




在这个“万物皆可大模型”的时代,似乎无论什么任务都能一句“上LLM”解决。图像识别?让多模态大模型来。文档解析?让GPT系列试试看。
可问题是——大模型真的是万能的吗?
从聊天、写代码到看图、生成视频,大模型的能力确实惊人,可在这场AI的狂飙背后,有一个决定AI理解力上限的基础环节,却往往被忽视了——OCR(文字识别与文档解析)。
OCR的重要性,往小了说,它决定了AI输入的信息质量;往大了说,它是AI理解人类世界的“眼睛”。眼睛不清晰,AI再聪明也没用。
而在这个领域,有一个名字堪称“六边形战士”,不仅轻量、精准,还能打遍天下——PaddleOCR。

目录
一、从开源新秀到OCR砥柱
如果你关注OCR生态,这个名字一定不会陌生。
早在2020年,PaddleOCR刚开源时就登上了GitHub Trending日榜第一,那时它只是个轻量小模型,却能在效果上吊打不少“大块头”,震惊了一票开发者。
之后几年的进化堪称“开挂”:
-
2021-2022年:推出 PP-OCRv2,速度与精度齐飞;
-
2023年:PP-OCRv3与v4相继发布,性能全面突破;
-
2025年:迎来真正的里程碑——PaddleOCR 3.0 系列正式登场。

短短几年,它从一个高效的工具,成长为一个集文字检测、识别、结构化解析、多语种支持于一体的完整开源生态系统,几乎成为OCR界的“基础设施”。从一个轻量工具,到今天56K+ Star的顶级开源项目,PaddleOCR已经成为无数OCR项目的底座。像 Umi-OCR、MinerU、RAGFlow、OmniParser 等知名项目都直接集成了它。

这不仅是“国产之光”,更是开源界的一座里程碑。
二、PaddleOCR 3.x:三大进化,直击行业痛点
2025年,PaddleOCR迎来了三大核心升级版本——PP-OCRv5、PP-StructureV3、PP-ChatOCRv4。

这三者构成了一个完整的文档理解闭环:识别文字 → 解析结构 → 抽取信息。
-
PP-OCRv5:语种更多、精度更高
PaddleOCR 最新一代模型 PP-OCRv5 已经全面支持 42 种语言识别,覆盖中文、繁体、英文、法语、西语、德语、日语、韩语、俄语等多语种场景,还能识别拼音、生僻字、古籍、竖排文本、复杂手写体等高难度样本。

更夸张的是——在内部复杂评估集中,PP-OCRv5端到端精度较上一代提升了13个百分点。

此外,模型仍然保持了“轻量级”特性。它兼容 Windows、Linux、Mac 等系统,支持 NVIDIA GPU、Intel CPU、昆仑芯、昇腾等多种硬件部署,是真正意义上的全平台OCR解决方案。
-
PP-StructureV3:文档解析的“结构化大师”
传统OCR能“识字”,但面对结构化的复杂文档(比如表格、PDF、公式、图表),往往束手无策。
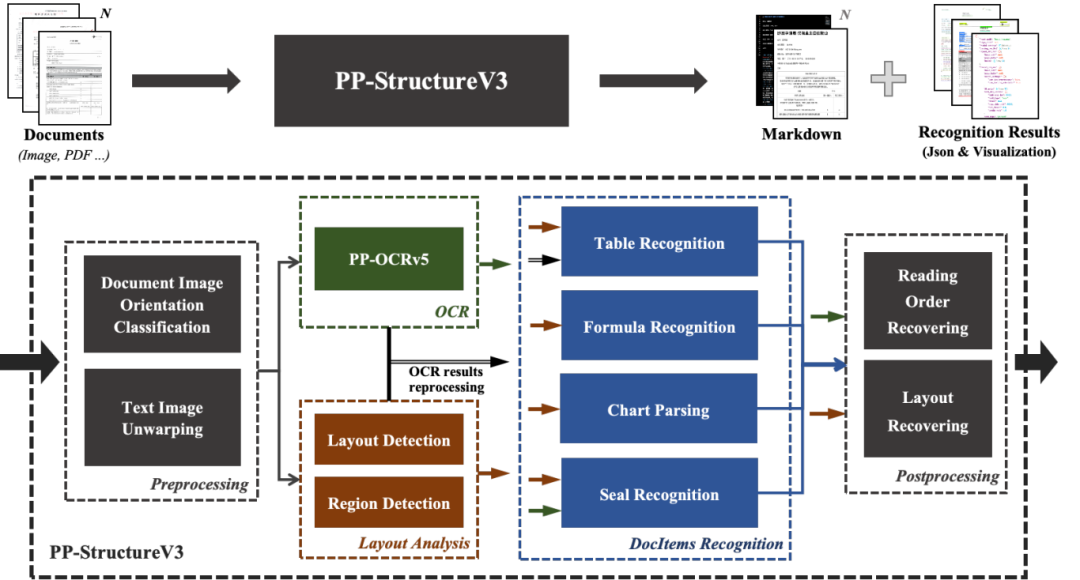
PP-StructureV3 则真正实现了“从看得见到看得懂”。它能把文档图像精准解析成结构化的 Markdown 内容,保留表格结构、公式格式、阅读顺序等复杂信息。在 OmniDocBench 数据集上,PP-StructureV3 的表现甚至超越了部分多模态大模型和传统 pipeline 方案,成为文档解析领域的新标杆。

更难得的是,它不仅能处理标准PDF,还能解析扫描件、手写笔记、古籍、竖排文本等复杂样本。
-
PP-ChatOCRv4:让OCR有了“对话式理解”
到了PP-ChatOCRv4,PaddleOCR正式进入“智能文档理解”时代。
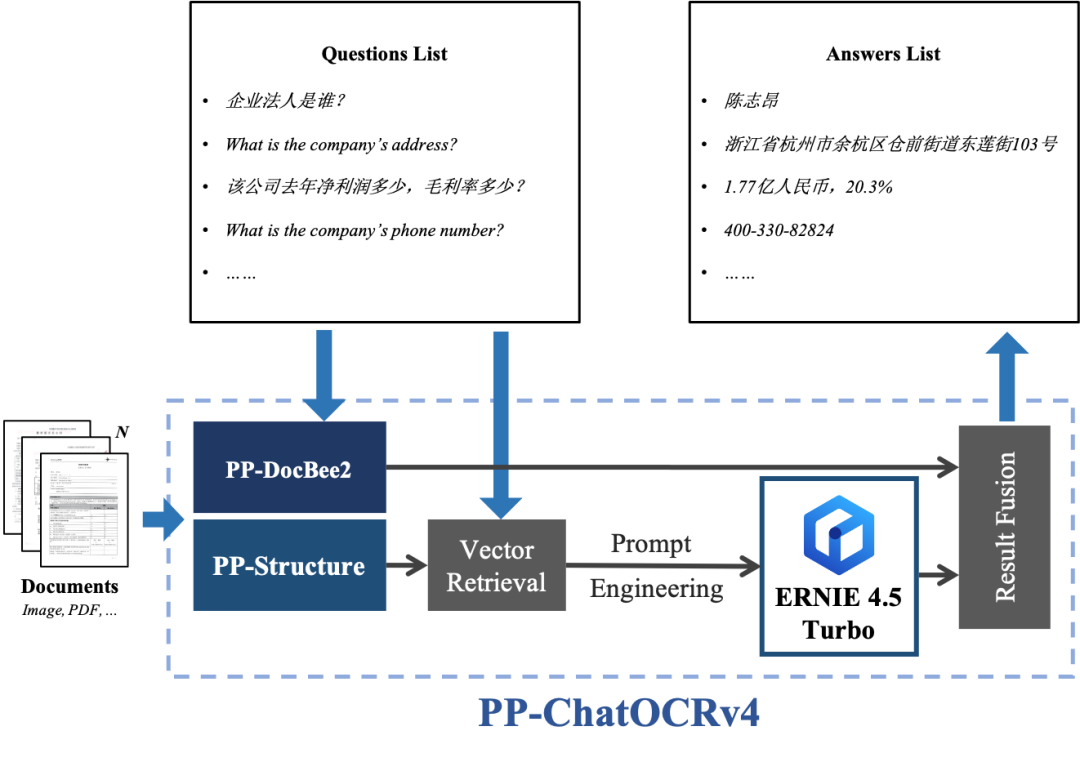
它创新性采用大小模型协同架构,融合了:
-
PaddleOCR 的视觉识别;
-
文心大模型 4.5 的语义理解;
-
PP-DocBee2 的多模态文档解析。
这套组合拳让它能实现——“对话即抽取,一问即得”。
比如上传一份合同或财报,你只需问一句“帮我提取付款日期和金额”,它就能精准返回答案。
在复杂文档信息抽取的准确率上,相比上一代提升了15个百分点。
而且它支持服务化部署、国产硬件适配、二次训练调优,开发者可以轻松把它集成进自家系统。
三、为什么 PaddleOCR 能“卷对地方”
在大模型狂卷参数量、拼算力的今天,PaddleOCR 却坚持另一条路线——卷技术细节、卷生态实用性。
我觉得这反而是最聪明的“内卷”。
总结来看,它的优势主要体现在三个层面:
-
核心识别能力持续突破
从v2到v5,PaddleOCR在算法层面持续演进:
文本检测模型引入 DBNet++ 改进版,边界更精准;
识别模型采用自适应注意力模块,手写体表现显著提升;
字典扩展支持多语种并联训练;
增强学习结合数据合成策略,让识别更稳健。
-
多语言与全球化场景全面覆盖
从最初的中英文,到现在支持 42 种语言,PaddleOCR 已经从“能识别”进化到“识得准”。
更惊喜的是,它还支持自定义字典、模型微调——比如你要加上韩文或中亚小语种,只需扩展字典并微调模型即可无缝接入。
这对于跨国企业、教育机构、多语种文档平台来说,都是极大的便利。
-
部署与开发者生态日趋完善
PaddleOCR 3.x 引入了 MCP服务器 支持,能与大模型无缝交互;
同时兼容 Intel CPU、英伟达GPU、昆仑芯、昇腾等国产硬件,部署自由度极高。
它还提供了多语言API(C++、C#、Java、Go、PHP 等),方便在各类项目中集成。
开发者体验可谓“开箱即用”,这也是它能快速在产业中落地的关键原因。
这一系列改进,让 PaddleOCR 能稳稳在开源界站C位。
-
Coovally平台助力模型快速生产迭代
当然如果你还在为配环境、部署模型感到头疼,Coovally平台帮助你,在Coovally平台上汇聚了国内外开源社区超1000+热门模型,涵盖图像分类、目标检测、语义分割、文字识别等场景。同时集成300+公开数据集,一键下载即可投入训练,彻底告别“找模型、配环境、改代码”的繁琐流程!
!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
Coovally还有多模态大模型智能推荐,根据模型配置信息和任务类型以及训练结果等信息,自动推荐优化建议,让模型迭代事半功倍!

根据数据统计分布特点和任务类型等信息,基于多模态大模型技术自动推荐数据增强方法及模型选择建议。
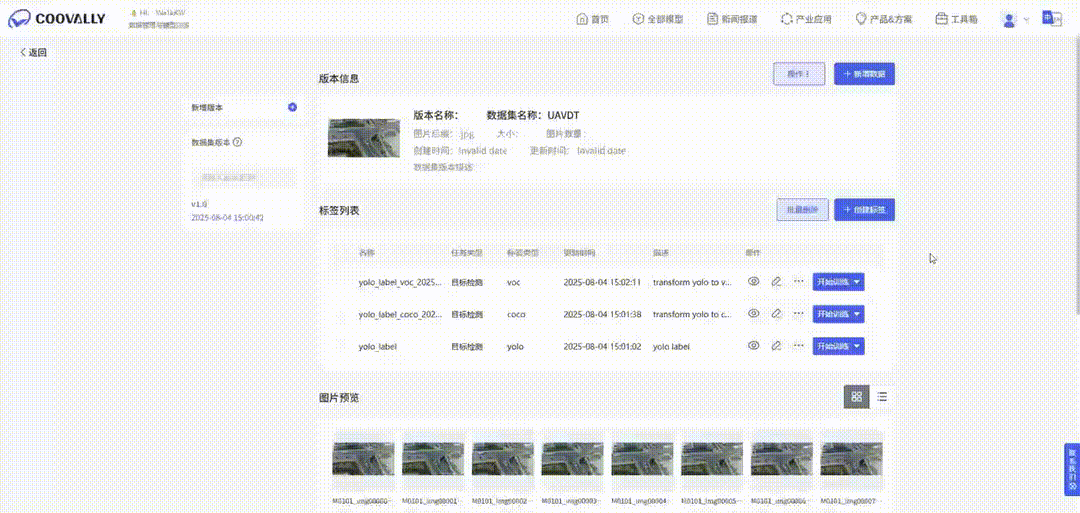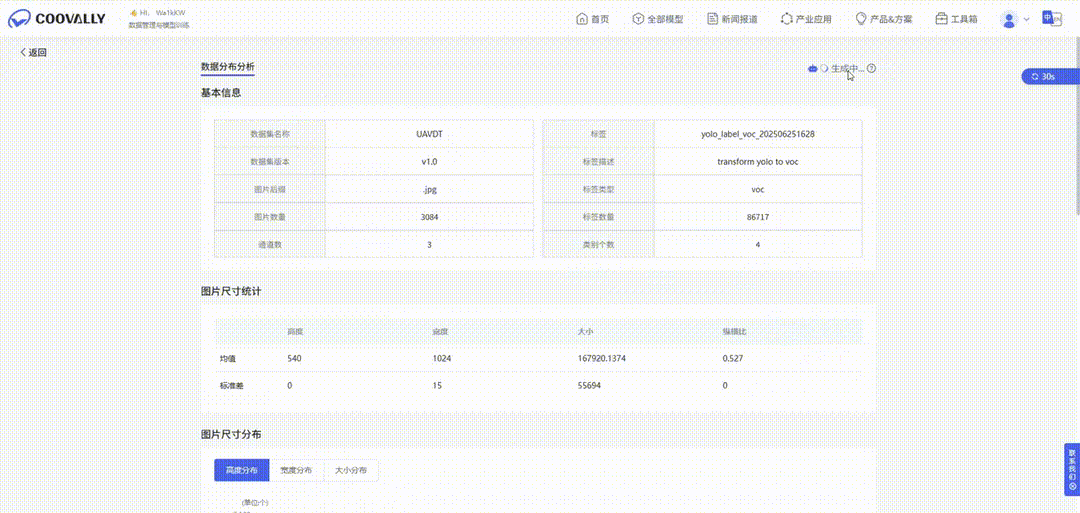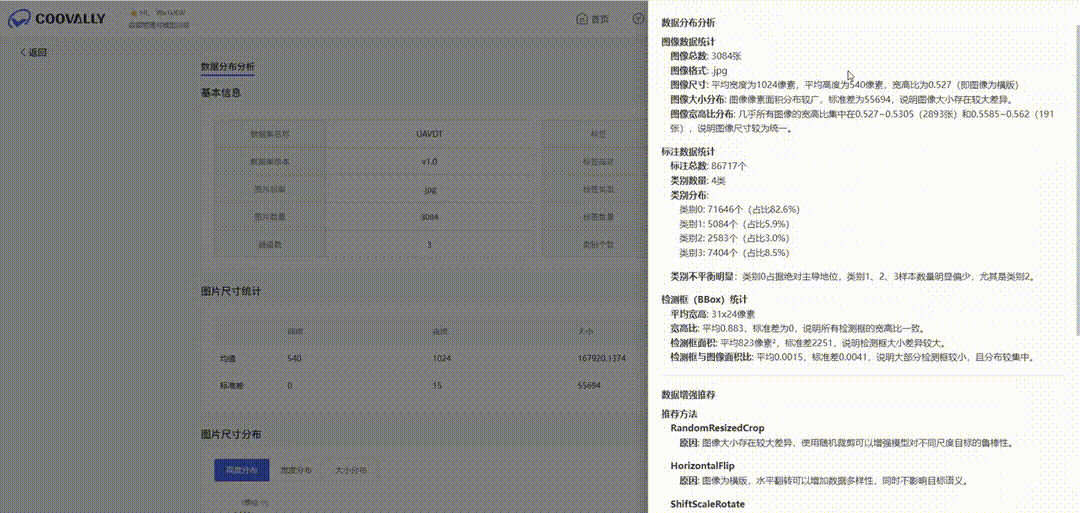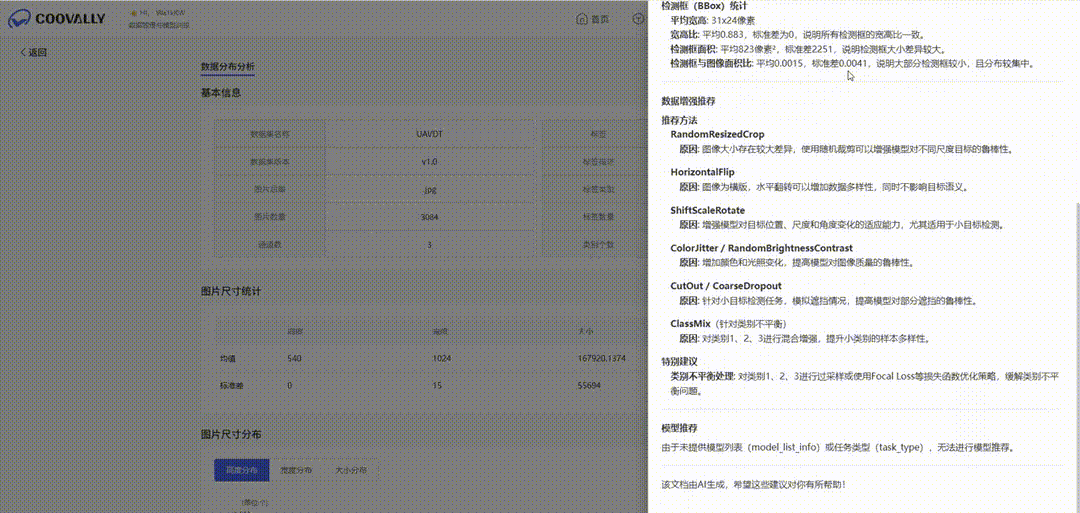
四、这场OCR“卷”得有价值
大模型当然值得期待,但基础能力才是AI走得远的关键。
OCR 是所有文本理解任务的底座,而 PaddleOCR 用五年的积累,给出了一个完美的答案——开源、轻量、高精度、多语言、易部署。
它不仅是一套OCR工具,更是AI理解世界的底层引擎。
对开发者而言,它意味着我们能更高效地构建全球化、智能化的应用;
对企业而言,它意味着数据治理、知识提取、文档理解的效率革命。
PaddleOCR 卷得不浮躁,不盲目,它卷技术、卷体验、卷生态。
这样的“内卷”,我们真心欢迎。
五、文档及开源项目地址
PaddleOCR 文档链接:https://www.paddleocr.ai/main/
Github:https://github.com/PaddlePaddle/PaddleOCR




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









