




 本文总结了MIT 6.830数据库实验室的体验,包括lab1到lab6的主要内容:从基本数据结构到事务处理、B+树索引和日志恢复。实验难度逐渐提升,lab4和lab5最具挑战性。文中还提到一些未深入研究的优化点,如并发控制、死锁检测和索引并发,并分享了相关的学习资源。
本文总结了MIT 6.830数据库实验室的体验,包括lab1到lab6的主要内容:从基本数据结构到事务处理、B+树索引和日志恢复。实验难度逐渐提升,lab4和lab5最具挑战性。文中还提到一些未深入研究的优化点,如并发控制、死锁检测和索引并发,并分享了相关的学习资源。
前提: 我做的是最新版的6.830 lab
架构图
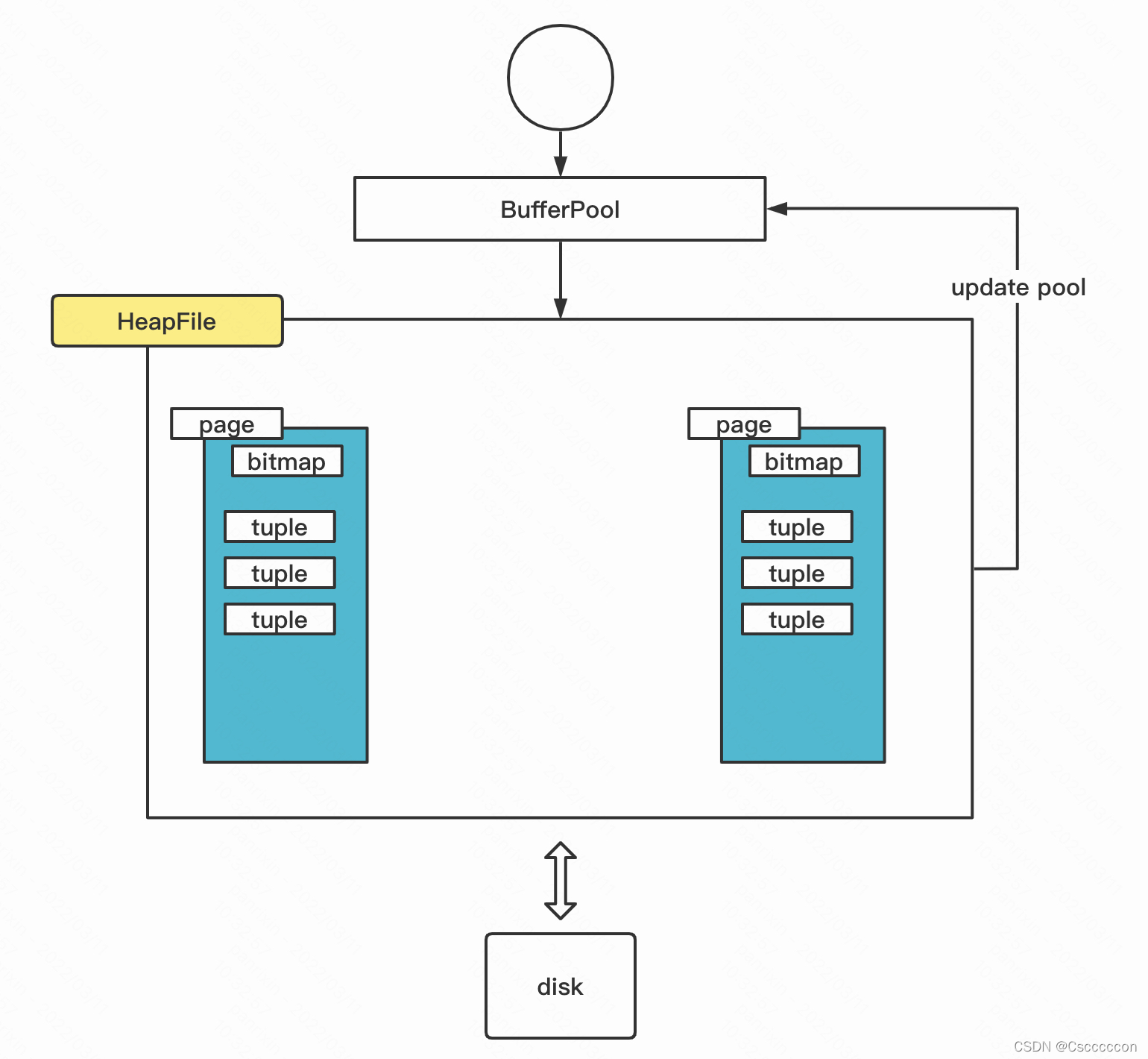
实验
- lab1 实现基本的数据结构
tuple, page, tupleDesc, iterator等等,难度不大 - lab2 实现scan iterator
基于scan iterator 来实现各种聚合函数,比如avg,count,sum,join等 - lab3 join 优化
建立一个优化模型, 按照主键,非主键,scan 表代价,直方图等进行成本估计,根据估计值来确定多表join的顺序 - lab 4 事务以及锁
这一章相对较难,要自己实现一个简单的读写锁,但是6.830中简化了,实现了page-level的锁,粒度比较粗,还有多种死锁的情况,test很给力,建议在写的时候一定要看清楚是哪个transaction 拿到了哪些page的哪些lock,而且这里的代码会影响到后面的lab 5、6,这里主要是按照两阶段锁协议并且no steal / force 的策略 - lab 5 B+ 树索引
实现B+树索引,插入、删除、修改,难点在于要把B+树结构以及这三种操作逻辑要捋清楚,还有父节点,子节点;叶子兄弟节点,非叶子节点的指针问题,以及一些边界条件。 - lab 6 实现基于 log的rollback 和 recover
lab中并没有真正存在undo log 和redo log,日志结构比较简单,只需要根据偏移处理即可,可以理解成是逻辑上的undo log 和 redo log。
心得和遗留的坑
- 实验难度
lab4 = lab5 > lab6 >>>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3080
3080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









