







STL容器(Standard Template Library Container)
目录
31.2.1 容器表示(Container Representation)
31.2.2 容器中元素要求(Element Requirements)
31.2.2.1 容器中元素比较问题(Comparisons)
31.2.2.2 其它关系运算符(Other Relational Operators)
31.3 容器操作概览(Operations Overview)
31.3.2 构造、析构、和赋值(Constructors, Destructor, and Assignments)
31.3.3 大小和容量(Size and Capacity)
31.4.1.1 vector及其增长(vector and Growth)
31.4.1.2 vector及其嵌入(vector and Nesting)
31.4.1.3 vector和array(vector and Arrays)
31.4.1.4 vector和string (vector and string)
31.4.3 关联容器(Associative Containers)
31.4.3.1 有序关联容器(Ordered Associative Containers)
31.4.3.2 无序关联容器(Unordered Associative Containers)
31.4.3.3 构造unordered_map (Constructing unordered_maps)
31.4.3.4 哈希和相等函数 (Hash and Equality Functions)
31.4.3.5 装载和桶(Load and Buckets)
31.5 容器适配器(Container Adaptors)
31.1 引言(Introduction)
STL由标准库中的迭代器(iterator),容器(container),算法(algorithm)和函数对象(function object)部分组成。STL 的其余部分将在第 32 章和第 33 章中介绍。
31.2 容器概览(Container Overview)
容器用于保存一系列对象。本节概述了容器的类型并简要概述了它们的属性。容器的操作在§31.3中进行了总结。
容器可以像这样分类:
• 序列容器提供对(半开)元素序列的访问。(译注:按内存连续形式存储元素。)
• 关联容器提供基于键的关联查找。(译注:按键值对存储元素,在内存上不一定连续。)
此外,标准库提供了一些保存元素的对象的类型,但它们并不提供序列容器或关联容器的所有功能:
• 容器适配器提供对底层容器的专用访问。
• 几乎所有容器都是元素序列,它们提供容器的大部分(但不是全部)功能。
STL 容器(序列容器和关联容器)都是具有复制和移动操作的资源句柄(§3.3.1)。所有对容器的操作都提供了基本保证(§13.2),以确保它们能够与基于异常的错误处理正确交互。
| 序列容器 | |
| vector<T,A> | 一个连续分配的T序列;默认的容易选择。 |
| list<T,A> | 一个T 的双向链表,当然你需要插入或删除元素而又不移动现有元素,就使用这种容器。 |
| forward_list<T,A> | 一个T 的单向链表,非常适合空的和非常短的序列。 |
| deque<T,A> (译注:de=d(oubl)e,que = que(ue)) | 一个T的双端队列;vector和list的混合体;在大多数情况下比其中之一慢。 |
模板参数 A 是容器用于获取和释放内存的分配器(§13.6.1,§34.4)。例如:
template<typename T, typename A = allocator<T>>
class vector {
// ...
};
A 默认为 std::allocator<T> (§34.4.1),当它需要为其元素获取或释放内存时,使用运算符 new() 和运算符 delete() 。
这些容器定义在 <vector>,<list> 和 <deque> 中。序列容器是连续分配的(例如,vector),或链表(例如,forward_list ),其元素的值类型(在上面使用的符号中为 T )相同。deque(发音为“deck”)是链表和连续分配的混合体。
除非你有充分的理由不这样做,否则请使用vector。注意,vector提供了插入和删除元素的操作,允许向量根据需要增长和收缩。对于小元素序列,vector可以很好地表示需要列表操作的数据结构。
插入或删除vector元素时,元素可能会被移动。相反,list或关联容器的元素在插入新元素或删除其他元素时不会移动。
forward_list(单链表)在本质上是一个针对空list和非常短的列表进行了优化的list。空的 forward_list 只占用一个字。令人惊讶的是,大多数为空(其余非常短)的列表用途广泛。
| 有序关联容器(§iso.23.4.2) | |
| map<K,V,C,A> | 从K到 V 的有序map,一个 <K,V> 对序列。 |
| multimap<K,V,C,A> | 从K到 V 的有序map,允许重复键。 |
| set<K,C,A> | 一个有序的K集。 |
| multiset<K,C,A> | 一个有序的K集, 允许重复键。 |
这些容器通常实现为平衡二叉树(通常是红黑树)。
一个键 K 默认有序标准是 std::less<K> (§33.4)。
对于序列容器,模板参数 A 是容器用于获取和释放内存的分配器(§13.6.1,§34.4)。对于map,模板参数 A 默认为 std::allocator<std::pair<const K,T>> (§31.4.3),对于set,模板参数 A 默认为 std::allocator<K> 。
| 无序关联容器(§iso.23.5.2) | |
| unordered_map<K,V,H,E,A> | 从K到 V 的无序map 。 |
| unordered_multimap<K,V,H,E,A> | 从K到 V 的无序map,允许重复键。 |
| unordered_set<K,H,E,A> | 一个无序的K集。 |
| unordered_multiset<K,H,E,A> | 一个无序的K集, 允许重复键。 |
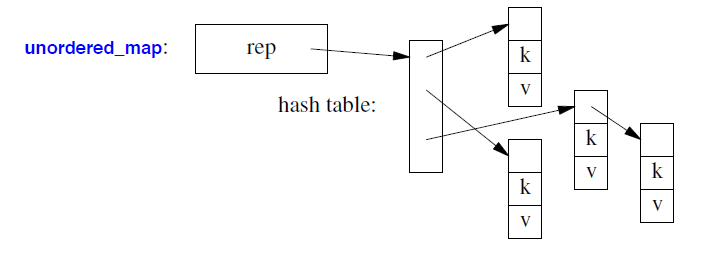
这些容器实现为带有链接溢出(overflow)的哈希表。类型 K 的默认哈希函数类型 H 为 std::hash<K> (§31.4.3.2)。类型 K 的相等函数类型 E 的默认值为 std::equal_to<K> (§33.4);该相等函数用于判断两个具有相同哈希码的对象是否相等。
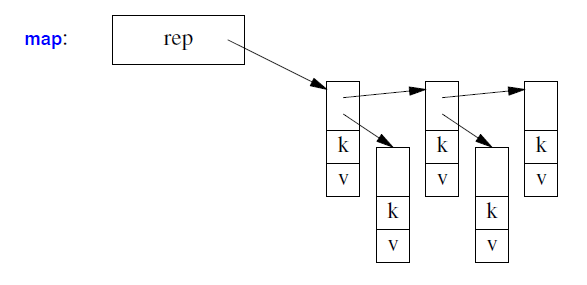
关联容器是具有其值类型(value_type)节点的链表结构(树)(在上面使用的表示法中,pair<const K,V> 表示map,K 表示set)。set,map或multimap的序列按其键值 (K) 排序。无序容器不需要其元素具有有序关系(例如 < ),而是使用哈希函数 (§31.2.2.1)。无序容器的序列不保证顺序。multimap与map的不同之处在于,一个键值可能出现多次。
容器适配器是向其他容器提供专用接口的容器:
| 容器适配器 C是容器类型 | |
| priority_queue<T,C,Cmp> | T的优先队列; Cmp是优先函数类型 。 |
| queue<T,C> | 具有push()和pop()的T的队列。 |
| stack<T,C> | 具有push()和pop()的T的栈。 |
优先级队列 (priority_queue) 的优先级函数 Cmp 的默认值为 std::less<T>。容器类型 C 的默认值为:对于队列 (queue) 为 std::deque<T>,对于栈 (stack) 和优先级队列 (priority_queue) 为 std::vector<T>。参见 §31.5。
有些数据类型满足了标准容器的大部分设计要求,但并非全部。我们有时将这些数据类型称为“准容器(almost containers)”。其中最有趣的是:
| “准容器(almost containers)” | |
| T[N] | 固定大小的内置数组:N 个连续的 T 类型元素;无 size() 或其他成员函数。 |
| array<T,N> | 一个由 N 个连续元素组成的固定大小的 T 类型数组;类似内置数组,但解决了大多数问题。 |
| basic_string<C,Tr,A> | 连续分配的 C 类型字符序列,用于文本操作,例如连接(+ 和 +=);basic_string 通常经过优化,不需要为短字符串预留存储空间(§19.3.3)。 |
| string | basic_string<char> |
| u16string | basic_string< char16_t > |
| u32string | basic_string< char32_t > |
| wstring | basic_string< wchar_t > |
| valarray<T> | 具有vector运算的数值vector,但为了实现高性能,会受到一些限制;仅在进行大量vector运算时使用。 |
| bitset<N> | 一个具有集合运算的N 位的集合,例如 & 和 | 。 |
| vector<bool> | 具有紧致存储位的一个vector<T>的特化。 |
对于 basic_string,A 是分配器(§34.4),Tr 是字符trait(§36.2.2)。
如果可以选择,优先使用容器,例如vector, string或array,而不是数组。隐式数组到指针的转换以及需要记住内置数组的大小是导致错误的主要来源(例如,参见§27.2.1)。
优先使用标准字符串,而非其他字符串和 C 风格字符串。C 风格字符串的指针语义意味着书写方式不便,程序员需要做额外的工作,而且它们是错误(例如内存泄漏)的主要来源(§36.3.1)。
31.2.1 容器表示(Container Representation)
该标准并未规定标准容器的特定表示形式。相反,它指定了容器接口和一些复杂性要求。实现者将选择合适的、通常经过巧妙优化的实现,以满足一般需求和常见用途。除了操作元素所需的功能外,此类“句柄”还将保存一个分配器(§34.4)。
对于一个 vector (译注:可以看成是一个数组),其元素数据结构很可能是一个数组:
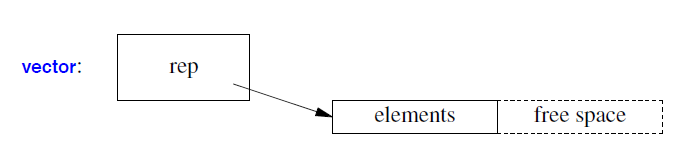
该vector将保存指向元素数组的指针、元素数量和容量(已分配的、当前未使用的内存槽位(slots)的数量)或等效值(§13.6)。
list很可能由指向元素的链表序列和元素的数量来表示:
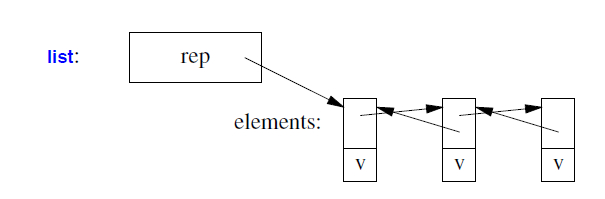
forward_list 很可能由指向以下元素的一个链表序列表示:
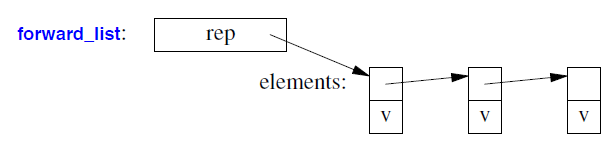
map 最有可能实现为指向(键,值)对的节点(平衡)树:
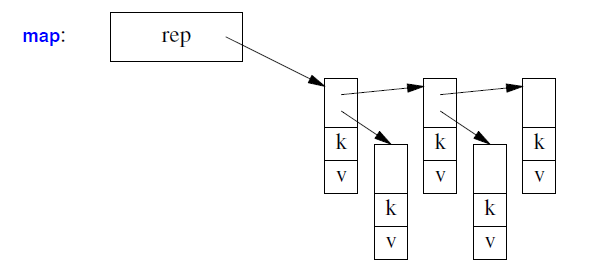
一个 unordered_map 最有可能实现为哈希表:
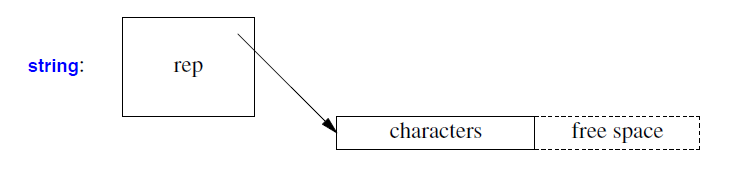
一个string可以按照§19.3和§23.2中概述的方式实现;也就是说,对于短string,字符存储在字符串句柄本身中;对于长string,元素连续存储在自由存储空间中(类似vector元素)。与vector类似,string可以增长到分配的“自由空间”,以避免重复重新分配:
与内置数组(§7.3)类似,array只是元素的序列,没有句柄(译注:但相对于内置数组使用起来更方便):
这意味着局部数组不使用任何自由存储(除非它在那里分配)(译注:作者的意思是程序员手动分配,比如使用new()运算符分配),并且类的数组成员不意味着任何自由存储操作。
31.2.2 容器中元素要求(Element Requirements)
要成为容器的元素,对象的类型必须允许容器实现复制或移动它,以及交换元素。如果容器使用复制构造函数或复制赋值函数复制元素,则复制的结果必须是等效的对象。这大致意味着,任何针对对象值进行的相等性测试都必须将副本视为与原始值相等。换言之,复制元素的操作必须与复制 int 类型的普通副本非常相似(译注:实际上就是要注意自由存储分配这种情况)。同样,移动构造函数和移动赋值函数必须具有常规定义和移动语义(§17.5.1)。此外,必须能够使用常规语义swap()元素。如果类型具有复制或移动功能,则标准库中的 swap() 函数将起作用。
标准中关于元素要求的细节散布各处,且颇为晦涩(§iso.23.2.3,§iso.23.2.1,§iso.17.6.3.2),但基本上,容器可以容纳具有常规复制或移动操作的元素。许多基本算法,例如 copy(),find() 和 sort(),只要满足容器元素的要求以及算法的特定要求(例如元素有序;§31.2.2.1),就能正常工作。
一些违反标准容器规则的行为可以被编译器检测到,但其他一些则无法检测到,并且可能会导致意外行为。例如,抛出异常的赋值操作可能会留下一个部分复制的元素。这将是糟糕的设计(§13.6.1),并且由于未提供基本保证(§13.2),违反了标准规则。处于无效状态的元素可能会在以后造成严重问题。
当复制对象不合理时,一种替代方法是将指向对象的指针放入容器中,而不是将对象本身放入容器中。最明显的例子是多态类型(§3.2.2,§20.3.2)。例如,我们使用vector<unique_ptr<Shape>> 或 vector<Shape∗> 而不是vector<Shape> 来保留多态行为。
31.2.2.1 容器中元素比较问题(Comparisons)
关联容器要求其元素可以排序。许多可应用于容器的操作(例如 sort() 和 merge())也要求排序。默认情况下,使用 < 运算符定义顺序。如果 < 不合适,程序员必须提供替代方案(§31.4.3,§33.4)。排序标准必须定义严格的弱排序。通俗地说,这意味着小于和相等(如果定义)都必须是可传递的。也就是说,对于排序标准 cmp(可以将其视为“小于”),我们要求:
[1] 非自反性:cmp(x,x) 为假。
[2] 反对称性:cmp(x,y) 蕴含 !cmp(y,x)。
[3] 可传递性:如果 cmp(x,y) 且 cmp(y,z),则 cmp(x,z)。
[4] 等价的传递性:定义 equiv(x,y) 为 !cmp(x,y)||cmp(y,x))。( 如果 equiv(x,y) 且 equiv(y,z),则 equiv(x,z)。)
最后一条规则允许我们将相等性 (x==y) 定义为 !(cmp(x,y)||cmp(y,x))(如果我们需要 == )。标准库中需要比较的操作有两种版本。例如:
template<typename Ran>
void sort(Ran first, Ran last); // 用 < 比较
template<typename Ran, typename Cmp>
void sort(Ran first, Ran last, Cmp cmp); // 用cmp
第一个版本使用 < ,第二个版本使用用户提供的比较运算符 cmp。例如,我们可能决定使用不区分大小写的比较运算符对水果进行排序。为此,我们定义了一个函数对象(§3.4.3,§19.2.2),当对一对字符串调用该函数对象时,它会执行该比较操作:
class Nocase { // 大小写不敏感 string 比较
public:
bool operator()(const string&, const string&) const;
};
bool Nocase::operator()(const string& x, const string& y) const
// 如果 x 按字典顺序小于 y,则返回 true,不考虑大小写
{
auto p = x.begin();
auto q = y.begin();
while (p!=x.end() && q!=y.end() && toupper(∗p)==toupper(∗q)) {
++p;
++q;
}
if (p == x.end()) return q != y.end();
if (q == y.end()) return false;
return toupper(∗p) < toupper(∗q);
}
我们可以使用该比较标准调用 sort()。考虑:
fruit:
apple pear Apple Pear lemon
使用 sort(fruit.begin(),fruit.end(),Nocase()) 进行排序将产生类似以下结果:
fruit:
Apple apple lemon Pear pear
假设字符集中大写字母位于小写字母之前,则简单的 sort(fruit.begin(),fruit.end()) 将给出:
fruit:
Apple Pear apple lemon pear
请注意,C 风格字符串(例如 const char∗s)中的 < 比较的是指针值(§7.4)。因此,如果使用 C 风格字符串作为键,关联容器将无法像大多数人预期的那样工作。为了使它们正常工作,必须使用基于字典顺序的小于操作。例如:
struct Cstring_less {
bool operator()(const char∗ p, const char∗ q) const { return strcmp(p,q)<0; }
};
map<char∗,int,Cstring_less> m; // map that uses strcmp() to compare const char* keys
31.2.2.2 其它关系运算符(Other Relational Operators)
默认情况下,容器和算法在需要进行小于比较时使用 < 。如果默认值不正确,程序员可以提供比较标准。但是,没有提供同时通过相等性测试的机制。相反,当程序员提供比较 cmp 时,会使用两个比较来测试相等性。例如:
if (x == y) //用户提供的比较未完成
if (!cmp(x,y) && !cmp(y,x)) // 用户提供的比较 cmp完成
这样,用户就不必为用作关联容器值类型的每个类型或使用比较算法的类型提供相等性运算。这看起来可能很昂贵,但该库并不经常检查相等性,大约 50% 的情况下只需要调用一次 cmp(),而且编译器通常可以优化掉重复检查。
使用小于(默认为 < )而不是相等(默认为 == )定义的等价关系也有实际用途。例如,关联容器(§31.4.3)使用等价测试 !(cmp(x,y)||cmp(y,x)) 比较键。这意味着等价键不必相等。例如,使用不区分大小写比较作为比较标准的multimap(§31.4.3)会将字符串 Last ,last , lAst , laSt 和 lasT 视为等价,即使字符串的 == 认为它们不同。这使我们能够在排序时忽略我们认为无关紧要的差异。
有了 < 和 ==,我们可以轻松构造其余的常见比较操作。标准库在命名空间 std::rel_ops 中定义了它们,并在 <utility> (§35.5.3) 中进行了展示。
31.3 容器操作概览(Operations Overview)
标准容器提供的操作和类型可以概括如下:
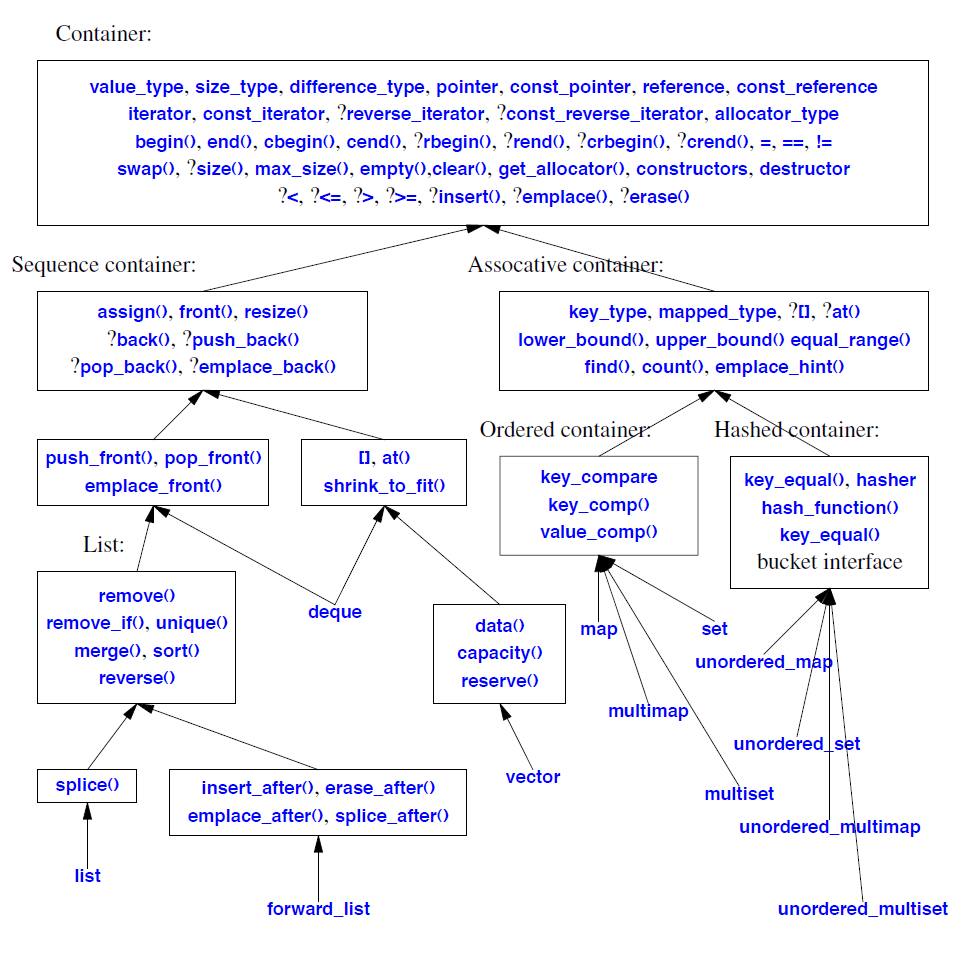
箭头表示为容器提供了一组操作;它不是继承操作。问号 (?) 表示简化:我仅包含了为部分容器提供的操作。具体来说:
• multi∗ 关联容器或集合不提供 [] 或 at() 操作。
• forward_list 不提供 insert(),erase() 或 emplace() 操作;它提供的是 ∗_after 操作。
• forward_list 不提供 back(),push_back(),pop_back() 或 emplace_back() 操作。
• forward_list 不提供 reverse_iterator,const_reverse_iterator,rbegin(),rend(),crbegin(),crend() 或 size() 操作。
• unordered_∗ 关联容器不提供 < ,<= ,> 或 >= 操作。
重复 [] 和 at() 操作只是为了减少箭头的数量。
桶(bucket)接口在§31.4.3.2中描述。
在有意义的地方,访问操作有两个版本:一个用于 const,一个用于非 const 对象。
标准库操作具有复杂性保证:
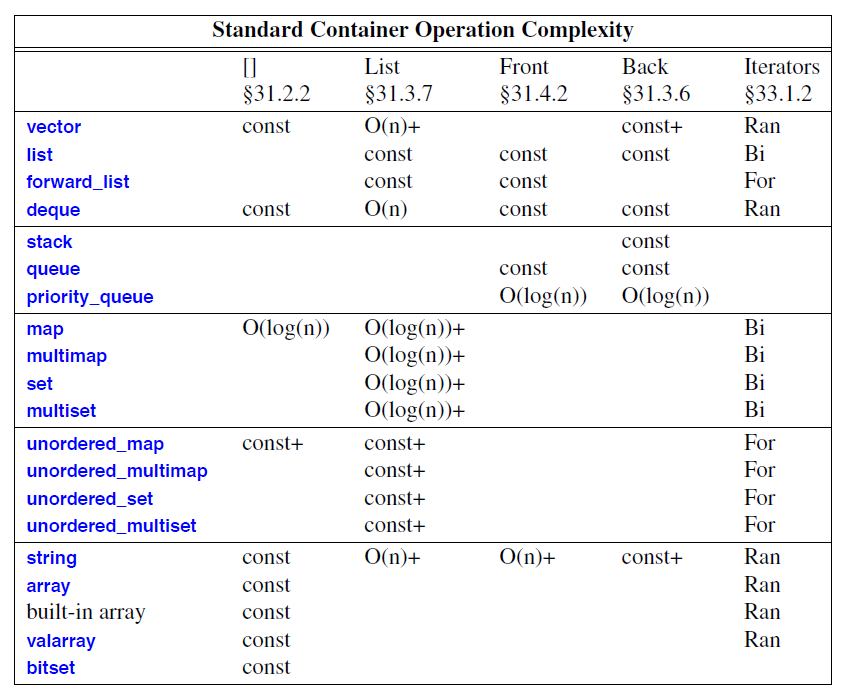
“Front”操作是指在第一个元素之前插入和删除。类似地,“Back”操作是指在最后一个元素之后插入和删除;“List”操作是指插入和删除不一定在容器的末尾进行。
在Iterators列中,“Ran”表示“随机访问迭代器”,“For”表示“前向迭代器”,“Bi”表示“双向迭代器”(§33.1.4)。
其他条目衡量操作的效率。const条目表示操作所需的时间与容器中的元素数量无关;常数时间的另一个常规表示法是 O(1)。O(n) 表示操作所需的时间与所涉及的元素数量成正比。+ 后缀表示偶尔会产生显著的额外开销。例如,将元素插入列表具有固定开销(因此列为 const),而对vector执行相同的操作则涉及移动插入点之后的元素(因此列为 O(n))。有时,向量的所有元素都必须重新定位(因此我添加了一个 + )。“大 O”表示法是常规的(译注:表示时间复杂度,德语单词 Ordnung 的首字母,英语中对应单词为 Order,指的是“阶”,例如级数展开式中幂的最高次项的阶)。我添加 + 是为了方便那些除了平均性能之外还关心可预测性的程序员。O(n)+ 的常规术语是平摊线性时间(amortized linear time)。
当然,如果一个常数很大,它的成本可能会比与元素数量成比例的小成本高得多。然而,对于大型数据结构来说,const 往往意味着“廉价”,O(n) 意味着“昂贵”,而 O(log(n)) 则意味着“相当廉价”。即使 n 值比较大,O(log(n))(其中 log 是二进制对数,即以2为底的对数)也更接近常数时间,而不是 O(n)。例如:
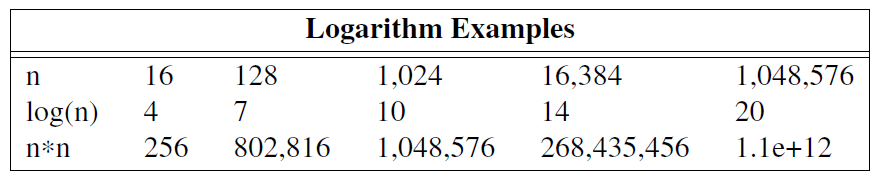
那些在意成本的人必须仔细研究。特别是,他们必须了解计算 n 需要计算哪些元素。然而,信息很明确:对于较大的 n 值,不要使用二次算法。
复杂性和成本的衡量标准是上限。这些衡量标准的存在是为了给用户提供一些指导,让他们了解最终的实现效果。当然,在重要情况下,实现者会努力做得更好。
请注意,“大O”复杂度度量是渐近的;也就是说,可能需要处理大量元素后,复杂度差异才会变得显著。其他因素,例如对单个元素执行单个操作的成本,也可能起主导作用。例如,遍历vector和list的复杂度均为 O(n)。然而,考虑到现代机器架构,通过链表(在list中)获取下一个元素的成本可能比获取vector的下一个元素(元素连续)的成本高得多。同样,由于内存和处理器架构的细节,线性算法对于十倍数量的元素,所需的时间可能远多于或少于十倍。不要仅仅相信你对成本和复杂性度量的直觉;要进行度量。幸运的是,容器接口非常相似,因此不难通过代码进行比较。
size() 操作对所有操作而言都是常数时间。需要注意的是,forward_list 没有 size() 操作,因此如果您想知道元素数量,必须自行计算(计算时间为 O(n))。forward_list 针对空间进行了优化,不存储其大小或指向最后一个元素的指针。
string估算针对的是较长的字符串。“短字符串优化”(§19.3.3)使所有短字符串(例如,少于 14 个字符)的操作都保持恒定时间。
stack和queue的条目反映了使用双端队列作为底层容器的默认实现的成本(§31.5.1,§31.5.2)。
31.3.1 容器的成员类型(Member Types)
一个容器定义了一组成员类型:
| 容器成员类型(§iso.23.2, §iso.23.3.6.1) | |
| value_type | 元素类型 |
| allocator_type | 内存管理器类型 |
| size_type | 容器下标、元素数量、等的无符号类型(即数据的最高位表示数据,只取正和0), |
| difference_type | 迭代器之间的差之无符号类型 |
| iterator | 其行为类似 value_type * |
| const_iterator | 其行为类似const_value_type∗ |
| reverse_iterator | 其行为类似value_type ∗ |
| reference | value_type & |
| const_reference | const_value_type& |
| pointer | 其行为类似 value_type * |
| const_pointer | 其行为类似 const_value_type * |
| key_type | key的类型,仅对针关系容器 |
| mapped_type | mapped_type的值类型,仅对针关系容器 |
| key_compare | 比较标准类型,仅针对有序容器 |
| hasher | 哈希函数类型,仅针对无序容器 |
| key_equal | 等价函数类型,仅针对无序容器 |
| local_iterator | 桶迭代类型,仅针对无序容器 |
| const_local_iterator | 桶迭代类型,仅针对无序容器 |
每个容器和“准容器”都提供了大多数这些成员类型。但是,它们不会提供无意义的类型。例如,array 没有 allocator_type,而vector 没有 key_type。
31.3.2 构造、析构、和赋值(Constructors, Destructor, and Assignments)
容器提供了各种构造函数和赋值操作。对于名为 C 的容器(例如,vector<double> 或 map<string,int>),我们有:
| 构造,析构,和赋值 C是一个容器,默认情况下,一个C使用一个默认分配器C::allocator_type{} | |
| C c {}; | 默认构造,c是一个空容器 |
| C c {a}; | 默认构造c,使用分配器a |
| C c(n); | 用值 value_type{} 初始化对象 c 的 n 个元素;不适用于关联容器 |
| C c(n,x); | 用 n 个 x 的副本初始化c ;不适用于关系容器 |
| C c(n,x, a); | 用 n 个 x 的副本初始化c ;用分配器 a ;不适用于关系容器 |
| C c {elem}; | 从elem初始化c; 若c有一个 initializer-list 构造函数,则选择它; 若则,用另一个构造函数。 |
| C c {c2}; | 复制构造函数:复制 c2 的元素和分配器到c |
| C c {move(c2)}; | 移动构造函数:移动 c2 的元素和分配器到c |
| C c {{elem},a}; | 从initializer_list {elem} 初始化c , 使用分配器 a |
| C c {b,e}; | 用来自 [b:e) 的元素初始化 c |
| C c {b,e ,a}; | 用来自 [b:e) 的元素初始化 c ; 使用分配器 a |
| c.˜C() | 析构函数:销毁 c 的元素并释放所有资源 |
| c2=c | 复制赋值,将 c的元素复制进c2 |
| c2=move(c) | 移动赋值,将 c的元素移进c2 |
| c={elem} | 从initializer_list {elem} 向 c 赋值 |
| c.assign(n,x) | 赋值 n 个 x 的副本;不适用于关联容器 |
| c.assign(b,e) | 从 [b:e) 向 c 赋值 |
| c.assign({elem}) | 从initializer_list {elem} 向 c 赋值 |
关联容器的附加构造函数在§31.4.3 中描述。
请注意,赋值不会复制或移动分配器。目标容器会获得一组新的元素,但会保留其旧容器,并使用该旧容器为新元素(如果有)分配空间。分配器在§34.4中描述。
请记住,构造函数或元素副本可能会抛出异常,表明它无法执行其任务。
初始化器的潜在歧义在 §11.3.3 和 §17.3.4.1 中讨论。例如:
void use()
{
vector<int> vi {1,3,5,7,9}; //由5个元素初始化的vector
vector<string> vs(7); // 由7个空string 初始化的vector
vector<int> vi2;
vi2 = {2,4,6,8}; // 将 4 个整数序列赋值到vi2
vi2.assign(&vi[1],&vi[4]); //赋值序列3,5,7 至 vi2
vector<string> vs2;
vs2 = {"The Eagle", "The Bird and Baby"}; // 赋值2个string至 vs2
vs2.assign("The Bear", "The Bull and Vet"); //运行时错误
}
对 vs2 赋值时的错误在于传递了一对指针(而不是一个initializer_list),而这两个指针指向的不是同一个数组。大小初始化器使用 (),其他类型的迭代器使用 {}。
容器通常很大,所以我们几乎总是通过引用传递它们。但是,由于它们是资源句柄(§31.2.1),我们可以高效地返回它们(隐式使用 move 操作)。同样,当我们不想使用别名时,可以将它们作为参数移动。例如:
void task(vector<int>&& v);
vector<int> user(vector<int>& large)
{
vector<int> res;
// ...
task(move(large)); // 将数据所有权转移给task()
// ...
return res;
}
31.3.3 大小和容量(Size and Capacity)
大小是容器中元素的数量;容量是容器在分配更多内存之前可以容纳的元素数量:
| 大小和容量 | |
| x=c.size() | x是c的元素数量 |
| c.empty() | c是否为空 |
| x=c.max_size() | x是c的最大可能元素数量 |
| x=c.capacity() | x是为c分配的空间;仅针对 vector 和 string |
| c.reserve(n) | c的n个元素的空间反转;仅针对 vector 和 string |
| c.resize(n) | 将 c 的大小改变为 n ; 对于加入的元素使用默认元素值; 仅针对序列容易(和string) |
| c.resize(n,v) | 将 c 的大小改变为 n ; 对于加入的元素使用v值; 仅针对序列容易(和string) |
| c.shrink_to_fit() | 使 c.capacity() 等于 c.size() ; 仅针对 vector, deque 和 string |
| c.clear() | 擦除 c 的所有元素 |
更改大小或容量时,元素可能会被移动到新的存储位置。这意味着指向元素的迭代器(以及指针和引用)可能会失效(即指向旧的元素位置)。有关示例,请参阅§31.4.1.1。
指向关联容器(例如 map)元素的迭代器,只有当其指向的元素从容器中移除( erase();§31.3.7)时才会失效。相比之下,指向序列容器(例如 vector)元素的迭代器,如果元素被重新定位(例如,通过 resize(), reserve() 或 push_back()),或者其指向的元素在容器内被移动(例如,通过对索引较低的元素执行 eras() 或 insert()),则会失效。
人们很容易认为 reserve() 可以提高性能,但向量的标准增长策略(§31.4.1.1)非常有效,因此性能很少成为使用 reserve() 的充分理由。相反,reserve() 应该视为一种提高性能可预测性和避免迭代器失效的方法。
31.3.4 迭代器(Iterators)
一个容器可以视为一个按照容器迭代器定义的顺序或其反向顺序排布的序列。对于关联容器,顺序基于容器的比较条件(默认为 < ):
| 迭代器 | |
| p=c.begin() | p指向c的第一个元素(如果没有元素,则指向end()所指的位置) |
| p=c.end() | p指向c的最后一个元素的下一个位置(这是一个没有存储元素的位置) |
| cp=c.cbegin() | p指向constant 的 c的第一个元(如果没有元素,则指向cend()所指的位置) |
| p=c.cend() | p指向constant 的 c的最后一个元素的下一个位置 |
| p=c.rbegin() | c的n个元素的空间反转;仅针对 vector 和 string |
| p=c.rend() | p指向c的反转的第一个元(如果没有元素,则指向end()所指的位置) |
| p=c.crbegin() | p指向 constant 的c的反转的第一个元(如果没有元素,则指向crend()所指的位置) |
| p=c.crend() | p指向 constant 的c的反转的最后一个元素的下一个位置 |
元素迭代最常见的形式是从容器的开头到结尾进行遍历。最简单的方法是使用范围for(§9.5.1),它隐式地使用了 begin() 和 end()。例如:
for (auto& x : v) // implicit use of v.begin() and v.end()
cout << x << '\n';
当我们需要知道元素在容器中的位置,或者需要一次引用多个元素时,我们会直接使用迭代器。在这种情况下,auto 有助于最小化源代码大小并消除拼写错误。例如,假设一个随机访问迭代器:
for (auto p = v.begin(); p!=end(); ++p) {
if (p!=v.begin() && ∗(p−1)==∗p)
cout << "duplicate " << ∗p << '\n';
}
当我们不需要修改元素时,cbegin() 和 cend() 是合适的。也就是说,我应该这样写:
for (auto p = v.cbegin(); p!=cend(); ++p) { // 使用 const 迭代器
if (p!=v.cbegin() && ∗(p−1)==∗p)
cout << "duplicate " << ∗p << '\n';
}
对于大多数容器和大多数实现来说,重复使用 begin() 和 end() 并不会带来性能问题,所以我没有费心去让代码变得像这样复杂:
auto beg = v.cbegin();
auto end = v.cend();
for (auto p = beg; p!=end; ++p) {
if (p!=beg && ∗(p−1)==∗p)
cout << "duplicate " << ∗p << '\n';
}
31.3.5 元素访问(Element access)
一些元素可以直接方问:
| 迭代器 | |
| c.front() | 引用 c 的第一个元素;不适用于关联容器 |
| c.back() | 引用 c 的最后一个元素;不适用于 forward_list 或关联容器 |
| c[i] | 引用 c 的第 i 个元素;未经检查的访问;不适用于列表或关联容器 |
| c.at(i) | 引用 c 的第 i 个元素;如果 i 超出范围,则抛出 out_of_range异常;不适用于列表或关联容器 |
| c[k] | 引用 c 中键为 k 的元素;如果未找到,则插入 (k,mapped_type{});仅适用于 map 和 unordered_map |
| c.at(k) | 引用 c 的第 i 个元素;如果未找到 k,则抛出 out_of_range 异常;仅适用于 map 和 unordered_map |
某些实现(尤其是调试版本)始终会进行范围检查,但您无法完全依赖此方法确保正确性,也无法依赖其不进行性能检查。如果此类问题很重要,请检查你的实现。
关联容器 map 和 unordered_map 具有 [] 和 at(),它们接受键类型的参数,而不是位置(§31.4.3)。
31.3.6 栈操作(Stack Operations)
标准vector,deque和list(但不包括 forward_list 或关联容器)在其元素序列的末尾(返回)提供了高效的操作:
| 栈操作 | |
| c.push_back(x) | 将 x 添加到 c 的最后一个元素之后(使用复制或移动) |
| c.pop_back() | 引用 c 的最后一个元素;不适用于 forward_list 或关联容器 |
| c.emplace_back(args) | 引用 c 的第 i 个元素;未经检查的访问;不适用于列表或关联容器 |
c.push_back(x) 将 x 移动或复制到 c 中,使 c 的大小增加 1。如果内存不足或 x 的复制构造函数抛出异常,c.push_back(x) 将会失败。push_back() 失败对容器没有任何影响:容器仍然提供强引用保证 (§13.2)。
注意,pop_back() 不返回值。如果它返回了值,复制构造函数抛出的异常可能会严重影响实现。
此外,list 和 deque 在其序列的开头(前端)提供了等效的操作(§31.4.2)。这就是 forward_list 的作用。
push_back() 一直以来都是一个很受欢迎的函数,它可以增加容器空间,避免预分配和溢出,但 emplace_back() 也可以起到类似的作用。例如:
vector<complex<double>> vc;
for (double re,im; cin>>re>>im; ) //读两个双精度数
vc.emplace_back(re ,im); // 在尾部加入 complex<double>{re,im}
31.3.7 链表操作(List Operations)
容器提供链表操作:
| 链表操作 | |
| q=c.insert(p,x) | 在 p 之前添加 x;使用复制或移动 |
| q=c.insert(p,n,x) | 在 p 之前添加 n 个 x 副本;如果 c 是关联容器,则 p 是从哪里开始搜索的提示 |
| q=c.insert(p,first,last) | 在 p 之前添加来自 [first:last) 的元素;不适用于关联容器 |
| q=c.insert(p,{elem}) | 在 p 之前添加来自初始化列表 {elem} 的元素;p 提示从哪里开始搜索放置新元素的位置;仅适用于有序关联容器 |
| q=c.emplace(p,args) | 在 p 之前添加由 args 构造的元素;不适用于关联容器 |
| q=c.erase(p) | 从 c 中删除 p 处的元素 |
| q=c.erase(first,last) | 擦除 c 的 [first:last) |
| c.clear() | 删除 c 的所有元素 |
对于 insert() 函数,结果 q 指向最后一个插入的元素。对于 erase() 函数,q 指向最后一个被擦除元素之后的元素。
对于具有连续内存分配的容器(例如 vector 和 deque),插入和删除元素可能会导致元素移动。指向已移动元素的迭代器将变为无效。如果元素的位置位于插入/删除点之后,或者由于新大小超出了先前的容量而导致所有元素都移动,则元素将移动。例如:
vector<int> v {4,3,5,1};
auto p = v.begin()+2; // 指向 v[2], 即, 元素5
v.push_back(6); //p 变得无效; v == {4,3,5,1,6}
p = v.begin()+2; // 指出 v[2], 即元素 5
auto p2 = v.begin()+4; // 指出 v[4], 即元素 6
v.erase(v.begin()+3); // v == {4,3,5,6}; p 仍有效; p2 无效
任何向vector添加元素的操作都可能导致每一个元素重新分配位置(§13.6.4)。
emplace() 操作适用于这种情况:首先创建一个对象,然后将其复制(或移动)到容器中,这种方式在符号上比较笨拙或效率较低。例如:
void user(list<pair<string,double>>& lst)
{
auto p = lst.begin();
while (p!=lst.end()&& p−>first!="Denmark") //查找插入点
/* do nothing */ ;
p=lst.emplace(p,"England",7.5); // 简洁明了
p=lst.insert(p,make_pair("France",9.8)); // 辅助函数
p=lst.insert(p,pair<string,double>>{"Greece",3.14}); // 繁琐
}
forward_list 不提供诸如 insert() 之类的操作,这些操作在迭代器标识的元素之前执行。此类操作无法实现,因为没有通用的方法在仅给定迭代器的情况下查找 forward_list 中的前一个元素。相反,forward_iterator 提供了诸如 insert_after() 之类的操作,这些操作在迭代器标识的元素之后执行。同样,无序容器使用 emplace_hint() 来提供提示,而不是使用“普通”的 emplace()。
31.3.8 其它操作(Other Operations)
容器可以比较和交换:
| 比较和交换 | |
| c1==c2 | c1 和 c2 的所有对应元素是否相等? |
| c1!=c2 | !(c1==c2) |
| c1<c2 | 按字典顺序,c1 是否在 c2 之前? |
| c1<=c2 | !(c2<c1) |
| c1>c2 | c2<c1 |
| c1>=c2 | !(c1<c2) |
| c1.swap(c2) | 交换c1和c2的值;noexcept |
| swap(c1,c2) | c1.swap(c2) |
当使用运算符(例如 <= )比较容器时,将使用由 == 或 < 生成的等效元素运算符来比较元素(例如,a>b 使用 !(b<a) 来比较)。
swap() 操作交换元素和分配器。
31.4 几个容器(Containers)
本节将更详细地介绍以下内容:
• vector,默认容器 (§31.4.1)
• 链表:list 和 forward_list (§31.4.2)
• 关联容器,例如 map 和 unordered_map (§31.4.3)
31.4.1 vector
STL 的 vector 是默认容器。除非有充分的理由,否则最好使用它。如果你建议的替代方案是链表或内置数组,请三思。
§31.3 描述了 vector 的操作,并隐式地将它们与其他容器的操作进行了对比。然而,鉴于 vector的重要性,本节将重新审视这些操作,并更加强调其实现方式。
vector的模板参数和成员类型定义如下:
template<typename T, typename Allocator = allocator<T>>
class vector {
public:
using reference = value_type&;
using const_reference = const value_type&;
using iterator = /* implementation-defined */;
using const_iterator = /* implementation-defined */;
using size_type = /* implementation-defined */;
using difference_type = /* implementation-defined */;
using value_type = T;
using allocator_type = Allocator;
using pointer = typename allocator_traits<Allocator>::pointer;
using const_pointer = typename allocator_traits<Allocator>::const_pointer;
using reverse_iterator = std::reverse_iterator<iterator>;
using const_reverse_iterator = std::reverse_iterator<const_iterator>;
// ...
};
31.4.1.1 vector及其增长(vector and Growth)
考虑vector对象的布局(如§13.6 中所述):
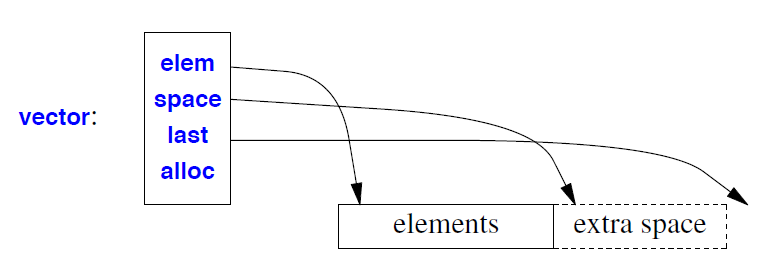
同时使用大小(元素数量)和容量(无需重新分配的可用元素槽位数量)使得通过 push_back() 进行增长操作更加高效:每次添加元素时都不会进行分配操作,只有超出容量(§13.6)时才会进行分配。标准并未规定超出容量时应增加多少,但通常会增加一半的大小。我以前在读取向量时会谨慎使用 reserve()。结果却惊讶地发现,在我几乎所有的应用中,调用 reserve() 都不会显著影响性能。默认的增长策略与我的预期一样有效,因此我不再尝试使用 reserve() 来提升性能。相反,我使用它来提高重新分配延迟的可预测性,并防止指针和迭代器失效。
容量的概念允许迭代器在vector中有效,除非实际发生重新分配。考虑将字母读入缓冲区并跟踪单词的(word)边界:
vector<char> chars; // 输入字符的缓冲区 "buffer"
constexpr int max = 20000;
chars.reser ve(max);
vector<char∗> words; //指向字符的起点
bool in_word = false;
for (char c; cin.get(c)) {
if (isalpha(c)) {
if (!in_word) { // 发现字符头
in_word = true;
chars.push_back(0); //前一个字条的尾
chars.push_back(c);
words.push_back(&chars.back());
}
else
chars.push_back(c);
}
else
in_word = false;
}
if (in_word)
chars.push_back(0); // 终止最后一个字符
if (max<chars.siz e()) { // oops: chars grew beyond capacity; the words are invalid
// ...
}
chars.shrink_to_fit(); // 释放过剩容量
如果我在这里没有使用 reserve(),那么当 chars.push_back() 导致重定位时,words 中的指针就会失效。“失效”是指,任何使用这些指针的行为都将是未定义的行为。它们可能指向某个元素,也可能不指向,但几乎肯定不会指向重定位之前它们指向的元素。
使用 push_back() 和相关操作来增大vector的能力意味着,使用低级 C 风格 malloc() 和 realloc() (§43.5) 是不必要的,因为它既繁琐又容易出错。
31.4.1.2 vector及其嵌入(vector and Nesting)
与其他数据结构相比,vector (以及类似的连续分配的数据结构)具有三大优点:
• vector的元素存储紧凑:每一个元素没有额外的内存开销。vector<X> 类型的vector占用的内存大约为sizeof(vector<X>)+vec.size()∗sizeof(X)。sizeof(vector<X>)大约为12个字节,对于较大的向量来说,这个大小可以忽略不计。
• vector的遍历速度非常快。为了获取下一个元素,代码无需通过指针间接访问,而且现代机器已经针对通过类似vector的结构进行连续访问进行了优化。这使得对vector元素进行线性扫描(例如 find() 和 copy())接近最优。
• vector支持简单高效的随机访问。许多算法都支持基于vector的这种访问方式。例如sort()和binary_search(),效率很高。
人们很容易低估这些好处。例如,双向链表(例如 list)通常会产生每个元素四个字的内存开销(两个链接加上一个空闲存储分配头),而且遍历它的开销很容易比遍历包含等效数据的vector高出一个数量级。其效果可能非常惊人,我建议您亲自测试一下 [Stroustrup,2012a]。
紧凑性和访问效率的优势可能会在无意中受到损害。考虑如何表示二维矩阵。有两种明显的替代方案:
• vector的vector:vector<vector<double>>,可通过 C 语言风格的 double 下标访问:m[i][j] 。
• 一种特定的矩阵类型,Matrix<2,double>(第 29 章),它连续存储元素(例如,在 vector<double> 中),并根据一对索引计算该vector中的位置:m(i,j) 。
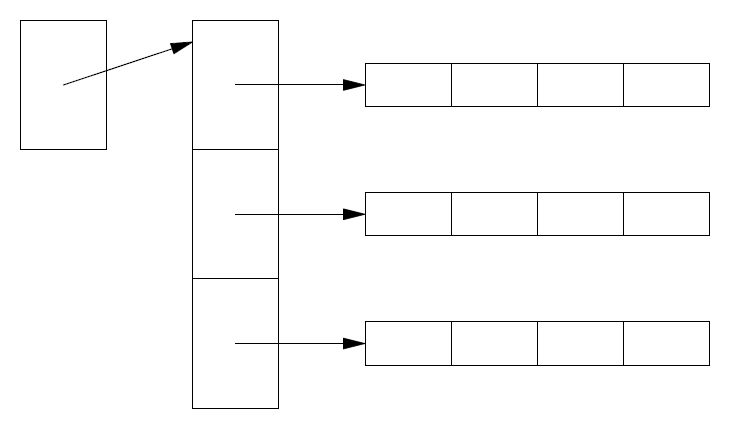
一个 3×4 的 vector<vector<double>> 的内存布局如下所示:
Matrix<2,double> 的内存布局如下所示:

要构造一个 vector<vector<double>> ,我们需要调用四次构造函数,并进行四次空闲存储分配操作。要访问元素,我们需要进行双重间接寻址。
要构造 Matrix<2,double>,我们需要调用一次构造函数并分配一次空闲存储空间。要访问元素,我们只需要一次间接寻址。
一旦到达某一行的某个元素,就无需进一步间接访问其后继元素,因此访问vector<vector<double>> 的成本并不总是访问Matrix<2,double> 的两倍。然而,对于要求高性能的算法来说,vector<vector<double>> 这种链接结构所隐含的分配、释放和访问成本可能会成为一个问题。
vector<vector<double>> 解决方案意味着行可能具有不同的大小。在某些情况下,这是一个优势,但更多时候,它只是一个容易出错的机会,并且会给测试带来负担。
当我们需要更高维度时,问题和开销会变得更糟:比较一下vector<vector<vector<double>>> 和 Matrix<3,double> 所增加的间接寻址和分配的数量。
总而言之,我注意到数据结构的紧凑性的重要性经常被低估或妥协。其优势不仅体现在逻辑上,也体现在性能上。再加上过度使用指针和 new 的趋势,我们面临着一个普遍存在的问题。例如,考虑一下在二维结构实现中,当行在空闲存储空间中实现为独立对象时,开发复杂性、运行时成本、内存成本以及出错的可能性:vector<vector<double>∗> 。
31.4.1.3 vector和array(vector and Arrays)
vector是一个资源句柄。这使得它能够调整大小并实现高效的移动语义。然而,与不依赖于将元素与句柄分开存储的数据结构(例如内置数组和array)相比,这有时会使其处于劣势。将元素序列保存在栈或其他对象中可以带来性能优势,但也可能带来劣势。
vector处理的是已正确初始化的对象。这使得我们可以简单地使用它们,并依赖于元素的正确销毁。然而,与允许未初始化元素的数据结构(例如内置数组和array)相比,这有时会使其处于劣势。
例如,我们不需要先初始化数组元素,然后再读取它们:
void read()
{
array<int,MAX]> a;
for (auto& x : a)
cin.get(&x);
}
对于vector,我们可以使用 emplace_back() 来实现类似的效果(而不必指定 MAX)(译注:超过已分配的容量后会自动增长空间,且采用移动方式)。
31.4.1.4 vector和string (vector and string)
vector<char> 是一个可调整大小的连续字符序列,string也是如此。那么,我们该如何在两者之间做出选择呢?
vector是一种通用的值存储机制。它不对存储在其中的值之间的关系做任何假设。对于vector<char> 来说,字符串 “Hello,World!” 仅仅是 13 个 char 类型元素的序列。将它们排序为 “!,HWdellloor”(前面加一个空格)是合理的。相比之下,string旨在存储字符序列。字符之间的关系一般认为很重要。因此,例如,我们很少对string中的字符进行排序,因为这会破坏字符串的意义。一些string操作反映了这一点(例如,c_str(),>> 和 find()“知道”C 风格的字符串是以0结尾的)。string的实现反映了我们对使用字符串方式的假设。例如,如果不是因为我们使用了许多短字符串,那么短字符串优化(§19.3.3)将是一种纯粹的悲观主义,因此最小化空闲存储空间的使用变得值得。
是否应该进行“短vector优化”?我怀疑不应该,但这需要大量的实证研究才能确定。
31.4.2 链表(Lists)
STL 提供两种链表类型:
• list:双向链表
• forward_list:单向链表
list是针对元素的插入和删除进行了优化的序列。当你向列表中插入或从列表中删除一个元素时,列表中其他元素的位置不会受到影响。特别是,引用其他元素的迭代器不会受到影响。
与vector相比,下标操作可能非常慢,因此list不提供下标操作。如有必要,请使用 advance() 和类似的操作来浏览list (§33.1.4)。可以使用迭代器遍历list:list 提供双向迭代器(§33.1.2),forward_list 提供前向迭代器(因此得名)。
在默认情况下,list元素在内存中单独分配,并包含前向指针和后继指针(§11.2.2)。与vector相比,list每一个元素占用的内存更多(通常每个元素至少多四个字),并且遍历(迭代)速度明显较慢,因为它们涉及通过指针进行间接访问,而不是简单的连续访问。
forward_list 是一个单向链表。可以将其视为一种针对空列表或非常短的列表进行优化的数据结构,通常需要从头开始遍历。为了保持紧凑性,forward_list 甚至没有提供 size();空的 forward_list 只占用一个字的内存。如果您需要知道 forward_list 中元素的数量,只需计算它们即可。如果元素数量太多,计算起来非常昂贵,那么您可能需要使用其他容器。
除了下标,容量管理和 forward_list 的 size() 函数之外,STL 链表提供了由vector (§31.4) 提供的成员类型和操作。此外,list 和 forward_list 还提供了特定的列表成员函数:
| list<T> 和 forward_list<T>的操作 (§iso.23.3.4.5, §iso.23.3.5.4) | |
| lst.push_front(x) | 将 x 添加到 lst 的第一个元素之前(使用复制或移动) |
| lst.pop_front() | 从 lst 中删除第一个元素 |
| lst.emplace_front(args) | 将 T{args} 添加到 lst 的第一个元素之前 |
| lst.remove(v) | 删除 lst 中所有值为 v 的元素 |
| lst.remove_if(f) | 删除 lst 中所有满足 f(x)==true 的元素 |
| lst.unique() | 删除 lst 的相邻重复元素 |
| lst.unique(f) | 使用 f 判断相等性,删除 lst 的相邻重复元素 |
| lst.merge(lst2) | 使用 < 作为顺序合并有序列表 lst 和 lst2; |
| lst.merge(lst2,f) | 以 f 为顺序合并有序列表 lst 和 lst2;lst2 被合并到 lst 中,并在此过程中被清空lst2 。 |
| lst.sort() | 使用 < 作为顺序对 lst 进行排序 |
| lst.sort(f) | 使用 f 作为顺序对 lst 进行排序 |
| lst.reverse() | 反转 lst 元素的顺序;noexcept |
与通用的 remove() 和 unique() 算法(见 32.5 节)不同,成员算法确实会影响列表的大小。例如:
void use()
{
list<int> lst {2,3,2,3,5};
lst.remove(3); //lst is now {2,2,5}
lst.unique(); //lst is now {2,5}
cout << lst.size() << '\n'; // writes 2
}
merge() 算法是稳定的;也就是说,等效元素保持其相对顺序。
| list<T> 的操作 (§iso.23.3.5.5) p 指向 lst 或 lst.end() 的一个元素 | |
| lst.splice(p,lst2) | 在 p 之前插入 lst2 的元素;lst2 变为空 |
| lst.splice(p,lst2,p2) | 将 p2 指向的元素插入到 lst2 中的 p 之前; 将 p2 指向的元素从 lst2 中移除 |
| lst.splice(p,lst2,b,e) | 将元素 [b:e) 从 lst2 插入到 p 之前; 元素 [b:e) 从 lst2 中移除 |
splice() 操作不会复制元素值,也不会使元素的迭代器失效。例如:
list<int> lst1 {1,2,3};
list<int> lst2 {5,6,7};
auto p = lst1.begin();
++p; //p 指向 2
auto q = lst2.begin();
++q; //q 指向 6
lst1.splice(p,lst2); // lst1现在是 {1,5,6,7,2,3}; lst2现在是 {}
// p 仍指向 2而 q 仍指向 6
forward_list 无法访问迭代器指向的元素之前的元素(它没有前向链接),因此其 emplace(),insert(),erase() 和 splice() 操作均作用于迭代器之后的位置:
| forward_list<T> 的操作 (§iso.23.3.4.6) | |
| p2=lst.emplace_after(p,args) | 将由 args 构造的元素放置在 p 之后; p2 指向新元素 |
| p2=lst.insert_after(p,x) | 在 p 后插入 x;p2 指向新元素 |
| p2=lst.insert_after(p,n,x) | 在 p 后插入 n 个 x 的副本; p2 指向最后一个新元素 |
| p2=lst.insert_after(p,b,e) | p2 指向最后一个新元素 |
| p2=lst.insert_after(p,{elem}) | 在 p 后插入 [b:e); p2 指向最后一个新元素 |
| p2=lst.erase_after(p) | 在 p 后插入 {element}; |
| p2=lst.erase_after(b,e) | p2 指向最后一个新元素; elem 是一个初始化列表 |
| lst.splice_after(p,lst2) | 删除 p 之后的元素; p2 指向 p 之后的元素或 lst.end() p2=lst.erase_after(b,e) 删除 [b:e); p2=e |
| lst.splice_after(p,b,e) | 在 p 之后拼接 [b:e) |
| lst.splice_after(p,lst2,p2) | 在 p 之后拼接到 p2;从 lst2 中删除 p2 |
| lst.splice_after(p,lst2,b,e) | 在 p 之后拼接 [b:e);从 lst2 中删除 [b:e) |
这些列表操作都是稳定的;也就是说,它们保留了具有相同值的元素的相对顺序。
31.4.3 关联容器(Associative Containers)
关联容器提供基于键的查找。它们有两种变体:
• 有序关联容器基于排序标准进行查找,默认情况下为 <(小于)。它们实现为平衡二叉树,通常是红黑树。
• 无序关联容器基于哈希函数进行查找。它们实现为带有链接溢出的哈希表。
二者均以以下形式出现:
• map:{键,值} 对的序列
• set:不包含值的map(或者也可以说键即值)
最后,无论是有序的还是无序的,map和set都有两种变体:
• “单(Plain)”set或map,每个键都有一个唯一的条目
• “多(Multi)” set或map,每个键可以有多个条目
关联容器的名称表明了它在这个三维空间中的位置:{set|map, plain|unordered, plain|multi}。“Plain”这个名称从不拼写出来,因此关联容器如下:

它们的模板参数在§31.4 中描述。
从内部来看,map 和 unordered_map 有很大不同。有关图形表示,请参阅 §31.2.1。具体来说,map 使用键的比较条件(通常为 < ) 来搜索平衡树(O(log(n)) 运算),而 unordered_map 则对键应用哈希函数来在哈希表中查找位置(对于好的哈希函数,O(1) 运算)。
31.4.3.1 有序关联容器(Ordered Associative Containers)
以下是 map的模板参数和成员类型:
template<typename Key,
typename T,
typename Compare = less<Key>,
typename Allocator = allocator<pair<const Key, T>>>
class map {
public:
using key_type = Key;
using mapped_type = T;
using value_type = pair<const Key, T>;
using key_compare = Compare;
using allocator_type = Allocator;
using reference = value_type&;
using const_reference = const value_type&;
using iterator = /* implementation-defined */ ;
using const_iterator = /* implementation-defined */ ;
using size_type = /* implementation-defined */ ;
using difference_type = /* implementation-defined */ ;
using pointer = typename allocator_traits<Allocator>::pointer;
using const_pointer = typename allocator_traits<Allocator>::const_pointer;
using reverse_iterator = std::reverse_iterator<iterator>;
using const_reverse_iterator = std::reverse_iterator<const_iterator>;
class value_compare { /* operator()(k1,k2) does a key_compare()(k1,k2) */ };
// ...
};
除了§31.3.2中提到的构造函数外,关联容器还具有允许程序员提供比较器的构造函数:
| map<K,T,C,A> 的构造函数 (§iso.23.4.4.2) | |
| map m {cmp,a}; | 构造 m 以使用比较器 cmp 和分配器 a;显式 |
| map m {cmp}; | map m {cmp, A{}}; 显式 |
| map m {}; | map m {C{}}; 显式 |
| map m {b,e,cmp,a}; | 构造 m 以使用比较器 cmp 和分配器 a; 使用 [b:e) 中的元素进行初始化 |
| map m {b,e,cmp}; | map m {b,e ,cmp, A{}}; |
| map m {b,e}; | map m {b,e,C{}}; |
| map m {m2}; | 复制和移动构造函数 |
| map m {a}; | 构造默认 map ,使用分配器 a ;显式 |
| map m {m2,a}; | 从 m2 复制或移动构造 m;使用分配器 a |
| map m {{elem},cmp,a}; | 构造 m 以使用比较器 cmp 和分配器 a; 使用来自初始化列表 {elem} 的元素进行初始化 |
| map m {{elem},cmp}; | map m {{elem},cmp,A{}}; |
| map m {{elem}}; | map m {{elem},C{}}; |
例如:
map<string,pair<Coordinate ,Coordinate>> locations
{
{"Copenhagen",{"55:40N","12:34E"}},
{"Rome",{"41:54N","12:30E"}},
{"New York",{"40:40N","73:56W"}
};
关联容器提供各种插入和查找操作:
| 关联容器操作 (§iso.23.4.4.1) | |
| v=c[k] | v 是对键为 k 的元素的引用; 如果未找到 k,则将 {k,mapped_type{}} 插入到 c 中; 仅适用于 map 和 unordered_map |
| v=c.at(k) | v 是对键为 k 的元素的引用; 如果未找到 k,则抛出 out_of_range 异常; 仅适用于 map 和 unordered_map |
| p=c.find(k) | p指向键为 k 的第一个元素或 c.end(); |
| p=c.lower_bound(k) | p 指向键 >=k 的第一个元素或 c.end(); 仅适用于有序容器 |
| p=c.upper_bound(k) | p 指向键 >k 或 c.end() 的第一个元素; 仅限有序容器 |
| pair(p1,p2)=c.equal_range(k) | p1=c.lower_bound(k); p2=c.upper_bound(k) |
| pair(p,b)=c.insert(x) | x 是 value_type 或可以复制的内容到 value_type 中(例如,一个二元素元组); 如果 x 被插入,则 b 为 true;如果已经存在一个包含 x 键的条目,则 b 为 false; p 指向包含 x 键的(可能是新的)元素 |
| p2=c.insert(p,x) | x 是 value_type 或可以复制的内容(例如,一个二元素元组); p 指示从哪里开始查找 x 的键对应的元素; p2 指向 x 的键对应的元素(可能是新的元素) |
| c.insert(b,e) | c.对 [b:e) 中的每个 p 插入 t(∗p) |
| c.insert({args}) | 插入初始化列表参数中的每个元素;元素的类型为 pair<key_type ,mapped_type> |
| p=c.emplace(args) | p指向一个 c 的 value_type 对象,该对象由 args 构造并插入到 c 中 |
| p=c.emplace_hint(h,args) | p 指向一个 c 的 value_type 对象,该对象由 args 构造并插入到 c 中; h 是 c 中的一个迭代器,可能用作提示从哪里开始搜索新条目的位置 |
| r=c.key_comp() | r 是键比较对象的副本;仅适用于有序容器 |
| r=c.value_comp() | r 是值比较对象的副本;仅适用于有序容器 |
| n=c.count(k) | n 是具有键 k 的元素的数量 |
无序容器的特定操作在§31.4.3.5 中介绍。
如果通过下标操作 m[k] 找不到键 k,则插入默认值。例如:
map<string,string> dictionary;
dictionary["sea"]="large body of water"; // 插入或赋予一个元素
cout << dictionary["seal"]; // read value
如果字典中没有 seal,则不打印任何内容:输入空字符串作为 seal 的值,并作为查找结果返回。
如果这不是所需的行为,我们可以直接使用 find() 和 insert() :
auto q = dictionary.find("seal"); // 查询; 不插入
if (q==dictionary.end()) {
cout << "entry not found";
dictionary.inser t(make_pair("seal","eats fish"));
}
else
cout q−>second;
实际上,[] 只不过是insert() 的一个便捷表示法。m[k] 的结果等价于 (∗(m.insert(make_pair(k,V{})).first)).second 的结果,其中 V 是map类型。
insert(make_pair()) 的写法比较冗长。我们可以使用 emplace() 来代替:
dictionary.emplace("sea cow","extinct");
根据优化器的质量,这也可能会更有效。
如果你尝试将一个值插入到map中,并且已经有一个与其键对应的元素,则map不会发生任何变化。如果你想为单个键设置多个值,请使用multimap。
equal_range() 返回的迭代器对(§34.2.4.1)中的第一个迭代器是 lower_bound(),第二个迭代器是 upper_bound()。您可以像这样在 multimap<string,int> 中打印所有键为“apple”的元素的值:
multimap<string,int> mm {{"apple",2}, { "pear",2}, {"apple",7}, {"orange",2}, {"apple",9}};
const string k {"apple"};
auto pp = mm.equal_range(k);
if (pp.first==pp.second)
cout << "no element with value '" << k << "'\n";
else {
cout << "elements with value '" << k << "':\n";
for (auto p=pp.first; p!=pp.second; ++p)
cout << p−>second << ' ';
}
打印 2 7 9 。
我也可以这样写:
auto pp = make_pair(m.lower_bound(),m.upper_bound());
// ...
然而,这意味着需要额外遍历 map。equal_range(),lower_bound() 和 upper_bound() 函数也适用于已排序的序列(§32.6)。
我倾向于将set视为没有单独 value_type 的map。对于set而言,value_type 也是 key_type 。考虑一下:
struct Record {
string label;
int value;
};
要获得 set<Record> ,我们需要提供一个比较函数。例如:
bool operator<(const Record& a, const Record& b)
{
return a.label<b.label;
}
鉴于此,我们可以写出:
set<Record> mr {{"duck",10}, {"pork",12}};
void read_test()
{
for (auto& r : mr) {
cout << '{' << r.label << ':' << r.value << '}';
}
cout << endl;
}
关联容器中元素的键是不可变的(§iso.23.2.4)。因此,我们无法更改set的值。我们甚至无法更改不参与比较的元素的成员。例如:
void modify_test()
{
for (auto& r : mr)
++r.value; // 错误 : set 元素不可变
}
如果需要修改元素,请使用 map。不要尝试修改键:如果修改成功,底层查找元素的机制就会崩溃。
31.4.3.2 无序关联容器(Unordered Associative Containers)
无序关联容器(unordered_map , unordered_set , unordered_multimap, unordered_multiset ) 都是哈希表。对于简单的用途,它们与(有序)容器几乎没有区别,因为关联容器共享大多数操作(§31.4.3.1)。例如:
unordered_map<string,int> score1 {
{"andy", 7}, {"al",9}, {"bill",−3}, {"barbara",12}
};
map<string,int> score2 {
{"andy", 7}, {"al",9}, {"bill",−3}, {"barbara",12}
};
template<typename X, typename Y>
ostream& operator<<(ostream& os, pair<X,Y>& p)
{
return os << '{' << p.first << ',' << p.second << '}';
}
void user()
{
cout <<"unordered: ";
for (const auto& x : score1)
cout << x << ", ";
cout << "\nordered: ";
for (const auto& x : score2)
cout << x << ", ";
}
明显的区别是,通过 map 进行迭代是有序的,而对于 unordered_map 则不是:
unordered: {andy,7}, {al,9}, {bill,−3}, {barbara,12},
ordered: {al,9}, {andy, 7}, {barbara,12}, {bill,−3},
unordered_map 的迭代取决于插入顺序、哈希函数和负载因子。具体来说,无法保证元素按插入顺序打印。
31.4.3.3 构造unordered_map (Constructing unordered_maps)
unordered_map 有很多模板参数和成员类型别名需要匹配:
template<typename Key,
typename T,
typename Hash = hash<Key>,
typename Pred = std::equal_to<Key>,
typename Allocator = std::allocator<std::pair<const Key, T>>>
class unordered_map {
public:
using key_type = Key;
using value_type = std::pair<const Key, T>;
using mapped_type = T;
using hasher = Hash;
using key_equal = Pred;
using allocator_type = Allocator;
using pointer = typename allocator_traits<Allocator>::pointer;
using const_pointer= typename allocator_traits<Allocator>::const_pointer;
using reference = value_type&;
using const_reference = const value_type&
using size_type = /* implementation-defined */;
using difference_type = /* implementation-defined */;
using iterator = /* implementation-defined */;
using const_iterator = /* implementation-defined */;
using local_iterator = /* implementation-defined */;
using const_local_iterator = /* implementation-defined */;
// ...
};
在默认情况下,unordered_map<X> 使用 hash<X> 进行散列,并使用 equal_to<X> 来比较键。
默认的 equal_to<X> (§33.4) 只是使用 == 比较 X 值。
通用(主)模板哈希没有定义。如果需要,X 类型的用户需要自行定义 hash<X>。对于常见类型(例如字符串),已提供标准哈希特化,因此用户无需提供(译注:下面是具有hash<X>的类型):

哈希函数(例如,针对类型 T 的哈希特化或指向函数的指针)必须能够以类型 T 的参数调用,并返回一个 size_t 类型的值(§iso.17.6.3.4)。对同一值两次调用哈希函数必须得出相同的结果,并且理想情况下,这些结果均匀分布在 size_t 类型的值集合上,以最大限度地减少当 x!=y 时 h(x)==h(y) 的可能性。
对于无序容器来说,模板参数类型、构造函数和默认值的组合可能会让人眼花缭乱。幸运的是,有一个模式:
| unordered_map<K,T,H,E,A> 的构造函数(§iso.23.5.4) | |
| unordered_map m {n,hf,eql,a}; | 构造 m,其中包含 n 个桶, 哈希函数 hf,相等函数 eql, 以及分配器 a;显式 |
| unordered_map m {n,hf,eql}; | unordered_map m{n,hf,eql,allocator_type{}};显式 |
| unordered_map m {n,hf}; | unordered_map m {n,hf,key_eql{}};显式 |
| unordered_map m {n}; | unordered_map m {n,hasher{}};显式 |
| unordered_map m {}; | unordered_map m {N};桶的数量N由定义实现;显式 |
这里,n 是空的 unordered_map 的元素计数。
| unordered_map<K,T,H,E,A> 的构造函数(§iso.23.5.4) | |
| unordered_map m {b,e,n,hf,eql,a}; | 使用哈希函数 hf,相等函数 eql 和分配器 a,构造具有 n 个存储桶的 m,这些存储桶来自 [b:e) 的元素; |
| unordered_map m {b,e,n,hf,eql}; | unordered_map m {b,e,n,hf,eql,allocator_type{}}; |
| unordered_map m {b,e,n,hf}; | unordered_map m {b,e,n,hf,key_equal{}}; |
| unordered_map m {b,e,n}; | unordered_map m {b,e,n,hasher{}}; |
| unordered_map m {b,e}; | unordered_map m {b,e,N};桶的数量N由定义实现 |
这里,我们从序列 [b:e] 中获取初始元素。元素的数量将是 [b:e] 中元素的数量,即距离 (b,e)。
| unordered_map<K,T,H,E,A> 的构造函数(§iso.23.5.4) | |
| unordered_map m {{elem},n,hf,eql,a}; | 使用 n 个桶,哈希函数 hf,相等函数 eql 和分配器 a,从初始化列表的元素构造 m |
| unordered_map m {{elem},n,hf,eql}; | unordered_map m {{elem},n,hf,eql,allocator_type{}}; |
| unordered_map m {{elem},n,hf}; | unordered_map m {{elem},n,hf,key_equal{}}; |
| unordered_map m {{elem},n,hf}; | unordered_map m {{elem},n,hasher{}}; |
| unordered_map m {{elem},n,hf}; | unordered_map m {{elem},N};桶的数量N由定义实现 |
这里,我们从以 {} 分隔的初始化元素列表中获取序列的初始元素。unordered_map 中的元素数量将是初始化列表中元素的数量。
最后,unordered_map 具有复制和移动构造函数,以及提供分配器的等效构造函数:
| unordered_map<K,T,H,E,A> 的构造函数(§iso.23.5.4) | |
| unordered_map m {m2}; | 使用哈希函数 hf,相等函数 eql 和分配器 a,构造具有 n 个存储桶的 m,这些存储桶来自 [b:e) 的元素; |
| unordered_map m {a}; | 复制并移动构造函数:从 m2 构造 m |
| unordered_map m {m2,a}; | 默认构造 m 并赋予其分配器 a;显式 |
构造包含一个或两个参数的 unordered_map 时要小心。类型组合可能有很多种,错误可能会导致奇怪的错误消息。例如:
map<string,int> m {My_comparator}; // OK
unordered_map<string,int> um {My_hasher}; // error
单个构造函数参数必须是另一个 unordered_map(用于复制或移动构造函数)、桶计数或分配器。请尝试以下代码:
unordered_map<string,int> um {100,My_hasher}; // OK
31.4.3.4 哈希和相等函数 (Hash and Equality Functions)
当然,用户可以定义哈希函数。事实上,有几种方法可以实现这一点。不同的技术可以满足不同的需求。这里,我介绍了几个版本,从最明确的开始,到最简单的结束。考虑一个简单的Record类型:
struct Record {
string name;
int val;
};
我可以像这样定义Record哈希和相等操作:
struct Nocase_hash {
int d = 1; // 每次迭代的移位码 d 位数
size_t operator()(const Record& r) const
{
size_t h = 0;
for (auto x : r.name) {
h <<= d;
h ˆ= toupper(x);
}
return h;
}
};
struct Nocase_equal {
bool operator()(const Record& r,const Record& r2) const
{
if (r.name .size()!=r2.name .size()) return false;
for (int i = 0; i<r.name .size(); ++i)
if (toupper(r.name[i])!=toupper(r2.name[i]))
return false;
return true;
}
};
鉴于此,我可以定义并使用Record的unordered_set:
unordered_set<Record,Nocase_hash,Nocase_equal> m {
{ {"andy", 7}, {"al",9}, {"bill",−3}, {"barbara",12} },
Nocase_hash{2},
Nocase_equal{}
};
for (auto r : m)
cout << "{" << r.name << ',' << r.val << "}\n";
如果我想使用哈希函数和相等函数的默认值(这很常见),只需不将它们作为构造函数参数即可。默认情况下,unordered_set 使用默认版本:
unordered_set<Record,Nocase_hash,Nocase_equal> m {
{"andy", 7}, {"al",9}, {"bill",−3}, {"barbara",12}
// use Nocase_hash{} and Nocase_equal{}
};
通常,编写哈希函数最简单的方法是使用标准库中作为hash规范提供的哈希函数(参见 §31.4.3.2)。例如:
size_t hf(const Record& r) { return hash<string>()(r.name)ˆhash<int>()(r.val); };
bool eq (const Record& r, const Record& r2) { return r.name==r2.name && r.val==r2.val; };
使用排它OR(ˆ) 合并哈希值可保留它们在 size_t 类型值集合上的分布(§3.4.5,§10.3.1)。
已知这个哈希函数和相等函数,我们可以定义一个 unordered_set:
unordered_set<Record,decltype(&hf),decltype(&eq)> m {
{ {"andy", 7}, {"al",9}, {"bill",−3}, {"barbara",12} },
hf,
eq
};
for (auto r : m)
cout << "{" << r.name << ',' << r.val << "}\n";
我使用 decltype 来避免必须明确重复 hf 和 eq 的类型。
如果我们手边没有初始化列表,我们可以给出一个初始大小:
unordered_set<Record,decltype(&hf),decltype(&eq)> m {10,hf,eq};
这也使得我们更容易关注哈希和相等操作。
如果我们想避免将 hf 和 eq 的定义与它们的使用点分开,我们可以尝试 lambda:
unordered_set<Record, //value type
function<size_t(const Record&)>, //hash type
function<bool(const Record&,const Record&)> // equal type
> m { 10,
[](const Record& r) { return hash<string>{}(r.name)ˆhash<int>{}(r.val); },
[](const Record& r, const Record& r2) { return r.name==r2.name && r.val==r2.val; }
};
使用(命名或未命名的)lambda 表达式代替函数的优点在于,它们可以在函数内部局部定义,紧邻它们的使用。
然而,如果 unordered_set 被频繁使用,函数可能会产生开销,我更倾向于避免这种情况。另外,我认为这个版本比较混乱,所以我更喜欢将 lambda 表达式命名为:
auto hf = [](const Record& r) { return hash<string>()(r.name)ˆhash<int>()(r.val); };
auto eq = [](const Record& r, const Record& r2) { return r.name==r2.name && r.val==r2.val; };
unordered_set<Record,decltype(hf),decltype(eq)> m {10,hf,eq};
最后,我们可能更倾向于通过特化 unordered_map 使用的标准库 hash 和 equal_to 模板,为所有 Record 无序容器一次性定义 hash 和相等性的含义:
namespace std {
template<>
struct hash<Record>{
size_t operator()(const Record &r) const
{
return hash<string>{}(r.name)ˆhash<int>{}(r.val);
}
};
template<>
struct equal_to<Record> {
bool operator()(const Record& r, const Record& r2) const
{
return r.name==r2.name && r.val==r2.val;
}
};
}
unordered_set<Record> m1;
unordered_set<Record> m2;
默认hash值以及通过异或运算得到的哈希值通常都相当不错。不要在没有进行实验的情况下就贸然使用自制哈希函数。
31.4.3.5 装载和桶(Load and Buckets)
无序容器实现的大部分内容对程序员可见。具有相同哈希值的键称为“位于同一个桶中”(参见§31.2.1)。程序员可以检查并设置哈希表的大小(称为“桶的数量”):
| 哈希策略(§iso.23.2.5) | |
| h=c.hash_function() | h 是 c 的哈希函数 |
| eq=c.key_eq() | eq 是 c 的相等性测试 |
| d=c.load_factor() | d 是元素数量除以桶数量: double(c.size())/c.bucket_count(); 无异常 |
| d=c.max_load_factor() | d 是 c 的最大装载因子;无异常 |
| c.max_load_factor(d) | 将 c 的最大装载因子设置为 d;如果 c 的装载因子 接近其最大装载因子,c 将调整哈希表的大小 (增加桶的数量) |
| c.rehash(n) | 使 c 的桶数 >= n |
| c.reserve(n) | 为 n 个条目腾出空间(考虑负载因子):c.rehash(ceil(n/c.max_load_factor())) |
无序关联容器的负载因子仅仅是已使用容量的一小部分。例如,如果 capacity() 为 100 个元素,size() 为 30,则 load_factor() 为 0.3。
请注意,设置 max_load_factor,调用 rehash() 或调用 reserve() 可能是非常昂贵的操作(最坏情况为 O(n∗n)),因为它们可能导致(在实际场景中通常确实如此)所有元素重新哈希。这些函数用于确保在程序执行过程中相对方便的时间进行重新哈希。例如:
unordered_set<Record,[](const Record& r) { return hash(r.name); }> people;
// ...
constexpr int expected = 1000000; // 预期最大元素数
people.max_load_factor(0.7); // 至少 70% 满
people.reserve(expected); //约1,430,000 个桶
您需要进行实验来为给定的元素集和特定的哈希函数找到合适的装载因子,但 70%(0.7) 通常是一个不错的选择。
| 桶接口(§iso.23.2.5) | |
| n=c.bucket_count() | n 是 c 中的桶数量(哈希表的大小);无异常 |
| n=c.max_bucket_count() | n 是桶中元素的最大可能数量;无异常 |
| m=c.bucket_siz e(n) | m 是第 n 个桶中的元素数量 |
| i=c.bucket(k) | 具有键 k 的元素将位于第 i 个桶中 |
| p=c.begin(n) | p 指向第 n个桶中的第一个元素 |
| p=c.end(n) | p 指向第 n个桶中的最后一个元素的后一位置 |
| p=c.cbegin(n) | p 指向第 n个桶中的第一个元素,p 是 const 迭代器 |
| p =c.cend(n) | p 指向第 n个桶中的最后一个元素的后一位置p 是 const 迭代器 |
使用 c.max_bucket_count()<= n 的 n 作为桶的索引是未定义的(并且可能是灾难性的)。
桶接口的一个用途是允许对哈希函数进行实验:一个较差的哈希函数会导致某些键值的 bucket_count() 次数过大。也就是说,它会导致许多键映射到同一个哈希值。
31.5 容器适配器(Container Adaptors)
容器适配器为容器提供不同的(通常受限制的)接口。容器适配器只能通过其专用接口使用。具体来说,STL 容器适配器不提供对其底层容器的直接访问。它们不提供迭代器或下标操作。
用于从容器创建容器适配器的技术通常可用于非侵入式地调整类的接口以满足其用户的需求。
31.5.1 stack
栈容器适配器定义在头文件 <stack> 中。可以通过部分实现来对其描述:
template<typename T, typename C = deque<T>>
class stack { // §iso.23.6.5.2
public:
using value_type = typename C::value_type;
using reference = typename C::reference;
using const_reference = typename C::const_reference;
using size_type = typename C::size_type;
using container_type = C;
public:
explicit stack(const C&); // 从容器复制
explicit stack(C&& = C{}); // 从容器移动
// 默认复制,移动,赋值,析构
template<typename A>
explicit stack(const A& a); //默认容器,分配器 a
template<typename A>
stack(const C& c, const A& a); // 来自 c的元素, 分配器 a
template<typename A>
stack(C&&, const A&);
template<typename A>
stack(const stack&, const A&);
template<typename A>
stack(stack&&, const A&);
bool empty() const { return c.empty(); }
size_type siz e() const { return c.size(); }
reference top() { return c.back(); }
const_reference top() const { return c.back(); }
void push(const value_type& x) { c.push_back(x); }
void push(value_type&& x) { c.push_back(std::move(x)); }
void pop() { c.pop_back(); } // pop the last element
template<typename... Args>
void emplace(Args&&... args)
{
c.emplace_back(std::forward<Args>(args)...);
}
void swap(stack& s) noexcept(noexcept(swap(c, s.c)))
{
using std::swap; // 确定使用标准 swap()
swap(c,s.c);
}
protected:
C c;
};
也就是说,stack是作为模板参数传递给它的容器类型的接口。栈从接口中消除了对其容器的非栈操作,并提供了常规名称:top(),push() 和 pop()。
此外,stack 还提供常用的比较运算符(==、< 等)和非成员 swap()。
在默认情况下,stack会创建一个双端队列来保存其元素,但任何提供 back(),push_back() 和 pop_back() 的序列都可以使用。例如:
stack<char> s1; // 使用一个 deque<char>存储元素
stack<int,vector<int>> s2; // 使用一个 vector<int> 存储元素
通常,vector比双端队列更快并且占用更少的内存。
使用底层容器的 push_back() 将元素添加到stack中。因此,只要机器上有可供容器获取的内存,stack就不会“溢出”。在另一方面,stack可能会“下溢”:
void f()
{
stack<int> s;
s.push(2);
if (s.empty()) { // 下溢是可以预防的
// don’t pop
}
else { // 但不是不可能
s.pop(); // 良好: s.size() 变为0
s.pop(); // 未定义影响,可能是灾难性的
}
}
我们不会通过 pop() 来使用元素。相反,我们会访问 top() 元素,并在不再需要时 pop() 。这不会造成太大不便,在不需要 pop() 时效率更高,并且大大简化了异常保证的实现。例如:
void f(stack<char>& s)
{
if (s.top()=='c') s.pop(); // optionally remove optional initial ’c’
// ...
}
在默认情况下,stack依赖于其底层容器的分配器。如果这还不够,还有另外几个构造函数可以提供其他分配器。
31.5.2 queue
队列定义在头文件 <queue> 中,它是一个容器的接口,允许在 back() 处插入元素,在 front() 处提取元素:
template<typename T, typename C = deque<T> >
class queue { //§iso.23.6.3.1
// ... 似stack ...
void pop() { c.pop_front(); } // 弹出第一个元素
};
queue似乎在每个系统中都会出现。对于一个简单的基于消息的系统,我们可以像这样定义一个服务器:
void server(queue<Message>& q, mutex& m)
{
while (!q.empty()) {
Message mess;
{
lock_guard<mutex> lck(m); // 提取消息时锁定
if (q.empty()) return;
mess = q.front();
q.pop();
}
// serve request
}
}
31.5.3 prioriry_ queue
优先级队列 (priority_queue) 是一种队列,其中每个元素都被赋予一个优先级,该优先级决定了元素到达 top() 的顺序。priority_queue的声明与queue的声明非常相似,只是增加了一些用于处理比较对象的函数,以及几个用于从序列初始化的构造函数:
template<typename T, typename C = vector<T>, typename Cmp = less<typename C::value_type>>
class priority_queue { // §iso.23.6.4
protected:
C c;
Cmp comp;
public:
priority_queue(const Cmp& x, const C&);
explicit priority_queue(const Cmp& x = Cmp{}, C&& = C{});
template<typename In>
priority_queue(In b, In e, const Cmp& x, const C& c); // insert [b:e) into c
// ...
};
在 <queue> 中可以找到priority_queue的声明。
默认情况下,priority_queue 仅使用 < 运算符比较元素,top() 返回最大的元素:
struct Message {
int priority;
bool operator<(const Message& x) const { return priority < x.priority; }
// ...
};
void server(priority_queue<Message>& q, mutex& m)
{
while (!q.empty()) {
Message mess;
{ lock_guard<mutex> lck(m); // 提取消息时持有锁
if (q.empty()) return; //其他们获得了消息
mess = q.top();
q.pop();
}
//满足最高优先级请求
}
}
这与queue版本(§31.5.2)的不同之处在于,优先级较高的Message将优先处理。优先级相同的元素到达队列头部的顺序尚未定义。如果两个元素的优先级都不高于另一个,则认为它们具有相同的优先级(§31.2.2.1)。
保持元素有序并非毫无代价,但也未必代价高昂。实现priority_queue 的一个实用方法是使用树形结构来跟踪元素的相对位置。这使得 push() 和 pop() 的复杂度均为 O(log(n))。priority_queue几乎肯定是使用heap (§32.6.4) 实现的。
31.6 建议(Advice)
[1] STL 容器定义一个序列;§31.2。
[2] 使用vector作为默认容器;§31.2、§31.4。
[3] 插入运算符(例如 insert() 和 push_back())在vector上通常比在list上更高效;§31.2,§31.4.1.1。
[4] 对于通常为空的序列,请使用 forward_list;§31.2,§31.4.2。
[5] 谈到性能,不要相信你的直觉:测量;§31.3。
[6] 不要盲目相信渐近复杂度度量;有些序列很短,各个操作的成本可能差异很大;§31.3。
[7] STL 容器是资源句柄;§31.2.1。
[8] map通常实现为红黑树; §31.2.1,§31.4.3。
[9] unordered_map 是一个哈希表;§31.2.1,§31.4.3.2。
[10] 要成为 STL 容器的元素类型,该类型必须提供复制或移动操作;§31.2.2。
[11] 需要保留多态行为时,请使用指针容器或智能指针;§31.2.2。
[12] 比较操作应实现严格的弱顺序;§31.2.2.1。
[13] 通过引用传递容器,通过值返回容器;§31.3.2。
[14] 对于容器,使用 () 初始化语法来设置大小,使用 {} 初始化语法来设置元素列表;§31.3.2。
[15] 对于容器的简单遍历,请使用 范围for 循环或 begin/end 迭代器对;§31.3.4。
[16] 在不需要修改容器元素的情况下使用 const 迭代器;§31.3.4。
[17] 使用迭代器时,请使用 auto 以避免冗长和拼写错误;§31.3.4。
[18] 使用 reserve() 以避免使指向元素的指针和迭代器无效;§31.3.3,§31.4.1。
[19] 未经测量,请勿假设 reserve() 会带来性能提升;§31.3.3。
[20] 对容器使用 push_back() 或 resize(),而不是对数组使用 realloc();§31.3.3,§31.4.1.1。
[21] 不要在已调整大小的vector或deque中使用迭代器; §31.3.3.
[22] 必要时,使用 reserve() 使性能可预测;§31.3.3.
[23] 不要假设 [] 会进行范围检查;§31.2.2.
[24] 需要保证范围检查时,请使用 at();§31.2.2.
[25] 为了符号方便,请使用 emplace();§31.3.7.
[26] 优先使用紧凑且连续的数据结构;§31.4.1.2。
[27] 使用 emplace() 避免预先初始化元素;§31.4.1.3。
[28] list的遍历开销相对较大;§31.4.2。
[29] list表通常每个元素占用四个字的内存;§31.4.2。
[30] 有序容器的序列由其比较对象定义( 默认为 < );§31.4.3.1。
[31] 无序容器(散列容器)的序列无法预测顺序;§31.4.3.2。
[32] 如果需要快速查找大量数据,请使用无序容器;§31.3。
[33] 对于没有自然顺序的元素类型(例如,没有合理的 < ),请使用无序容器;§31.4.3。
[34] 如果需要按顺序迭代元素,请使用有序关联容器(例如,map 和 set);§31.4.3.2。
[35] 通过实验检查你是否有一个可接受的哈希函数;§31.4.3.4。
[36] 使用排它或(exclusive or)运算符组合元素的标准哈希函数获得的哈希函数通常效果很好;§31.4.3.4。
[37] 0.7 通常是一个合理的装载因子;§31.4.3.5。
[38] 您可以为容器提供替代接口;§31.5。
[39] STL 适配器不提供对其底层容器的直接访问;§31.5。
内容来源:
<<The C++ Programming Language >> 第4版,作者 Bjarne Stroustrup

















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









