代码
import requests
from bs4 import BeautifulSoup
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 歌单ID
playlist_id = '689203961'
# 构造歌单页面的URL
url = 'https://music.163.com/playlist?id=' + playlist_id
# 发送GET请求获取网页内容
response = requests.get(url, headers=headers)
html = response.text
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(html, 'html.parser')
# 提取歌单中的歌曲
song_list = soup.find('ul', {'class': 'f-hide'}).find_all('a')
for song in song_list:
# 获取歌曲名称
song_name = song.text
# 获取歌曲ID
song_id = song['href'].split('=')[-1]
# 构造歌曲详情页面的URL
song_url = 'https://music.163.com/song?id=' + song_id
# 发送GET请求获取歌曲详情页面的内容
song_response = requests.get(song_url, headers=headers)
song_html = song_response.text
# 使用BeautifulSoup解析歌曲详情页面的内容
song_soup = BeautifulSoup(song_html, 'html.parser')
# 提取歌曲的歌手
song_artist = song_soup.find('p', {'class': 'des s-fc4'}).find('span')['title']
# 打印歌曲的信息
print('歌曲名称:', song_name)
print('歌手:', song_artist)
结果
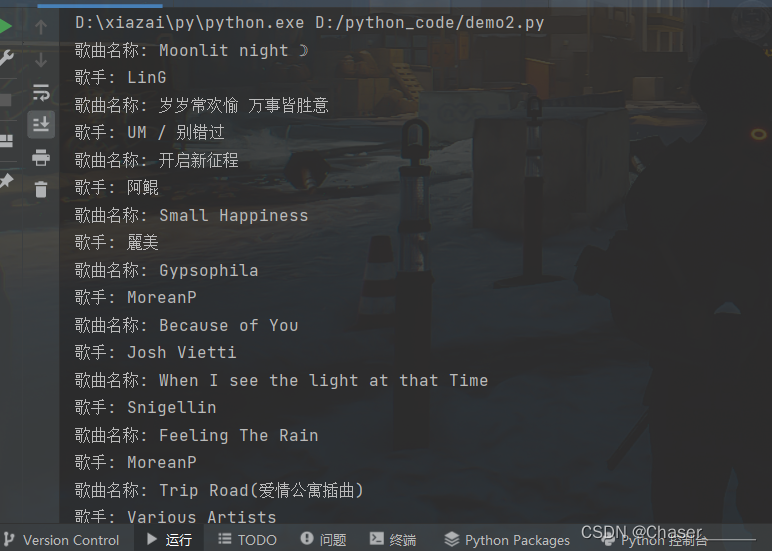





 本文展示了如何使用Python的requests和BeautifulSoup库爬取网易云音乐的歌单,包括歌单中的歌曲名称、歌曲ID以及歌曲的艺术家信息。
本文展示了如何使用Python的requests和BeautifulSoup库爬取网易云音乐的歌单,包括歌单中的歌曲名称、歌曲ID以及歌曲的艺术家信息。



















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











