1,hive是数据仓库,数据库和数据仓库的区别?
数据库:传统的关系型数据库的应用,主要是基本的、日常的事务处理,更关注业务交易处理(OLTP)
数据仓库:数据仓库支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询效果,更关注数据分析层面(OLAP)
2,hive搭建, hive搭建是按照元数据的存储和管理进行搭建的,hive将元数据保存到mysql。
3,hive相关的DDL操作
3.1创建数据库:create database databaseName
3.2创建表:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
•CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常
•EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
•LIKE 允许用户复制现有的表结构,但是不复制数据
•COMMENT可以为表与字段增加描述
•PARTITIONED BY 指定分区
•ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe(正则)。在建表的时候,
用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe(正则),Hive 通过 SerDe(正则) 确定表的具体的列的数据。
•STORED AS
SEQUENCEFILE //序列化文件
| TEXTFILE //普通的文本文件格式
| RCFILE //行列存储相结合的文件
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname //自定义文件格式
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。
•LOCATION指定表在HDFS的存储路径
3.3内部表和外部表:
内部表:内部表不需要指定数据存储的路径,直接将数据存储在默认的目录中。内部表的数据和元数据都是由hive来管理的,删除的时候全部删除
外部表:外部表需要使用external关键字指定,需要使用location指定存储数据的位置。外部表的数据由hdfs管理,元数据由hive管理,删除的时候只删除元数据,数据不会删除
4,Hive中的相关DML
增:
常用的三种方式
1,load加载
语法:load data local inpath ' filepath ' overwrite/into table tablename (partition)
解释:
local:可选,表示从本地文件系统中加载,而非hdfs
overwrite:可选,先删除原来数据,然后再加载 partition:这里是指将inpath中的所有数据加载到那个分区,并不会判断待加载的数据中每一条记录属于哪个分区。
2,insert插入
基本模式
INSERT INTO|OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1
多插入模式
FROM frometable1,fromtable2....
INSERT INTO|OVERWRITE TABLE desttable1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1
[INSERT INTO|OVERWRITE TABLE desttable2 [PARTITION ...] select_statement2] ...
动态分区模式
INSERT INTO|OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement
删:
想要使用删除和修改必须要经过事务,需要配置事务。基本上不要想着去做删除操作,工作中也用不到
改:
update操作速度特别慢,最好不要在hive中做update操作
Hive函数
1,函数的分类
udf:一进一出
udaf:多进一出
udtf:一进多出
hive中的内嵌函数:字符函数,数值函数,日期函数,条件函数,复杂类型函数
hive中可以自定义函数:
1、编写Java代码继承UDF类
2、实现evaluate方法,所有实现的核心逻辑写到此方法中
3、将写好的代码打成jar包
4、将jar包上传到本地linux或者hdfs
5、如果是本地linux,在hive客户端执行add jar path;
create temporary function func_name as 'package+class'
如果是hdfs,直接创建函数
create function func_name as 'package+class' using 'jar在hdfs上的路径'
Hive的分区
目的:方便提高检索效率 展现形式:再hdfs目录上创建多级目录
hive分区的分类: 静态分区 动态分区
静态分区
1、创建分区表
hive (default)> create table order_mulit_partition(
> order_number string,
> event_time string
> )
> PARTITIONED BY(event_month string, step string)
> row format delimited fields terminated by '\t';
2、加载数据到分区表
load data local inpath '/opt/data/order_created.txt' overwrite into table order_mulit_partition PARTITION(event_month='201405', step='1');
order_created.txt内容如下
order_number event_time
10703007267488 2014-05-01 06:01:12.334+01
10101043505096 2014-05-01 07:28:12.342+01
10103043509747 2014-05-01 07:50:12.33+01
10103043501575 2014-05-01 09:27:12.33+01
10104043514061 2014-05-01 09:03:12.324+01
3、这种手动指定分区加载数据,就是常说的静态分区的使用。但是在日常工作中用的比较多的是动态分区。
静态分区是在创建表的时候就指定分区或者将表已经创建之后再指定分区(使用alter关键字)
动态分区
1、创建目标表
hive (default)> create table emp_dynamic_partition(
> empno int,
> ename string,
> job string,
> mgr int,
> hiredate string,
> sal double,
> comm double)
> PARTITIONED BY(deptno int)
> row format delimited fields terminated by '\t';
2、采用动态方式加载数据到目标表
加载之前先设置一下下面的参数
hive (default)> set hive.exec.dynamic.partition.mode=nonstrict
开始加载
insert into table emp_dynamic_partition partition(deptno)
select empno , ename , job , mgr , hiredate , sal , comm, deptno from emp;
上面加载数据方式并没有指定具体的分区,只是指出了分区字段。在select最后一个字段必须跟你的分区字段,这样就会自行根据deptno的value来分区。
3、验证一下
有值
hive (default)> select * from emp_dynamic_partition;
OK
emp_dynamic_partition.empno emp_dynamic_partition.ename emp_dynamic_partition.job emp_dynamic_partition.mgr emp_dynamic_partition.hiredate emp_dynamic_partition.sal emp_dynamic_partition.comm emp_dynamic_partition.deptno
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
8888 HIVE PROGRAM 7839 1988-1-23 10300.0 NULL NULL
有分区(自动分区)
hive (default)> show partitions emp_dynamic_partition;
OK
partition
deptno=10
deptno=20
deptno=30
deptno=__HIVE_DEFAULT_PARTITION__
Time taken: 0.29 seconds, Fetched: 4 row(s)
动态分区无需指定分区目录,直接根据指定的字段进行自动进行分区
Hive的分桶
因为Hive的分桶是按倍数因子结合哈希值来将数据随机放入相应的桶中。
应用场景通常是数据抽样。
tablesample(bucket x out of y) x:从哪个桶开始抽取数据
Hive的视图




hive的权限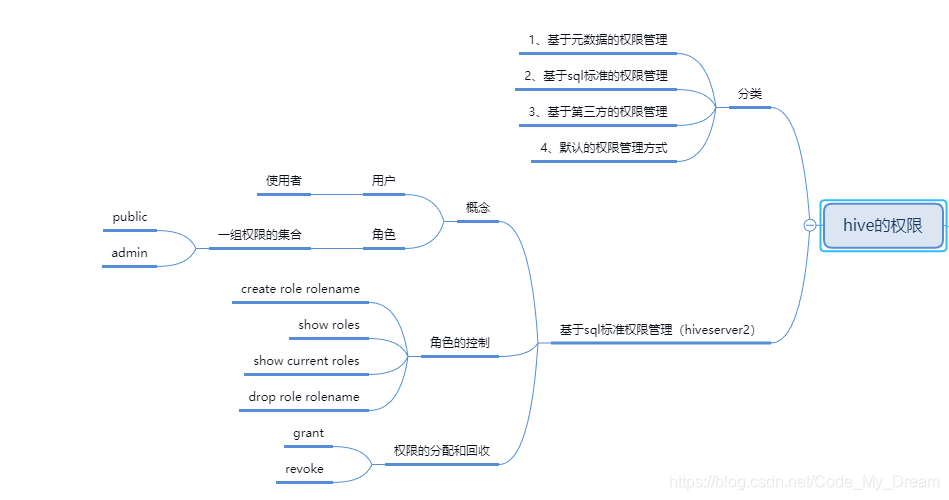
Hive的youhu





 本文介绍了Hive作为数据仓库的特性,对比了数据库和数据仓库的区别,详细阐述了Hive的搭建过程,元数据存储在MySQL中。接着讲解了Hive的DDL操作,包括创建数据库、表以及内部表和外部表的差异。重点讨论了Hive的分区概念,通过静态和动态分区的实例展示了数据加载。最后提到了Hive的分桶、视图、权限管理和一些实用功能。
本文介绍了Hive作为数据仓库的特性,对比了数据库和数据仓库的区别,详细阐述了Hive的搭建过程,元数据存储在MySQL中。接着讲解了Hive的DDL操作,包括创建数据库、表以及内部表和外部表的差异。重点讨论了Hive的分区概念,通过静态和动态分区的实例展示了数据加载。最后提到了Hive的分桶、视图、权限管理和一些实用功能。

















 390
390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









