失败的问题,错误提示:文件内容校验失败:请检查文件第1行,instruction 字段未填写。
为了解决这个问题,DataWhale 群里的专业助教助攻了一把,他分享了一个用于处理数据格式转换脚本,通过脚本处理,将原始的推理结果文件转换为符合要求的格式,生成了新的数据集filtered_output.jsonl,包含 400 条数据,文件大小 0.67MB。
模型优化与最终结果
3.1 优化后的参数配置
基于 Task2 的学习和数据优化,我调整了训练参数:
| 数据集 | 使用处理后的 filtered_output.jsonl | 400条数据 |
| 学习率 | 调整为 8e-5 | 降低学习率 |
| 训练次数 | 减少为1 | 避免过拟合 |
| LoRA随机丢弃 | 降低为0.01 | 减少随机性 |
| LoRA缩放系数 | 提高为32 | 增强适配器作用 |
| 其他参数保持不变 | ||
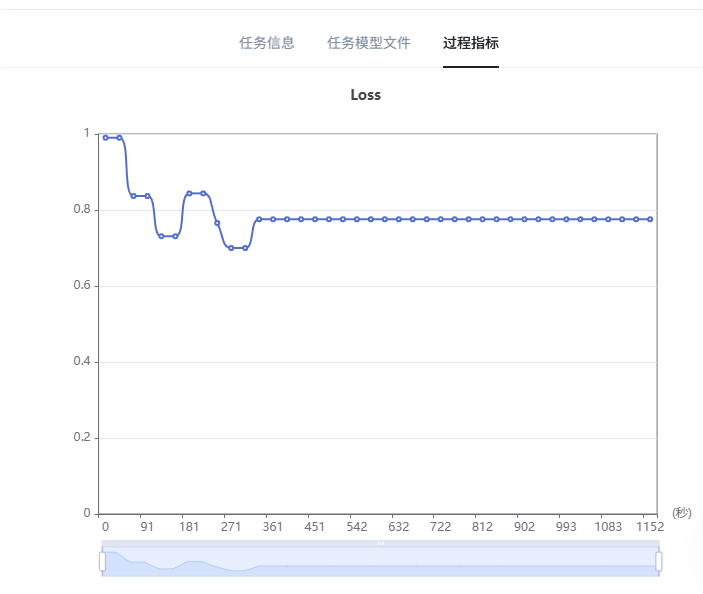
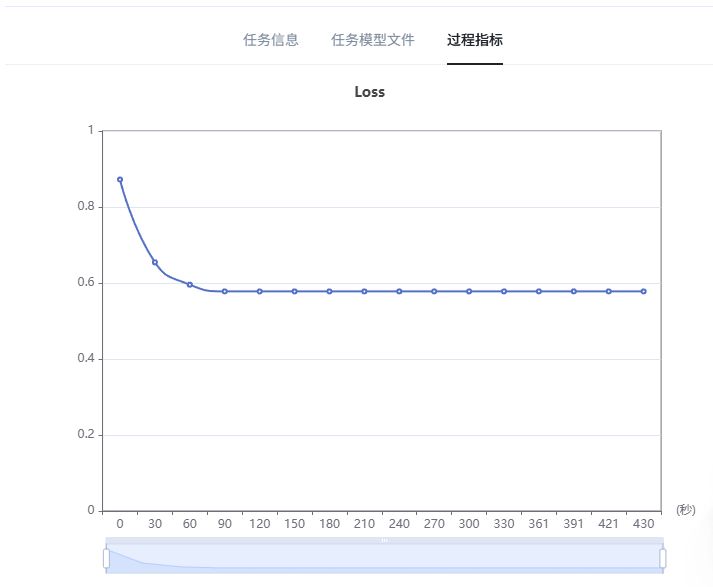
3.2 优化效果
经过一次优化后:
| Baseline评分 | 76 分 |
|---|---|
| 优化后评分 | 86 分 |
| 提升幅度 | 10 分 |
心得体会与总结
4.1 技术收获
模型蒸馏理解:深入理解了知识蒸馏的核心思想,即将大模型(教师)的知识传递给小模型(学生)
数据质量的重要性:从 200 条数据扩充到 400 条,并且通过批量推理获得更高质量的数据,显著提升了模型性能。
参数调优策略:
- 降低学习率可以让模型更稳定地学习
- 减少训练轮数避免过拟合
- 调整 LoRA 参数优化适配效果
4.2 实践经验
平台操作熟练度:通过反复操作星辰 MaaS 平台,熟悉了从数据上传到模型部署的完整流程
错误调试能力:遇到数据格式问题时,能够分析错误原因并借助脚本解决
优化思路培养:学会了从数据、参数、训练策略等多个维度思考模型优化
4.3 学习感悟
这次夏令营让我体验了完整的 AI 模型开发流程,从理论学习到实践操作,从遇到问题到解决问题。特别是在 Task2 的学习中,深入了解了模型蒸馏的理论基础和实际应用,这对后续的 AI 学习和实践都很有帮助。
最重要的是,通过这次实践认识到,AI 模型的优化不仅仅是调参数那么简单,数据质量、训练策略、问题分析等各个环节都很关键。
展望
虽然这次只进行了一轮优化就取得了不错的提升,但还有很多可以探索的方向:
- 进一步优化数据集质量和数量
- 尝试不同的训练参数组合
- 深入研究 CoT 推理模式的优化策略
- 探索更多的模型蒸馏技术
再次感谢 Datawhale 和科大讯飞提供这样优质的学习平台和机会,让我能够在实践中学习和成长。期待后续能够继续深入AI领域的学习和研究!
本文记录了 Datawhale AI 夏令营的完整学习过程,从 76 分 Baseline 到 86 分优化结果的实践之旅。希望能对同样在学习 AI 模型优化的朋友们有所帮助。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









