




配置之前,需要配置非root用户的免密登陆
说明: 集群规划: 192.168.12.148
192.168.12.149
192.168.12.150
主节点是: 192.168.12.148
从节点是: 192.168.12.149
192.168.12.150
前期配置: 所有节点都增加ip和机器名称的映射关系,且3个节点可以相互ping通。
vim /etc/hosts
加上
192.168.12.148 cloud31
192.168.12.149 cloud32
192.168.12.150 cloud33
1.1配置 Hadoop
1.1.1修改配置
1、XML文件配置,在主节点执行以下命令:
cd /home/cloud/platform/hadoop-2.7.3/etc/hadoop
下面所有的配置文件都在/home/cloud/platform/hadoop-2.7.3/etc/hadoop下面
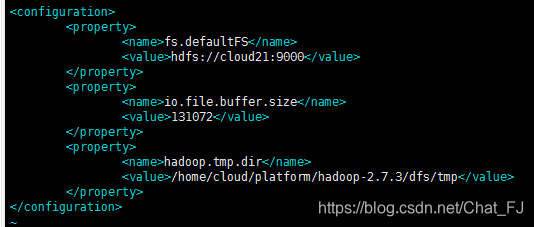
vim core-site.xml文件
加入
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cloud31:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/cloud/platform/hadoop-2.7.3/dfs/tmp</value>
</property>
</configuration>
dfs/tmp不需要自己建文件夹 , 需要初始化 , 最后配置好了初始化
修改 hdfs://cloud31:9000 #主节点用户名cloud31
修改 /home/cloud/platform/hadoop-2.7.3/dfs/tmp #hadoop/dfs/tmp的路径,
dfs/tmp不需要自己建文件夹 , 需要初始化 , 最后配置好了初始化
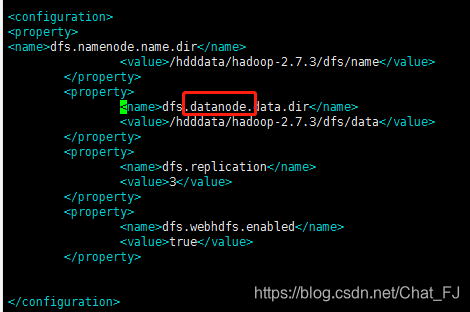
2)vim hdfs-site.xml文件
加入
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/cloud/platform/hadoop-2.7.3/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/cloud/platform/hadoop-2.7.3/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
data和name目录不需要自己新建
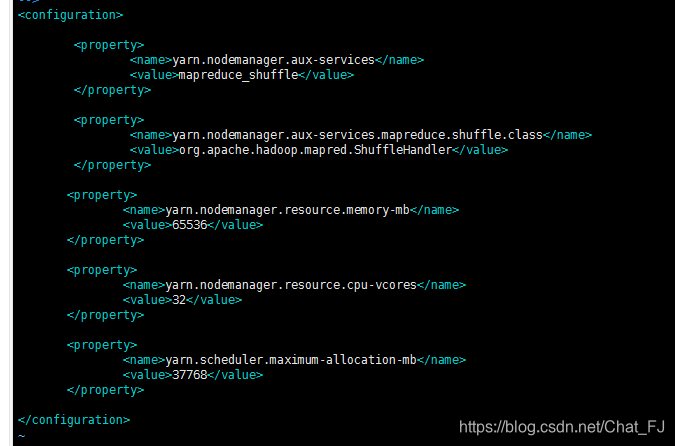
3)vim yarn-site.xml文件
加入
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>65536</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>37768</value>
</property>
</configuration>
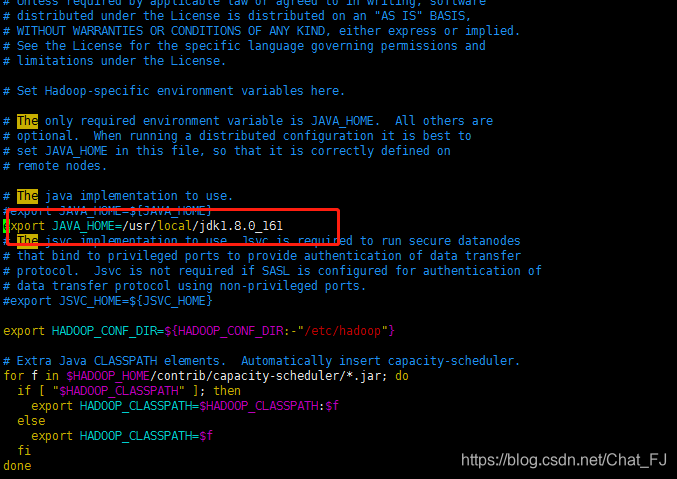
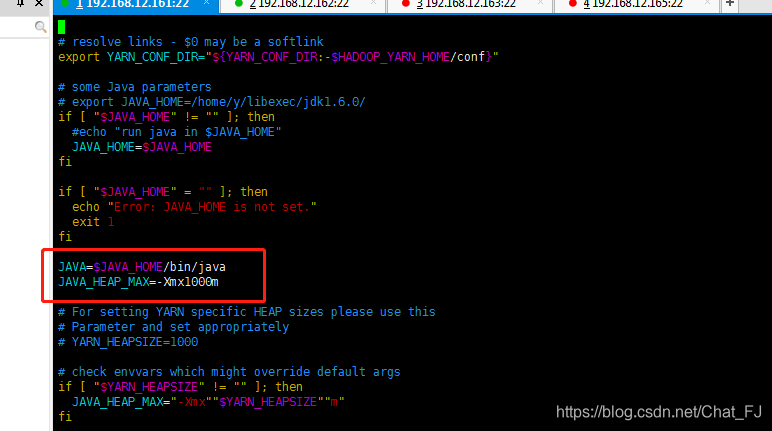
4)vim hadoop-env.sh
修改如下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_112
5)vim yarn-env.sh
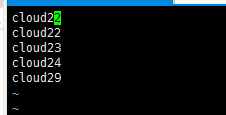
vim slaves
在文件中配置从节点IP,每个节点IP单独占一行,格式要求及示例如下:
格式要求 示例
cloud31
cloud32
cloud33
保存并关闭文件。
7)、配置文件分发:将hadoop文件夹从主节点上分发至集群中每一个从节点(在主节点执行)。**
cd /home/cloud/platform
scp -r hadoop 从节点IP:/bdp_softwares/(将主节点配置好的hadoop分发给另外两台从节点服务器上)
示例:scp -r /home/cloud/platform/hadoop2.7.3 cloud@192.168.12.149:/home/cloud/platform/
上述分发命令针对每一个从节点都需要执行一遍。
主节点初始化(去主节点上执行,必须要先scp,然后在初始化)
cd /hadoop2.7.3
./bin/hdfs namenode -format
**
2.启动验证hadoop
2.1启动hadoop
cd /home/cloud/platform/hadoop2.7.3
./sbin/start-dfs.sh
2.2验证Hadoop
1)在主节点输入jps命令,可看到以下两个进程:
NameNode
SecondaryNameNode
2)在每一个从节点输入jps命令,可看到以下一个进程:
DataNode
3)或者去页面上输入 主节点ip:50070 页面上有东西就ok了
若以上命令都正常,说明Hadoop安装成功。
2.3停止
cd /bdp_softwares/hadoop
./sbin/stop-dfs.sh
欢迎大家留下您的宝贵意见 , 一起讨论

















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









