




目录
前言
YOLO(You Only Look Once)作为一种高效、实时的目标检测算法,一直是计算机视觉领域中最受欢迎的技术之一。YOLOv7是YOLO系列中一款高效、精准且灵活的目标检测模型。目标检测任务中提供了更高的准确度、更强的实时性和更丰富的功能,是目标检测领域的强力工具。今天就跟着小编一起来全方面认识一下YOLOv7算法模型吧~

参考论文:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
论文链接:https://arxiv.org/abs/2207.02696
一、模型介绍
YOLOv7虽然在热度上不及YOLOv5或YOLOv8,但它在模型上的提升却是不容小觑的,特别是在精度、推理速度和多尺度特征融合等方面,YOLOv7推出即超过当时所有已知的目标检测器,YOLOv7各方面的优化让它特别适用于小物体和密集物体,这使得它非常适合实时性要求较高的应用场景,如视频监控、自动驾驶、无人机等。
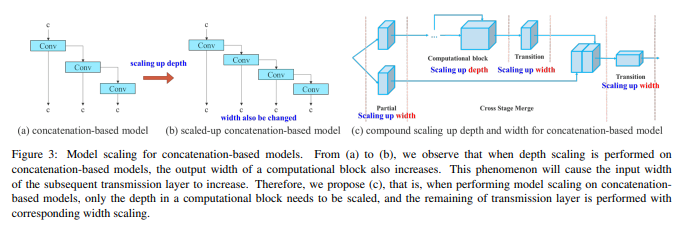
二、架构设计
YOLOv7的架构继承了YOLO系列的优良传统,并在此基础上做出了多项创新。

1.Backbone(骨干网络)
YOLOv7的 backbone采用了ELAN结构,在YOLOv7的研究中,研究团队提出了E-ELAN(Extended ELAN),这是对ELAN(Efficient Layer Aggregation Networks)的扩展版本,也是YOLOv7的重大创新,旨在优化网络结构以提升模型性能。

ELAN通过聚合不同层的特征来提高网络的表征能力,但研究团队发现其在特征利用率和网络学习能力上仍有提升空间。因此,E-ELAN通过使用组卷积增加特征基数,并通过shuffle和merge cardinality的方式组合不同组的特征,以更有效地利用特征并增强网络学习能力。
E-ELAN在计算块架构上进行了改进,采用了expand、shuffle、merge cardinality等操作,以连续增强网络的学习能力。
此外,研究团队还研究使用梯度流传播路径来分析如何重参数化卷积,以与不同的网络相结合。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2864
2864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









