 大数据体系的演进:热点、趋势与挑战
大数据体系的演进:热点、趋势与挑战





 本文探讨大数据技术的演进热点,包括多种计算引擎并存、框架与接入层、数据开发与治理平台、智能化、安全与隐私保护以及运维。未来趋势涉及近实时架构、数据共享与隐私保护、物联网分析和AI for System。同时,文章提出了3个疑问,涉及计算引擎的跨界发展、计算范式和开源与企业级产品的选择。
本文探讨大数据技术的演进热点,包括多种计算引擎并存、框架与接入层、数据开发与治理平台、智能化、安全与隐私保护以及运维。未来趋势涉及近实时架构、数据共享与隐私保护、物联网分析和AI for System。同时,文章提出了3个疑问,涉及计算引擎的跨界发展、计算范式和开源与企业级产品的选择。

作者 | 阿里云计算平台事业部
如今,大数据技术已进入“后红海”时代,成了“水电煤”一样可以普惠人人的技术。同时,新领域仍在不断演进迭代。
本文的上篇 “Snowflake如日中天是否代表Hadoop已死?大数据体系到底是什么?”,阐述了后红海时代下大数据体系的演进热点是什么,以及大数据体系3个子领域的技术解读,包括多层智能化演进的分布式存储系统、统一框架和算法多元化发展的分布式调度系统,和统一化发展的元数据服务。
本文作为下篇,继续对计算引擎、框架与接入、数据开发与治理、智能化、安全与隐私保护、运维6个子领域做技术解读,概述各领域的演进历史、背后驱动力、以及发展方向,并希望和大家一起探讨大数据体系未来演进的技术趋势,以及仍待探索的未解问题。

大数据体系的领域架构
在Shared-Everything架构角度下,大数据体系子领域划分成9个领域:

注:这张图上的前3个子领域:分布式存储、分布式调度、元数据服务已在上篇完成,本文直接从第4个子领域开始分享。
4. 多种计算引擎并存
计算层是整个大数据计算生态的核心,是数据到价值转换的关键。大数据场景中有各类计算形态,如批、流、交互式、多模、图、搜索、等多种计算模式。
大数据领域发展了20年,在“后红海”时代,主流计算模式已经基本固定,形成批处理、流处理、交互式、机器学习四个核心方向,以及一些小众/专门场景的计算模式。在开源社区领域,经过百舸争流式的竞争和沉淀,也基本形成了主流的社区形态。
除了机器学习,前三个方向有一定的overlapping,例如Spark同时支持流、批和部分交互能力。但最终形成广泛影响力的引擎,都是在某一方向建立显著的竞争门槛。
整体看,计算引擎的发展将会在存储计算分离架构基础上,以一套数据支持多种计算模式:
(1)存储计算分离,以及随后的1+N架构(即一套数据之上支持多种计算模式)
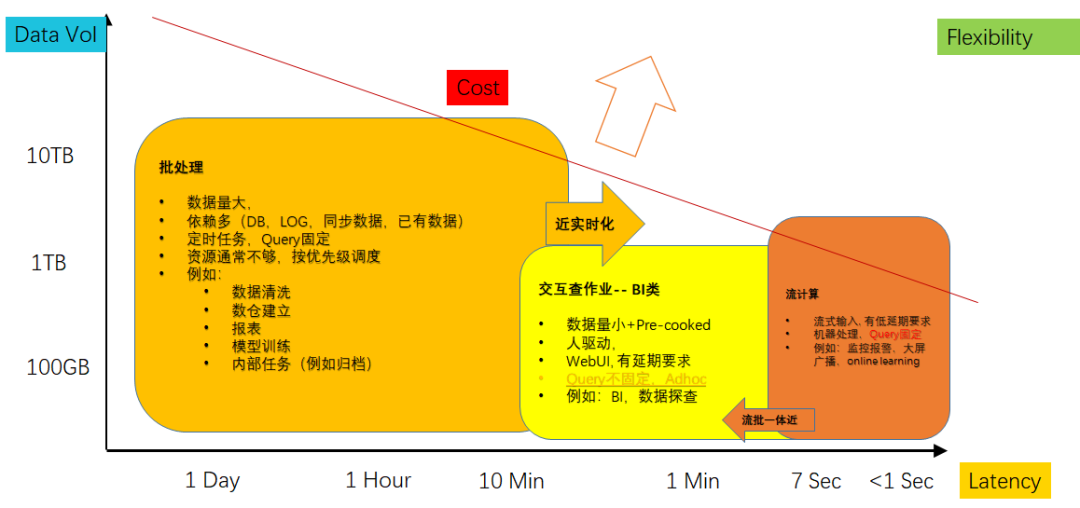
(2)批处理——是大数据处理的基础形态,以Bulk Synchronous Parallelism(BSP)为基础原理,从Map-Reduce(MR)模式开始发展起来,所谓“批”指的就是Bulk(也译作Batch)。Map-Reduce的运算框架逐步发展成Direct Acyclic Graph(DAG),上层语言也开始从MR的Java代码向SQL转型,第一版本集大成的批处理开源系统是Hive+Tez。因为Hive2.0是严格BSP模式,每次数据交互均需要落盘,牺牲了延迟和性能。Spark抓住内存增长的趋势,推出基于ResilientDistributed Dataset(RDD)的运算框架,展开与Hive的竞争。当前在开源领域,Hive/Spark是主流引擎,随Spark稳定性和内存控制逐步完善,Spark逐步占领开源市场。目前批处理仍然是最主流的计算形态,整体的优化方向是更高吞吐/更低成本。
最近两年,随近实时方向的兴起(以开源ApacheDelta/Hudi为代表),批处理数据从接入到计算的延迟得的显著的降低,给用户提供了一种成本/延迟的另一个平衡点。
(3)交互式分析——通常是面向分析场景(人驱动,中小规模输入数据/小规模输出数据),在中小规模cook好的数据上(通常是批处理之后的数据),基于更快的存储、更多的内存(bufferpool)、更实时的数据更新(通常是基于LSMTree的方案),也采用更多的OLAP优化技术(例如PlanCache)。优化方向更偏延迟(而非成本和吞吐率)。技术栈发展上,有两个脉络,一个是从分布式数据库角度发展起来,采用MPP架构,例如开源领域的Apache Impala和Clickhouse,自研领域的AWS Redshift。另一个是更偏云原生和大数据的架构,例如Apache Presto。
批处理和交互分析,有天然的统一需求,因此很多自研的分析引擎也包括一定的批处理能力,形成一体化,例如当前如日中天的SnowFlake。而Google BigQuery采用附加交互引擎(内置一个更快的BIEngine)的方式形成一体化。从细节看,交互分析的引擎优化更偏数据库类优化方向,更强调用好Memory和Index,Plan相对简单,对QueryOptimizer要求低,不需要支持丰富的UDF,也不需要做Query中间的failover。批处理引擎更面向吞吐量(Throughput)优化,核心是更优化的Plan以及尽量降低IO,同时对failover要求高(因此部分数据要落盘)。这也是为什么BigQuery选择双引擎的原因。
(4)流处理——采用ContinuousProces
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









