







第42章 线程和任务(Threads and Tasks)
目录
42.2.7 (优雅地)结束一个thread(Killing a thread)
42.2.8 thread_local数据(thread_local Data)
42.3 避免数据竞争(Avoiding Data Races)
42.3.1.1 mutex和recursive_mutex
42.3.1.3 timed_mutex 和 recursive_timed_mutex
42.3.1.4 lock_guard 和 unique_lock
42.3.4 条件变量(Condition Variables)
42.3.4.1 condition_variable_any
42.4 基于任务的并发(Task-Based Concurrency)
42.1 引言(Introduction)
并发——即同时执行多个任务——被广泛用于提高吞吐量(通过使用多个处理器进行单个计算)或提高响应速度(通过允许程序的一部分继续执行,而另一部分等待响应)。
§5.3 以教程的方式介绍了 C++ 标准对并发的支持。本章和上一章提供了更详细、更系统的观点。
我们将可能与其他活动并发执行的活动称为任务。线程是计算机执行任务的系统级功能表示。线程可以执行任务。线程可以与其他线程共享地址空间。也就是说,同一地址空间内的所有线程都可以访问相同的内存位置。并发系统开发程序员面临的核心挑战之一是确保线程以合理的方式访问内存。
42.2 线程(Threads)
一个thread是对计算机硬件计算概念的一种抽象。C++ 标准库中的thread旨在与操作系统线程一一对应。当程序中的多个任务需要并发执行时,我们会使用线程。在具有多个处理单元(“内核”)的系统中,thread允许我们利用这些单元。所有thread都在同一个地址空间中工作。如果你需要硬件保护来防止数据竞争,请使用进程的概念。thread之间不共享栈,因此局部变量不会受到数据竞争的影响,除非你不小心地将指向局部变量的指针传递给另一个thread。特别是,lambda 表达式中按引用绑定上下文的情况(§11.4.30。谨慎地共享栈内存是有用且常见的做法,例如,我们可以将局部数组的部分传递给并行排序。
如果一个thread无法继续执行(例如,因为它遇到了另一个thread拥有的mutex),则称该线程处于阻塞(blocked)或休眠(asleep)状态。
| thread (§iso.30.3.1) | |
| id | 一个thread修饰符类型 |
| native_handle_type | 系统线程句柄类型; 由实现定义(§iso.30.2.3) |
| thread t {}; | 默认构造函数:创建一个尚未有任务的thread;noexcept |
| thread t {t2}; | 移动构造函数;noexcept |
| thread t {f,args}; | 构造函数:在新thread上执行 f(args);explicit |
| t.˜thread(); | 析构函数:如果 t.joinable(),则 terminate();否则无影响 |
| t=move(t2) | 移动赋值:如果 t.joinable(),则终止();无例外 |
| t.swap(t2) | 交换 t 和 t2 的值;无例外 |
| t.joinable() | 是否存在与 t 关联的执行线程?t.get_id()!=id{}?; noexcept |
| t.join() | 将 t 与当前线程连接起来; 也就是说,阻塞当前线程直到 t 完成; 如果检测到死锁(例如,t.get_id() == this_thread::get_id()),则抛出 system_error 异常;如果 t.id == id{},则抛出 system_error 异常。 |
| t.detach() | 确保没有系统线程被 t 表示;如果 t.id!=id{},则抛出 system_error 异常。 |
| x=t.get_id() | x 是 t 的 id;noexcept |
| x=t.native_handle() | x 是 t 的本地句柄(native_handle_type 类型)。 |
| n=hardware_concurrency() | n 是硬件处理单元的数量(0 表示“未知”);noexcept |
| swap(t,t2) | t.swap(t2); noexcept |
thread代表系统资源,即系统线程,甚至可能拥有专用的硬件:
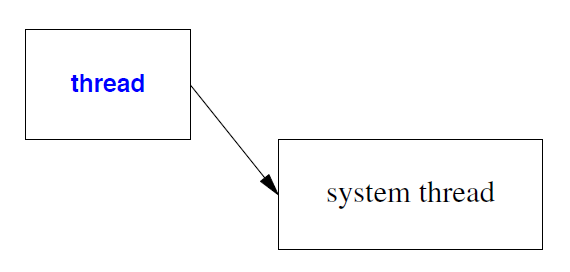
因此,thread可以移动但不能复制。
thread在成为移动的源之后,就不再代表一个计算线程。尤其不能再使用 join() 函数。
thread::hardware_concurrency() 操作会报告在硬件支持下可以同时运行的任务数量。其具体含义取决于架构,但通常小于操作系统提供的线程数(例如,通过时间复用或时间片轮转),有时大于处理器或“核心”的数量。例如,我的小型双核笔记本电脑报告有四个硬件线程(它使用了有时被称为超线程的技术)。
42.2.1 线程id(Identity)
每一个执行线程都有一个唯一的标识符,表示为 thread::id 类型的值。如果一个thread不代表一个执行线程,则其 id 为默认值 id{}。可以通过调用 t.get_id() 获取线程 t 的 id 。
可以通过 this_thread::get_id() 获取当前线程的 id(§42.2.6)。
对于一个 thread ,其可以拥有一个 id{} 作为其 id 的条件是:
• 它尚未分配任务,
• 它已终止,
• 它已被移出,或
• 它已被 detach() 。
每一个thread都有一个 id ,但即使系统线程没有 id(即在执行 detach() 之后),它仍然可能在运行。
thread::id 可以复制,id 可以使用常规的比较运算符(==、< 等)进行比较,使用 << 输出,并使用专门的 hash<thread::id> 进行哈希处理(§31.4.3.4)。例如:
void print_id(thread& t)
{
if (t.get_id()==id{})
cout << "t not joinable\n";
else
cout << "t's id is " << t.get_id() << '\n';
}
请注意,cout 是一个全局共享对象,因此除非确保没有两个thread同时写入 cout (§iso.27.4.1),否则不能保证这些输出语句会按可识别的顺序产生输出字符。
42.2.2 构造对象(Construction)
一个thread构造函数接受一个要执行的任务以及该任务所需的参数。参数的数量和类型必须与任务的要求相匹配。例如:
void f0(); // no arguments
void f1(int); // one int argument
thread t1 {f0};
thread t2 {f0,1}; // error : too many arguments
thread t3 {f1}; // error : too few arguments
thread t4 {f1,1};
thread t5 {f1,1,2}; // error : too many arguments
thread t3 {f1,"I'm being silly"}; // error : wrong type of argument
thread创建完成后,一旦运行时系统能够为其运行获取到所需的资源,线程就会立即开始执行其任务。可以理解为“立即执行”。不存在单独的“启动线程”操作。
如果你想构建一组任务并将它们链接起来(例如,通过消息队列进行通信),首先需要将这些任务构建为函数对象,然后在所有任务都准备就绪后启动thread。例如:
template<typename T>
class Sync_queue<T> { // a queue providing put() and get() without data races (§42.3.4)
// ...
};
struct Consumer {
Sync_queue<Message>& head;
Consumer(Sync_queue<Message>& q) :head(q) {}
void operator()(); // get messages from head
};
struct Producer {
Sync_queue<Message>& tail;
Consumer(Sync_queue<Message>& q) :tail(q) {}
void operator()(); // put messages on tail
};
Sync_queue<Message> mq;
Consumer c {mq}; // make tasks and ‘‘wire them together’’
Producer p {mq};
thread pro {p}; // finally: start threads
thread con {c};
// ...
尝试将thread创建与thread要运行的任务之间的连接设置穿插进行,很容易变得复杂且容易出错。
thread构造函数是可变参数模板(§28.6)。这意味着,要将引用传递给thread构造函数,我们必须使用引用包装器(wrapper)(§33.5.1)。例如:
void my_task(vector<double>& arg);
void test(vector<double>& v)
{
thread my_thread1 {my_task,v}; // oops: pass a copy of v
thread my_thread2 {my_task,ref(v)}; // OK: pass v by reference
thread my_thread3 {[&v]{ my_task(v); }}; // OK: dodge the ref() problem
// ...
}
问题在于可变参数模板使用了 bind() 或类似的机制,因此默认情况下会解引用并复制结果。所以,如果 v 的值为 {1,2,3},而 my_task 递增了元素,thread 将永远不会对 v 产生任何影响。请注意,所有三个thread都对 v 存在数据竞争;这是一个调用约定导致的问题,而非良好的并发编程风格。
vector<thread> worker(1000); // 1000 default threads
for (int i=0; i!=worker.siz e(); ++i) {
// ... compute argument for wor ker[i] and create wor ker thread tmp ...
worker[i] = move(tmp);
}
将任务从一个thread移动到另一个thread不会影响任务的执行。thread移动只会改变thread之间引用的对象。
42.2.3 析构对象(Destruction)
显然,thread析构函数会销毁thread对象。为了防止系统线程意外地比其自身thread的生命周期更长,thread析构函数会在thread是joinable() 时(即若 get_id!=id{} )的情况下调用 terminate() 来终止程序。例如:
void heartbeat()
{
while(true) {
output(steady_clock::now());
this_thread::sleep_for(second{1}); // §42.2.6
}
}
void run()
{
thread t {heartbeat};
} //terminate because heartbeat() is still running at the end of t’s scope
如果确实需要系统线程在其生命周期之外继续运行,请参阅 §42.2.5。
42.2.4 join()
t.join() 会告诉当前thread在 t 完成之前不要继续执行。例如:
void tick(int n)
{
for (int i=0; i!=n; ++i) {
this_thread::sleep_for(second{1}); // §42.2.6
output("Alive!");
}
}
int main()
{
thread timer {tick,10};
timer.join();
}
这将以大约 1 秒的间隔输出“Alive!”十次。如果缺少 timer.join(),程序会在 tick() 输出任何内容之前终止。join() 使主程序等待定时器完成。
如第 42.2.3 节所述,试图让线程在其作用域结束之后(或者更一般地说,在其析构函数执行之后)执行而不调用 detach() 会被视为程序的致命错误。然而,我们可能会忘记 join() 一个thread 。当我们把thread视为一种资源时,就会发现应该考虑资源获取与使用(RAII)原则(第 5.2 节,第 13.3 节)。考虑一个简单的测试示例:
void run(int i, int n) // warning: really poor code
{
thread t1 {f};
thread t2;
vector<Foo> v;
// ...
if (i<n) {
thread t3 {g};
// ...
t2 = move(t3); // move t3 to outer scope
}
v[i] = Foo{}; // might throw
// ...
t1.join();
t2.join();
}
在这里,我犯了几个严重的错误。特别是:
• 我们可能永远不会执行到末尾的两个 join() 操作。在这种情况下,t1 的析构函数会终止程序。
• 我们可能在执行到末尾的两个 join() 操作之前,t2 = move(t3) 尚未执行。在这种情况下,t2.join() 会终止程序。
对于这种thread使用方式,我们需要一个能够隐式调用 join() 的析构函数。例如:
struct guarded_thread : thread {
using thread::thread; // §20.3.5.1
˜guarded_thread() { if (t.joinable()) t.join(); }
};
遗憾的是,guarded_thread不是标准库类,但秉承 RAII 的优良传统,guarded_thread 使我们的代码更简洁、更不容易出错。例如:
void run2(int i, int n) // simple use of a guard
{
guarded_thread t1 {f};
guarded_thread t2;
vector<Foo> v;
// ...
if (i<n) {
thread t3 {g};
// ...
t2 = move(t3); // move t3 to outer scope
}
v[i] = Foo{}; // might throw
// ...
}
但为什么线程的析构函数不直接调用 join() 呢?长期以来,系统线程一直被设计成“永存”或自行决定何时终止。如果这种方法可行,执行 tick() 函数的定时器(§42.2.2)就是一个典型的例子。监控数据结构的线程提供了更多此类示例。这类线程(和进程)通常被称为守护进程。分离线程的另一个用途是,只需启动一个线程来完成一项任务,然后就无需再管它。这样做可以将“清理工作”留给运行时系统。
42.2.5 detach()
意外地让thread尝试执行到析构函数之后会视为非常严重的错误。如果你确实希望系统线程的生命周期超过其线程(句柄)的生命周期,请使用 detach() 方法。例如:
void run2()
{
thread t {heartbeat};
t.detach(); //let heartbeat run independently
}
我对分离的线程存在哲学上的抵触情绪。如果可以选择,我更倾向于
• 准确了解哪些线程正在运行,
• 能够判断线程是否按预期运行,
• 能够检查应该自行销毁的线程是否真的销毁了,
• 能够判断使用线程结果是否安全,
• 确保与线程关联的所有资源都已正确释放,以及
• 确保线程在创建它的作用域销毁后,不会尝试访问该作用域中的对象。
除非我使用标准库之外的方法(例如,使用 get_native_handle() 和“原生”系统机制),否则我无法对分离线程进行调试。此外,如何调试一个无法直接观察分离线程行为的系统?如果一个分离线程持有指向其创建作用域内某个对象的指针会发生什么?这可能会导致数据损坏、系统崩溃或安全漏洞。当然,分离线程显然是有用的,也可以进行调试。毕竟,人们已经这样做了几十年。但是,人们也做了几个世纪的自毁行为,并认为这些行为是有用的。如果可以选择,我宁愿不执行 detach() 操作。
请注意,thread 类提供了移动赋值和移动构造函数。这使得thread可以迁移出其构造的作用域,并且通常可以替代 detach() 方法。我们可以将线程迁移到程序的“主模块”中,通过 unique_ptr 或 shared_ptr 访问它们,或者将它们放置在容器(例如 vector<thread>)中以避免丢失对它们的跟踪。例如:
vector<thread> my_threads; // keep otherwise detached threads here
void run()
{
thread t {heartbeat};
my_threads.push_back(move(t));
// ...
my_threads.emplace_back(tick,1000);
}
void monitor()
{
for (thread& t : my_threads)
cout << "thread " << t.get_id() << '\n';
}
举个更实际的例子,我会给 my_thread 中的每一个thread关联一些信息。我甚至可能会把monitor作为任务启动。
如果必须使用 detach() 方法分离线程,请确保它不引用线程作用域内的变量。例如:
void home() // don’t do this
{
int var;
thread disaster{[&]{ this_thread::sleep_for(second{7.3});++var; }}
disaster.detach();
}
除了警告注释和引人遐想的名称之外,这段代码看起来似乎没什么问题。但事实并非如此:disaster() 函数调用的系统线程会“永远”不断地写入 home() 函数分配变量的地址,从而破坏之后可能分配到该地址的任何数据。这类错误极难发现,因为它与它所体现的代码关联性很弱,而且程序的重复运行会产生不同的结果——很多次运行甚至可能没有任何症状。这类错误称为“Heisenberg错误”(Heisenbugs),以纪念发现不确定性原理的Heisenberg。
请注意,该示例的根本问题在于违反了简单且众所周知的规则“不要将指向局部对象的指针传递到其作用域之外”(§12.1.4)。然而,使用 lambda 表达式,创建指向局部变量的指针非常容易(而且几乎不可见):[&]。幸运的是,我们需要使用 detach() 来允许thread退出其作用域;除非有非常充分的理由,否则不要这样做,而且只有在仔细考虑其任务可能执行的操作之后才能这样做。
42.2.6 命名空间this_thread
当前线程的操作位于命名空间 this_thread 中:
| 命名空间this_thread (§iso.30.3.1) | |
| x=get_id() | x 是当前thread的id;noexcept |
| yield() | 允许调度器运行另一个thread;noexcept |
| sleep_until(tp) | 将当前thread置于睡眠状态,直到time_point tp |
| sleep_for(d) | 将当前thread休眠 duration d |
为了得到当前thread的标识,调用方法 this_thread::get_id() 。例如:
void helper(thread& t)
{
thread::id me {this_thread::get_id()};
// ...
if (t.get_id()!=me) t.join();
// ...
}
类似地,我们可以使用 this_thread::sleep_until(tp) 和 this_thread::sleep_for(d) 使当前线程进入睡眠状态。
this_thread::yield() 用于让另一个thread有机会继续执行。当前线程不会阻塞,因此它最终会再次运行,而无需任何其他thread执行任何特定操作来唤醒它。因此,yield() 主要用于等待atomic改变状态以及协作式多线程。通常,使用 sleep_for(n) 比直接使用 yield() 更好。sleep_for() 的参数使调度器能够更好地合理地选择何时运行哪些thread。可以将 yield() 视为一种在非常罕见和特殊情况下用于优化的特性。
在所有主流实现中,thread都是可抢占的;也就是说,实现可以从一个任务切换到另一个任务,以确保所有thread以合理的速度推进。然而,由于历史原因和语言技术原因,标准(§iso.1.10)仅鼓励而非强制使用抢占。
在通常情况下,程序员不应该直接修改系统时钟。但是,如果时钟被重置(例如,由于时钟偏离了实际时间),wait_until() 函数会受到影响,而 wait_for() 函数则不会。对于timed_mutex(定时互斥锁)(参见 §42.3.1.3),wait_until() 和 wait_for() 函数也同样适用。
42.2.7 (优雅地)结束一个thread(Killing a thread)
我发现thread机制缺少一个重要的操作。目前还没有一种简单标准的方法来告知正在运行的thread,我已经对它的任务失去兴趣,请它停止运行并释放所有资源。例如,如果我启动一个并行的 find() 函数(参见 §42.4.7),我通常希望在得到结果后让其他任务停止运行。缺少这种操作(在不同的语言和系统中分别称为 kill,cancel 和 interrupt)的原因有很多,既有历史原因,也有技术原因。
如有需要,应用程序员可以编写自己的版本来实现这一想法。例如,许多任务都涉及请求循环。在这种情况下,“请自行终止”消息可以让接收thread释放所有资源并终止。如果没有请求循环,任务可以定期检查“needed”变量,以确定是否仍然需要结果。
因此,通用的取消操作可能难以设计和在所有系统上实现,但我从未见过哪个应用程序的特定取消机制难以实现。
42.2.8 thread_local数据(thread_local Data)
顾名思义,一个thread_local 变量是thread拥有的对象,除非其所有者(不小心)将其指针传递给其他thread,否则其他thread无法访问它。从这个意义上讲,thread_local类似于局部变量,但局部变量的生命周期和访问权限受限于其在函数内部的作用域,而thread_local则在线程的所有函数之间共享,并且与thread的生命周期相同。thread_local对象可以是extern的。
对于大多数用途而言,将对象放在本地(栈上)比放在共享内存中更可取;thread_local与全局变量一样,存在一些逻辑问题。通常,可以使用命名空间来限制非局部数据带来的问题。然而,在许多系统中,thread的栈存储空间相当有限,因此对于需要大量非共享数据的任务来说,thread_local就显得尤为重要。
thread_local具有线程存储期(thread storage duration)(§iso.3.7.2)。每一个thread都有其自身的thread_local变量的副本。thread_local在首次使用前会初始化(§iso.3.2)。如果已创建,则会在thread退出时销毁。
thread_local的一个重要用途是允许线程显式地维护一个数据缓存,以便独占访问。这可能会使程序逻辑变得复杂,但在使用共享缓存的机器上,它有时可以带来非常显著的性能提升。此外,它还可以通过仅以较大批次传输数据来简化和/或降低加锁的成本。
一般来说,非局部内存对于并发编程来说是个问题,因为确定它是否被共享通常并非易事,而共享内存又可能导致数据竞争。尤其static类成员可能造成严重问题,因为它们通常对类的用户是隐藏的,因此潜在的数据竞争很容易忽略。考虑一个具有每个类型默认值的 Map 设计:
template<typename K, typename V>
class Map {
public:
Map();
// ...
static void set_default(const K&,V&); // set default for all Maps of type Map<K,V>
private:
static pair<const K,V> default_value;
};
用户为什么会怀疑两个不同的 Map 对象之间存在数据竞争呢?显然,如果用户在成员中发现了 set_default(),就可能会有所怀疑,但 set_default() 是一个很容易忽略的次要功能(§16.2.12)。
每一个类只有一个(static)值曾经很流行。它们包括默认值、使用计数器、缓存、空闲列表、常见问题解答以及许多其他不太常用的用途。当在并发系统中使用时,我们会遇到一个经典问题:
// somewhere in thread 1:
Map<string,int>::set_default("Heraclides",1);
// somewhere in thread 2:
Map<string,int>::set_default("Zeno",1);
这是一个潜在的数据竞争:哪一个线程可以首先执行 set_default()?
添加 thread_local 参数会有帮助:
template<typename K, typename V>
class Map {
// ...
private:
static thread_local pair<const K,V> default_value;
};
现在,潜在的数据竞争问题已经不存在了。然而,所有用户之间也不再共享同一个默认值。在示例中,线程 1 永远不会看到线程 2 中 set_default() 的效果。通常情况下,这并非原始代码的预期,因此添加 thread_local 只是用一个错误替换了另一个错误。始终要对static数据成员保持警惕(因为你无法预知你的代码将来是否会在并发系统中执行),并且不要将 thread_local 视为万能药。
命名空间变量、局部static变量和类static成员都可以声明为 thread_local。与局部static变量一样,thread_local 局部变量的构造也受到首次声明开关的保护(§42.3.3)。thread_local 的构造顺序未定义,因此应保持不同 thread_local 的构造顺序独立,并尽可能使用编译时或链接时初始化。与static变量一样,thread_local 默认初始化为零(§6.3.5.1)。
42.3 避免数据竞争(Avoiding Data Races)
避免数据竞争的最佳方法是不共享数据。将重要数据保存在局部变量、不与其他线程共享的自由存储区或thread_local内存(参见 §42.2.8)。不要将指向此类数据的指针传递给其他thread。当需要其他thread处理此类数据时(例如,通过并行排序),传递指向数据特定部分的指针,并确保在任务终止之前不要修改传递的这部分数据。
这些简单的规则基于避免同时访问数据的理念,因此不需要加锁,并能使程序达到最高效率。如果无法使用这些规则,例如需要共享大量数据时,则应使用某种形式的加锁:
• 互斥锁:互斥锁(互斥变量)是一个用于表示对某个资源独占访问权的对象。要访问该资源,需要获取互斥锁,进行访问,然后释放互斥锁(§5.3.4,§42.3.1)。
• 条件变量:条件变量是thread用来等待另一个thread或计时器生成的事件的变量(§5.3.4.1,§42.3.4)。
严格来说,条件变量并不能防止数据竞争。它们的作用是避免引入可能导致数据竞争的共享数据。
42.3.1 互斥锁(Mutexes)
mutex是一种用于表示对某个资源独占访问的对象。因此,它可以用来防止数据竞争,并同步多个thread之间共享数据的访问。
| 互斥锁类(§iso.30.4) | |
| mutex | 非递归互斥锁;如果thread试图获取一个已被获取的互斥锁,则阻塞。 |
| recursive_mutex | 单个thread可以重复获取的互斥锁 |
| timed_mutex | 一个非递归互斥锁,其操作旨在尝试在指定时间内获取互斥锁。 |
| recursive_timed_mutex | 递归定时互斥锁 |
| lock_guard<M> | mutex M 的保护 |
| unique_lock<M> | mutex M 的锁 |
“普通”mutex是最简单、最小、最快的互斥锁。递归互斥锁和定时互斥锁虽然功能更强大,但会带来一些额外的开销,这些开销对于特定机器上的特定应用程序而言可能微不足道。
同一时间只能有一个thread拥有互斥锁:
• 获取互斥锁意味着独占该互斥锁;获取操作可能会阻塞执行该操作的thread。
• 释放互斥锁意味着放弃独占所有权;释放操作将允许另一个thread最终获取该互斥锁。也就是说,释放操作将解除等待thread的阻塞。
如果多个thread阻塞在互斥锁上,系统调度器原则上可以选择释放阻塞的thread,从而导致某些thread永远无法运行。这称为“饥饿”。避免饥饿的调度算法,即给予每个thread平等的机会,称为公平的。例如,调度器可能总是选择thread::id 最高的thread来运行下一个thread,从而使thread::id较低的线程“饥饿”。标准并不保证公平性,但实际上调度器是“相当公平的”。也就是说,它们使得thread永远“饥饿”的可能性极低。例如,调度器可能会在阻塞的线程中随机选择下一个运行的thread。
互斥锁本身并不会执行任何操作。相反,我们使用互斥锁来表示其他东西。我们使用互斥锁的所有权来表示操作某个资源(例如对象、数据或 I/O 设备)的权限。例如,我们可以定义一个 cout_mutex 来表示从某个thread使用 cout 的权限:
mutex cout_mutex; // represent the right to use cout
template<typename Arg1, typename Arg2, typename Arg3>
void write(Arg1 a1, Arg2 a2 = {}, Arg3 a3 = {})
{
thread::id name = this_thread::get_id();
cout_mutex.lock();
cout << "From thread " << name << " : " << a1 << a2 << a3;
cout_mutex.unlock();
}
如果所有线程都使用 write() 函数,我们应该能够正确区分来自不同thread的输出。问题在于,每一个thread都必须按照预期使用互斥锁。互斥锁与其资源之间的对应关系是隐式的。在 cout_mutex 的示例中,直接使用 cout 的线程(绕过 cout_mutex)可能会破坏输出。标准保证 cout 变量不会被破坏,但无法防止来自不同线程的输出混杂在一起。
请注意,我只对需要锁的那条语句加了互斥锁。为了最大限度地减少争用和thread阻塞的可能性,我们尽量缩短锁的持有时间,只在必要时才加锁。受锁保护的代码段称为临界区(互斥段)(critical section)(译注:译为“临界区”似乎不能达其意,它本质上就是一块共享代码段,与“界”没有关系,而是整块代码都是需要互斥访问的,不如称其为“互斥段”)。为了保持代码运行速度并避免与锁相关的问题,我们尽量减小临界区的大小。
标准库中的互斥锁提供独占所有权语义。即,一次只能有一个thread独占访问资源。还有其他类型的互斥锁。例如,多读单写互斥锁很常用,但标准库目前尚未提供。如果你需要其他类型的互斥锁,请使用特定系统提供的互斥锁或自行编写。
42.3.1.1 mutex和recursive_mutex
mutex类提供了一组简单的操作:
| mutex (§iso.30.4.1.2.1) | |
| mutex m {}; | 默认构造函数:m 不属于任何线程;constexpr;noexcept |
| m.˜mutex() | 析构函数:如果所有者是析构函数,则行为未定义。 |
| m.lock() | 获得 m;阻止直至获得所有权 |
| m.try_lock() | 尝试获取 m;获取成功了吗? |
| m.unlock() | 释放m |
| native_handle_type | 一种实现定义的系统互斥锁类型 |
| nh=m.native_handle() | nh 是互斥锁 m 的系统句柄。 |
互斥锁不能被复制或移动。可以将互斥锁视为一种资源,而不是资源的句柄。实际上,互斥锁通常是作为系统资源的句柄实现的,但由于该系统资源不能共享、泄露、复制或移动,因此将它们视为独立存在通常是一种不必要的复杂情况。
mutex的基本用法非常简单。例如:
mutex cout_mutex; // initialized to ‘‘not owned by any thread’’
void hello()
{
cout_mutex.lock();
cout << "Hello, ";
cout_mutex.unlock();
}
void world()
{
cout_mutex.lock();
cout << "World!";
cout_mutex.unlock();
}
int main()
{
thread t1 {hello};
thread t2 {world};
t1.join();
t2.join();
}
鉴于此,我们将得到输出
Hello, World!
或
World! Hello,
我们不会遇到 cout 输出损坏或出现混乱输出字符的情况。
当其他thread正在使用某个资源时,我们需要执行一些其他可能有用的工作,这时可以使用 try_lock() 操作。例如,考虑一个工作生成器,它会生成其他任务的工作请求,并将它们放入工作队列中:
extern mutex wqm;
extern list<Work> wq;
void composer()
{
list<Work> requests;
while (true) {
for (int i=0; i!=10; ++i) {
Work w;
// ... compose wor k request ...
requests.push_back(w);
}
if (wqm.try_lock()) {
wq.splice(requests); // splice() requests into the list (§31.4.2)
wqm.unlock();
}
}
}
当某个服务器thread正在检查 wq 时,composer() 会执行更多工作而不是等待。
使用锁时,我们必须注意死锁。也就是说,我们不能等待一个永远无法释放的锁。最简单的死锁形式只需要一个锁和一个thread 。考虑以下线程安全输出操作的一个变体:
template<typename Arg, typename... Args>
void write(Arg a, Args tail...)
{
cout_mutex.lock();
cout << a;
write(tail...);
cout_mutex.unlock();
}
现在,如果一个thread调用 write("Hello,","World!"),当它尝试对tail进行递归调用时,就会与自身发生死锁。
递归调用和相互递归调用非常常见,因此标准提供了相应的解决方案。recursive_mutex与普通mutex类似,区别在于单个thread可以重复获取它。例如:
recursive_mutex cout_mutex; // changed to recursive_mutex to avoid deadlock
template<typename Arg, typename... Args>
void write(Arg a, Args tail...)
{
cout_mutex.lock();
cout << a;
write(tail...);
cout_mutex.unlock();
}
现在 cout_mutex 可以正确处理 write() 的递归调用。
42.3.1.2 mutex错误处理
尝试操作互斥锁可能会失败。如果失败,互斥锁操作会抛出系统错误。一些可能的错误反映了底层系统的问题:
| 互斥锁错误条件 (§iso.30.4.1.2) | |
| resource_deadlock_would_occur | 会发生死锁。 |
| resource_unavailable_tr y_again | 某些本地句柄不可用 |
| operation_not_permitted | 该thread无权执行此操作 |
| device_or_resource_busy | 某些本地句柄已锁定 |
| invalid_argument | 构造函数原生句柄参数是不好的。 |
例如:
mutex mtx;
try {
mtx.lock();
mtx.lock(); // try to lock a second time
}
catch (system_error& e) {
mtx.unlock();
cout << e.what() << '\n';
cout << e.code() << '\n';
}
我得到输出结果:
device or resource busy
generic: 16
这似乎是使用 lock_guard 或 unique_lock 的一个很好的理由(§42.3.1.4)。
42.3.1.3 timed_mutex 和 recursive_timed_mutex
简单的 mtx.lock() 是无条件的。如果我们不想阻塞,可以使用 mtx.try_lock(),但当获取 mtx 失败时,我们通常希望等待一段时间后再重试。timed_mutex 和 recursive_timed_mutex 提供了对此的支持:
| timed_mutex (§iso.30.4.1.3.1) | |
| timed_mutex m {}; | 默认构造函数;m 不属于任何所有者;constexpr;noexcept |
| m.˜timed_mutex() | 析构函数:如果所有者是析构函数,则行为未定义。 |
| m.lock() | 获得 m ;阻塞直至获得所有权 |
| m.try_lock() | 尝试得 m ;获取成功了吗? |
| m.try_lock_for(d) | 尝试获取 m 并使其持续时间最长为 d;获取是否成功? |
| m.try_lock_until(tp) | 尝试在最迟时间点 tp 获取 m ;获取是否成功? |
| m.unlock() | 释放 m |
| native_handle_type | 实现定义的系统互斥锁类型 |
| nh=m.native_handle() | nh 是互斥锁的系统句柄 |
recursive_timed_mutex 接口与 timed_mutex 接口完全相同(就像 recursive_mutex 接口与 mutex 接口完全相同一样)。
对于 this_thread,我们可以执行 sleep_until(tp) 来等待一个时间点,也可以执行 sleep_for(d) 来等待一个持续时间(§42.2.6)。更一般地,对于 timed_mutex m,我们可以执行 m.try_lock_until(tp) 或 m.try_lock_for(d)。如果 tp 早于当前时间点,或者 d 小于等于零,则该操作等价于执行“普通”的 try_lock() 操作。
例如,考虑使用新图像更新输出缓冲区(例如,在视频游戏或可视化中):
extern timed_mutex imtx;
extern Image buf;
void next()
{
while (true) {
Image next_image;
// ... compute ...
if (imtx.try_lock(milliseconds{100})) {
buf = next_image;
imtx.unlock();
}
}
}
这里的假设是,如果图像无法以合理的速度更新(此处为 100 毫秒),用户会倾向于获取更新版本的图像。此外,假设在一系列更新的图像中缺少一张图片几乎不会被注意到,因此无需更复杂的解决方案。
42.3.1.4 lock_guard 和 unique_lock
锁是一种资源,因此我们不能忘记释放它。也就是说,每一个 m.lock() 操作都必须由一个 m.unlock() 操作来对应。这里存在一些常见的出错机会;例如:
void use(mutex& mtx, Vector<string>& vs, int i)
{
mtx.lock();
if (i<0) return;
string s = vs[i];
// ...
mtx.unlock();
}
mtx.unlock() 虽然存在,但如果 i<0 或 i 超出了 vs 的范围并且 vs 进行了范围检查,则执行线程永远不会到达 mtx.unlock(),mtx 可能会永远被锁定。
标准库提供了两个 RAII 类 lock_guard 和 unique_lock 来处理此类问题。
“普通”的 lock_guard 是最简单、最小、最快的安全机制。为了增加功能,unique_ptr 会带来一些开销,但对于特定机器上的特定应用程序而言,这些开销可能微不足道。
| lock_guard<M> (§iso.30.4.2) m是一个可锁对象 | |
| lock_guard lck {m}; | lck 获取 m ;explicit。 |
| lock_guard lck {m,adopt_lock_t}; | lck 持有 m;假设当前线程已获取 m;noexcept |
| lck.˜lock_guard() | 析构函数:调用 unlock() 函数解锁所持有的互斥锁。 |
例如:
void use(mutex& mtx, vector<string>& vs, int i)
{
lock_guard<mutex> g {mtx};
if (i<0) return;
string s = vs[i];
// ...
}
lock_guard 的析构函数对其参数执行必要的 unlock() 操作。
和往常一样,我们应该只持有锁最短的时间,因此,如果我们只需要在作用域的一小部分内使用锁,就不应该以 lock_guard 为借口,一直持有锁直到作用域结束。显然,检查 i 不需要加锁,所以我们可以在获取锁之前进行检查:
void use(mutex& mtx, vector<string>& vs, int i)
{
if (i<0) return;
lock_guard<mutex> g {mtx};
string s = vs[i];
// ...
}
此外,假设我们只需要对 v[i] 进行读取时才需要锁。那么,我们可以将 lock_guard 放在一个很小的作用域内:
void use(mutex& mtx, vector<string>& vs, int i)
{
if (i<0) return;
string s;
{
lock_guard<mutex> g {mtx};
s = vs[i];
}
// ...
}
代码如此复杂值得吗?不查看“隐藏在……”中的代码,我们无法判断,但我们绝对不应该仅仅因为不愿意考虑哪里需要加锁就使用 lock_guard。尽量减小临界区的大小通常是一件好事。即便没有其他好处,它也能迫使我们思考究竟哪里需要加锁以及为什么需要加锁。
因此,lock_guard(以及 unique_lock)是对象的资源句柄(“守卫”),你可以锁定它以获取所有权,并解锁它以释放所有权。
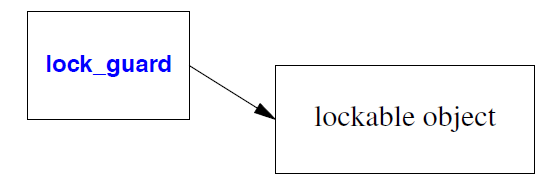
这样的对象称为可锁对象(a lockable object)。最典型的可锁对象是标准库中的互斥锁类型,但用户也可以定义自己的互斥锁类型。
lock_guard 是一个非常简单的类,没有任何特殊操作。它只负责对互斥锁进行 RAII 操作。要获得一个能够对包含的互斥锁进行 RAII 操作的对象,我们使用 unique_lock:
| unique_lock<M> (§iso.30.4.2) m是一个可锁对象 | |
| unique_lock lck {}; | 默认构造函数:lck 不持有互斥锁;noexcept |
| unique_lock lck {m}; | lck 获得 m;explicit |
| unique_lock lck {m,defer_lock_t}; | lck 持有 m 但并未获得它 |
| unique_lock lck {m,tr y_to_lock_t}; | lck 持有 m 并执行 m.try_lock();如果 try 成功,则 lck 拥有 m;否则不拥有 m。 |
| unique_lock lck {m,adopt_lock_t}; | lck 持有 m;假设当前thread已经获取了 m。 |
| unique_lock lck {m,tp}; | lck 持有 m 并调用 m.try_lock_until(tp);如果 try 成功,则 lck 拥有 m 的所有权;否则不拥有 m 的所有权。 |
| unique_lock lck {m,d}; | lck 持有 m 并调用 m.try_lock_for(d);如果 try 成功,则 lck 拥有 m 的所有权;否则不拥有 m 的所有权。 |
| unique_lock lck {lck2}; | 移动构造函数:lck 持有 lck2 持有的互斥锁(如果有);lck2 不持有互斥锁。 |
| lck.˜unique_lock() | 析构函数:调用 unlock() 函数解锁持有的互斥锁(如果有)。 |
| lck2=move(lck) | 移动分配:lck 持有 lck2 持有的互斥锁(如果有);lck2 不持有互斥锁。 |
| lck.lock() | m.lock() |
| lck.tr y_lock() | m.try_lock(); 获取是否成功? |
| lck.tr y_lock_for(d) | m.try_lock_for(d); 获取是否成功? |
| lck.tr y_lock_until(tp) | m.try_lock_until(tp); 获取是否成功? |
| lck.unlock() | m.unlock() |
| lck.swap(lck2) | 交换 lck 和 lck2 的可锁定对象;noexcept |
| pm=lck.release() | lck不再拥有∗pm;noexcept |
| lck.owns_lock() | lck 是否拥有可锁对象?noexcept |
| bool b {lck}; | 转换为bool值;b==lck.owns_lock();explicit;noexcept |
| pm=lck.mutex() | *pm 是拥有的可锁对象(如果有);否则 pm=nullptr;noexcept |
| swap(lck,lck2) | lck.swap(lck2); noexcept |
显然,只有当包含的互斥锁是 timed_mutex 或 recursive_timed_mutex 时,才允许进行定时操作。
例如:
mutex mtx;
timed_mutex mtx2;
void use()
{
unique_lock<defer_lock_t,mutex> lck {mtx};
unique_lock<defer_lock_t,timed_mutex> lck2 {mtx2};
lck.tr y_lock_for(milliseconds{2}); // error : mutex does not have member try_lock_for()
lck2.tr y_lock_for(milliseconds{2}); // OK
lck2.tr y_lock_until(steady_clock::now()+milliseconds{2});
// ...
}
如果将持续时间或时间点作为第二个参数传递给 unique_lock,构造函数将执行相应的尝试操作。owns_lock() 操作允许我们检查此类获取是否成功。例如:
timed_mutex mtx2;
void use2()
{
unique_lock<timed_mutex> lck2 {mtx2,milliseconds{2}};
if (lck2.owns_lock()) {
// acquisition succeeded:
// ... do something ...
}
else {
// timeout:
// ... do something else ...
}
}
42.3.2 多锁操作(Multiple Locks)
为了完成某项任务,我们常常需要获取多个资源。然而,获取两个锁意味着存在死锁的风险。例如:
mutex mtx1; // protects one resource
mutex mtx2; // protects another resource
void task(mutex& m1, mutex& m2)
{
unique_lock<mutex> lck1 {m1};
unique_lock<mutex> lck2 {m2};
// ... use resources ...
}
thread t1 {task,ref(mtx1),ref(mtx2)};
thread t2 {task,ref(mtx2),ref(mtx1)};
ref() 是来自<functional> (§33.5)的 std::ref() 引用包装器。它用于在可变参数模板( thread构造函数;§42.2.2)中传递引用。互斥锁不能复制或移动,因此我必须通过引用传递它们(或使用指针)。
将 mtx1 和 mtx2 的名称更改为不表示顺序的名称,并在源代码中将 t1 和 t2 的定义彼此分开,这样就不会再明显看出程序最终很有可能会发生死锁,t1 拥有 mtx1,t2 拥有 mtx2,并且它们各自试图永远获取第二个互斥锁。
| 锁(§iso.30.4.2) | |
| x=try_lock(locks) | 尝试获取所有锁;锁按顺序获取;如果所有锁都已获取,则 x = -1;否则 x = n,其中 n 是未能获取的锁的编号,并且此时没有持有任何锁。 |
| lock(locks) | 获取所有lock;避免死锁。 |
try_lock() 的具体算法没有明确规定,但一种可能的实现方式是:
template <typename M1, typename... Mx>
int try_lock(M1& mtx, Mx& tail...)
{
if (mtx.try_lock()) {
int n = try_lock(tail...);
if (n == −1) return −1; // all locks acquired
mtx.unlock(); //back out
return n+1;
}
return 1; // couldn’t acquire mtx
}
template <typename M1>
int try_lock(M1& mtx)
{
return (mtx.try_lock()) ? −1 : 0;
}
有了 lock() 函数,有问题的 task() 函数可以简化并纠正如下:
void task(mutex& m1, mutex& m2)
{
unique_lock lck1 {m1,defer_lock_t};
unique_lock lck2 {m1,defer_lock_t};
lock(lck1,lck2);
// ... use resources ...
}
请注意,如果直接对互斥锁调用 lock() 函数,例如 lock(m1, m2),而不是对 unique_lock 对象调用该函数,那么程序员就必须显式地释放 m1 和 m2 。
42.3.3 call_once()
我们经常需要在不引发竞态条件的情况下初始化对象。类型 once_flag 和函数 call_once() 为此提供了一种底层、高效且简单的工具。
| call_once (§iso.30.4.2) | |
| once_flag fl {}; | 默认构造函数:变量 fl 尚未被使用。 |
| call_once(fl,f,args) | 函数fl的call(args)方法尚未被使用。 |
例如:
class X {
public:
X();
// ...
private:
// ...
static once_flag static_flag;
static Y static_data_for_class_X;
static void init();
};
X::X()
{
call_once(static_flag,init());
}
可以将 call_once() 函数理解为一种简单的方法,用于修改依赖于已初始化static数据的非并发代码。
局部static变量的运行时初始化是通过 call_once() 函数或与 call_once() 非常类似的机制实现的。例如:
Color& default_color() // user code
{
static Color def { read_from_environment("background color") };
return def;
}
这可以按以下方式实现:
Color& default_color() // generated code
{
static Color def;
static_flag __def;
call_once(__def,read_from_environment,"background color");
return def;
}
我使用双下划线前缀(§6.3.3)来强调后一个版本代表的是编译器生成的代码。
42.3.4 条件变量(Condition Variables)
条件变量用于管理thread之间的通信。thread可以等待(阻塞)在condition_variable上,直到某个事件发生,例如到达特定时间或另一个thread完成其任务。
| condition_variable (§iso.30.5) | |
| condition_variable cv {}; | 默认构造函数:如果无法获取某些系统资源,则抛出 system_error 异常。 |
| cv.˜condition_variable() | 析构函数:不允许任何thread处于等待状态且未收到通知。 |
| cv.notify_one() | 解除一个等待线程的阻塞(如果存在);noexcept。 |
| cv.notify_all() | lck 必须由调用thread持有; 原子性地调用 lck.unlock() 并阻塞; 如果收到通知或“意外地”解除阻塞,则恢复运行; 解除阻塞后调用 lck.lock()。 |
| cv.wait(lck) | lck 必须由调用thread持有; while (!pred()) wait(lock); |
| cv.wait(lck,pred) | lck 必须由调用thread持有; while (!pred()) wait(lock); |
| x=cv.wait_until(lck,tp) | lck必须由调用thread持有; 原子地调用 lck.unlock() 并阻塞; 如果收到通知或在 tp 时间点超时,则解除阻塞; 解除阻塞后调用 lck.lock(); 如果超时,则 x 为 timeout;否则 x=no_timeout。 |
| b=cv.wait_until(lck,tp,pred) | while (!pred()) if (wait_until(lck,tp)==cv_status::timeout); b=pred() |
| x=cv.wait_for(lck,d) | x=cv.wait_until(lck,steady_clock::now()+d) |
| b=cv.wait_for(lck,d,pred) | b=cv.wait_until(lck,steady_clock::now()+d,move(pred)) |
| native_handle_type | 见 §iso.30.2.3 |
| nh=cv.native_handle() | nh 是 cv 的系统句柄 |
一个condition_variable可能(也可能不)依赖于系统资源,因此构造函数可能会因为缺少此类资源而失败。然而,与mutex一样,条件变量不能复制或移动,因此最好将condition_variable本身视为一种资源,而不是将其视为资源的句柄。
当condition_variable销毁时,所有正在等待的thread(如果存在)都必须被通知(即被唤醒),否则它们可能会永远等待下去。
wait_until() 和 wait_for() 函数返回的状态定义如下:
enum class cv_status { no_timeout, timeout };
condition_variable的 unique_lock 被等待函数用来防止由于对 unique_lock 的等待线程列表的竞争而导致唤醒信号丢失。
“普通”的 wait(lck) 操作是一种底层操作,使用时需要格外小心,通常仅用于实现某些更高级别的抽象。它可能会“虚假唤醒”,也就是说,即使没有其他thread发出通知,系统也可能决定恢复 wait() 调用的thread!显然,允许虚假唤醒可以简化某些系统上condition_variable的实现。始终在循环中使用“普通”的 wait() 函数。例如:
while (queue.empty()) wait(queue_lck);
造成这种循环的另一个原因是,某些thread可能“悄悄地”修改了条件(例如,queue.empty()),而调用无条件 wait() 方法的thread还没来得及运行。这样的循环实际上就是带有条件的等待的实现,因此最好使用带有条件的等待,而不是无条件的 wait() 函数。
thread可以等待一段时间:
void simple_timer(int delay)
{
condition_variable timer;
mutexmtx; //mutex protecting timer
auto t0 = steady_clock::now();
unique_lock<mutex> lck(mtx); // acquire mtx
timer.wait_for(lck,milliseconds{delay}); // release and reacquire mtx
auto t1 = steady_clock::now();
cout << duration_cast<milliseconds>(t1−t0).count() << "milliseconds passed\n";
} // implicitly release mtx
这基本上展示了 this_thread::wait_for() 函数的实现。mutex保护 wait_for() 函数免受数据竞争的影响。wait_for() 函数在进入睡眠状态时会释放其mutex,并在thread被唤醒时重新获取该锁。最后,lck(隐式地)在其作用域结束时释放mutex 。
condition_variable的另一个简单用途是控制生产者向消费者发送消息的流程:
template<typename T>
class Sync_queue {
public:
void put(const T& val);
void put(T&& val);
void get(T& val);
private:
mutex mtx;
condition_variable cond;
list<T> q;
};
其理念是 put() 和 get() 操作不会相互干扰。执行 get() 操作的线程会休眠,除非队列中有可供其获取的值。
template<typename T>
void Sync_queue::put(const T& val)
{
lock_guard<mutex> lck(mtx);
q.push_back(val);
cond.notify_one();
}
也就是说,生产者调用 put() 方法时会获取队列的mutex,将一个值添加到队列末尾,调用 notify_one() 唤醒可能处于阻塞状态的消费者,然后隐式释放mutex 。我提供了 put() 方法的右值引用版本,以便我们可以传输那些支持移动操作但不支持复制操作的对象,例如 unique_ptr(§5.2.1,§34.3.1)和 packaged_task(§42.4.3)。
我使用了 notify_one() 而不是 notify_all(),因为我只添加了一个元素,并且想让 put() 函数保持简洁。但考虑到可能存在多个消费者以及消费者可能落后于生产者的情况,我或许需要重新考虑这种做法。
get() 方法稍微复杂一些,因为它只有在mutex阻止访问或队列为空的情况下才会阻塞其thread :
template<typename T>
void Sync_queue::get(T& val)
{
unique_lock<mutex> lck(mtx);
cond.wait(lck,[this]{ return !q.empty(); });
val=q.front();
q.pop_front();
}
调用 get() 方法的线程将会一直阻塞,直到 Sync_queue 不为空为止。
我使用了 unique_lock 而不是普通的 lock_guard,因为 lock_guard 的设计注重简洁性,不提供解锁和重新锁定mutex所需的操作。
我使用[这种方法]使 lambda 函数能够访问 Sync_queue 对象(§11.4.3.3)。
我通过引用参数而不是返回值来返回 get() 函数的值,以确保具有可能抛出异常的复制构造函数的元素类型不会导致问题。这是常用的技术(例如,STL 栈适配器提供了 pop() 函数,容器也提供了 front() 函数)。编写一个直接返回值的一般 get() 函数是可能的,但出乎意料地棘手。例如,请参见 future<T>::get() (§42.4.4)。
一个简单的生产者-消费者对可以非常简单:
Sync_queue<Message> mq;
void producer()
{
while (true) {
Message m;
// ... fill m ...
mq.put(m);
}
}
void consumer()
{
while (true) {
Message m;
mq.get(m);
// ... use m ...
}
}
thread t1 {producer};
thread t2 {consumer};
使用condition_variable可以省去消费者显式处理无事可做的情况的麻烦。如果我们仅仅使用mutex来控制对 Sync_queue 的访问,那么消费者就必须反复唤醒,检查队列中是否有任务,并在队列为空时决定如何处理。
我将值复制到用于存储队列元素的列表中,也会从列表中复制值。复制元素类型时可能会抛出异常,但如果发生这种情况,Sync_queue 将保持不变,put() 或 get() 操作只会失败。
Sync_queue 本身不是共享数据结构,因此我们不需要为其使用单独的mutex;只有 put() 和 get() 方法(用于更新队列的头部和尾部,这两个位置可能指向同一个元素)需要防止数据竞争。
对于某些应用程序来说,简单的Sync_queue存在一个致命缺陷:如果生产者停止添加值,消费者可能会永远等待下去,该怎么办?如果消费者还有其他事情要做,无法长时间等待,又该怎么办?通常情况下,这些问题都有解决方案,但一种常用的技术是为 get() 方法添加超时机制,即指定最长等待时间:
void consumer()
{
while (true) {
Message m;
mq.get(m,milliseconds{200});
// ... use m ...
}
}
为了使之正常工作,我们需要在 Sync_queue 中添加第二个 get() 方法:
template<typename T>
void Sync_queue::get(T& val, steady_clock::duration d)
{
unique_lock<mutex> lck(mtx);
bool not_empty = cond.wait_for(lck,d,[this]{ return !q.empty(); });
if (not_empty) {
val=q.front();
q.pop_front();
}
else
throw system_error{"Sync_queue: get() timeout"};
}
使用超时机制时,我们需要考虑等待结束后该如何处理:是成功获取到数据了,还是仅仅超时了?实际上,我们并不真正关心是否超时,而只关心谓词(以 lambda 表达式表示)是否为真,因此 wait_for() 函数返回的就是这个结果。我选择通过抛出异常来报告 get() 函数因超时而失败的情况。如果我认为超时是一种常见且“非异常”的事件,那么我就会返回一个bool值而不是抛出异常。
与 put() 方法大致等效的修改方法是等待消费者处理完一部分长队列,但等待时间不宜过长:
template<typename T>
void Sync_queue::put(T val, steady_clock::duration d, int n)
{
unique_lock<mutex> lck(mtx);
bool not_full = cond.wait_for(lck,d,[this]{ return q.size()<n; });
if (not_full) {
q.push_back(val);
cond.notify_one();
}
else {
cond.notify_all();
throw system_error{"Sync_queue: put() timeout"};
}
}
对于 put() 方法,返回bool值以鼓励生产者始终显式处理两种情况的方案似乎比 get() 方法更具吸引力。然而,为了避免陷入关于如何最好地处理溢出的讨论,我再次选择通过抛出异常来表示失败。
如果队列已满,我选择调用 notify_all()。或许,有些消费者需要唤醒才能继续运行。选择 notify_all() 还是 notify_one() 取决于应用程序的行为,而且并非总是显而易见的。只通知一个thread会使对队列的访问串行化,因此当存在多个潜在消费者时,可能会降低吞吐量。另一方面,通知所有等待的thread可能会唤醒多个thread,导致互斥锁争用,并可能导致thread反复唤醒却发现队列为空(已被其他线程清空)。我遵循一条老规则:不要相信直觉;要进行实际测量。
42.3.4.1 condition_variable_any
condition_variable 针对 unique_lock<mutex> 进行了优化。condition_variable_any 在功能上与 condition_variable 等效,但可以使用任何可加锁对象进行操作:
| condition_variable_any (§iso.30.5.2) lck 可以是任何具有所需操作的可锁对象。 |
| ……如condition_variable…… |
42.4 基于任务的并发(Task-Based Concurrency)
到目前为止,本章重点介绍了运行并发任务的机制:包括thread ,避免竞态条件以及thread同步。但我发现,对于许多并发任务而言,这种对机制的关注反而会分散人们对真正任务(即指定并发任务)的注意力。本节将重点介绍一种简单的任务类型:这种任务接受一些参数,执行一项操作,并产生一个结果。
为了支持这种基于任务的并发模型,标准库提供了以下功能:
| 任务支持 (§iso.30.6.1) | |
| packaged_task<F> | 将类型为 F 的可调用对象包装起来,作为任务运行。 |
| promise<T> | 一种用于放置类型为 T 的结果的对象类型 |
| future<T> | 一种可以从中移动类型为 T 的结果的对象类型 |
| shared_future<T> | 一个可以多次读取类型为 T 的结果的future对象。 |
| x=async(policy,f,args) | 根据策略执行函数 f(args)。 |
| x=async(f,args) | 使用默认策略启动: x=async(launch::async|launch::deferred,f,args) |
这些功能的介绍会涉及许多细节,而这些细节通常无需应用程序开发人员操心。请记住任务模型的基本简洁性。大多数更复杂的细节都是为了支持一些特殊用途,例如隐藏底层线程和锁机制的复杂性。
标准库提供的任务支持只是任务式并发支持的一个例子。通常,我们希望提供大量的小任务,然后让“系统”负责如何将这些任务映射到硬件资源上执行,并避免数据竞争、虚假唤醒、过度等待等问题。
这些功能的优势在于它们对程序员来说非常简单易用。在顺序执行的程序中,我们通常会这样编写代码:
res = task(args); // 执行一个已知参数的任务并返回伤
并发版本如下:
auto handle = async(task,args); // 执行一个已知参数的任务
// ... do something else ...
res = handle.get() // 获得结果
有时,当我们考虑各种替代方案、细节、性能和权衡取舍时,会忽略简单性的价值。默认情况下,请使用最简单的技术,并将更复杂的解决方案留到真正值得使用的时候再用。
42.4.1 future和promise
正如第 5.3.5 节所述,任务之间的通信是通过future/promise对来实现的。一个任务将其结果放入promise中,而需要该结果的任务则从相应的future对象中获取结果:
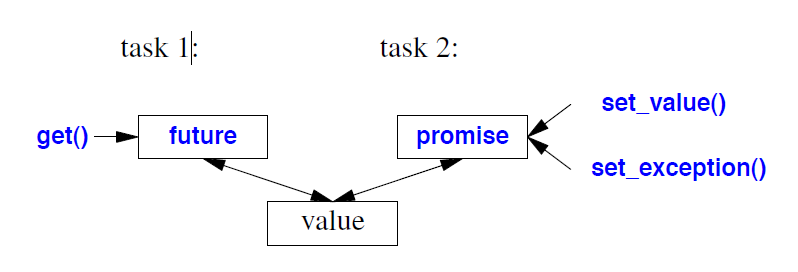
此图中的“值”在技术上称为共享状态(§iso.30.6.4)。除了返回值或异常之外,它还包含两个thread安全地交换信息所需的信息。至少,共享状态必须能够存储以下信息:
• 一个适当类型的值或一个异常。对于返回类型为 void 的 future,该值为空。
• 一个就绪位(ready bit),指示 future 是否已准备好提取值或异常。
• 当对使用发起策略(launch future)为 deferred 的 async() 函数启动的任务的 future 调用 get() 时要执行的任务(§42.4.6)。
• 一个使用计数,以便仅当最后一个潜在用户放弃访问时才销毁共享状态。特别是,如果存储的值属于具有析构函数的类,则当使用计数变为零时,会调用其析构函数。
• 一些互斥数据,用于解除任何可能正在等待的thread的阻塞(例如,condition_variable)。
实现可以对共享状态执行操作:
• 构建:可能使用用户提供的分配器。
• 准备就绪:设置“就绪位”并解除所有等待thread的阻塞。
• 释放:减少使用计数,如果这是最后一个用户,则销毁共享状态。
• 放弃:如果承诺无法将值或异常放入共享状态(例如,因为promise销毁),则会将带有错误条件 broken_promise 的 future_error 异常存储在共享状态中,并将共享状态设置为就绪状态。
42.4.2 promise
promise是共享状态的句柄(§42.4.1)。任务可以将结果存入promise中,然后通过future对象(§42.4.4)检索该结果。
| promise<T> (§iso.30.6.5) | |
| promise pr {}; | 默认构造函数:pr 具有一个尚未就绪的共享状态。 |
| promise pr {allocator_arg_t,a}; | 构造 pr;使用分配器 a 构造一个尚未就绪的共享状态。 |
| promise pr {pr2}; | 移动构造函数:pr 获取 pr2 的状态;pr2 不再拥有共享状态;noexcept。 |
| pr.˜promise() | 析构函数:放弃共享状态;将结果设置为 broken_promise 异常。 |
| pr2=move(pr) | 移动赋值:pr2 获取 pr 的状态; pr 不再拥有共享状态;noexcept。 |
| pr.swap(pr2) | 交换 pr 和 pr2 的值;noexcept |
| fu=pr.g et_future() | fu 是与 pr 对应的future。 |
| pr.set_value(x) | 任务的结果值为 x 。 |
| pr.set_value() | 为void future设置任务结果 |
| pr.set_exception(p) | 任务的结果是 p 指向的异常;p 是一个 exception_ptr。 |
| pr.set_value_at_thread_exit(x) | 任务的结果是值 x ;在thread退出之前,不要使结果可用。 |
| pr.set_exception_at_thread_exit(p) | 任务的结果是 p 指向的异常; p 是一个 exception_ptr; 在thread退出之前,不要使结果就绪。 |
| swap(pr,pr2) | pr.swap(pr2); noexcept |
promise对象没有复制操作。
如果值或异常已设置,则set函数会抛出 future_error 异常。
通过 promise 只能传递一个结果值。这看起来可能有些限制,但请记住,该值是在共享状态中移动而不是复制的,因此我们可以以较低的成本传递对象集合。例如:
promise<map<string,int>> pr;
map<string,int>> m;
// ... fill m with a million <string,int> pairs ...
pr.set_value(m);
然后,任务可以以几乎零成本从相应的future对象中提取该map。
42.4.3 packaged_task
packaged_task 包含一个任务和一个 future/promise 对。
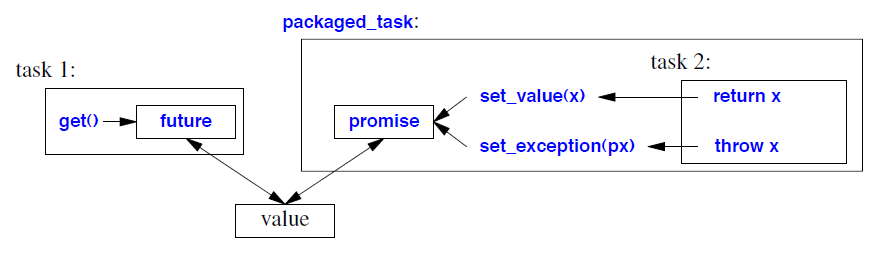
我们将要执行的任务(一个函数或函数对象)传递给 packaged_task。当任务执行 return x 时,它会在 packaged_task 的 promise 上调用 set_value(x)。类似地,如果任务抛出异常 x,则会调用 set_exception(px),其中 px 是 x 的 exception_ptr。在本质上,packaged_task 会像这样执行其任务 f(args):
try {
pr.set_value(f(args)); // 假设 promise 由 pr 调用
}
catch(...) {
pr.set_exception(current_exception());
}
一个packaged_task 提供了一系列相当常规的操作:
| packaged_task<R(ArgTypes...)> (§iso.30.6.9) | |
| packaged_task pt {}; | 默认构造函数:pt 不包含任何任务;noexcept。 |
| packaged_task pt {f}; | 构造对象 pt,持有 f;将 f 移动到 pt 中; 使用默认分配器;explicit |
| packaged_task pt {allocator_arg_t,a,f}; | 构造包含 f 的 pt;将 f 移入 pt;使用分配器 a;explicit |
| packaged_task pt {pt2}; | 移动构造函数:pt 获取 pt2 的状态; 移动后 pt2 不再拥有任务;noexcept。 |
| pt=move(pt2) | 移动赋值:pt 获取 pt2 的状态; 减少 pt 原先共享状态的引用计数; 移动后 pt2 不再拥有任务;noexcept。 |
| pt.˜packaged_task(); | 析构函数:放弃共享状态 |
| pt.swap(pt2) | 交换 pt 和 pt2 的值;noexcept。 |
| pt.valid() | pt 是否具有共享状态?如果它分配了任务且尚未移动,则它具有共享状态;noexcept |
| fu=pt.get_future() | fu 代表着 pt 的promise的future; 如果调用两次,则会抛出 future_error 异常。 |
| pt()(args) | 执行 f(args); f() 函数中的 return x 会调用 pt 的 promise 对象的 set_value(x) 方法, f() 函数中的 throw x 会调用 pt 的 promise 对象的 set_exception(px) 方法;其中 px 是指向 x 的 exception_ptr。 |
| pt.make_ready_at_exit(args) | 调用 f(args);但直到thread退出后才能获取结果。 |
| pt.reset() | 重置到初始状态;放弃旧状态。 |
| swap(pt,pt2) | pt.swap(pt2) |
| uses_allocator<PT,A> | 如果 PT 使用分配器类型 A,则为 true_type。 |
packaged_task 对象可以移动,但不能复制。packaged_task 对象可以复制其内部的任务,并且假定任务的副本会产生与原任务相同的结果。这一点很重要,因为任务及其对应的 packaged_task 对象可能会移动到新thread的堆上。
放弃共享状态(例如析构函数和移动操作所做的那样)意味着使其处于就绪状态。如果没有存储值或异常,则会存储指向 future_error 类型的指针(§42.4.1)。
make_ready_at_exit() 的优点在于,只有在thread_local变量的析构函数执行完毕后,才能获取到结果。
没有与 get_future() 相对应的 get_promise() 操作。promise 的使用完全由 packaged_task 处理。
举一个非常简单的例子,我们甚至不需要用到thread。首先,定义一个简单的任务:
int ff(int i)
{
if (i) return i;
throw runtime_error("ff(0)");
}
现在我们可以将这个函数打包到 packaged_task 中并调用它们:
packaged_task<int(int)> pt1 {ff}; // store ff in pt1
packaged_task<int(int)> pt2 {ff}; // store ff in pt2
pt1(1); //let pt1 call ff(1);
pt2(0); //let pt2 call ff(0);
到目前为止,似乎什么都没有发生。特别是,我们没有看到 ff(0) 触发的异常。事实上,pt1(1) 对附加到 pt1 的 promise 调用了 set_value(1),而 pt1(0) 对附加到 pt2 的 promise 调用了 set_exception(px);其中 px 是指向 runtime_error("ff(0)") 的 exception_ptr。
之后,我们可以尝试检索结果。get_future() 操作用于获取一个 future 对象,打包的thread会将任务结果存入该对象中。
auto v1 = pt1.get_future();
auto v2 = pt2.get_future();
try {
cout << v1.get() << '\n'; // will print
cout << v2.get() << '\n'; // will throw
}
catch (exception& e) {
cout << "exception: " << e.what() << '\n';
}
输出是:
1
exception: ff(0)
我们只需这样写就能达到完全相同的效果:
try {
cout << ff(1) << '\n'; // will print
cout << ff(0) << '\n'; // will throw
}
catch (exception& e) {
cout << "exception: " << e.what() << '\n';
}
关键在于,使用 packaged_task 的版本与使用普通函数调用的版本功能完全相同,即使任务(此处为 ff )的调用和 get() 函数的调用位于不同的thread中也是如此。我们可以专注于指定任务本身,而无需考虑thread和锁的问题。
我们可以移动 future 对象,packaged_task 对象,或者同时移动两者。最终,packaged_task 会被调用,其任务会将结果存入 future 对象中,而无需知道是哪个thread执行了该任务,也无需知道是哪个thread将接收结果。这种方法既简单又通用。
考虑一个处理一系列请求的thread。它可以是 GUI thread、拥有特定硬件访问权限的thread,或者任何通过队列对资源进行串行访问的服务器。我们可以将此类服务实现为消息队列(§42.3.4),或者传递要执行的任务:
using Res = /* result type for server */;
using Args = /* argument types for server */;
using PTT = Res(Args);
Sync_queue<packaged_task<PTT>> server;
Res f(Args); // function: do something
struct G {
Res operator()(Args); // function object: do something
// ...
};
auto h = [=](Args a) { /* do something */ }; // lambda
packaged_task<PTT> job1(f);
packaged_task<PTT> job2(G{});
packaged_task<PTT> job3(h);
auto f1 = job1.get_future();
auto f2 = job2.get_future();
auto f3 = job3.get_future();
server.put(move(job1));
server.put(move(job2));
server.put(move(job3));
auto r1 = f1.get();
auto r2 = f2.get();
auto r3 = f3.get();
服务器线程会从服务器队列中取出封装好的任务,并以合适的顺序执行它们。通常,这些任务会携带来自调用上下文的数据。
这些任务的编写方式与普通函数、函数对象和 lambda 表达式基本相同。服务器调用这些任务的方式也与调用普通(回调)函数类似。实际上,由于已对异常处理进行了封装,因此服务器使用 packaged_task 比使用普通函数更加便捷。
42.4.4 future
future对象是对共享状态的引用(§42.4.1)。任务可以通过future对象获取由promise对象存储的结果(§42.4.2)。
| future<T> (§iso.30.6.6) (续) | |
| future fu {}; | 默认构造函数:不共享状态;noexcept。 |
| future fu {fu2}; | 移动构造函数:fu 获取 fu2 的共享状态(如果存在); fu2 不再拥有共享状态;noexcept。 |
| fu.˜future() | 析构函数:释放共享状态(如果存在)。 |
| fu=move(fu2) | 移动赋值:fu 获取 fu2 的共享状态(如果存在); fu2 不再拥有共享状态;释放 fu 原有的共享状态(如果存在)。 |
| sf=fu.share() | 将 fu 的值移动到 shared_future sf 中;fu 不再拥有共享状态。 |
| x=fu.get() | fu 的值被赋给 x;如果 fu 中存储了异常,则抛出该异常; fu 不再具有共享状态;不要尝试调用两次 get() 方法。 |
| fu.get() | 对于未来的<void>类型:类似于 x=fu.get(),但不会移动任何值。 |
| fu.valid() | 函数 fu 是否有效?也就是说,fu 是否具有共享状态?noexcept |
| fu.wait() | 阻塞直到收到值。 |
| fs=fu.wait_for(d) | 阻塞直到达到值或经过duration d 时间段; fs 表明一个值是否ready,是否timeout或执行是否deferred。 |
| fs=fu.wait_until(tp) | 阻塞直到达到值或time_point tp 时间点; fs 表明一个值是否ready,是否timeout或执行是否deferred。 |
一个future具有独特的价值,并且无法进行复制操作。
如果存在返回值,则该值会从 future 对象中取出。因此,get() 方法只能调用一次。如果你可能需要多次读取结果(例如,由不同的任务读取),请使用 shared_future(§42.4.5)。
如果你尝试调用两次 get() 方法,其行为是未定义的。事实上,如果你对一个无效的 future 对象执行除第一次调用 get(),valid() 或析构函数之外的任何操作,其行为都是未定义的。标准“建议”在这种情况下,实现应该抛出带有错误代码 future_errc::no_state 的 future_error异常。
如果 future<T> 的值类型 T 是 void 或引用类型,则 get() 方法适用特殊规则:
• future<void>::get() 不返回任何值:它要么直接返回,要么抛出异常。
• future<T&>::get() 返回一个 T& 类型的值。引用本身不是对象,因此库必须传输其他内容,例如 T*,然后 get() 将其转换回 T& 类型。
可以通过调用 wait_for() 和 wait_until() 方法来查看 future 对象的当前状态:
| enum class future_status | |
| ready | future有值 |
| timeout | 操作超时 |
| deferred | future 任务的执行会延迟到调用 get() 方法之后 |
对future进行操作时可能出现的错误包括:
| future 错误: future_errc | |
| broken_promise | promise在提供值之前就被放弃了 |
| future_already_retrieved | 对 future 对象进行第二次 get() 操作 |
| promise_already_satisfied | 对 promise() 对象调用第二次 set_value() 或 set_exception() 方法。 |
| no_state | 某个操作尝试访问promise的共享状态,但该状态尚未创建(例如,调用 get_future() 或 set_value())。 |
某个操作尝试访问承诺的共享状态,但该状态尚未创建(例如,调用 get_future() 或 set_value())。
查看future<T> 表,我发现缺少两个有用的函数:
• wait_for_all(args):等待 args 中的所有 future 都获得值。
• wait_for_any(args):等待 args 中的任何一个 future 获得值。
我可以轻松实现一个类似 wait_for_all() 的函数。
template<typename T>
vector<T> wait_for_all(vector<future<T>>& vf)
{
vector<T> res;
for (auto& fu : vf)
res.push_back(fu.g et());
return res;
}
这个方法用起来很简单,但它有一个缺点:如果我等待十个future,我的thread就有可能被阻塞十次。在理想情况下,我的thread最多只会阻塞和唤醒一次。然而,对于许多应用场景来说,这种 wait_for_all() 的实现方式已经足够好了:如果其中一些任务运行时间较长,额外的等待时间就不会显得那么重要。在另一方面,如果所有任务都很短,那么它们很可能在第一次等待之后就已经完成了。
实现 wait_for_any() 函数比较棘手。首先,我们需要一种方法来检查某个 future 是否已就绪。令人惊讶的是,这可以通过使用 wait_for() 函数来实现。例如:
future_status s = fu.wait_for(seconds{0});
使用 wait_for(seconds{0}) 来获取 future 的状态并不直观,但 wait_for() 会告诉我们它恢复执行的原因,并且它会在暂停之前检查是否已就绪。通常情况下,wait_for(seconds{0}) 会立即返回,而不是尝试暂停零时间,但遗憾的是,这一点并不能得到保证。
有了 wait_for() 函数,我们可以这样编写代码:
template<typename T>
int wait_for_any(vector<future<T>>& vf, steady_clock::duration d)
// return index of ready future
// if no future is ready, wait for d before trying again
{
while(true) {
for (int i=0; i!=vf.siz e(); ++i) {
if (!vf[i].valid()) continue;
switch (vf[i].wait_for(seconds{0})) {
case future_status::ready:
return i;
case future_status::timeout:
break;
case future_status::deferred:
throw runtime_error("wait_for_all(): deferred future");
}
}
this_thread::sleep_for(d);
}
}
我决定在我自己的使用场景中,将一个deferred 任务(§42.4.6)视为错误。
请注意对 valid() 函数的检查。如果在无效的 future 对象上调用 wait_for() 函数(例如,已经调用过 get() 函数的 future 对象),将会导致难以查找的错误。最好的情况下,可能会抛出一个(或许令人意外的)异常。
与 wait_for_all() 的实现类似,这种实现也存在缺陷:理想情况下,wait_for_any() 的调用者不应该在唤醒后发现没有任何任务完成,而应该在有任务完成时立即解除阻塞。这种简单的实现只能近似地达到这个目标。在数据量较大的情况下,无用的唤醒不太可能发生,但这仍然意味着可能出现不必要的长时间等待。
wait_for_all() 和 wait_for_any() 函数是构建并发算法的有用基础模块。我在第 42.4.6 节中使用了它们。
42.4.5 shared_future
future 的结果值只能读取一次:因为它会移动。因此,如果你想重复读取该值,或者可能需要多个读取器读取该值,则必须复制该值,然后再读取副本。这就是 shared_future 的作用。每个可用的 shared_future 都是通过从具有相同结果类型的 future 中移动值来直接或间接初始化的。
| shared_future<T> (§iso.30.6.7) | |
| shared_future sf {}; | 默认构造函数:不共享状态;noexcept |
| shared_future sf {fu}; | 构造函数:从 future 对象 fu 移动值; fu 不再具有状态;noexcept。 |
| shared_future sf {sf2}; | 复制构造函数和移动构造函数;移动构造函数是noexcept的。 |
| sf.˜future() | 析构函数:释放共享状态(如果存在)。 |
| sf=sf2 | 复制赋值 |
| sf=move(sf2) | 移动赋值;noexcept |
| x=sf.get() | sf 的值被复制到 x 中;如果 fu 中存储了异常,则抛出该异常。 |
| sf.get() | 对于 shared_future<void>:类似于 x=sf.get() 但不会复制任何值 |
| sf.valid() | sf 是否具有共享状态?noexcept |
| sf.wait() | 阻塞直到收到值。 |
| fs=sf.wait_for(d) | 阻塞直到收到值或经过一个时间段 duration d; fs 表明值是否已ready ,是否timeout, 或执行是否deferred。 |
| fs=sf.wait_until(tp) | 阻塞直到达到值或time_point tp 时间点; fs 表明一个值是否ready,是否timeout或执行是否deferred。 |
显然,shared_future 与 future 非常相似。关键区别在于,shared_future 会将其值移动到一个可以被重复读取和共享的位置。至于 future<T>,当 shared_future<T> 的值类型 T 为 void 或引用类型时,get() 方法的调用会遵循一些特殊规则:
• shared_future<void>::get() 不返回值:它只会返回或抛出异常。
• shared_future<T&>::get() 返回一个 T&。引用不是对象,因此库必须传输其他内容,例如 T*,然后 get() 将其(转换)回 T&。
• 当 T 不是引用类型时,shared_future<T>::get() 返回 const T&。
除非返回的对象是引用,否则它是const,因此可以安全地从多个thread访问而无需同步。如果返回的对象是非const引用,则需要某种形式的互斥机制来避免对被引用对象的数据竞争。
42.4.6 async()
有了 future 和 promise(§42.4.1)以及 packaged_task(§42.4.3),我们可以编写简单的任务,而无需过多担心thread问题。有了这些工具,thread就只是用来执行任务的载体。然而,我们仍然需要考虑使用多少thread,以及任务是在当前thread上运行还是在其他thread上运行更合适。这些决策可以委托给线程启动器(thread launcher),即一个函数,它负责决定是创建新thread,重用现有thread,还是直接在当前线程上运行任务。
| 异步任务启动器:async<F,Args>() (§iso.30.6.8) | |
| fu=async(policy,f,args) | 根据启动策略 policy 执行函数 f(args)。 |
| fu=async(f,args) | fu=async(launch::async|launch::deferred,f,args) |
async() 函数本质上是一个用于启动未知复杂程度任务的简单接口。调用 async() 函数会返回一个 future<R> 对象,其中 R 是任务结果的类型。例如:
double square(int i) { return i∗i; }
future<double> fd = async(square,2);
double d = fd.get();
如果启动一个thread来执行 square(2) 函数,我们可能会遇到一种执行 2*2 的效率非常低下的方式。使用 auto 关键字可以简化代码:
double square(int i) { return i∗i; }
auto fd = async(square,2);
auto d = fd.get();
在原则上,调用 async() 函数的调用者可以提供各种各样的信息,以帮助 async() 的实现机制决定是启动新thread还是直接在当前thread上执行任务。例如,我们可以很容易地想到,程序员可能希望向启动器提供有关任务预计运行时间的提示。然而,目前只有两种策略是标准策略:
| 启动策略:launch | |
| async | 根据启动策略 policy 执行函数 f(args)。 |
| deferred | fu=async(launch::async|launch::deferred,f,args) |
注意这里的“仿佛( as if )”。启动器在是否启动新thread方面拥有很大的自主权。例如,由于默认策略是 async|deferred(async 或 deferred),因此不难想象,async() 决定对 async(square,2) 使用 deferred,从而将执行简化为 fd.get() 调用 square(2)。我甚至可以想象,优化器会将整个代码片段简化为
double d = 4;
然而,我们不应该期望 async() 的实现会针对如此简单的示例进行优化。实现者应该将精力投入到更实际的示例中,在这些示例中,任务需要执行大量的计算,这样才能合理地考虑在新thread或“复用”thread上启动任务。
我所说的“可复用thread”是指从thread集合(线程池)中获取的thread,async() 函数可以创建一次这样的thread,然后反复使用它来执行各种任务。根据系统线程的实现方式,这可以显著降低在thread上执行任务的成本。如果thread被复用,启动程序必须确保任务不会看到之前在该thread上执行的任务遗留的状态,并且任务不会将指向其栈或thread_local数据(§42.2.8)的指针存储在非局部存储中。此类数据可能会用于安全漏洞攻击。
一个简单且实际的 async() 用法是创建一个任务来收集用户的输入:
void user()
{
auto handle = async([](){ return input_interaction_manager(); });
// ...
auto input = handle.g et();
// ...
}
这样的任务通常需要调用者提供一些数据。我使用 lambda 表达式是为了清楚地表明我可以传递参数或允许访问局部变量。使用 lambda 表达式指定任务时,请注意不要通过引用捕获局部变量。这可能导致两个thread访问同一堆栈帧,从而引发数据竞争或不良的缓存访问模式。此外,请注意,使用 [this] (§11.4.3.3) 捕获对象的成员意味着这些成员是通过指针(this)间接访问的,而不是复制,因此除非你确保对象不会由多个thread同时访问,否则它容易发生数据竞争。如有疑问,请使用值传递或值捕获 ([=]) 进行复制。
我们通常需要能够“稍后”选择调度策略,并根据需要进行更改。例如,我最初进行调试时可能会使用 launch::deferred。这样可以消除与并发相关的错误,直到我排除所有顺序执行错误为止。此外,我还可以经常回到 launch::deferred 模式,以确定某个错误是否确实与并发有关。
随着时间的推移,可能会出现更多启动策略,而且某些系统提供的启动策略可能比其他系统更好。在这种情况下,我可以通过局部更改启动策略来提高代码性能,而不是修改程序逻辑的细微之处。这再次体现了基于任务的模型(第 42.4 节)的基本简洁性所带来的优势。
将 launch::async|launch::deferred 作为默认启动策略可能会带来实际问题。本质上,这与其说是一种默认设置,不如说是一种设计缺陷。某些实现可能会认为“不使用并发”是个好主意,因此始终使用 launch::deferred 。如果你在进行并发实验时发现结果与单线程执行的结果惊人地相似,那么请尝试明确指定启动策略。
42.4.7 一个并行find()的例子
find() 函数会对序列进行线性搜索。假设有数百万个难以排序的元素,那么 find() 函数就是查找特定元素的合适算法。但这可能会很慢,因此,与其从头到尾进行一次搜索,不如将数据分成一百份,然后同时启动一百个 find() 函数分别在每一份数据上进行搜索。
首先,我们将数据表示为 Record 的vector:
extern vector<Record> goods; // 需搜索的数据
单个(顺序)任务只是简单地使用标准库函数 find_if():
template<typename Pred>
Record∗ find_rec(vector<Record>& vr, int first, int last, Pred pr)
{
vector<Record>::iterator p = std::find_if(vr.begin()+first,vr.begin()+last,pr);
if (p == vr.begin()+last)
return nullptr; // at end: no record found
return &∗p; //found: return a pointer to the element
}
遗憾的是,我们必须确定并行处理的“粒度(grain)”。也就是说,我们需要指定每次顺序搜索的记录数量。
const int grain = 50000; // 线性搜索的记录数
像那样选择一个数来确定粒度是一种非常原始的方法。除非对硬件、库的实现、数据和算法有深入了解,否则很难做出合适的选择。实验至关重要。能够帮助我们避免手动选择粒度或辅助我们进行选择的工具和框架会非常有用。然而,为了简单地演示基本标准库的功能及其最基本的使用技巧,使用固定的粒度就足够了。
pfind()(“并行查找”)函数会根据粒度和记录数量执行所需数量的 async() 调用。然后,它会获取结果:
template<typename Pred>
Record∗ pfind(vector<Record>& vr, Pred pr)
{
assert(vr.siz e()%grain==0);
vector<future<Record∗>> res;
for (int i = 0; i!=vr.siz e(); i+=grain)
res.push_back(async(find_rec<Pred>,ref(vr),i,i+grain,pr));
for (int i = 0; i!=res.size(); ++i) // look for a result in the futures
if (auto p = res[i].get()) // did the task find a match?
return p;
return nullptr; // no match found
}
最后,我们可以初始化一个搜索:
void find_cheap_red()
{
assert(goods.size()%grain==0);
Record∗ p = pfind(goods,
[](Record& r) { return r.price<200 && r.color==Color::red; });
cout << "record "<< ∗p << '\n';
}
这个并行版本的 find() 函数首先会创建大量任务,然后按顺序等待这些任务完成。与 std::find_if() 类似,它会报告第一个符合条件的元素;也就是说,它会找到索引最小的那个符合条件的元素。这或许没什么问题,但是:
• 我们最终可能要等待很多找不到任何结果的任务(也许只有最后一个任务才能找到结果)。
• 我们可能会丢弃很多可能有用的信息(例如,可能有一千个项目符合我们的条件)。
第一个问题可能没有听起来那么糟糕。假设(姑且这么认为)启动一个thread不需要任何成本,并且我们拥有的处理单元数量与任务数量相同;那么我们仍然可以在处理一个任务所需的时间内获得结果。也就是说,我们有可能在检查 50,000 条记录的时间内获得结果,而不是数百万条记录。如果我们有 N 个处理单元,结果将以 N*50000 条记录为一批次进行交付。如果在vector的最后一个片段之前都没有找到匹配的记录,则所需时间大约为 vr.size()/(N*grain) 个时间单位。
与其按顺序等待每一个任务完成,不如尝试按照任务完成的顺序查看结果。即,我们可以使用 wait_for_any() 函数(§42.4.4)。例如:
template<typename Pred>
Record∗ pfind_any(vector<Record>& vr, Pred pr)
{
vector<future<Record∗>> res;
for (int i = 0; i!=vr.siz e(); i+=grain)
res.push_back(async(find_rec<Pred>,ref(vr),i,i+grain,pr));
for (int count = res.size(); count; −−count) {
int i = wait_for_any(res,microseconds{10}); // find a completed task
if (auto p = res[i].get()) // did the task find a match?
return p;
}
return nullptr; // no match found
}
调用 get() 方法会使相应的 future 对象失效,因此我们无法两次查看部分结果。
我使用计数器来确保在所有任务都返回结果后不再继续查找。除此之外,pfind_any() 的用法与 pfind() 一样简单。pfind_any() 相较于 pfind() 是否具有性能优势取决于许多因素,但关键在于,为了(潜在地)获得并发带来的优势,我们必须使用略有不同的算法。与 find_if() 类似,pfind() 返回第一个匹配项,而 pfind_any() 返回它找到的第一个匹配项。通常,解决问题的最佳并行算法是顺序解决方案思路的一种变体,而不是简单地重复顺序解决方案。
在这种情况下,显而易见的疑问是:“真的只需要找到一个匹配项吗?”考虑到并发性,找到所有匹配项才更有意义。这样做也很简单。我们只需要让每个任务返回一个匹配项vector,而不是仅仅返回一个简单的匹配项即可:
template<typename Pred>
vector<Record∗> find_all_rec(vector<Record>& vr, int first, int last, Pred pr)
{
vector<Record∗> res;
for (int i=first; i!=last; ++i)
if (pr(vr[i]))
res.push_back(&vr[i]);
return res;
}
可以说,这个 find_all_rec() 函数比原来的 find_rec() 函数更简单。
现在我们只需要调用 find_all_rec() 函数足够多次,然后等待结果即可:
template<typename Pred>
vector<Record∗> pfind_all(vector<Record>& vr, Pred pr)
{
vector<future<vector<Record∗>>> res;
for (int i = 0; i!=vr.siz e(); i+=grain)
res.push_back(async(find_all_rec<Pred>,ref(vr),i,i+grain,pr));
vector<vector<Record∗>> r2 = wait_for_all(res);
vector<Record∗> r;
for (auto& x : r2) // merge results
for (auto p : x)
r.push_back(p);
return r;
}
如果我只是返回一个 vector<vector<Record*>> 类型的结果,那么 pfind_all() 函数将是迄今为止最简单的并行化函数。然而,通过将返回的向量合并成一个单一的向量,pfind_all() 成为了常见且流行的并行算法的一个典型示例:
[1] 创建多个待执行任务。
[2] 并行运行这些任务。
[3] 合并结果。
这就是基本思想,当它发展成一个框架,从而完全隐藏并发执行的细节时,通常称为 map-reduce [Dean, 2004]。
该示例可以这样运行:
void find_all_cheap_red()
{
assert(goods.size()%grain==0);
auto vp = pfind_all(goods,
[](Record& r) { return r.price<200 && r.color==Color::red; });
for (auto p : vp)
cout << "record "<< ∗p << '\n';
}
最后,我们必须考虑并行化工作是否值得。为此,我在测试中添加了简单的顺序执行版本:
void just_find_cheap_red()
{
auto p = find_if(goods.begin(),goods.end(),
[](Record& r) { return r.price<200 && r.color==Color::red; });
if (p!=goods.end())
cout << "record "<< ∗p << '\n';
else
cout << "not found\n";
}
void just_find_all_cheap_red()
{
auto vp = find_all_rec(goods,0,goods.size(),
[](Record& r) { return r.price<200 && r.color==Color::red; });
for (auto p : vp)
cout << "record "<< ∗p << '\n';
}
对于我简单的测试数据和我(相对而言)配置较低、只有四个硬件线程的笔记本电脑,我没有发现任何一致或显著的性能差异。在这种情况下,由于 async() 函数的实现尚不成熟,线程创建的开销占据了主导地位,掩盖了并发带来的优势。如果我现在需要显著的并行加速,我会基于预先创建的线程池和工作队列,实现一个自己的 async() 函数变体,类似于使用 packaged_tasks (§42.4.3) 的 Sync_queue (§42.3.4) 的方式。值得注意的是,这种重要的优化无需修改我基于任务的并行 find() 程序即可完成。从应用程序的角度来看,用优化版本替换标准库的 async() 函数只是一个实现细节。
42.5 建议(Advice)
[1] thread是系统线程的一种类型安全接口;§42.2。
[2] 不要销毁正在运行的thread;§42.2.2。
[3] 使用 join() 等待一个thread完成;§42.2.4。
[4] 考虑使用 guarded_thread 为thread提供 RAII 机制;§42.2.4。
[5] 除非绝对必要,否则不要调用 detach() 分离线程;§42.2.4。
[6] 使用 lock_guard 或 unique_lock 管理互斥锁;§42.3.1.4。
[7] 使用 lock() 获取多个锁;§42.3.2。
[8] 使用condition_variable管理thread间的通信;§42.3.4。
[9] 思考可以并发执行的任务,而不是直接思考thread;§42.4。
[10] 追求简洁;§42.4。
[11] 使用 promise 返回结果,并从 future 获取结果;§42.4.1。
[12] 不要对同一个 promise 调用 set_value() 或 set_exception() 两次;§42.4.2。
[13] 使用 packaged_tasks 处理任务抛出的异常并安排返回值;§42.4.3。
[14] 使用 packaged_task 和 future 来表达对外部服务的请求并等待其响应;§42.4.3。
[15] 不要对同一个 future 调用两次 get();§42.4.4。
[16] 使用 async() 启动简单的任务;§42.4.6。
[17] 选择合适的并发任务粒度很困难:需要进行实验和测量;§42.4.7。
[18] 尽可能将并发性隐藏在并行算法的接口后面;§42.4.7。
[19] 并行算法在语义上可能与同一问题的顺序解决方案不同(例如,pfind_all() 与 find());§42.4.7。
[20] 有时,顺序解决方案比并发解决方案更简单、更快;§42.4.7。
内容来源:
<<The C++ Programming Language >> 第4版,作者 Bjarne Stroustrup


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









