





本文字数:6857;估计阅读时间:18 分钟
作者:Alexey Milovidov
本文在公众号【ClickHouseInc】首发

Rust 是一门非常优秀的编程语言,特别适合开发终端应用、幻想类游戏主机,以及 web3 项目。如果你在网上随便提一下 “C++”,很快就会有人跳出来安利 Rust 的种种好处。遗憾的是,ClickHouse 是用 C++ 编写的,而不是 Rust。如果我们能吸引到一批热情洋溢的 Rust 开发者,那该有多好啊……于是,我决定——我们必须在 ClickHouse 中引入 Rust。
当然,我们的目标并不是把 ClickHouse 全部用 Rust 重写——这完全是浪费时间。我们仍然使用 C++ 开发 ClickHouse,并将其中的一些部分重构成更“现代化”的 C++。重写从来都不是终点。尽管我也见过一些工程师,他们乐于将 Rust 写的代码重新用 Rust 再写一遍,只因为他们对 Rust 情有独钟。我们真正应该做的,是允许用 Rust 编写新的系统组件。Rust 应该能无缝集成进 ClickHouse 的构建系统中,能够与 C++ 实现良好的互操作,整体项目也能一同编译、一同测试,而且不会引入任何额外的复杂性。
第一步:从小组件开始尝试 Rust
要在 ClickHouse 中引入 Rust,第一步是挑选一个适合“试水”的小组件。这个组件不能处在系统的关键路径上,最好是随时可以剥离的——万一我们的工程师因为“Rust 过敏”而感到不适,我们也能果断回滚,假装什么都没发生。同时,这个组件又要足够复杂,好让我们完整地测试 Rust 与构建系统的集成效果。
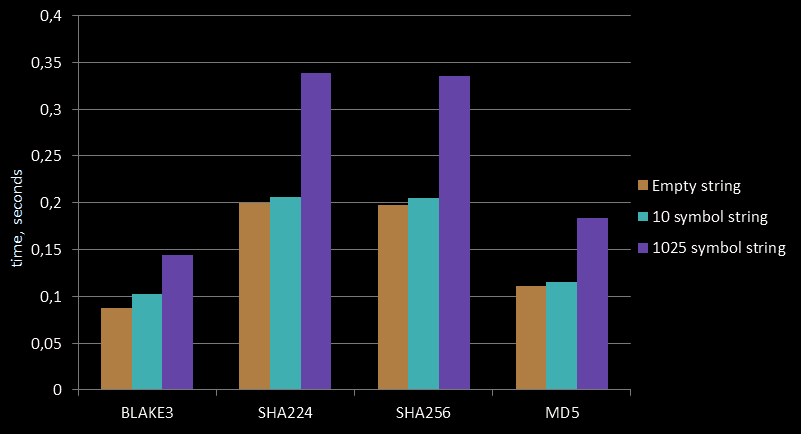
为了不让我们宝贵的资深 C++ 工程师承担这个风险,我把这个任务交给了一位本科实习生。说实话,在学生群体中找到精通 Rust 的人比在公司里容易多了——Rust 在区块链和 web3 圈子里可是“顶流”。于是,我们选择将 BLAKE3 哈希函数集成到 ClickHouse 作为第一个实验对象。那时,BLAKE3 还只有 Rust 实现,因此选择它显得非常合理。
BLAKE3 集成实践
几个月后,多亏了 Denis Bolonin,我们的第一段 Rust 代码终于出现在 ClickHouse 中。我们通过 "corrosion" 将 Rust 集成进 CMake 构建流程,项目目录里也新加了一个用于存放 Rust 代码的专属目录,并编写了如何通过 C++ 包装器调用 Rust 库的示例。关于这部分的技术细节,欢迎阅读我们的博客文章。
Skim:Rust 开发者的大门已开启
至此,我们已经成功为 Rust 开发者打开了进入 ClickHouse 代码库的大门!他们终于不用再写那些老旧终端应用了。我也满怀期待地刷着 Pull Request 列表,等待第一位 Rust 爱好者的外部贡献。果然,他们来了!
第一份 Rust 编写的外部 PR,是对 clickhouse-client 的改进,引入了“交互式历史记录导航”功能。之前这个功能是通过子进程实现的,而现在我们直接将这段 Rust 代码编译并链接进 ClickHouse 主程序。不过,这个 Rust 库里有个 bug,运行时直接导致程序崩溃了……

后来我们又引入了第二个 Rust 库 skim。但就在这时我们发现,实际上 LLVM 的 C++ 代码库中已经包含了 BLAKE3 实现(我们也依赖了 LLVM)。升级后直接使用 LLVM 中的 BLAKE3 要简单得多。而为了验证 Rust 集成确实可用、CI 能跑通,其实只保留一个 Rust 库就够了。于是我们把原本的 Rust 版本 BLAKE3 替换成了 LLVM 的 C++ 实现,性能也没有任何明显差异。
PRQL:用 Rust 写的新查询语言
我们在 ClickHouse 中引入的第三个 Rust 库是 PRQL —— 一种新的查询语言,旨在作为 SQL 的替代方案。PRQL 支持将查询表达为一种“流水线式”的组合结构,设计初衷很前卫。不过,它的语法比 SQL 更加复杂,甚至有点类似 Clojure 的风格。这种语言在网上挺火——只要有人晒出 PRQL 的代码,评论区里就会响起一片“这真是个好主意,而且还是 Rust 写的!”的赞叹,项目也随之在 GitHub 上收获大量 star。实际上,这也是很多 Rust 项目涨星星的典型路径。虽然看起来没多少人真的会用这门语言,但我们也想蹭一下这波热度。于是,另一个学生选择将 PRQL 集成进 ClickHouse 作为他的毕业课题。
以下是一个标准的 ClickHouse SQL 方言的查询示例:
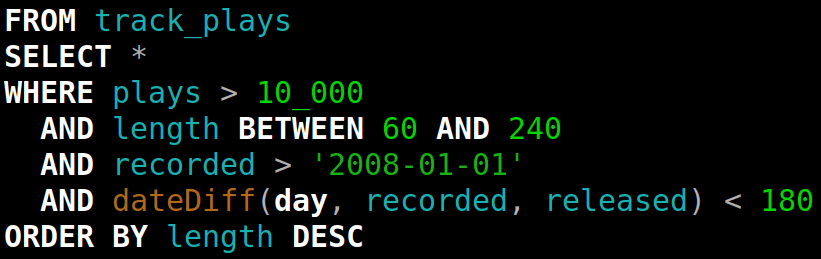
而用 PRQL 表达的同一查询则是这样的:

几个月后,在 Alexander Nam 的帮助下,PRQL 支持正式合并进了 ClickHouse 代码库。ClickHouse 本身支持可切换的查询方言,你可以通过 SET dialect = 'prql'(或 'kusto' / 'sql')随时切换查询语言。也可以在用户配置或 HTTP API 参数中设置默认方言,然后用对应的语法发送查询。当然,非 SQL 方言目前也有一些限制,比如暂不支持交互式语法高亮,内置函数和扩展的兼容性也还有待加强。
尽管 PRQL 的实用性仍有争议,但它确实增强了我们对 Rust 的信心。在引入了两个 Rust 库之后,我们开始意识到:Rust 可能真的没那么容易“赶走”了,而我们也渐渐习惯并接受了它的存在。
Delta Kernel:Rust 首个“真需求”落地
这是我们首次引入 Rust,不再只是为了探索,而是出于真实的业务需求。Delta Lake 是 Databricks 推出的开放数据湖格式,它在功能上类似 ClickHouse 中的 MergeTree 表,但底层数据存储采用对象存储中的 Parquet 文件。近年来,数据湖(Data Lake)以及“Lakehouse”(一种听起来像 ClickHouse,但实际是数据湖 + 数据仓库混合架构的新模式)在大型企业中越来越受欢迎。它们的优势在于:数据格式不再依赖特定计算引擎。比如,Spark 可以将数据写入 Iceberg 或 Delta Lake 格式的湖中,而 ClickHouse 则可以直接在这套数据湖之上执行分析查询,这种架构因此被称为“Data Lakehouse”。
问题来了:目前市面上并没有成熟的 C++ 实现可以用于解析 Iceberg 或 Delta Lake。不是你只能用 Java(这对 ClickHouse 项目组来说简直“灾难”),就是得从头用 C++ 实现。而乍看之下,其实这类格式的结构并不复杂:
-
数据以 Parquet 文件形式存储在对象存储中;
-
元数据和快照信息通常是 JSON 或 Avro 格式;
-
表目录服务通过统一的 catalog API 提供。
我们过去其实已经用 C++ 实现过这些格式,包括 Iceberg v1/v2、Delta Lake 和 Apache Hudi。但这些实现并不完整,有很多边角场景未覆盖,而且写起来非常“痛苦”——毕竟,很少有 C++ 工程师会喜欢做“读 JSON 按规范逐字段解析”的工作。
就在这时,Rust 的快速崛起为我们带来了新的可能。Databricks 官方发布了 Rust 实现版的 Delta Lake,我们第一时间采用,并替换掉了原有的 C++ 实现。你可以在我们的发布会上,观看来自 Databricks 的工程师 Oussama Saoudi 的技术分享。不仅如此,我们在使用中还发现并修复了其中的一个 Bug,并为该库贡献了新特性,从而反哺整个开源社区。这也是目前为止 Rust 在 ClickHouse 中最深入、最真实的一次落地集成。接下来,我们就来看看为实现这项集成,我们解决了哪些关键技术难题……
问题与挑战
一、构建供应链的挑战
在最初集成 Rust 时,我们采用的是标准方式:通过 cargo 在构建过程中从互联网下载依赖库。但这显然无法满足 ClickHouse 的构建要求。我们的构建系统必须是完全封闭、可复现的,不能依赖外部网络,也不能依赖第三方服务平台,否则可能引发供应链安全问题。同时,我们所有内容都必须基于源代码构建,项目仓库中不得包含任何预编译二进制文件。
我们一开始提供了关闭 Rust 支持的选项,作为临时解决方案;之后,在构建镜像中预置依赖;最终,我们将所有 Rust 依赖项打包进源码树(vendor 方式),但这也还不是终极方案。
二、Rust 与 C++ 的复杂互操作性
虽然 Rust 是一门内存安全语言,但贡献者们的第一份 Rust 代码往往反而会导致 segment fault(段错误)。原因在于 Rust 与 C++ 的互操作需要手动编写桥接包装代码,而且必须非常谨慎地管理内存所有权、生命周期、释放顺序等细节。这类问题的复杂程度远超写一段纯 Rust 逻辑。即便你是个熟练的 Rust 工程师,想要正确完成跨语言封装仍不是一件轻松的事。幸运的是,我们在 CI 中开启了 fuzzing 测试机制,能够在代码合并之前发现这类潜在风险。
三、Panic:Rust 中没有异常机制

在错误处理上,Rust 的一大争议点就是它不支持传统意义上的异常机制(虽然可以通过一些技巧实现)。Rust 使用错误返回值处理异常,虽然比 Go 或 C 做得更好,但这要求你对每一处可能出错的地方都显式地处理异常,包括用户输入错误、网络连接断开,甚至操作系统的底层失败。
而在 C++ 中,异常可以自然传播到上层堆栈,并由查询线程统一处理。但在 Rust 中,许多开发者为了图省事,直接使用 panic!,这会导致整个程序崩溃退出。这在批处理程序中也许没问题,但对于运行着数百个查询线程的多租户 ClickHouse 服务器来说,显然是不能接受的。
我们的 CI 中的 fuzz 测试自动发现:某些格式不正确的 PRQL 查询会触发 panic,从而导致整个服务器崩溃。好在 PRQL 的作者在收到报告后迅速修复了问题。
我们发现的问题,其实和很多 C 项目中常见的问题如出一辙。很多 C 库通过 assert 检查“绝不可能出错”的代码路径,结果我们的 CI 总能证明——这些错误非常可能发生。我们处理 Rust 库 bug 的方式,与我们处理 C 库 bug 并无二致。此外,Rust 中的 panic 实际上也是通过栈展开来实现的,这种机制也被我们用来改造相关逻辑,从而更安全地处理运行时错误。
四、Sanitizers:即使用了 Rust,也不能少的安全检查
在 ClickHouse,我们始终坚持在 C++ 项目中使用完整的 sanitizer 套件,包括:AddressSanitizer:检测无效的内存访问;MemorySanitizer:检测未初始化内存的使用;ThreadSanitizer:检测并发数据竞争;UBSanitizer:检测可能引发未定义行为的代码。这些工具在我们 CI 中运行得非常彻底——每次 Pull Request、每次提交、master 和 release 分支都会执行全套检查,覆盖所有测试类型,结合强化编译选项、随机性测试、压力测试和 fuzzing 机制共同运行。
有人可能会说:Rust 不是号称“绝对安全”吗,为什么还需要这些工具?但问题在于,我们现在面对的,是一个主要用 C++ 编写、并混入了少量 Rust 的复杂应用。在这种场景下,我们必须确保整个系统层面上的一致性。比如,C++ 分配了一段内存,然后调用 Rust 函数写入数据,最后再由 C++ 读取。如果我们启用了 MemorySanitizer,那这段写入操作也必须被标记为“已初始化”。否则 Sanitizer 会误报未初始化访问。
这意味着 Rust 代码也必须支持 MSan 插桩。虽然 Rust 是支持的,但 MSan 仅在 Rust 的 nightly 工具链中可用,所以我们必须固定使用特定版本的 nightly,确保构建不随时间变化而失效。
另外,由于未知的兼容性问题,我们还必须在 Rust 中关闭 ThreadSanitizer 的支持。
五、交叉编译:跨平台构建的挑战
ClickHouse 一直坚持使用交叉编译的方式构建程序。哪怕是在 x86_64 Linux 上为同样的平台构建,我们也会使用“主机 ≠ 目标平台”的方式进行构建。这可以确保构建流程不依赖于本地操作系统环境,完全基于源码和构建脚本,进而实现封闭、可验证、强一致的构建过程。
ClickHouse 的跨平台能力非常强。IBM 工程师希望它能运行在 s390x 这样的特殊大端平台,我们也在 CI 中添加了支持。就连我那位住在车库、与五只猫为伴的朋友,也想在 FreeBSD 上部署 ClickHouse,我们同样提供了 FreeBSD 的构建版本(顺便一提,猫确实很可爱)。

在纯 Rust 项目中,交叉编译可能不难,甚至比 C++ 更简单。但当 Rust 与 C++ 深度混合时,问题变得棘手许多。
六、库链接:来自 Rust 依赖链的阻力
ClickHouse 构建过程中,严格禁止使用任何系统级库,我们要求所有依赖都以源码形式静态链接,确保系统环境无关性。然而,Rust 的 delta-kernel-rs 库依赖了 reqwest,而 reqwest 又会尝试自动链接系统中的 OpenSSL。这与我们的构建策略相冲突——我们希望使用的是项目内部构建的 OpenSSL,并以静态方式链接。最终,我们解决了这个链接冲突问题,让 Rust 库也遵循了 ClickHouse 构建的规则。
七、符号名爆炸:Rust 也难逃此劫
众所周知,C++ 模板虽然强大,但也带来了编译速度慢、二进制文件臃肿和超长符号名等问题(符号名就是编译后函数或数据在二进制中的名字,用于链接器关联各类库)。而 Rust 虽然强调“现代语言”,但在这方面做得可能更糟。引入 PRQL 后,我惊讶地发现 ClickHouse 的二进制大小显著增长。进一步排查后发现,单个 Rust 符号名竟然能达到 85KB,而这还只是函数名本身,不包括代码体积!PRQL 作者在得知问题后迅速修复。我们也决定为所有 Rust 库禁用调试信息——毕竟,Rust 安全得很,谁还需要调试?
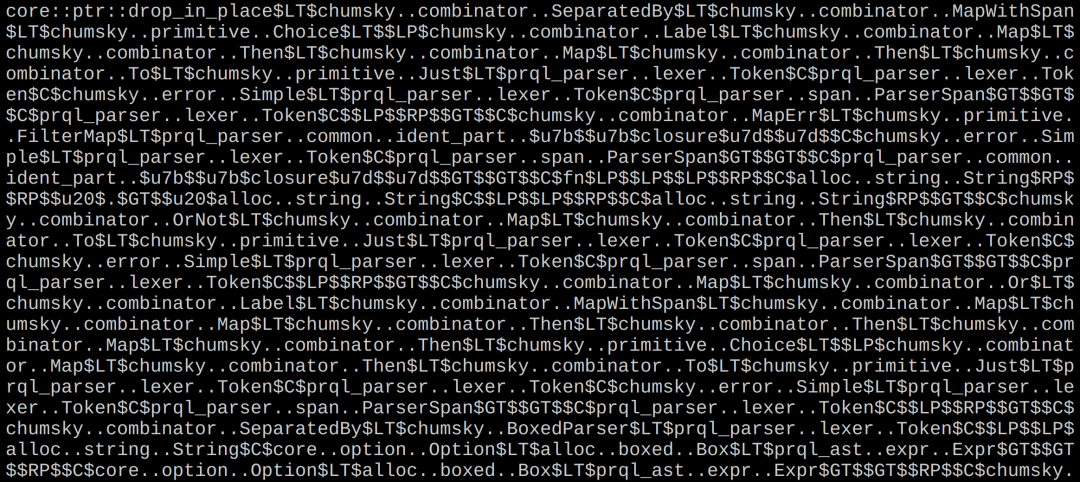
图像中,Rust 的符号长度几乎是画面容量的 300 倍。
我们还使用了自研的 Binary Visualizer 工具,通过 ClickHouse 的 /binary 接口,可视化分析二进制体积,最终定位了问题符号名的位置。

ClickHouse二进制代码可视化效果图。尝试在图中找到Rust。
然而——就在写这篇文章时我发现:这个问题不仅没被彻底修复,反而更严重了。现在部分 Rust 符号已经接近 1MB 大小,我必须马上处理这个问题。
八、组合性:理想很丰满,现实很复杂
ClickHouse 的 C++ 代码中有一套经过实践验证的资源管理机制,比如:我们自建了 S3 连接池;控制请求并发度并实现合理的负载均衡;使用指数退避算法管理连接重试;所有内存分配行为都在查询上下文中进行统一计量,用于控制和追踪内存用量。但 Rust 第三方库往往另有一套运行约定,无法轻易适配我们的架构。你很难要求一个外部库支持自定义内存分配器、连接池等机制。也许在 Haskell 或 Julia 的圈子里大家乐于这么做,但对于我们来说,这根本不现实。结果就是——当某个 Rust 库行为与我们不一致,我们只能硬着头皮深入源码做修改。而在项目初期,这些工作量和维护成本是完全无法预估的。
九、构建缓存与性能分析:Rust 另起炉灶
ClickHouse 的构建基础设施支持分布式缓存和构建性能分析系统。但要让 Rust 构建也受益于这些能力,就必须单独适配。现实是,我们曾有相当长一段时间无法为 Rust 构建启用缓存,导致 CI 成本和构建时间都显著增加。
十、依赖管理:Rust 借鉴了 Node.js 的一切(好与坏)
Rust 拥有极其模块化的生态系统,组件之间组合灵活,远胜 C++。但代价是:依赖链极长,传递依赖复杂,常常一个库就引入十几个间接依赖,有点类似 Node.js 的风格。这也意味着,我们不得不投入额外精力控制依赖膨胀,并与 dependabot 等自动工具“斗智斗勇”。
结尾:Rust 的现状如何?
Rust 在 ClickHouse 的应用一切顺利!如果你有热爱 Rust 编程的朋友,欢迎推荐他们加入 ClickHouse,我们保证给予最热烈的欢迎!
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









