



AI编程王座,一夜易主。
前日,谷歌放出全新升级的Gemini 2.5 Pro Preview(I/O版),一举拿下三连冠,登顶LMeana。
它成为首个横扫文本、视觉、WebDev Arena基准的SOTA模型,编码性能碾压Claude 3.7 Sonnet。
在WebDev上,它成为首个超越Claude的编程模型,甚至连最新发布的GPT-4.1都不及Gemini 2.5 Pro。
此次更新,除了以UI为中心的开发外,还扩展到了代码转换、代码编辑和开发复杂的AI智能体工作流。
在博客中,谷歌随手放了个小实例:一句话将图片上树叶的行为用代码表达出来。

不论是在代码转换、代码编辑,甚至是开发复杂的智能体工作流中,Gemini 2.5 Pro都能得心应手。
随手画个草图,Gemini 2.5 Pro即可将其变成一个绘画小程序。

只需一个提示,它就能将自然图像,转化为代码来表示独特的图案。

Gemini 2.5 Pro Preview一经发布,热度直接爆表。开发者们借助其强大编码能力,构建出有趣的demo。
网友Arthur Lee只用调整一次,就生成了一个3D太阳系,非常漂亮,而且能够随意交互。
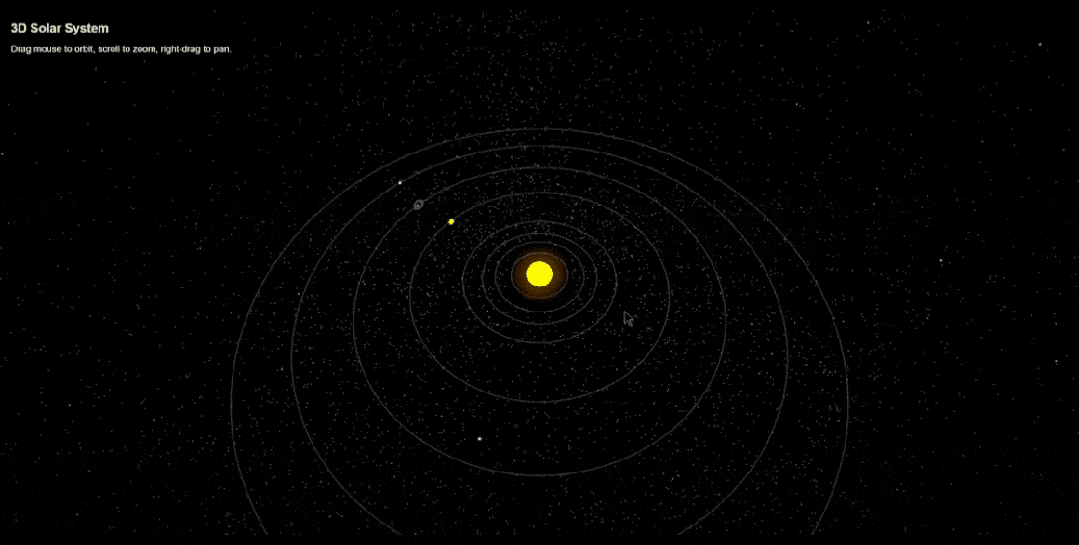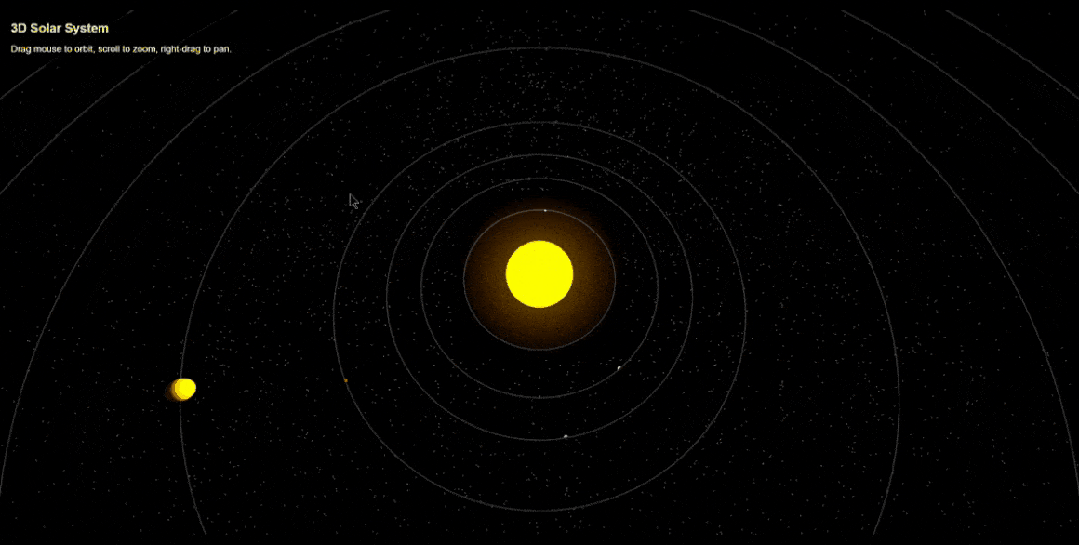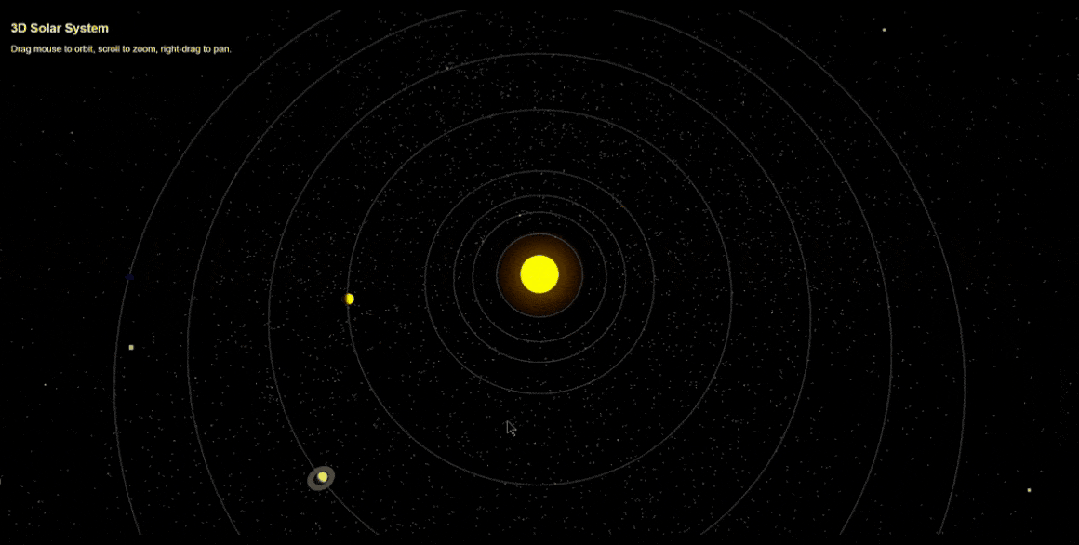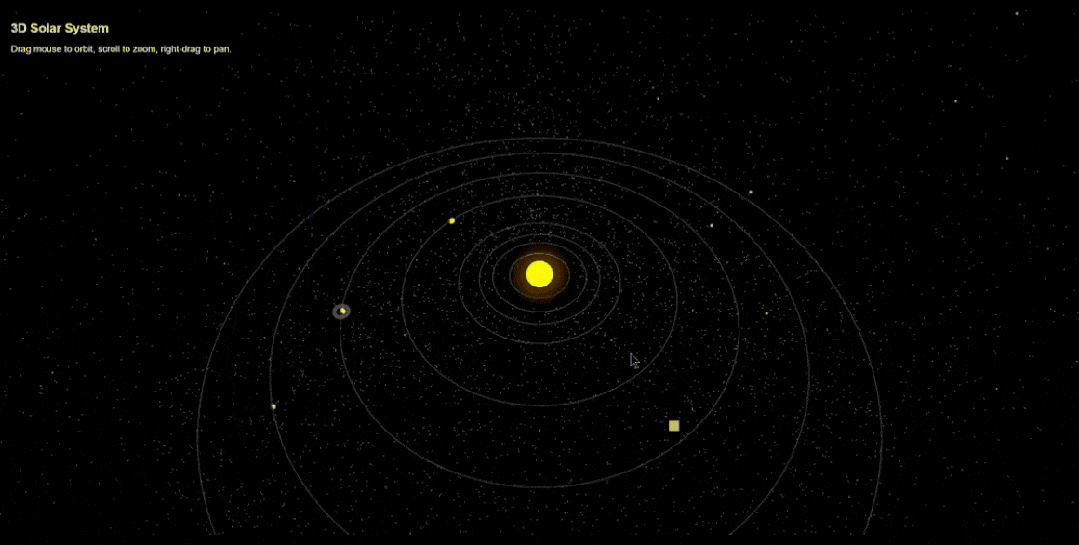
一系列演示,切切实实展示了Gemini 2.5 Pro强大编程能力。
现在如果你也想免费体验的话,可以前往Edge浏览器,安装DeepSider插件。
安装完成后,切换到Gemini 2.5 Pro模型即可。
DeepSider官网:https://www.deepsider.ai/


















 5745
5745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









