




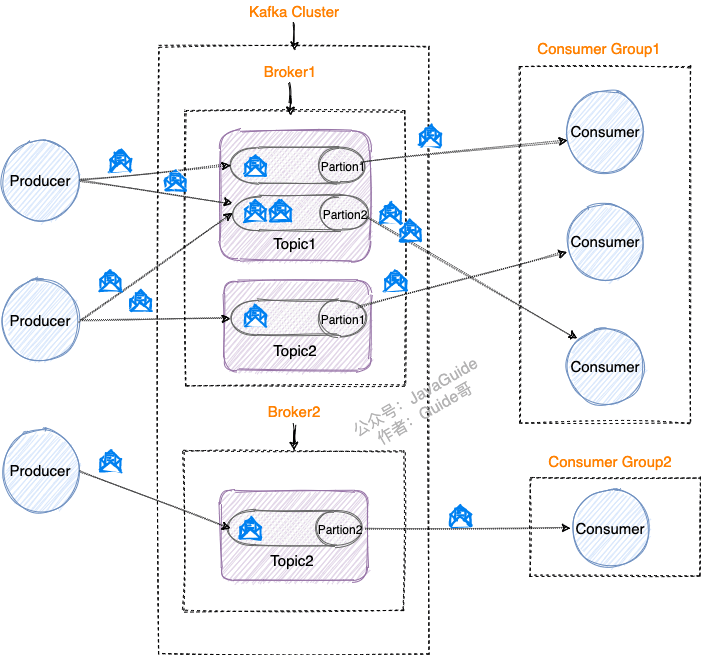
多个消费者实例共同组成的一个 Consumer Group(消费者组) ,Kafka 以 Consumer Group 这一个整体来订阅 Topic (主题),Consumer Group 内的所有 Consumer 共同来消费订阅的 Topic 内的所有 Partition(分区)。
Kafka 通过 Group ID(字符串) 唯一标识 Consumer Group 。
并且,Topic 下的每个 Partition 只从属于 Consumer Group 中的一个 Consumer,不可能出现 Consumer Group 中的两个 Consumer 负责同一个 Partition。
如果订阅的 Topic 内的所有 Partition 数量小于 Consumer Group 中的所有 Consumer 数量的话,会发生什么情况呢? 按照默认的策略,有一些 Consumer 是多余的,会没有消息消费而处于空闲的状态。那如果订阅的 Topic 内的所有 Partition 数量大于 Consumer Group 中的所有 Consumer 数量的话,会发生什么情况呢?会出现一个 Consumer 负责多个分区现象。因此,一般建议两者(Consumer 和 Partition)数量相等。
举个例子:假设一个 Consumer Group 订阅了 2 个(Topic 1、Topic 2),Topic 1 有 2个分区,Topic 2 有 1 个分区。那么,最理想的状态就是给该 Consumer Group 设置 3 个 Consumer。
设想一下:假如某个 Consumer Group 突然加入或者退出了一个 Consumer,会发生什么情况呢?
答案就是 “Rebalance” 。
什么是 Rebalance 呢? Rebalance 翻译过来就是 重平衡 ,它本质上是一种协议,规定了一个 Consumer Group 下的所有 Consumer 如何达成一致来分配订阅 Topic 的每个分区。比如某个 Consumer Group 下有 3 个 Consumer,它订阅了 3 个 Topic,总共 6个 Partition 。正常情况下,Kafka 平均会为每个 Consumer 分配 2 个 分区。这个分配的过程就叫 Rebalance。
除了 Consumer Group 的 Consumer 发生变化时会发生 Rebalance,下面这些情况也会发生 Rebalance:
●订阅的 Topic 内的 Partition 发生变更
●订阅的 Topic 发生变更
●…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









