




 本文详细介绍了Java中的IO流,包括File类的使用、Lambda表达式、文件流、缓冲流、对象流、字符流、转换流等。重点讨论了文件输出流的覆盖与追加模式,以及缓冲流如何提高读写效率。同时,文章还涵盖了对象的序列化与反序列化,以及字符流与字节流的区别,特别是转换流在字节流与字符流之间的桥梁作用。
本文详细介绍了Java中的IO流,包括File类的使用、Lambda表达式、文件流、缓冲流、对象流、字符流、转换流等。重点讨论了文件输出流的覆盖与追加模式,以及缓冲流如何提高读写效率。同时,文章还涵盖了对象的序列化与反序列化,以及字符流与字节流的区别,特别是转换流在字节流与字符流之间的桥梁作用。
目录
File类
File类的每一个实例可以表示硬盘(文件系统)中的一个文件或目录(实际上表示的是一个抽象
路径)
File的作用:访问表示的文件或目录的属性信息,例如:名字,大小,修改时间等等
创建和删除文件或目录
访问一个目录中的子项
但是File不能访问文件数据
public class FileDemo {
public static void main(String[] args) {
//使用File访问当前项目目录下的demo.txt文件
/*
创建File时要指定路径,而路径通常使用相对路径。
相对路径的好处在于有良好的跨平台性。
"./"是相对路径中使用最多的,表示"当前目录",而当前目录是哪里
取决于程序运行环境而定,在idea中运行java程序时,这里指定的
当前目录就是当前程序所在的项目目录。
*/
// File file = new File("c:/xxx/xxx/xx/xxx.txt");
File file = new File("./demo1.2.3.423.txt");
//获取名字
String name = file.getName();
System.out.println(name);
//获取文件大小(单位是字节)
long len = file.length();
System.out.println(len+"字节");
//是否可读可写
boolean cr = file.canRead();
boolean cw = file.canWrite();
System.out.println("是否可读:"+cr);
System.out.println("是否可写:"+cw);
//是否隐藏
boolean ih = file.isHidden();
System.out.println("是否隐藏:"+ih);
}
}File类常用的方法
delete():删除File表示的文件,delete()方法可以删除一个目录,但是只有删除空目录
package file;
import java.io.File;
/**
* 使用File删除一个文件
*/
public class DeleteFileDemo {
public static void main(String[] args) {
//将当前目录下的test.txt文件删除
/*
相对路径中"./"可以忽略不写,默认就是从当前目录开始的。
*/
File file = new File("test.txt");
if(file.exists()){
file.delete();
System.out.println("文件已删除!");
}else{
System.out.println("文件不存在!");
}
}
}package file;
import java.io.File;
/**
* 删除一个目录
*/
public class DeleteDirDemo {
public static void main(String[] args) {
//将当前目录下的demo目录删除
File dir = new File("demo");
// File dir = new File("a");
if(dir.exists()){
dir.delete();//delete方法删除目录时只能删除空目录
System.out.println("目录已删除!");
}else{
System.out.println("目录不存在!");
}
}
}mkDir():创建当前File表示的目录
mkDirs():创建当前File表示的目录,同时将所有不存在的父目录一同创建
package file;
import java.io.File;
/**
* 使用File创建目录
*/
public class MkDirDemo {
public static void main(String[] args) {
//在当前目录下新建一个目录:demo
// File dir = new File("demo");
File dir = new File("./a/b/c/d/e/f");
if(dir.exists()){
System.out.println("该目录已存在!");
}else{
// dir.mkdir();//创建目录时要求所在的目录必须存在
dir.mkdirs();//创建目录时会将路径上所有不存在的目录一同创建
System.out.println("目录已创建!");
}
}
}listFiles()方法可以访问一个目录中的所有子项
package file;
import java.io.File;
/**
* 访问一个目录中的所有子项
*/
public class ListFilesDemo1 {
public static void main(String[] args) {
//获取当前目录中的所有子项
File dir = new File(".");
/*
boolean isFile()
判断当前File表示的是否为一个文件
boolean isDirectory()
判断当前File表示的是否为一个目录
*/
if(dir.isDirectory()){
/*
File[] listFiles()
将当前目录中的所有子项返回。返回的数组中每个File实例表示其中的一个子项
*/
File[] subs = dir.listFiles();
System.out.println("当前目录包含"+subs.length+"个子项");
for(int i=0;i<subs.length;i++){
File sub = subs[i];
System.out.println(sub.getName());
}
}
}
}重载的listFiles方法:File[] listFiles(FileFilter)
该方法要求传入一个文件过滤器,并仅将满足该过滤器要求的子项返回
package file;
import java.io.File;
import java.io.FileFilter;
/**
* 重载的listFiles方法,允许我们传入一个文件过滤器从而可以有条件的获取一个目录
* 中的子项。
*/
public class ListFilesDemo2 {
public static void main(String[] args) {
/*
需求:获取当前目录中所有名字以"."开始的子项
*/
File dir = new File(".");
if(dir.isDirectory()){
// FileFilter filter = new FileFilter(){//匿名内部类创建过滤器
// public boolean accept(File file) {
// String name = file.getName();
// boolean starts = name.startsWith(".");//名字是否以"."开始
// System.out.println("过滤器过滤:"+name+",是否符合要求:"+starts);
// return starts;
// }
// };
// File[] subs = dir.listFiles(filter);//方法内部会调用accept方法
File[] subs = dir.listFiles(new FileFilter(){
public boolean accept(File file) {
return file.getName().startsWith(".");
}
});
System.out.println(subs.length);
}
}
}Lambda表达式
JDK8之后,java支持了lambda表达式这个特性
lambda可以用更精简的代码创建匿名内部类,但是该匿名内部类实现的接口只能有一个抽象 方法,否则无法使用.
lambda表达式是编辑器认可的,最终会将其改为内部类编译到class文件中
package lambda;
import java.io.File;
import java.io.FileFilter;
/**
* JDK8之后java支持了lambda表达式这个特性
* lambda表达式可以用更精简的语法创建匿名内部类,但是实现的接口只能有一个抽象
* 方法,否则无法使用。
* lambda表达式是编译器认可的,最终会被改为内部类形式编译到class文件中。
* 语法:
* (参数列表)->{
* 方法体
* }
*/
public class LambdaDemo {
public static void main(String[] args) {
//匿名内部类形式创建FileFilter
FileFilter filter = new FileFilter() {
public boolean accept(File file) {
return file.getName().startsWith(".");
}
};
FileFilter filter2 = (File file)->{
return file.getName().startsWith(".");
};
//lambda表达式中参数的类型可以忽略不写
FileFilter filter3 = (file)->{
return file.getName().startsWith(".");
};
/*
lambda表达式方法体中若只有一句代码,则{}可以省略
如果这句话有return关键字,那么return也要一并省略!
*/
FileFilter filter4 = (file)->file.getName().startsWith(".");
}
}IO流
java io可以让我们用标准的读写操作来完成对不同设备的读写数据工作
java将IO按照方法方向划分为输入与输出,参照点是我们写的程序
输入:用来读取数据的,是从外界到程序的方向,用于获取数据
输出:用来写出数据的,是从程序到外界的方向,用于发送数据
java将IO比喻为"流",即:stream,就像生活中"电流","水流"一样,它是以同一个方向顺序移动的过程,只不过这里流动的是字节(2进制数据).所以在IO中有输入流和输出流之分,我们理解他们是连接程序与另一端的"管道",用于获取或发送数据到另一端
Java定义了两个超类(抽象类):
java.io.InputStream:所有字节输入流的超类,其中定义了读取数据的方法,因此将来不管读取的是什么设备(连接该设备的流)都有这些读取的方法,因此我们可以用相同的方法读取不同设备中的数据
java.io.OutoutStream:所有字节输出流的超类,其中定义了写出数据的方法
java将流分为两类:节点流与处理流
节点流:也称为低级流,节点流的另一端是明确的,是实际读写数据的流,读写一定是建立在节点流基础上进行的
处理流:也称为高级流,处理流不能独立存在,必须连接在其他流上,目的是当数据流经当前流时对数据进行加工处理来简化我们对数据的该操作
实际应用中,我们可以通过串联一组高级流到某个低级流上以流水线式的加工处理对某设备的数据进行读写,这个过程也称为流的连接,这也是IO的精髓所在。
文件流
文件流是一对低级流,用于读写文件数据的流,用于连接程序与文件的管道。负责读写文件数据。
文件输出流
package io;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* JAVA IO
* IO:Input,Output 即:输入与输出
* JAVA IO用于我们程序可以和外界交换数据。用于与外界的数据进行读写操作的。
* java中将输入与输出比喻为"流":stream
* 如何理解流:将流想象为一个连接我们程序和另一端的"管道",在其中按照同一方向顺序移动的数据。
* 有点像"水管"中向着统一方向流动的水。
* 输入流:从外界向我们的程序中移动的方向,因此是用来获取数据的流,作用就是:读取操作
* 输出流:写出操作
* 注意:流是单向的,输入永远用来读,输出永远用来写。将来我们在实际开发中希望与程序交互的另一端
* 互相发送数据时,我们只需要创建一个可以连接另一端的"流",进行读写操作完成。
*
* java定义了两个超类,来规范所有的字节流
* java.io.InputStream:所有字节输入流的超类(抽象类),里面定义了读取字节的相关方法。
* 所有字节输入流都继承自它
* java.io.OutputStream:所有字节输出流的超类(抽象类),里面定义了写出字节的相关方法。
* 所有的字节输出流都继承自它
*
*
* 文件流
* java.io.FileInputStream和java.io.FileOutputStream
* 作用是真实连接我们程序和文件之间的"管道"。其中文件输入流用于从文件中读取字节。而文件输出流则
* 用于向文件中写入字节。
*
* 文件流是节点流
* JAVA IO将流划分为两类:节点流和处理流
* 节点流:俗称"低级流",特点:真实连接我们程序和另一端的"管道",负责实际读写数据的流
* 文件流就是典型的节点流,真实连接我们程序与文件的"管道",可以读写文件数据了。
* 处理流:俗称"高级流"
* 特点:
* 1:不能独立存在(单独实例化进行读写操作不可以)
* 2:必须连接在其他流上,目的是当数据"流经"当前流时,可以对其做某种加工操作,简化我们的工
作。
* 流的连接:实际开发中经常会串联一组高级流最终到某个低级流上,对数据进行流水线式的加工读写。
*
*/
public class FOSDemo {
public static void main(String[] args) throws IOException {
//需求:向当前目录的文件fos.dat中写入数据
/*
在创建文件输出流时,文件输出流常见的构造器:
FileOutputStream(String filename)
上述构造器会在创建时将该文件创建出来(如果该文件不存在才会这样做),自动创建
该文件的前提是该文件所在的目录必须存在,否则会抛出异常。
一个小技巧:在指定相对路径时,如果是从"当前目录"(./)开始的,那么"./"是可以忽略不写的
因为在相对路径中,默认就是从"./"开始
*/
// FileOutputStream fos = new FileOutputStream("./fos.dat");
FileOutputStream fos = new FileOutputStream("fos.dat");//与上面一句位置相同
/*
OutputStream(所有字节输出流的超类)中定义了写出字节的方法:
void write(int d)
写出一个字节,将给定的参数int值对应的2进制的"低八位"写出。
文件输出流继承OutputStream后就重写了该方法,作用是将该字节写入到文件中。
向文件中写入1个字节
fos.write(1)
将int值的1对应的2进制的"低八位"写如到文件第一个字节位置上
1个int值占4个字节,每个字节是一个8为2进制
int 1的2进制样子:
00000000 00000000 00000000 00000001
^^^^^^^^
写出的字节
write方法调用后,fos.dat文件中就有了1个字节,内容为:
00000001
再次调用:
fos.write(2)
int 2的2进制样子:
00000000 00000000 00000000 00000010
^^^^^^^^
写出的字节
write方法调用后,fos.dat文件中就有了2个字节,内容为:
00000001 00000010
上次写的 本次写的
*/
fos.write(1);
fos.write(2);
System.out.println("写出完毕!");
//注意!流使用完毕后要关闭,来释放底层资源
fos.close();
}
}文件输入流
package io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/**
* 使用文件输入流读取文件中的数据
*/
public class FISDemo {
public static void main(String[] args) throws IOException {
//将fos.dat文件中的字节读取回来
/*
fos.dat文件中的数据:
00000001 00000010
*/
FileInputStream fis = new FileInputStream("fos.dat");
/*
java.io.InputStream(所有字节输入流的超类)定义着读取字节的相关方法
int read()
读取1个字节并以int型整数返回读取到的字节内容,返回的int值中对应的2进制的"低八位"
就是读取到的数据。如果返回的int值为整数-1(这是一个特殊值,32位2进制全都是1)表达的
是流读取到了末尾了。
int read(byte[] data)
文件输入流重写了上述两个方法用来从文件中读取对应的字节。
fos.dat文件中的数据:
00000001 00000010
^^^^^^^^
第一次读取的字节
当我们第一次调用:
int d = fis.read();//读取的是文件中第一个字节
该int值d对应的2进制:
00000000 00000000 00000000 00000001
|------自动补充24个0-------| ^^^^^^^^
读取到的数据
而该2进制对应的整数就是1.
*/
int d = fis.read();//读取到的就是整数1
System.out.println(d);
/*
fos.dat文件中的数据:
00000001 00000010
^^^^^^^^
第二次读取的字节
当我们第二次调用:
d = fis.read();//读取的是文件中第二个字节
该int值d对应的2进制:
00000000 00000000 00000000 00000010
|------自动补充24个0-------| ^^^^^^^^
读取到的数据
而该2进制对应的整数就是2.
*/
d = fis.read();//2
System.out.println(d);
/*
fos.dat文件中的数据:
00000001 00000010 文件末尾
^^^^^^^^
没有第三个字节
当我们第三次调用:
d = fis.read();//读取到文件末尾了!
该int值d对应的2进制:
11111111 11111111 11111111 11111111
该数字是正常读取1个字节永远表达不了的值。并且-1的2进制格式好记。因此用它表达读取
到了末尾。
*/
d = fis.read();//-1
System.out.println(d);
fis.close();
}
}文件复制
package io;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 利用文件输入流与输出流实现文件的复制操作
*/
public class CopyDemo {
public static void main(String[] args) throws IOException {
//用文件输入流读取待复制的文件
// FileInputStream fis = new FileInputStream("image.jpg");
FileInputStream fis = new FileInputStream("01.rmvb");
//用文件输出流向复制文件中写入复制的数据
// FileOutputStream fos = new FileOutputStream("image_cp.jpg");
FileOutputStream fos = new FileOutputStream("01_cp.rmvb");
/*
原文件image.jpg中的数据
10100011 00111100 00001111 11110000....
^^^^^^^^
读取该字节
第一次调用:
int d = fis.read();
d的2进制:00000000 00000000 00000000 10100011
读到的字节
fos向复制的文件image_cp.jpg中写入字节
第一次调用:
fos.write(d);
作用:将给定的int值d的2进制的"低八位"写入到文件中
d的2进制:00000000 00000000 00000000 10100011
写出字节
调用后image_cp.jpg文件数据:
10100011
*/
/*
循环条件是只要文件没有读到末尾就应该复制
如何直到读取到末尾了呢?
前提是:要先尝试读取一个字节,如果返回值是-1就说明读到末尾了
如果返回值不是-1,则说明读取到的是一个字节的内容,就要将他写入到复制文件中
*/
int d;//先定义一个变量,用于记录每次读取到的数据
long start = System.currentTimeMillis();//获取当前系统时间
while ((d = fis.read()) != -1) {
fos.write(d);
}
long end = System.currentTimeMillis();
System.out.println("复制完毕!耗时:" + (end - start) + "ms");
fis.close();
fos.close();
}
}块读写的文件复制操作
int read(byte[] data) 一次性从文件中读取给定的字节数组总长度的字节量,并存入到该数组中。返回值为实际读取到的字节量,若返回值为-1则表示读取到了文件末尾
块写操作void write(byte[] data)一次性将给定的字节数组所有字节写入到文件中
void write(byte[] data,int offset,int len)一次性将给定的字节数组从下标offset处开始的连续len个字节写入文件
package io;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 通过提高每次读写的数据,减少读写次数可以提高读写效率。
*/
public class CopyDemo2 {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("01.rmvb");
FileOutputStream fos = new FileOutputStream("01_cp.rmvb");
/*
块读:一次性读取一组字节
块写:一次性将写出一组字节
java.io.InputStream上定义了块读字节的方法:
int read(byte[] data)
一次性读取给定字节数组length个字节并从头开始装入到数组中。返回值为实际读取到的字节量
如果返回值为-1则表示流读取到了末尾。
文件流重写了该方法,作用是块读文件里的数据。
java.io.OutputStream上定义了块写字节的方法:
void write(byte[] data)
一次性将给定的字节数组中所有的字节写出。
void write(byte[] data,int offset,int len)
一次性将给定的字节数组data中从下标offset处开始的连续len个字节写出。
原文件数据(假设文件共6个字节):
11110000 00001111 01010101 11111111 00000000 10101010
byte[] buf = new byte[4];//创建一个长度为4的字节数组
buf默认的样子(每个元素若以2进制表现):{00000000,00000000,00000000,00000000}
int len;//记录每次实际读取的字节数
当第一次调用:
len = fis.read(buf);
由于字节数组buf的长度为4.因此可以一次性最多从文件中读取4个字节并装入到buf数组中
返回值len表示的整数是这次实际读取到了几个字节。
原文件数据(假设文件共6个字节):
11110000 00001111 01010101 11111111 00000000 10101010
^^^^^^^^ ^^^^^^^^ ^^^^^^^^ ^^^^^^^^
第一次读取的4个字节
buf:{11110000,00001111,01010101,11111111}
len:4 表示本次读取到了4个字节
第二次调用:
len = fis.read(buf);
原文件数据(假设文件共6个字节):
11110000 00001111 01010101 11111111 00000000 10101010 文件末尾了
^^^^^^^^ ^^^^^^^^ ^^^^^^^^ ^^^^^^^^
本次实际只能读取到2个字节
buf:{00000000,10101010,01010101,11111111}
|本次新读的2字节数据| |---上次的旧数据---|
len:2表示本次实际只读取到了2个字节。它的意义就是告诉你buf数组中前几个字节是本次真实
读取到的数据
第三次调用:
len = fis.read(buf);
原文件数据(假设文件共6个字节):
11110000 00001111 01010101 11111111 00000000 10101010 文件末尾了
^^^^^^^^ ^^^^^^^^ ^^^^^^^^ ^^^^^^^^
buf:{00000000,10101010,01010101,11111111} 没有任何变化!
len:-1 表示本次读取时已经是文件末尾了!!
*/
/*
00000000 8位2进制 1byte 1字节
1024byte = 1kb
1024kb = 1mb
1024mb = 1gb
1024gb = 1tb
编译完该句代码:byte[] buf = new byte[10240];
在实际开发中,有时候用一个计算表达式更能表现这个值的含义时,我们不妨使用计算表达式
long t = 864000000;
long t = 60 * 60 * 24 * 1000;
*/
byte[] buf = new byte[1024 * 10];//10kb
int len;//记录每次实际读取到的字节数
long start = System.currentTimeMillis();
while ((len = fis.read(buf)) != -1) {
fos.write(buf, 0, len);
}
long end = System.currentTimeMillis();
System.out.println("复制完毕,耗时:" + (end - start) + "ms");
fis.close();
fos.close();
}
}文件流有两种创建方式
文件输出流-覆盖模式:
FileOutputStream(String filename)
FileOutputStream(File file)
所谓覆盖模式:文件流在创建是若发现该文件已存在,则会将该文件原内容全部删除。然后在陆续将通过该流写出的内容保存到文件中。
String提供方法:byte[] getBytes(String charsetName)将当前字符串转换为一组字节参数为字符集的名字,常用的是UTF-8。其中中文字3字节表示1个,英文1字节表示1个
package io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/**
* 使用文件输出流向文件中写入文本数据
*/
public class WriteStringDemo {
public static void main(String[] args) throws IOException {
/*
1:创建一个文件输出流
2:将写出的文字先转换为2进制(一组字节)
3:关闭流
*/
FileOutputStream fos = new FileOutputStream("fos.txt",true);
String line = "今天天气真不错!";
/*
String提供了将内容转换为一组字节的方法:getBytes()
java.nio.charset.StandardCharsets
*/
byte[] data = line.getBytes(StandardCharsets.UTF_8);
fos.write(data);
line = "今天在下大雨~~";
data = line.getBytes(StandardCharsets.UTF_8);
fos.write(data);
System.out.println("写出完毕!");
fos.close();
}
}文件输出流-追加模式
FileOutputStream(String path,boolean append)
FileOutputStream(File file,boolean append)
当第二个参数传入true时,文件流为追加模式,即:指定的文件若存在,则原有数据保留,新写入的数据会被顺序的追加到文件中
package io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/**
* 使用文件输出流向文件中写入文本数据
*/
public class WriteStringDemo {
public static void main(String[] args) throws IOException {
FileOutputStream fos = new FileOutputStream("fos.txt",true);
String line = "娃哈哈!";
byte[] data = line.getBytes(StandardCharsets.UTF_8);
fos.write(data);
line = "真不错!";
data = line.getBytes(StandardCharsets.UTF_8);
fos.write(data);
System.out.println("写出完毕!");
fos.close();
}
}
读取文本数据
package io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/**
* 从文件中读取文本数据
*/
public class ReadStringDemo {
public static void main(String[] args) throws IOException {
/*
1:创建一个文件输入流
2:从文件中将字节都读取回来
3:将读取到的字节转换回字符串
*/
FileInputStream fis = new FileInputStream("fos.txt");
byte[] data = new byte[1024];//1kb
int len = fis.read(data);//块读操作,返回值表达实际读取到了多少字节
System.out.println("实际读取了:"+len+"个字节");
/*
String提供了构造方法可以将一个字节数组还原为字符串
String(byte[] data,Charset charset)
将给定的字节数组data中所有字节按照给定的字符集转换为字符串。
String(byte[] data,int offset,int len,Charset charset)
将给定的字节数组data从下标offset处开始的连续len个字节按照指定的字符集转换为字符串
*/
String line = new String(data,0,len,StandardCharsets.UTF_8);
System.out.println(line.length());//输出字符串长度
System.out.println(line);
fis.close();
}
}缓冲流
缓冲流是一对高级流,作用是提高读取数据的效率。
java.io.BufferedOutputStream和BufferedInputStream
缓冲流内部有一个字节数组,默认长度是8k.缓冲流读写数据时一定是将数据的读写方式转换为块读写来保证读写效率。
使用缓冲流完成文件复制操作
import java.io.*;
/**
* java将流分为节点流与处理流两类
* 节点流:也称为低级流,是真实连接程序与另一端的"管道",负责实际读写数据的流。
* 读写一定是建立在节点流的基础上进行的。
* 节点流好比家里的"自来水管"。连接我们的家庭与自来水厂,负责搬运水。
* 处理流:也称为高级流,不能独立存在,必须连接在其他流上,目的是当数据经过当前流时
* 对其进行某种加工处理,简化我们对数据的同等操作。
* 高级流好比家里常见的对水做加工的设备,比如"净水器","热水器"。
* 实际开发中我们经常会串联一组高级流最终连接到低级流上,在读写操作时以流水线式的加工
* 完成复杂IO操作。这个过程也称为"流的连接"。
*
* 缓冲流,是一对高级流,作用是加快读写效率。
* java.io.BufferedInputStream和java.io.BufferedOutputStream
*/
public class CopyDemo3 {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("ppt.pptx");
BufferedInputStream bis = new BufferedInputStream(fis);
FileOutputStream fos = new FileOutputStream("ppt_cp.pptx");
BufferedOutputStream bos = new BufferedOutputStream(fos);
int d;
long start = System.currentTimeMillis();
while((d = bis.read())!=-1){//使用缓冲流读取字节
bos.write(d);//使用缓冲流写出字节
}
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-start)+"ms");
bis.close();//关闭流时只需要关闭高级流即可,它会自动关闭它连接的流
bos.close();
}
}缓冲输出流写出数据时的缓冲区问题
通过缓冲流写出的数据会被临时存入缓冲流内部的字节数组,直到数组存放满数据才会真是写出一次
import java.io.BufferedOutputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/**
* 缓冲输出流写出数据的缓冲区问题
*/
public class BOS_FlushDemo {
public static void main(String[] args) throws IOException {
FileOutputStream fos = new FileOutputStream("bos.txt");
BufferedOutputStream bos = new BufferedOutputStream(fos);
String line = "真不错!";
byte[] data = line.getBytes(StandardCharsets.UTF_8);
bos.write(data);
System.out.println("写出完毕!");
/*
缓冲流的flush方法用于强制将缓冲区中已经缓存的数据一次性写出。
注:该方法实际上实在字节输出流的超类OutputStream上定义的,并非只有缓冲
输出流有这个方法。但是实际上只有缓冲输出流的该方法有实际意义,其他的流实现
该方法的目的仅仅是为了在流连接过程中传递flush动作给缓冲输出流。
*/
bos.flush();//冲
bos.close();
}
}对象流
对象流是一对高级流,在流连接中的作用是进行对象的序列化与反序列化
对象序列化:将对象转化为可传输的字节序列过程
对象反序列化:将字节序列还原为对象的过程
序列化最终的目的是为了对象数据存储,或者进行网络传输
java.io.ObjectOutputStream和ObjectInputStream
对象序列化:
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
/**
* 对象序列化
* java.io.ObjectInputStream和ObjectOutputStream
* 它们是一对高级流,在流连接中负责进行对象的序列化与反序列化
*/
public class OOSDemo {
public static void main(String[] args) throws IOException {
//将一个Person对象写入文件person.obj中
String name = "张三";
int age = 20;
String gender = "男";
String[] otherInfo = {"天天学习","成绩好","老师都喜欢"};
Person p = new Person(name,age,gender,otherInfo);
FileOutputStream fos = new FileOutputStream("person.obj");
ObjectOutputStream oos = new ObjectOutputStream(fos);
/*
当我们将对象输出流连接到文件流上,把一个对象写出时,会经历以下操作:
1:对象先经过对象输出流writeObject(p)
该方法会将该对象按照其结构转换为一组字节,这个过程称为对象序列化
2:对象输出流会将序列化后的一组字节再经过其连接的文件输出流最终将这组
字节写入到文件中保存(写入到磁盘),该过程称为:数据持久化。
执行writeObject()进行序列化对象时抛出异常:
java.io.NotSerializableException
原因:
对象输出流在序列化是要求序列化的对象必须实现了接口:
java.io.Serializable
*/
oos.writeObject(p);
System.out.println("写出完毕!");
oos.close();
}
}
对象反序列化 :
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.ObjectInputStream;
/**
* 使用对象输入流完成对象的反序列化
*/
public class OISDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//从person.obj文件中将对象反序列化回来
FileInputStream fis = new FileInputStream("person.obj");
ObjectInputStream ois = new ObjectInputStream(fis);
/*
Object readObject()
该方法会进行对象的反序列化,如果对象流通过其连接的流读取的字节分析并非
是一个java对象时,会抛出异常:ClassNotFoundException
*/
Person p = (Person)ois.readObject();
System.out.println(p);
}
}需要进行序列化的类必须实现接口:java.io.Serializable实现序列化接口,最好主动定义序列化版本号这个常量。这样一来对象序列化时就不会根据类的结构生成一个版本号,而是使用该固定值。那么反序列化时,只要还原的对象和当前类的版本号一致就可以进行还原。
transient关键字可以修饰属性,用于在进行对象序列化时忽略不必要的属性,达到对象瘦身的目的。
import java.io.Serializable;
import java.util.Arrays;
/**
* JAVA BEAN设计规范
* 1:属性私有化
* 2:为属性提供公开的get和set方法
* 3:要有公开的无参构造器
*/
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private transient int age;
private String gender;
private String[] otherInfo;
public Person(){}
public Person(String name, int age, String gender, String[] otherInfo) {
this.name = name;
this.age = age;
this.gender = gender;
this.otherInfo = otherInfo;
}
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public String getGender() { return gender; }
public void setGender(String gender) { this.gender = gender; }
public String[] getOtherInfo() { return otherInfo;}
public void setOtherInfo(String[] otherInfo) { this.otherInfo = otherInfo;}
}
字符流
java将流按照读写单位划分为字节流与字符流
java.io.InputStream和OutputStream是所有字节流的超类
java.io.Reader和Writer则是所有字符流的超类
Reader和Writer是两个抽象类,里面规定了所有字符流都必须具备读写字符的相关方法
字符流最小读写单位是字符(char),但是底层实际还是读写字节,只是字符与字节的转换工作由字符流完成。
转换流
java.io.InputStreamReader和OutputStreamWriter
import java.io.*;
import java.nio.charset.StandardCharsets;
/**
* 转换流(是一对高级流,同时是一对字符流)
* 作用:
* 1:衔接字节流与其他字符流
* 2:将字符与字节相互转换
* 实际开发中我们不会直接使用这一对流,但是在流连接中它是重要的一环。
*/
public class OSWDemo {
public static void main(String[] args) throws IOException {
/*
使用这一对流演示转换流的读写字符方法
java.io.Writer所有字符输出流的超类上,定义了写出字符的相关方法
void write(int d)写出一个字符,实际传入的应当是一个char。
void write(char[] data)
void write(char[] data,int offset,int len)
void write(String str) 直接写出一个字符串
*/
FileOutputStream fos = new FileOutputStream("osw.txt");
OutputStreamWriter osw = new OutputStreamWriter(fos,StandardCharsets.UTF_8);
String line = "好好学习,天天向上。";
osw.write(line);//转换流的write(String str)会将写出的字符串转换为字节,然后写出
osw.write("今天天气真不错,over。");
System.out.println("写出完毕!");
osw.close();
}
}使用转化输入流读取文本文件
import java.io.*;
/**
* 转换字符输入流
* 可以将读取的字节按照指定的字符集转换为字符
*/
public class ISRDemo {
public static void main(String[] args) throws IOException {
//将osw.txt文件中的所有文字读取回来.
FileInputStream fis = new FileInputStream("osw.txt");
InputStreamReader isr = new InputStreamReader(fis,"UTF-8");
/*
字符流读一个字符的read方法定义:
int read()
读取一个字符,返回的int值实际上表示的是一个char(低16位有效).如果返回的
int值表示的是-1则说明EOF
*/
//读取文件中第一个字
// int d = isr.read();
// char c = (char)d;
// System.out.println(c);
//循环将文件所有字符读取回来
int d;
while((d = isr.read()) != -1){
System.out.print((char)d);
}
isr.close();
}
}转换流的意义:
实际开发中我们还有功能更好用的字符高级流,但是其他的字符高级流都有一个共同点:不能直接连接在字节流上,而实际操作设备的流都是低级流同时也是字节流,因此不能直接在流连接中串联起来,转换流是一对可以连接在字节流上的字符流,其他的高级字符流可以连接在转换流上。字符流在流连接中起到“转换器”的作用,负责字符与字节的实际转换。
缓冲字符流
java.io.BufferedWriter和BufferedReader
缓冲字符流内部也有一个缓冲区,读写文本数据以块读形式加快效率,并且缓冲流有一个特别的功能,可以按行读写文本数据。
java.io.PrintWriter具有自动行刷新的缓冲字符输出流,实际开发中更常用,它内部总是会自动连接BufferedWriter作为块写加速使用。
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintWriter;
import java.io.UnsupportedEncodingException;
/**
* 缓冲字符流(是一对高级流)
* java.io.BufferedWriter和BufferedReader
* 缓冲流内部维护一个char数组,默认长度8k.以块读写方式读写字符数据保证效率
*
* java.io.PrintWriter则是具有自动行刷新的换成字符输出流(实际缓冲功能是靠BufferedWriter
* 实现的,它内部总是连接着这个流。)
* 使用缓冲字符流后就可以实现按行读写字符串,并且读写效率高。
*/
public class PWDemo1 {
public static void main(String[] args) throws FileNotFoundException, UnsupportedEncodingException {
//按行向文件pw.txt中写入字符串
/*
PrintWriter继承自Writer.
它提供很多构造方法,其中就有可以直接对文件进行写操作的构造器
PrintWriter(File file)
PrintWriter(String filename)
*/
// PrintWriter pw = new PrintWriter("pw.txt");
/*
这里可以按照指定的字符集写出字符串到文本文件中。但是字符集只能以字符串形式
表达。因此注意拼写。字符集不区分大小写。
但是如果字符集名字拼写错误,会抛出异常:
UnsupportedEncodingException
不支持的 字符集 异常
*/
PrintWriter pw = new PrintWriter("pw.txt","UTF-8");
/*
println()方法是输出字符出后带上换行符
print()方法输出字符串后不带换行符
*/
pw.println("好好学习,天天向上");
pw.println("我们只是大自然的搬运工");
System.out.println("写出完毕!");
pw.close();
}
}PrintWriter的自动行刷新功能:如果实例化PW时第一个参数传入的是一个流,则此时可以再传入一个boolean型的参数,此值为true时就打开了自动刷新功能。即:每当我们用PW的println方法写出一行字符串后自动flush。
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
/**
* 练习PrintWriter的流连接操作
完成一个简易记事本工具:
将控制台上输入的每一行字符串按行写入到该文件中
如果单独输入exit,则程序退出。
思路:
用一个死循环,重复做下面的工作
1:在控制台上输入一行字符串
2:判断输入的字符串是否为"exit"
若是:则break掉循环退出程序
若不是:则将输入的字符串通过println方法写入文件
*/
public class PWDemo2 {
public static void main(String[] args) throws FileNotFoundException {
//文件输出流(低级流,字节流) 作用:向文件中写出字节
FileOutputStream fos = new FileOutputStream("pw2.txt");
//转换输出流(高级流,字符流) 作用:1衔接字符与字节流的 2:将写出的字符转换为字节
OutputStreamWriter osw = new OutputStreamWriter(fos, StandardCharsets.UTF_8);
//缓冲字符输出流(高级流,字符流) 作用:块写文本数据加速的(内部有一个8k的char数组)
BufferedWriter bw = new BufferedWriter(osw);
//具有自动行刷新功能(高级流,字符流) 作用:1按行写出字符串(println) 2:自动行刷新
PrintWriter pw = new PrintWriter(bw,true);
Scanner scanner = new Scanner(System.in);
while(true) {
String line = scanner.nextLine();
if("exit".equals(line)){
break;
}
pw.println(line);
}
System.out.println("写出完毕!");
pw.close();
}
}缓冲字符输入流
java.io.BufferedReader是一个高级的字符流,特点是块读文本数据,并且可以按行读取字符串
import java.io.*;
/**
* 使用缓冲字符输入流按行读取字符串
* 该高级流的主要作用:
* 1:块读文本数据加速(内部有一个默认8k的char数组)
* 2:可以按行读取字符串
*/
public class BRDemo {
public static void main(String[] args) throws IOException {
//将当前源代码输出到控制台上
/*
思路:
读取当前源代码文件,按行读取,并且将读取到的每一行字符串都输出到控制台上即可
*/
//文件输入流(低级流,字节流) 作用:从文件中读取字节
FileInputStream fis = new FileInputStream("./src/io/BRDemo.java");
//转换输入流(字符流,高级流) 作用:1衔接字节与字符流 2将读取的字节转换为字符
InputStreamReader isr = new InputStreamReader(fis);
//缓冲字符输入流(字符流,高级流) 作用:1块读字符数据加速 2按行读取字符串
BufferedReader br = new BufferedReader(isr);
/*
BufferedReader缓冲字符输入流
提供了一个独有的方法:readLine()
作用:读取一行字符串。连续读取若干字符直到遇到了换行符位置,并将换行符之前的
内容返回。注意:返回的字符串里不包含最后的换行符。
特殊情况:
如果这一行只有一个换行符,那么返回值为空字符串:""
如果读取到了流的末尾,那么返回值为null。
实际运行时:
当我们第一次调用readLine()方法时,缓冲字符输入流实际会一次性读取8k的char
回来并存入内部的char数组中(块读文本操作)。readLine方法只将char数组中从头
开始一直到第一个换行符位置的内容以一个字符串形式返回。
*/
String line;
while((line = br.readLine()) != null){
System.out.println(line);
}
br.close();
}
}IO总结
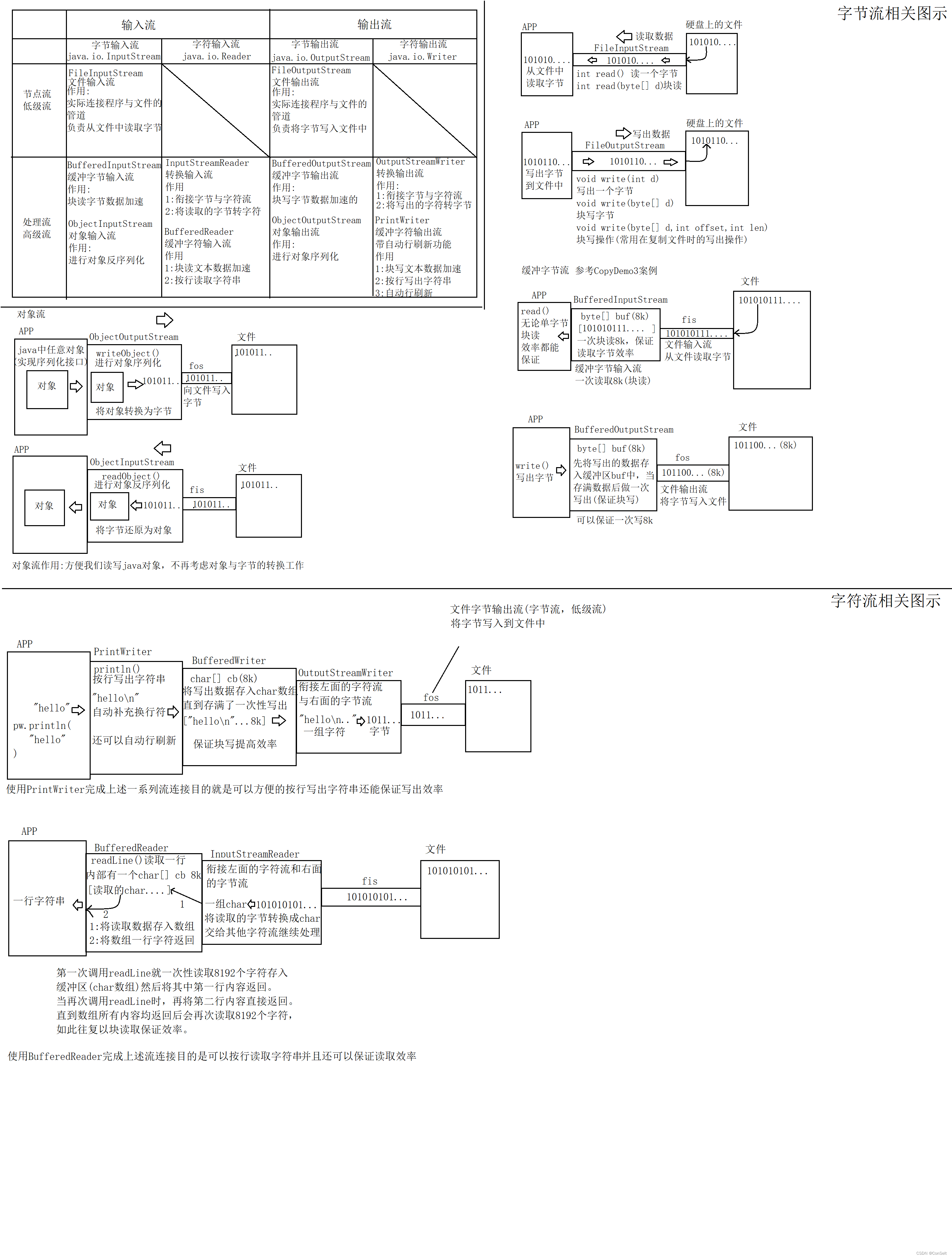
Java将流分为两类:节点流与处理流
节点流:也称为低级流
节点流的另一端是明确的,是实际读写数据的流,读写一定是建立在节点流基础上进行的
处理流:也称为高级流
处理流不能独立存在,必须连接在其他流上,目的是当数据流经当前流时对数据进行加工处理来简化我们对数据的该操作。
Java定义了两个超类(抽象类)
java.io.InputStream:所有字节输入流的超类,其中定义了读取数据的方法,因此将来不管是什么设备(连接该设备的流)都是这些读取的方法,因此我们可以用相同的方法去读不同设备中的数据
常用方法:
int read():读取一个字节,返回的int值低8位为读取的数据。如果返回值为整数-1则表示读取到了流的末尾
int read(byte[] data):块读取,最多读取data数组总长度的数据并从数组第一个位置开始存入到数组中,返回值表示实际读取到的字节量,如果返回值为-1表示本次没有读取到任何数据,是流的末尾。
java.io.OutputStream:所有字节输出流的超类,其中定义了写出数据的方法:
常用方法:
void write(int d):写出一个字节,写出的是给定的int值对应2进制的低八位
void write(byte[] data):块写,将给定字节数组中所有字节一次性写出
void write(byte[] data,int off,int len):块写,将给定字节数组从下标off处开始的连续len个字节一次性写出
java.io.FileOutputStream文件输出流,继承自java.io.OutputStream
覆盖模式对应的构造器:覆盖模式是指若指定的文件存在,文件流在创建时会先将该文件原内容清除
FileOutputStream(String pathname):创建文件输出流用于向指定路径表示的文件做写操作
FileOutputStream(File file):创建文件输出流用于向File表示的文件做写操作
注:如果写出的文件不存在文件流自动创建这个文件,但是如果该文件所在的目录不存在则会抛出异常:java.io.FileNotFoundException
追加写模式对应的构造器:追加模式是指若指定的文件存在,文件流会将写出的数据陆续追加到文件中
FileOutputStream(String pathname,boolean append):如果第二个参数为true则为追加模式,false则为覆盖模式
FileOutputStream(File file,boolean append):同理
常用方法:
void write(int d):向文件中写入一个字节,写入的是int值2进制的低八位
void write(byte[] data):向文件中块写数据。将数组data中所有字节一次性写入文件
void write(byte[] data,int off,int len):向文件中块写数据。将数组data中从下标off开始的连续len个字节一次性写入文件
java.io.FileInputStream文件输入流,继承自java.io.InputStream
FileInputStream(String pathname)创建读取指定路径下对应的文件的文件输入流,如果指定的文件不存在则会抛出异常java.io.FileNotFoundException
FileInputStream(File file)创建读取File表示的文件的文件输入流,如果File表示的文件不存在则会抛出异常java.io.IOException
常用方法:
int read():从文件中读取一个字节,返回的int值低八位有效,如果返回的int值为整数-1,则表示读取到了文件末尾
int read(byte[] data):块读数据,从文件中一次性读取给定的data数组总长度的字节量并从数组第一个元素位置开始存入数组中。返回值为实际读取到的字节数。如果返回值为整数-1则表示读取到了文件末尾。
缓冲流是一对高级流,在流链接中链接它的目的是加快读写效率。缓冲流内部默认缓冲区为8kb,缓冲流总是块读写数据来提高读写效率。
java.io.BufferedOutputStream缓冲字节输出流,继承自java.io.OutputStream
常用构造器:
BufferedOutputStream(OutputStream out):创建一个默认8kb大小缓冲区的缓冲字节输出流,并连接到参数指定的字节输出流上
BufferedOutputStream(OutputStream out,int size):创建一个size指定大小(单位是字节)缓冲区的缓冲字节输出流,并连接到参数指定的字节输出流上
常用方法:
flush():强制将缓冲区中已经缓存的数据一次性写出
缓冲流的写出方法功能与OutputStream一致,需要知道的是write方法调用后并非实际写出,而是先将数据存放入缓冲区(内部的字节数组中),当缓冲区满了时会自动写出一次。
java.io.BufferedInputStream缓冲字节输出流,继承自java.io.InputStream
常用构造器:
BufferedInputStream(InputStream in):创建一个默认8kb大小缓冲区的缓冲字节输入流,并连接到参数指定的字节输入流上。
BufferedInputStream(InputStream in,int size):创建一个size指定大小(单位是字节)缓冲区的缓冲字节输入流,并连接到参数指定的字节输入流上。
常用方法:
缓冲流的读取方法功能与InputStream一致,需要知道的是read方法调用后缓冲流会一次性读取缓冲区大小的字节数据并存入缓冲区,然后再根据我们调用read方法读取的字节数进行返回,直到缓冲区所有数据都已经通过read方法返回后会再次读取一组数据进缓冲区。即块读操作。
对象流是一对高级流,在流连接中的作用是完成对象的序列化与反序列化
序列化:是对象输出流的工作,将一个对象按照其结构转换为一组字节的过程
反序列化:是对象输入流的工作,将一组字节还原为对象的过程
java.io.ObjectInputStream对象输入流,继承自java.io.InputStream
常用构造器
ObjectInputStream(InputStream in):创建一个对象输入流并连接到参数in这个输入流上。
常用方法
Object readObject():进行对象反序列化,将读取的字节转换为一个对象并以Object形式返回(多态)
如果读取的字节表示的不是一个java对象会抛出异常:java.io.ClassNotFoundException
java.io.ObjectOutputStream对象输出流,继承自java.io.OutputStream
常用构造器
ObjectOutStream(OutputStream out):创建一个对象输出流并连接到参数out这个输出流上
常用方法
void writeObject(Object obj):进行对象的反序列化,将一个java对象序列化成一组字节后再通过连接的输出流将这组字节写出
如果序列化的对象没有实现序列化接口:java.io.Serializable就会抛出异常:java.io.NotSerializableException
序列化接口java.io.Serrializable
该接口没有任何抽象方法,但是只有实现了该接口的类的实例才能进行序列化与反序列化
实现了序列化接口的类建议显示的定义常量:static final long serialVersionUID=1L
可以为属性添加关键字transient,被该关键字修饰的属性在序列化时会被忽略,达到对象序列化瘦身的目的
Java将流按照读写单位划分为字节与字符流,字节流以字节为单位读写,字符流以字符为单位读写。
转换流:java.io.InputStreamReader和OutputStreamWriter
核心意义:衔接其他字节与字符流
将字符与字节进行转换
缓冲字符输出流:BufferedReader和PrintWriter
作用:块写或块读文本数据加速
可以按行写或读字符串
java.io.PrintWriter具有自动行刷新的缓冲字符输出流
构造器
PrintWriter(String filename):可以直接对给定路径的文件进行写操作
PrintWriter(File file):可以直接对FIle表示的文件进行写操作
PrintWriter(OutputStream out):将PW连接在给定的字节流上(构造方法内部会自行完成转换流等流连接)
PrintWriter(Writer writer):将PW连接在其他字符流上
PrintWriter(OutputStream out,boolean autoflush)
PrintWriter(Writer writer,boolean autoflush)
上述两个构造器可以在连接到流上的同时传入第二个参数,如果该值为true则开启了自动行刷新功能
常用方法
void println(String line):按行写出一行字符串
特点:自动行刷新,当打开该功能后,每当使用println方法写出一行字符串后就会自动flush

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









