




【导读】
7月6日晚,“苏超”联赛第六轮,常州客场对战淮安,最终0∶0握手言和。这场高温下的鏖战,是常州队在“苏超”中拿下的首个积分。
然而,“常州进球无效”却在赛后登上微博热搜第一,引发大量讨论——这个进球到底应不应该算?
这一次,我们从AI的角度切入,试着用YOLO目标检测技术搭建一个足球比赛追踪系统,看看AI是否能还原现场,为争议判罚提供“技术支持”。>>更多资讯可加入CV技术群获取了解哦
目录
一、为什么要用AI辅助足球判罚?
人眼观看有盲区,裁判也可能会错过某些细节。而现代AI视觉系统可以做到:
-
识别并追踪每一个球员;
-
实时定位足球在场上的运动轨迹;
-
精准分析越位、进球等关键事件。
尤其是在“是否越过门线”、“是否越位”等边界判罚上,AI能发挥巨大作用。
二、传统流程:从零搭建一个YOLO足球追踪系统
-
数据采集与标注
-
使用视频帧截取工具,将比赛视频转为图像序列(如每秒5帧);
-
使用CVAT、LabelImg等工具对球员、足球、裁判等目标进行框选标注;
-
导出为YOLO格式的标签文件。
/data
└── images/
└── match01_001.jpg
└── labels/
└── match01_001.txt # YOLO格式标签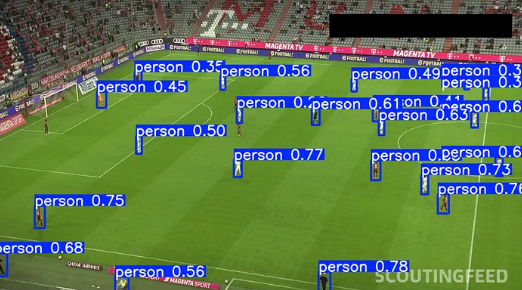
-
微调YOLO模型
-
使用YOLOv8预训练模型进行迁移学习;
-
自定义类如
ball、player、referee; -
设置好
match.yaml后训练。
yolo task=detect mode=train model=yolov8n.pt data=match.yaml epochs=50 imgsz=640from ultralytics import YOLO
model = YOLO("../assets/weights/best.pt")
result = model.predict(source="../assets/source_videos/B1606b0e6_1 (28).mp4",
save=True,
stream=True)import cv2
# Retrieve and visualize the first result
first_result = next(result) # Get the first result from the generator
annotated_frame = first_result.plot() # Overlay detections on the frame
# Display the annotated frame
cv2.imshow("YOLO Detection", annotated_frame)
cv2.waitKey(0)
cv2.destroyAllWindows()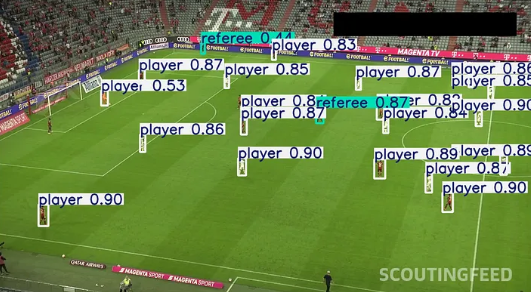
-
目标追踪机制详解
检测模型可以在每一帧中识别出球员和足球,但不会“记住”谁是谁。YOLO是静态检测器,追踪需要跨帧关联。
📌 什么是目标追踪?

目标追踪是指在视频序列中,保持同一物体ID一致,并绘制其移动轨迹。我们需要结合:
-
位置:距离与上帧目标位置的接近程度;
-
外观:颜色特征、尺寸、长宽比等;
-
运动轨迹:使用卡尔曼滤波器预测移动趋势。
首先,我们应该从视频文件中提取帧。
# funcs.py
import cv2
import numpy as np
from typing import List
def read_video_frames(video_path: str) -> List[np.ndarray]:
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
raise IOError(f"Cannot open video: {video_path}")
frames = []
while True:
ret, frame = cap.read()
if not ret:
break
frames.append(frame)
cap.release()
return frames批量推理并缓存,跟踪检测目标
import supervision as sv
from typing import Any, Dict
def run_tracking(detections: List[Any]) -> Dict[str, List[Dict[int, Dict[str, List[float]]]]]:
tracker = sv.ByteTrack()
results = {"players": [], "referees": [], "ball": []}
for det in detections:
cls_names = det.names
name2id = {v: k for k, v in cls_names.items()}
sv_det = sv.Detections.from_ultralytics(det)
for i, cls_id in enumerate(sv_det.class_id):
if cls_names[cls_id] == "goalkeeper":
sv_det.class_id[i] = name2id["player"]
tracked = tracker.update_with_detections(sv_det)
frame_result = {"players": {}, "referees": {}, "ball": {}}
for t in tracked:
bbox, cls_id, track_id = t[0].tolist(), t[3], t[4]
if cls_id == name2id["player"]:
frame_result["players"][track_id] = {"bbox": bbox}
elif cls_id == name2id["referee"]:
frame_result["referees"][track_id] = {"bbox": bbox}
for t in sv_det:
if t[3] == name2id["ball"]:
frame_result["ball"][1] = {"bbox": t[0].tolist()}
for key in results:
results[key].append(frame_result[key])
return results绘制可视化框和导出
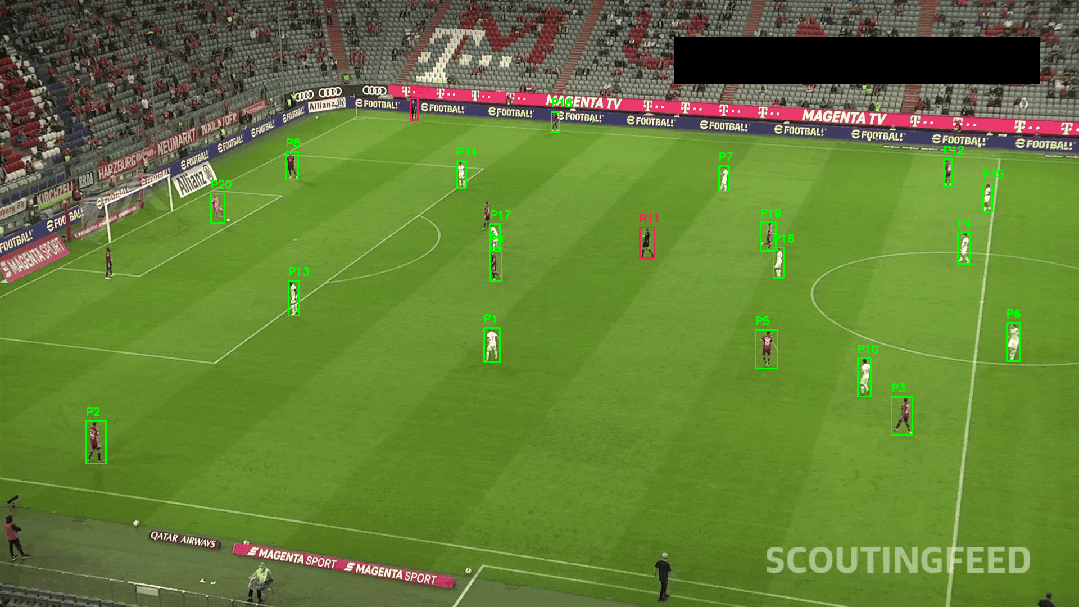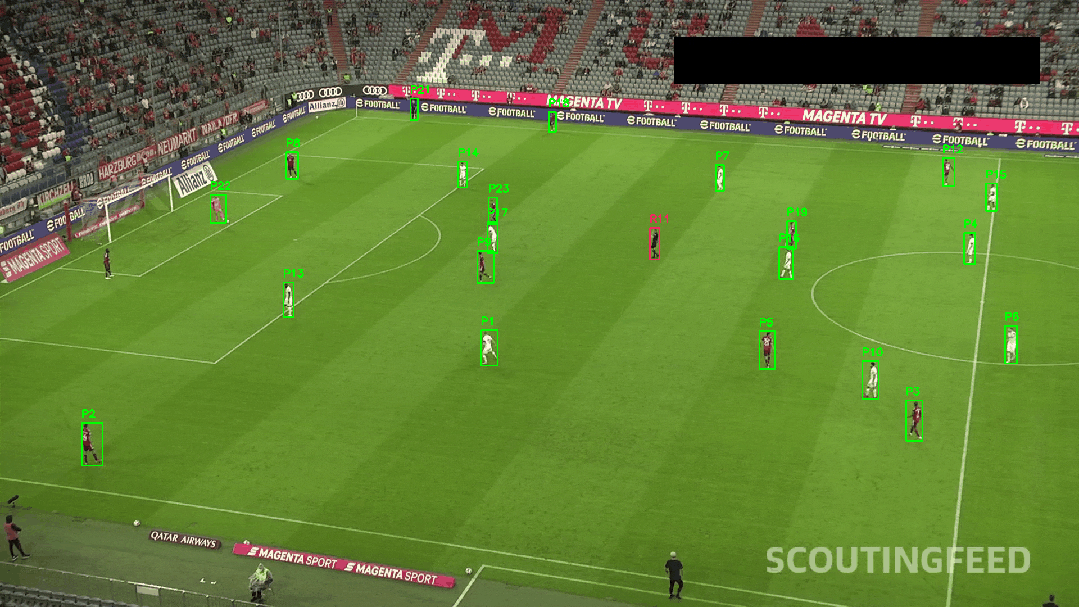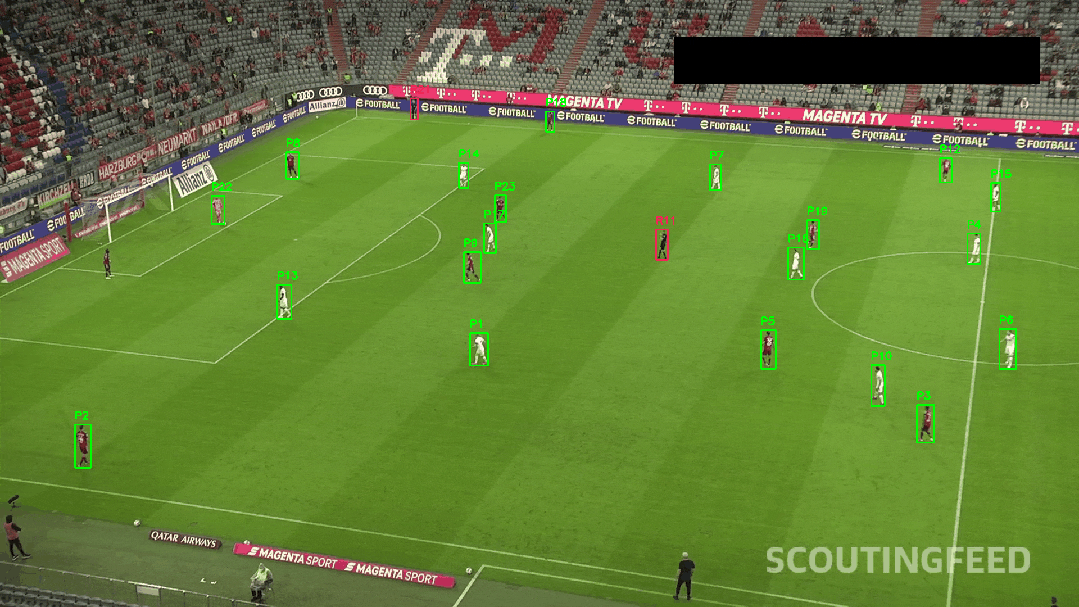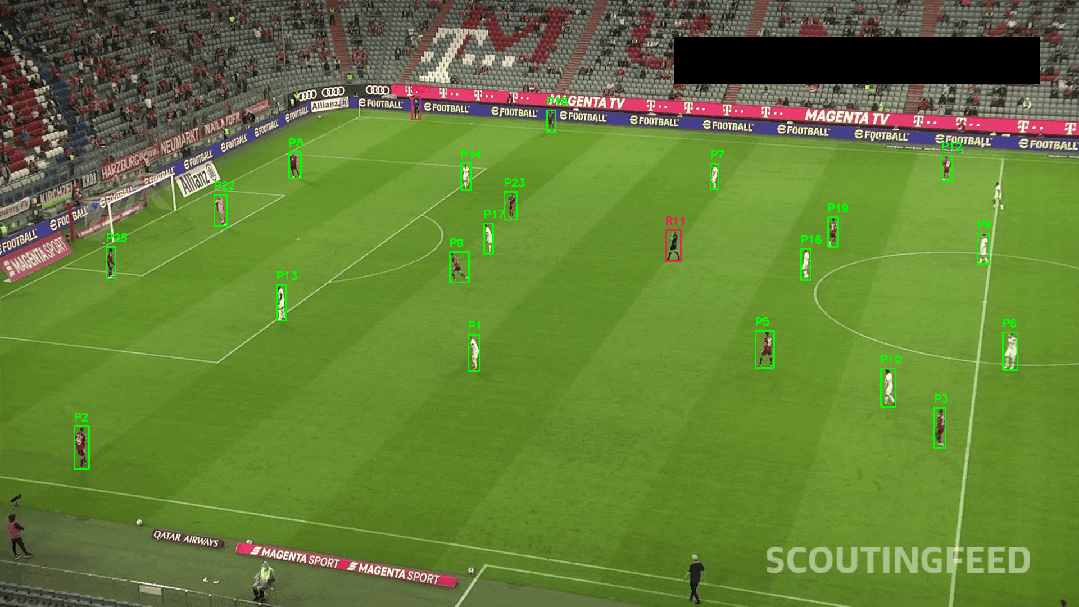
✅ 颜色聚类辅助身份识别
比赛中球衣颜色不同,我们使用 K-Means 聚类对图像上半部分进行颜色分割:

# 图像预处理
upper_half = frame[0:int(h/2), :, :] # 获取图像上半部分
pixels = upper_half.reshape(-1, 3)
# 聚类为两个颜色区域(假设为球衣+背景)
kmeans = KMeans(n_clusters=2).fit(pixels)
# 找出背景标签(角落像素最多的聚类中心)
corner_pixels = frame[0:10, 0:10, :].reshape(-1, 3)
corner_labels = kmeans.predict(corner_pixels)
background_label = np.bincount(corner_labels).argmax()
# 得到球员球衣颜色中心
player_cluster_color = kmeans.cluster_centers_[1 - background_label]
DeepSORT集成
使用DeepSORT,可以将检测结果与颜色特征结合,自动分配ID并持续追踪:
features = extract_color_features(frame, box)
tracker.update(box, features)最终,我们可在视频中呈现出球员编号、实时轨迹线、速度变化等效果。
-
动态边框与行为分析
-
在图像中渲染边框、轨迹线、球员速度;
-
识别关键事件帧(如足球接近门线、球员碰撞)。
-
球员分割
可使用YOLACT、RTMDet等模型,对遮挡球员进行实例分割,辅助精确识别和ID保持。
-
球轨迹插值
处理掉帧、遮挡时足球的轨迹连续性,可使用插值方法:
# 示例:两帧之间线性插值
ball_pos_frame1 = (x1, y1)
ball_pos_frame2 = (x2, y2)
interpolated = [(x1 + i*(x2-x1)/n, y1 + i*(y2-y1)/n) for i in range(1, n)]
三、这些流程的“痛点”
-
标注数据成本高,需逐帧框选目标;
-
训练和追踪逻辑复杂,涉及多种算法拼接;
-
调参、可视化、测试周期长;
-
需要本地配置深度学习环境,对初学者不友好。
四、Coovally:一键启动目标追踪系统
-
上传数据:支持YOLO标注/图像/视频,自动解析;
-
选择模型:YOLOv11/v12、DeepSort等已集成;
-
训练可视化:无需手动绘图,自动生成loss曲线、结果图;
-
启用追踪:DeepSORT等一键调用;
-
输出结果:训练视频、预测视频一站导出。
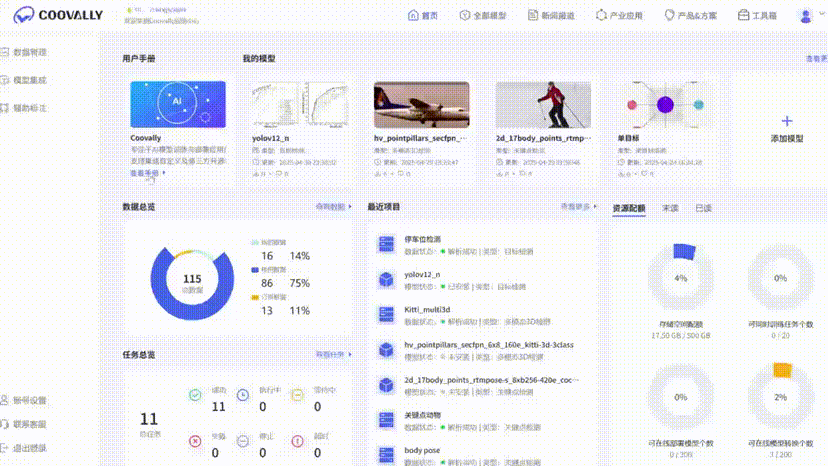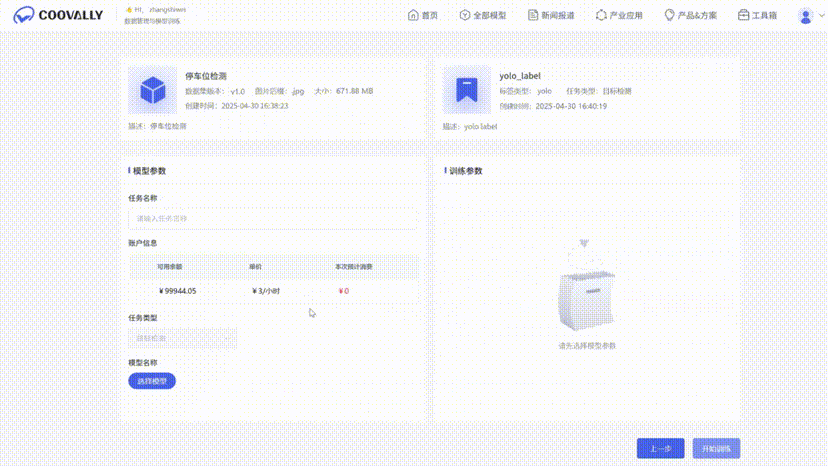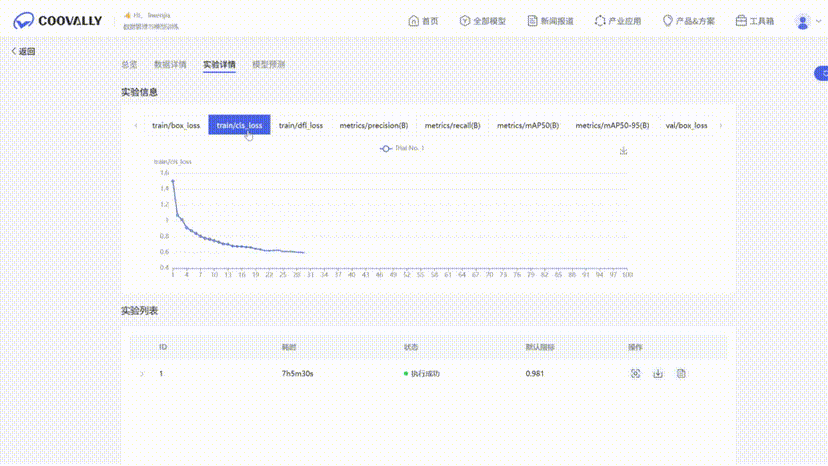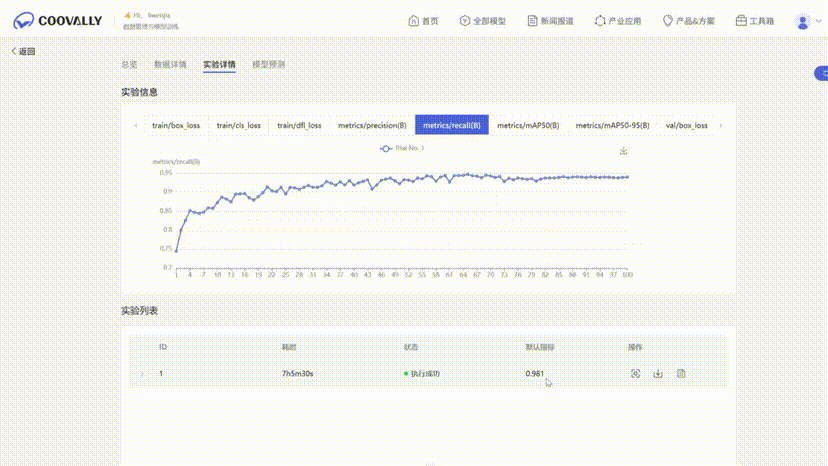
当然Coovally还推出了RaaS(Result-as-a-Service)服务:

RaaS 是一种按任务计价、结果交付的AI服务模式,你只需提交需求,无需管模型、平台、训练、测试这些繁琐细节,我们帮你完成所有开发,按阶段交付结果,且效果有保障!
不论是研究型开发还是商用AI系统建设,都可以通过RaaS快速实现原型搭建与迭代,节省90%开发时间与成本。
📮 欢迎扫描下方二维码,提交你的AI需求,开启你的多模态AI开发之旅!(详情可点击了解)

五、对比总结表格
| 模块 | 传统流程 | Coovally平台 |
| 模型训练 | YOLO下载 + 迁移学习 + 手动调参 | 一键启动,支持预训练YOLOv8 |
| 目标追踪 | 需接入DeepSORT、ReID模块 | 平台内置多种追踪算法 |
| 轨迹渲染 | 需OpenCV绘图脚本 | 自动轨迹线、速度变化可视化 |
| 球衣颜色辅助 | K-Means聚类手动实现 | 调用SSH本地修改 |
| 部署环境 | 需显卡、PyTorch、依赖配置 | 无需安装,云端训练 |
总结
这场0∶0背后的故事,不止是比分。
“我们从来不是因为看到希望才坚持,而是因为坚持,才能看到希望。”
而技术的价值也在于此:让争议判罚有“辅助证据”,让地方联赛也能享有“VAR级别”的智能辅助。
📣 关注 Coovally AI Hub,探索AI+体育更多可能!后台回复关键词「足球追踪」,获取完整源码与平台体验通道。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









