




 本文详细介绍Hadoop HA集群的部署流程,包括主机规划、软件安装、环境变量配置、关键配置文件修改等步骤,以及Hadoop HA集群的启动与维护方法。
本文详细介绍Hadoop HA集群的部署流程,包括主机规划、软件安装、环境变量配置、关键配置文件修改等步骤,以及Hadoop HA集群的启动与维护方法。
-java:jdk-8u201-linux-x64.tar
-zookeeper:zookeeper-3.4.14.tar
-hadoop:hadoop-2.7.7.tar
步骤1.主机规划 提取码:mk29
| 内网ip & 主机名 &角色 | 软件 & 运行进程 |
|---|---|
| 192.168.18.126 : weyes01 :master节点 | jdk、hadoop : jps NameNode DFSZKFailoverController ResourceManager |
| 192.168.18.125 : weyes02 :master节点 | jdk、hadoop : jps NameNode DFSZKFailoverController ResourceManager |
| 192.168.18.133 : weyes03 :slaver节点 | jdk、zookeeper、hadoop : jps QuorumPeerMain JournalNode NodeManager DataNode |
| 192.168.18.134 : weyes04 :slaver节点 | jdk、zookeeper、hadoop : jps QuorumPeerMain JournalNode NodeManager DataNode |
| 192.168.18.136 : weyes05 ;slaver节点 | jdk、zookeeper、hadoop : jps QuorumPeerMain JournalNode NodeManager DataNode |
步骤2.准备zookeeper环境
步骤3.安装Hadoop集群
1.每台服务器添加hosts信息,保证每台都可以相互ping通
vim /etc/hosts
192.168.18.126 weyes01
192.168.18.125 weyes02
192.168.18.133 weyes03
192.168.18.134 weyes04
192.168.18.136 weyes05
vim /etc/hostname
weyes??
# hostname临时生效
hostname weyes??
# hostname永久生效
vim /etc/sysconfig/network
HOSTNAME=weyes??
2.设置时间同步 之后需要安装HBASE,时间不同步会导致部分节点HRegionServer无法启动
yum install ntp ntpdate
ntpdate -u cn.pool.ntp.org # 将当前的liunx时间设置为北京时间
vim /etc/ntp.conf
#修改成自己的网段
restrict 192.168.18.0 mask 255.255.255.0 nomodify notrap
server 210.72.145.44 perfer # 中国国家授时中心
server weyes01 # 局域网中NTP服务器的ip
server 127.127.1.0
fudge 127.127.1.0 stratum 10
service ntpd restart
//检查配置是否生效
ntpq -p
crontab -e
10 23 * * * root (/usr/sbin/ntpdate cn.pool.ntp.org && /sbin/hwclock -w) &> /var/log/ntpdate.log
weyes02,weyes03,weyes04,weyes05 将时间与weyes01进行同步
ntpdate weyes01
这时候发现节点间的时间同步了,但ntpdate只在开机运行,我们若要设置为1小时同步一次
crontab -e
* */1 * * * /usr/sbin/ntpdate weyes01
2.weyes01节点进行免密操作
ssh-keygen -t dsa -P '' -f /root/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# 在~/.ssh/ 下进行操作
scp id_dsa.pub weyes02:`pwd`/node01.pub
scp id_dsa.pub weyes03:`pwd`/node01.pub
scp id_dsa.pub weyes04:`pwd`/node01.pub
scp id_dsa.pub weyes05:`pwd`/node01.pub
# 在相应的服务器中把node01.pub公钥追加到authorized_keys
cat ~/.ssh/node01.pub >> ~/.ssh/authorized_keys
# weyes01节点进行免密登录到其它节点
ssh weyes01
ssh weyes02
ssh weyes03
ssh weyes04
ssh weyes05
3.weyes02节点上进行免密操作
ssh-keygen -t dsa -P '' -f /root/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# 在~/.ssh/ 下进行操作
scp id_dsa.pub weyes01:`pwd`/node02.pub
scp id_dsa.pub weyes03:`pwd`/node02.pub
scp id_dsa.pub weyes04:`pwd`/node02.pub
scp id_dsa.pub weyes05:`pwd`/node02.pub
# 在相应的服务器中把node01.pub公钥追加到authorized_keys
cat ~/.ssh/node02.pub >> ~/.ssh/authorized_keys
# weyes01节点进行免密登录到其它节点
ssh weyes01
ssh weyes02
ssh weyes03
ssh weyes04
ssh weyes05
4.配置Hadoop环境变量
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
# 在每台服务器上进行配置Hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(1)weyes01 节点进行 Hadoop配置文件
# 将文件解压到/usr/local路径下
tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local
cd /usr/local/hadoop-2.7.7/etc/hadoop/
(2)修改java绝对路径
vim hadoop-env.sh
vim mapred-env.sh
vim yarn-env.sh
export JAVA_HOME=/usr/local/java
(3)修改core-site.xml (指定hdfs的访问方式)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopha</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.7/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.18.133:2181,192.168.18.134:2181,192.168.18.136:2181</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>15000</value>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<!--最大连接次数,修改大一点,为20,默认10 -->
<value>20</value>
<description>Indicates the number of retries a client will make to establish
a server connection.
</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<!--重复连接的间隔1000ms=1s -->
<value>1000</value>
<description>Indicates the number of milliseconds a client will wait for
before retrying to establish a server connection.
</description>
</property>
</configuration>
(4)修改hdfs-site.xml (指定namenode 和 datanode 的数据存储位置)
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.7/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.7/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--HA配置 -->
<property>
<name>dfs.nameservices</name>
<value>hadoopha</value>
</property>
<property>
<name>dfs.ha.namenodes.hadoopha</name>
<value>nn1,nn2</value>
</property>
<!--namenode1 RPC端口 -->
<property>
<name>dfs.namenode.rpc-address.hadoopha.nn1</name>
<value>weyes01:9000</value>
</property>
<!--namenode1 HTTP端口 -->
<property>
<name>dfs.namenode.http-address.hadoopha.nn1</name>
<value>weyes01:50070</value>
</property>
<!--namenode2 RPC端口 -->
<property>
<name>dfs.namenode.rpc-address.hadoopha.nn2</name>
<value>weyes02:9000</value>
</property>
<!--namenode2 HTTP端口 -->
<property>
<name>dfs.namenode.http-address.hadoopha.nn2</name>
<value>weyes02:50070</value>
</property>
<!--HA故障切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- journalnode 配置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://weyes03:8485;weyes04:8485;weyes05:8485/hadoopha</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.hadoopha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--发生failover时,Standby的节点要执行一系列方法把原来那个Active节点中不健康的NameNode服务给杀掉,
这个叫做fence过程。sshfence会通过ssh远程调用fuser命令去找到Active节点的NameNode服务并杀死它-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!--SSH私钥 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<!--SSH超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!--Journal Node文件存储地址 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop-2.7.7/journal</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<!-- 这个地方是为Hbase的专用配置,最小为4096,表示同时处理文件的上限,不配置会报错 -->
<property>
<name>dfs.datanode.max.xcievers</name>
<value>8192</value>
</property>
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>60000</value>
</property>
</configuration>
(5)修改yarn-site.xml ( 配置yarn)
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>weyes01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>weyes02</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>192.168.18.133:2181,192.168.18.134:2181,192.168.18.136:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(6)修改mapred-site.xml (配置mapreduce)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
</configuration>
(7)修改slaves
weyes03
weyes04
weyes05
(8)将文件传送到别的节点
cd /usr/local
scp -r hadoop-2.7.7 weyes02:`pwd`
scp -r hadoop-2.7.7 weyes03:`pwd`
scp -r hadoop-2.7.7 weyes04:`pwd`
scp -r hadoop-2.7.7 weyes05:`pwd`
步骤4.Hadoop HA集群启动及维护,需按照顺序执行
1.开启JournalNode服务
# weyes03 weyes04 weyes05 两个NameNode的服务冲突,必须的先开启JournalNode服务才行(三个节点都要先开)
hadoop-daemons.sh start journalnode
2…weyes01 格式化HDFS
hdfs namenode -format
3.weyes01 格式化zk 重点强调:只能在nameonde节点进行
hdfs zkfc -formatZK
4.在weyes01节点启动hdfs和yarn
start-dfs.sh
start-yarn.sh
5.在weyes02节点启动namenode和ResourceManager进程
hadoop-daemon.sh start namenode
yarn-daemon.sh start resourcemanager
6.weyes02保持主从master历史日志一致
#scp -r /usr/local/hadoop-2.7.7/name weyes02:/usr/local/hadoop-2.7.7/
#需要weyes01节点启动NameNode才能使用
hadoop-daemon.sh start namenode
hdfs namenode -bootstrapStandby
7.查看端口是否能访问
netstat -ano |grep 50070
使用浏览器访问一下
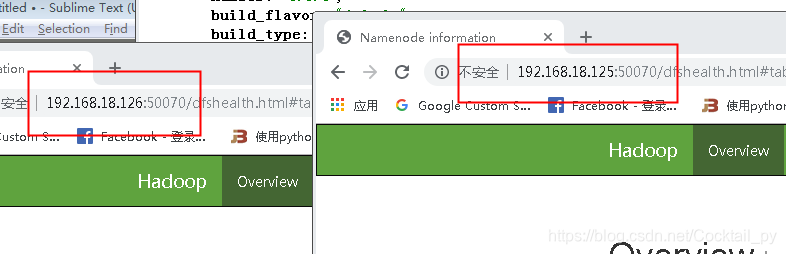
tips:可能会遇到的bug
bug1: kernel:NMI watchdog: BUG: soft lockup - CPU#0 stuck for 26s
https://blog.csdn.net/jackliu16/article/details/82017283
bug2: Hadoop搭建HA的时候,开启NameNode服务的时候总有其中一个挂掉的原因及解决方法
https://blog.csdn.net/xiaozelulu/article/details/81255183
bug3: hadoop-daemons.sh start journalnode ssh: Could not resolve hostname re03: Name or service not known
# 建议将sre03换成别的 名称
bug4: hadoop HA模式下 namenode 的HTTP端口 浏览器打不开
# 尝试把相应服务器的防火墙关闭
# telnet: connect to address 192.168.18.125: No route to host
# iptables -F
参考链接 :https://www.cnblogs.com/bigdatasafe/p/10784523.html
参考链接 : https://www.jianshu.com/p/71b4f456726a
参考链接: https://blog.youkuaiyun.com/maoyg0821/article/details/80180443
参考链接:https://yq.aliyun.com/articles/703353
https://oneandonly.readthedocs.io/en/latest/hadoop/hadoop-install.html#hadoop-ha


















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











