







 本文介绍了深度可分离卷积及其到MobileNet_v1和MobileNet_v2的发展。深度可分离卷积分Depthwise和Pointwise两步。MobileNet_v1轻量化,用超参数控制计算速度与准确度平衡;MobileNetV2引入shortcut结构,先升维再进行DW卷积,pointwise后用linear激活函数。
本文介绍了深度可分离卷积及其到MobileNet_v1和MobileNet_v2的发展。深度可分离卷积分Depthwise和Pointwise两步。MobileNet_v1轻量化,用超参数控制计算速度与准确度平衡;MobileNetV2引入shortcut结构,先升维再进行DW卷积,pointwise后用linear激活函数。
深度可分离卷积 to MobileNet_v1 to MobileNet_v2
深度可分离卷积
卷积
要解释深度可分离卷积,就要从卷积过程开始说起,我们假设输入为 N x H x W x C 的特征向量,其中N为特征向量个数,H、W为特征图的长宽,C为特征向量的通道数,当我们用k个卷积核进行卷积操作时,如果设置步长为1,那么最后输出为N x H x W x K
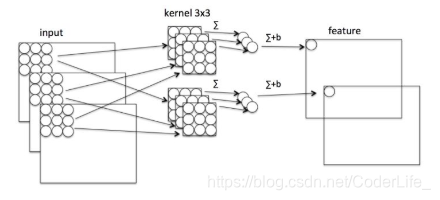
Depthwise
深度可分离卷积分为两个过程:
- Depthwise
- Pointwise
Depthwise作为可分离卷积第一步,主要是将特征图的通道分离开,来进行卷积操作,比如我们的输入数据维度为N x H x W x C,我们将数据分为C组,对每一组做3x3卷积,这样相当于搜集了每个通道的空间特征,即Depthwise特征
Pointwise
pointwise过程是对N x H x W x C 的输入上做k个普通的1x1卷积,相当于收集了每个点的特征,这样输出结果与直接对输入特征使用k个卷积核的结果相同
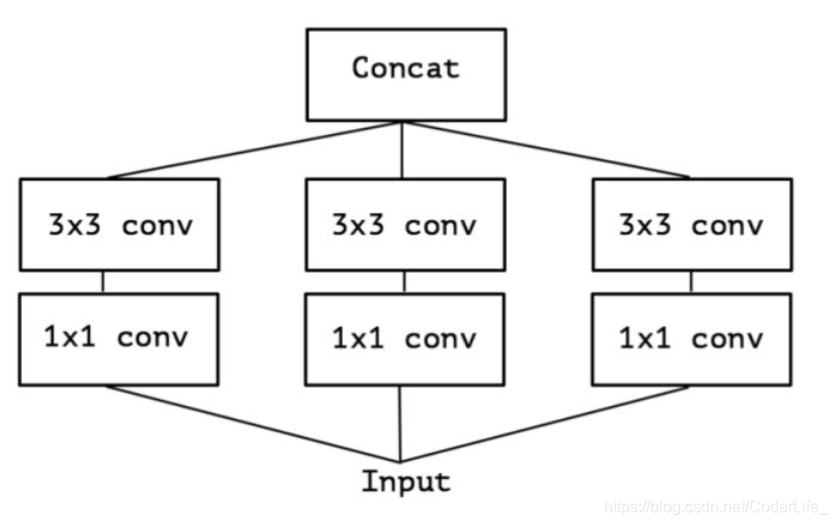
深度可分离卷积是Inception结构的极限版本,模型在低纬度嵌入上进行空间聚合,不会损失或损失太多的体现能力
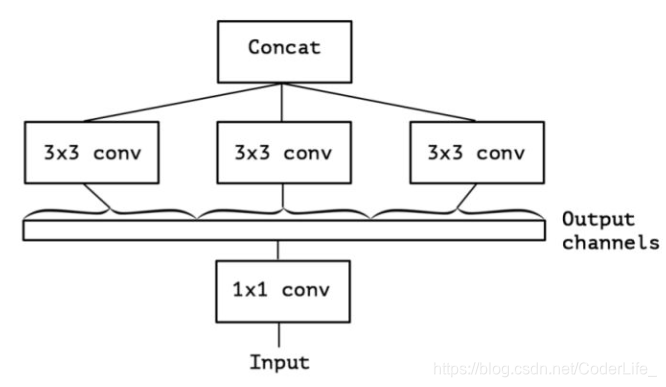
上面的简化版本,我们又可以看做,把一整个输入做为1*1卷积,然后切成三段,所以又出现了如下表现形式
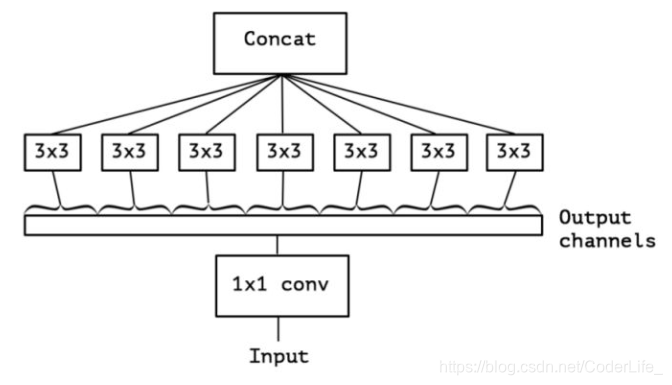
我们考虑,如果不是分成三段,而是分成5段或更多(最多达到通道数),性能可能会更好。
MobileNet_v1
模型结构
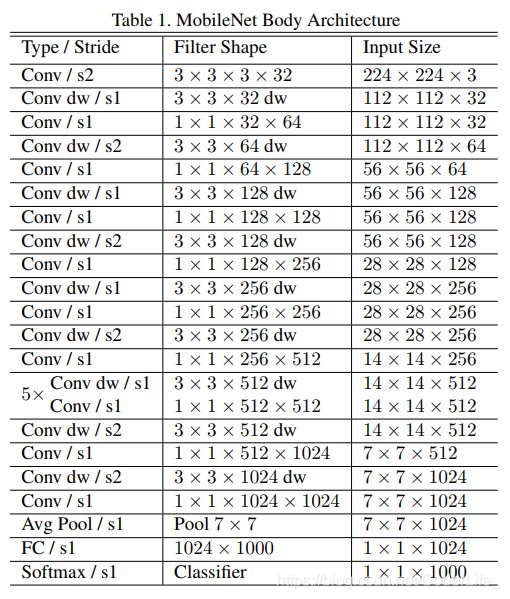

在每一个Depthwise Conv 后都接一个BN和RELU层
优点分析
-
轻量化 模型中没有使用池化操作,而是直接采用stride=2进行卷积操作
-
用两个超参数来控制网络计算速度与准确度之间的平衡:
-
Width Multiplier(α \alphaα): Thinner Models
所有层的通道数(channel)乘以α参数,模型大小近似下降到原来的α²倍,计算量下降到原来的α²倍
-
Resolution Multiplier(ρ \rhoρ): Reduced Representation
输入层的分辨率(Resolution)乘以ρ参数,等价于所有层分辨率乘以ρ,模型大小不变,计算量下降为原来的ρ²倍
-
MobileNetV2
不同点主要在于:
- 引入了shortcut结构(残差网络)
- 2、在进行depthwise之前先进行1x1的卷积增加feature map的通道数,实现feature maps的扩张。(inverted residual block,一般的residual block是两头channel多总监featuremap的通道少(沙漏形态)。而inverted residual block是两头通道少,中间feature的通道多(梭子形态))
- 3、pointwise结束之后弃用relu激活函数,改用linear激活函数,来防止relu对特征的破坏。作者认为,激活函数在高位空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好
模型结构:
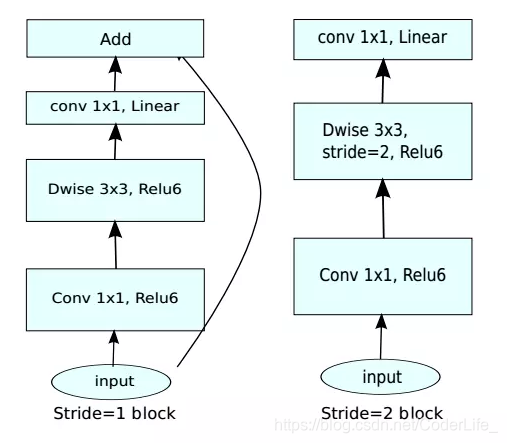
为什么要在Depthwise之前进行1x1卷积来增加feature map的通道数?
因为DW卷积的是对所有的通道进行卷积操作,通道数量成为制约卷积提取操作的关键因素,假如通道数很少的话,卷积只能在一个低纬空间中提取特征,因此效果不够好,所以我们在进行DW卷积之前,先对特征进行升维操作,这样DW卷积也会在一个相对高的维度进行特征提取工作
如通道数很少的话,卷积只能在一个低纬空间中提取特征,因此效果不够好,所以我们在进行DW卷积之前,先对特征进行升维操作,这样DW卷积也会在一个相对高的维度进行特征提取工作

















 1860
1860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









