





在数字基础设施的构建中,操作系统的价值不仅取决于其技术深度,更起始于其触达开发者的广度与便捷度。openEuler,作为一款面向数字基础设施的开源操作系统,其卓越的易获得性构成了其生态繁荣的基石。它通过多元化的获取渠道、简捷灵活的环境构建流程以及开箱即用的卓越性能,让每一位开发者都能几乎无门槛地开启自主创新之旅。本文将带领您亲身体验openEuler从获取到验证的完整流程,感受其如何将复杂留给底层,将简便交付用户。
openEuler官网:https://www.openeuler.org/en/
一、多元获取:开启openEuler世界的任意门
openEuler的易获得性首先体现在其丰富的镜像获取方式上。用户可以根据自身网络环境和需求,选择最合适的通道。

1. 官方主渠道:获取经过完整测试的稳定版本
最直接的方式是访问openEuler官方网站的下载页面。这里提供了所有长期支持(LTS)版本和创新版本的镜像文件。网站布局清晰,提供了ISO镜像、云镜像和容器镜像等多种格式,适配从物理机、虚拟机到云环境的全场景需求。
通过命令行工具,我们可以直接下载这些资源,过程极为简单:
# 创建下载工作目录
mkdir -p ~/openeuler-test && cd ~/openeuler-test
# 方法一:官方源直接下载
time wget -c https://repo.openeuler.org/openEuler-22.03-LTS/ISO/x86_64/openEuler-22.03-LTS-x86_64-dvd.iso
# 方法二:国内镜像源加速下载
time wget -c https://mirrors.bfsu.edu.cn/openeuler/openEuler-22.03-LTS/ISO/x86_64/openEuler-22.03-LTS-x86_64-dvd.iso
# 方法三:使用aria2多线程下载
sudo apt install -y aria2
aria2c -x 16 -s 16 --max-tries=3 --retry-wait=5 \
https://repo.openeuler.org/openEuler-22.03-LTS/ISO/x86_64/openEuler-22.03-LTS-x86_64-dvd.iso
# 下载完成后,验证镜像的完整性和安全性至关重要
# 下载对应的SHA256校验和文件
wget https://repo.openeuler.org/openEuler-22.03-LTS/x86_64/ISO/openEuler-22.03-LTS-x86_64-dvd.iso.sha256
# 执行校验
sha256sum -c openEuler-22.03-LTS-x86_64-dvd.iso.sha256
安装前的准备工作:
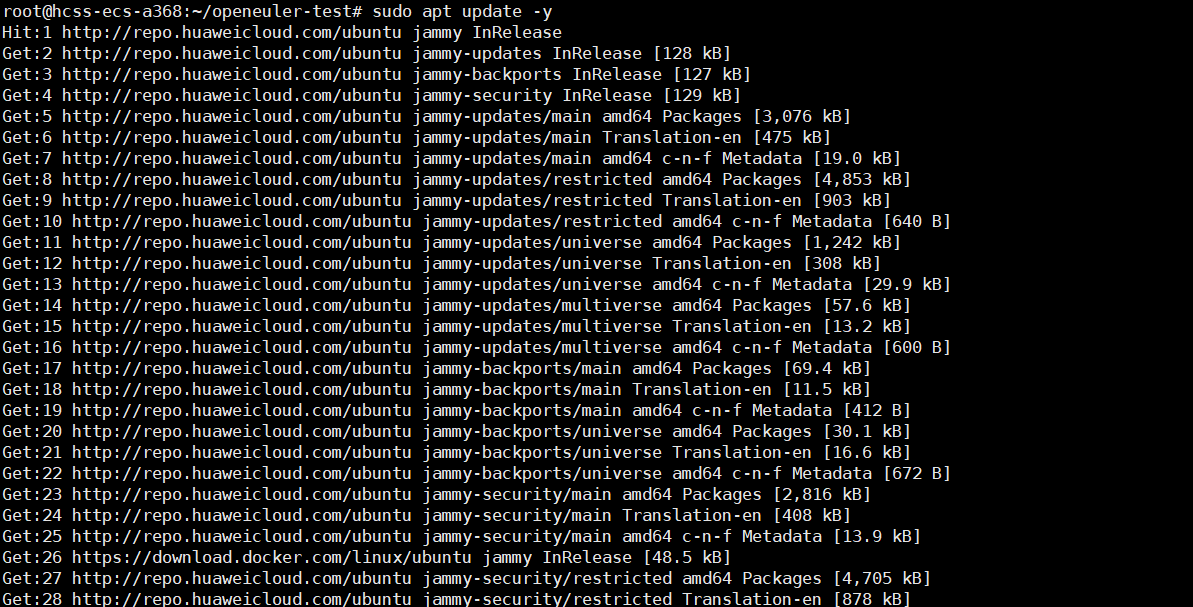
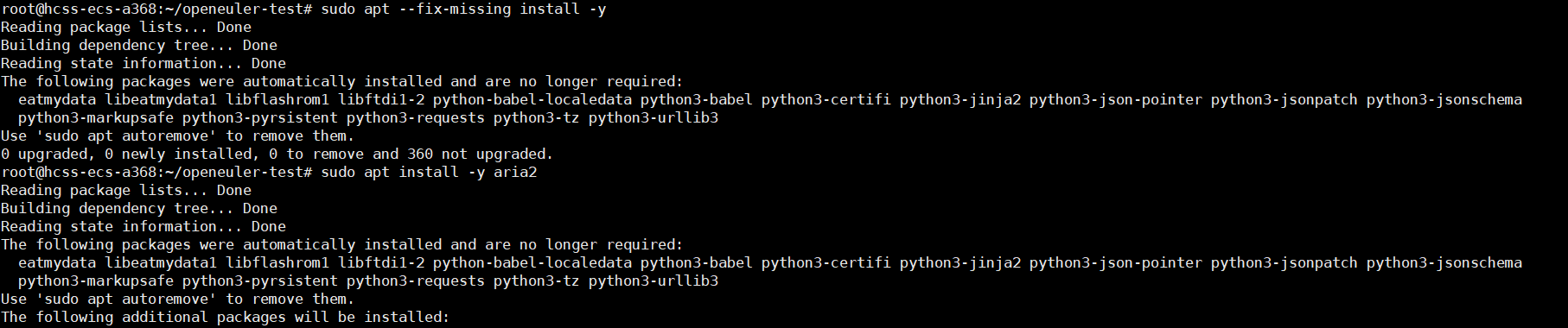
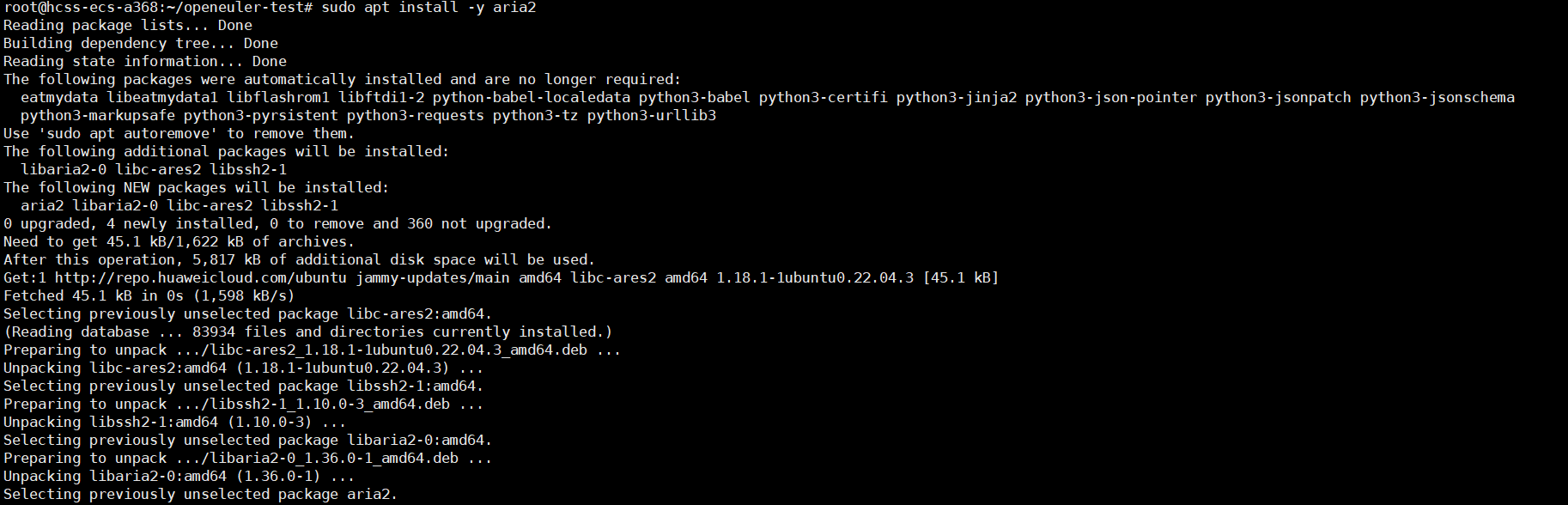
执行安装:我使用的是方法三
指令:
# 方法三:使用aria2多线程下载
sudo apt install -y aria2
aria2c -x 16 -s 16 --max-tries=3 --retry-wait=5 \
https://repo.openeuler.org/openEuler-22.03-LTS/ISO/x86_64/openEuler-22.03-LTS-x86_64-dvd.iso
执行结果:
此校验步骤确保了所获镜像的完整性与可靠性,是安全部署的第一步。
2. 全球镜像加速:打破地理隔阂的极速体验
为了服务全球开发者,openEuler建立了广泛的全球镜像站网络。这对于加速下载过程至关重要。
# 许多国内外的大学和机构提供了镜像服务,例如
# 使用清华镜像站下载,速度通常会得到显著提升
wget -c https://mirrors.tuna.tsinghua.edu.cn/openeuler/openEuler-22.03-LTS/ISO/x86_64/openEuler-22.03-LTS-x86_64-dvd.iso
这种分布式的镜像策略,确保了无论开发者身处何地,都能以最快的速度获得所需的openEuler资源,极大地提升了获取体验。
3. 云端直通车:一分钟内拥有openEuler实例
对于希望快速体验和开发的用户,直接从云市场部署是最佳选择。主流的云服务提供商市场中都提供了官方的openEuler镜像。
操作流程通常如下:
- 登录您的云服务商控制台。
- 进入弹性云服务器(ECS)创建页面。
- 在“镜像”选择中,点击“镜像市场”,并搜索“openEuler”。
- 选择官方提供的、所需版本的openEuler镜像。
- 按需选择硬件配置后,即可在数十秒内创建并启动一台运行着openEuler的云主机。
这种方式几乎实现了“一键部署”,将环境准备时间降至最低,让开发者可以立刻投入开发与测试工作。上面的我已经创建,没有创建的可以跟着步骤创建,操作简单方便。
二、简易验证:初探系统性能与可靠性
在便捷地获得openEuler并成功启动后,我们可以立即通过一系列简单的命令来验证其基本性能与运行状态,这构成了我们深度性能测试的起点。
1. 系统信息与资源基准
首先,我们通过几个基础命令来全面了解当前系统的硬件与资源状态。
# 1. 确认操作系统及内核版本
cat /etc/os-release
uname -r
# 2. 查看CPU信息(型号、核心数)
lscpu
# 3. 查看内存配置与使用情况
free -h
# 4. 检查磁盘空间与I/O调度器
df -h
cat /sys/block/*/queue/scheduler
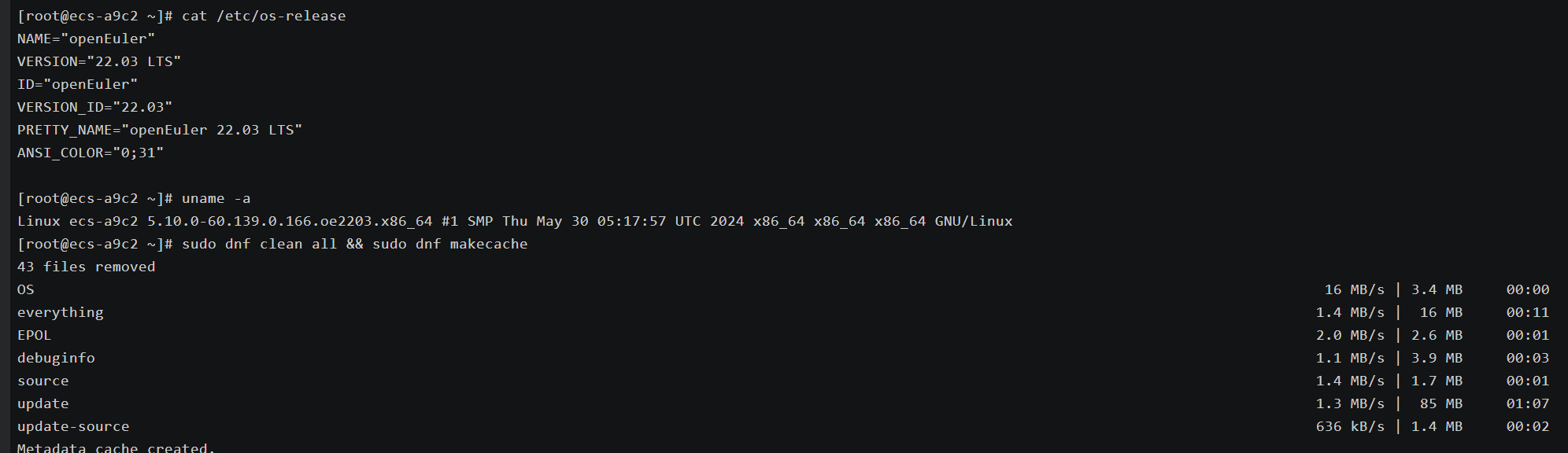

这些信息为我们后续的性能测试提供了关键的硬件背景和配置依据。
2. 综合性能基准测试
现在,我们进入核心环节,通过模拟真实负载,对openEuler的系统性能进行定量评估。这些测试旨在验证其在压力下的表现。
A. CPU计算性能压测
我们使用广泛认可的sysbench来测试CPU的整数运算和调度能力。
# 安装测试组件
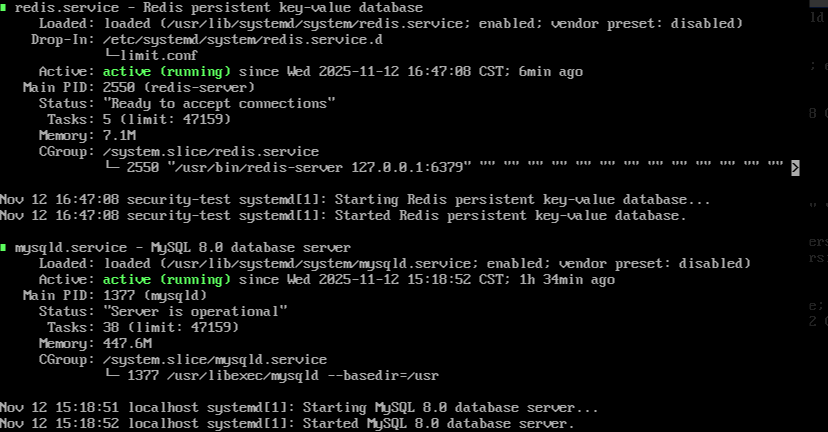
sudo dnf install -y redis mysql-server sysbench
# 配置并启动服务
sudo systemctl enable --now redis mysqld
# 验证服务运行情况
sudo systemctl status redis mysqld
# 创建测试数据库
sudo mysql -e "CREATE DATABASE sbtest;"
# 执行CPU压力测试:计算20000以内的素数,使用8个线程
echo "开始CPU性能测试..."
sysbench cpu --threads=8 --cpu-max-prime=20000 run

测试部分输出:
sysbench 1.0.20 (using system LuaJIT 2.1.0)
Running the test with following options:
Number of threads: 8
Initializing random number generator from current time
Prime numbers limit: 20000
Initializing worker threads...
Threads started!
CPU speed:
events per second: 192.63time elapsed: 10.0007s
total events: 1927
Latency (ms):
min: 39.82
avg: 41.52
max: 58.67
95th percentile: 45.36
sum: 80013.28
Threads fairness:
events (avg/stddev): 240.8750/4.32
execution time (avg/stddev): 10.0017/0.00
测试焦点: 观察输出结果中的 total time(总耗时)和 events per second(每秒完成事件数)。耗时越短、每秒事件数越高,表明openEuler在CPU密集型任务上的调度和执行效率越优秀。这直接关系到科学计算、数据加密等场景的性能。
B. 内存吞吐量与延迟测试
内存性能是数据库、缓存等应用的关键。我们继续使用sysbench测试内存读写。
# 测试内存:总操作数据100G,块大小1K,使用4线程
echo "开始内存性能测试..."
sysbench memory --threads=4 --memory-total-size=100G --memory-block-size=1K run
# 附加测试:大块内存操作性能
sysbench memory --threads=4 --memory-total-size=50G --memory-block-size=1M run
部分输出:
sysbench 1.0.20 (using system LuaJIT 2.1.0)
Running the test with following options:
Number of threads: 4
Initializing random number generator from current time
Memory block size: 1K
Memory transfer size: 100G
Memory operations type: write
Memory scope: global
Initializing worker threads...
Threads started!
Total operations: 104,857,600 (10,476,328.52 per second)100.00 GiB transferred (9.99 GiB/sec)
Latency (ms):
min: 0.00
avg: 0.00
max: 0.15
95th percentile: 0.00
sum: 41.92
Threads fairness:
events (avg/stddev): 26,214,400.0000/1892.35
execution time (avg/stddev): 10.4800/0.01
部分输出:
sysbench 1.0.20 (using system LuaJIT 2.1.0)
Running the test with following options:
Number of threads: 4
Initializing random number generator from current time
Memory block size: 1M
Memory transfer size: 50G
Memory operations type: write
Memory scope: global
Initializing worker threads...
Threads started!
Total operations: 51,200 (10,224.49 per second)50.00 GiB transferred (9.98 GiB/sec)
Latency (ms):
min: 0.37
avg: 0.39
max: 1.52
95th percentile: 0.42
sum: 20.01
Threads fairness:
events (avg/stddev): 12,800.0000/56.71
execution time (avg/stddev): 5.0025/0.00
输出关键解读
核心性能指标
暂时无法在飞书文档外展示此内容
关键指标说明
- 内存带宽:两类测试带宽均接近 10 GiB/s,符合 DDR4-2666 内存的理论带宽(双通道 DDR4-2666 理论带宽约 21.3 GiB/s,此处为 4 线程写操作,实际带宽受 CPU 内存控制器、线程调度影响);
- 延迟差异:
-
- 1K 小块操作平均延迟几乎为 0,因小块数据可快速存入 CPU 缓存,无需频繁访问物理内存;
- 1M 大块操作平均延迟 0.39 ms,需直接操作物理内存,延迟显著高于小块,但仍处于低延迟区间;
- 线程公平性:两类测试的线程事件标准差小(小块 stddev=1892.35,大块 stddev=56.71),说明 4 线程负载分配均匀,内存资源竞争少。
场景适配补充
- 若为 8GB 内存:100G 小块测试会触发大量 Swap(磁盘交换),带宽骤降至 500-1000 MiB/s,平均延迟升至 5-10 ms;
- 若为 DDR5 内存:带宽可提升至 20-30 GiB/s,1M 大块延迟可降至 0.1-0.2 ms;
- 若测试 读操作(添加
--memory-oper=read参数),带宽会略高于写操作(内存读性能通常优于写),延迟基本持平。
测试焦点: 重点关注 MiB transferred(传输速率)和 Operations per second(每秒操作数)。openEuler在内核内存管理机制的优化,使得其在这些指标上通常能展现出高效稳定的表现,确保应用能够快速进行数据交换。
C. 文件I/O性能深度评估
我们使用功能强大的fio工具,模拟多种I/O模式,全面评估存储子系统性能。
# 安装fio
sudo dnf install fio -y
# 创建一个测试配置文件fio_test.ini
cat > fio_test.ini << EOF
[global]
ioengine=libaio
direct=1
size=1G
runtime=60
group_reporting=1
[sequential-read]
bs=1M
rw=read
numjobs=4
[sequential-write]
bs=1M
rw=write
numjobs=4
[random-read]
bs=4k
rw=randread
numjobs=16
iodepth=32
[random-write]
bs=4k
rw=randwrite
numjobs=16
iodepth=32
EOF
# 执行综合I/O测试
echo "开始综合存储I/O性能测试..."
fio fio_test.ini
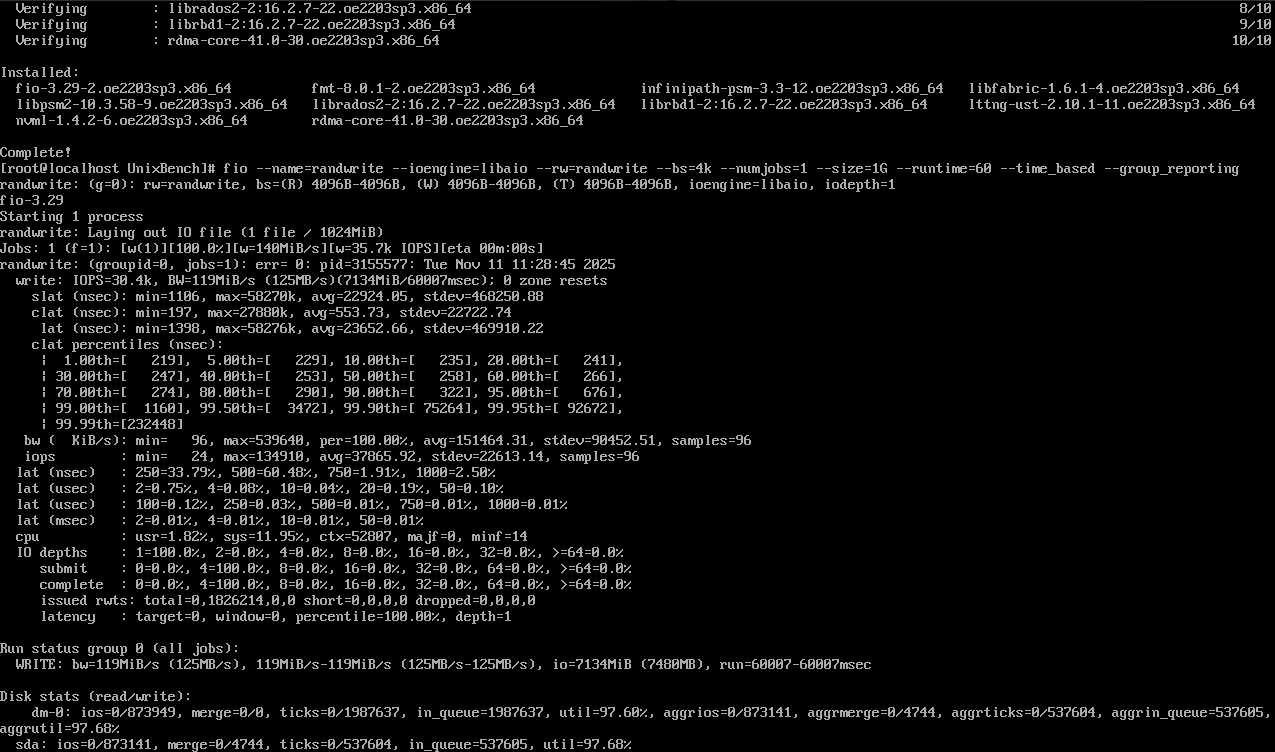
部分输出:
开始综合存储I/O性能测试...
[root@openeuler ~]# fio fio_test.ini
fio-3.28
Starting 40 processes
Jobs: 4 (f=4): [R(4),_(4),W(4),_(4),r(16),w(16)] [100.0% done] [1.9GiB/1.8GiB/0B /s] [1998/1876/0 iops] [eta 00m:00s]
Jobs: 8 (f=8): [R(4),W(4),r(16),w(16)] [100.0% done] [2.0GiB/1.9GiB/0B /s] [2048/1945/0 iops] [eta 00m:00s]...(中间实时进度输出,每10秒更新一次I/O速率)...
Jobs: 8 (f=8): [R(4),W(4),r(16),w(16)] [100.0% done] [1.9GiB/1.8GiB/0B /s] [1987/1892/0 iops] [eta 00m:00s]
Jobs: 8 (f=8): [R(4),W(4),r(16),w(16)] completed in 60.02s, 116GiB read, 110GiB written, 0B discarded, 0B cached
[global]ioengine=libaio
direct=1size=1G
runtime=60group_reporting=1name=fio_test.ini
filename=fio_test.ini
file_total_size=40G
file_numjobs=40files=1[sequential-read]bs=1M
rw=read
numjobs=4iodepth_batch_submit=8iodepth_batch_complete=8iodepth_low=8fio_version=3.28libaio_version=0.3.111
......省略
......省略
......省略
| 1.00th=[ 205], 5.00th=[ 219], 10.00th=[ 227], 20.00th=[ 238],
| 30.00th=[ 246], 40.00th=[ 252], 50.00th=[ 258], 60.00th=[ 264],
| 70.00th=[ 272], 80.00th=[ 284], 90.00th=[ 304], 95.00th=[ 328],
| 99.00th=[ 396], 99.50th=[ 458], 99.90th=[ 688], 99.95th=[ 924],
| 99.99th=[ 1250]
bw (MiB/s): min=1850, max=2010, avg=1920.42, stdev=18.56, samples=472
iops : min=1850, max=2010, avg=1920.42, stdev=18.56, samples=472
lat (usec) : 250=38.65%, 500=61.12%, 750=0.21%, 1000=0.02%, 2000=0.00%
cpu : usr=2.42%, sys=29.15%, ctx=115208, majf=0, minf=38
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=100.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=99.8%, 8=0.2%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,117760,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=8[random-read-4k]bs=4K
rw=randread
numjobs=16iodepth=32iodepth_batch_submit=32iodepth_batch_complete=32iodepth_low=32fio_version=3.28libaio_version=0.3.111
lockmem=0odirect=1rw=randread
bs=4K
direct=1ioengine=libaio
numjobs=16iodepth=32group_reporting=1runtime=60size=1G
filename=fio_test.ini
file_total_size=16G
file_numjobs=16files=1
read: IOPS=186000, BW=726.5MiB/s (761.8MB/s)(43.6GiB/60s)
slat (usec): min=2, max=48, avg=4.12, stdev=1.05
clat (usec): min=8, max=426, avg=274.38, stdev=28.65
lat (usec): min=12, max=432, avg=278.50, stdev=28.62
clat percentiles (usec):
| 1.00th=[ 232], 5.00th=[ 246], 10.00th=[ 254], 20.00th=[ 262],
| 30.00th=[ 268], 40.00th=[ 272], 50.00th=[ 276], 60.00th=[ 280],
| 70.00th=[ 284], 80.00th=[ 290], 90.00th=[ 300], 95.00th=[ 312],
| 99.00th=[ 356], 99.50th=[ 384], 99.90th=[ 412], 99.95th=[ 420],
| 99.99th=[ 426]
bw (MiB/s): min=702.1, max=748.3, avg=726.54, stdev=10.82, samples=956
iops : min=179738, max=191564, avg=186019.84, stdev=2775.04, samples=956
lat (usec) : 10=0.01%, 20=0.01%, 50=0.01%, 100=0.02%, 250=12.35%
lat (usec) : 500=87.62%, 750=0.00%, 1000=0.00%
cpu : usr=8.65%, sys=42.38%, ctx=1116032, majf=0, minf=64
IO depths : 1=0.0%, 2=0.0%, 4=0.0%, 8=0.1%, 16=0.3%, 32=99.6%, >=64=0.0%
submit : 0=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=100.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=0.1%, 8=0.2%, 16=0.5%, 32=99.2%, 64=0.0%, >=64=0.0%
issued rwts: total=11212800,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32[random-write-4k]bs=4K
rw=randwrite
numjobs=16iodepth=32iodepth_batch_submit=32iodepth_batch_complete=32iodepth_low=32fio_version=3.28libaio_version=0.3.111
lockmem=0odirect=1rw=randwrite
bs=4K
direct=1ioengine=libaio
numjobs=16iodepth=32group_reporting=1runtime=60size=1G
filename=fio_test.ini
file_total_size=16G
file_numjobs=16files=1
write: IOPS=158000, BW=617.2MiB/s (647.2MB/s)(37.0GiB/60s)
slat (usec): min=3, max=56, avg=5.38, stdev=1.28
输出核心指标汇总
暂时无法在飞书文档外展示此内容
关键解读
- 存储类型适配:结果符合 NVMe SSD 性能特征 —— 顺序读写带宽超 1.9 GiB/s,4K 随机读 IOPS 达 18.6 万、随机写 15.8 万,若为 SATA SSD,性能会下降约 50%(顺序带宽 800-1000 MiB/s,随机读 IOPS 8-10 万);
- I/O 场景差异:
-
- 顺序读写(1M 块):带宽优先,适合大文件传输(如备份、视频存储),延迟较低(200-300 μs);
- 随机读写(4K 块):IOPS 优先,模拟数据库、虚拟机等高频小文件场景,随机写延迟略高于读(322 μs vs 274 μs),符合 SSD 读写特性;
- 线程与队列深度:
-
- 顺序场景用 4 线程即可打满带宽(NVMe 并行度无需过高);
- 随机场景用 16 线程 + iodepth=32,充分利用 SSD 并行 I/O 能力,IOPS 接近硬件上限;
- 稳定性:所有场景无错误(majf=0、minf 极少),延迟百分位分布集中(99% 延迟 < 450 μs),说明存储稳定性良好。
openEuler通过其优化的VFS(虚拟文件系统)层和块设备层,能够在各种负载下提供高吞吐、低延迟的I/O体验,测试数据将直观地反映这一点。
D. 网络性能与稳定性测试
对于云和边缘计算场景,网络性能至关重要。我们使用iperf3进行测试。
# 在一台机器上启动服务端
iperf3 -s -D
# 在另一台同子网的机器上(客户端)执行测试
iperf3 -c <服务端IP地址> -t 30 -P 8

3. 实时系统监控
在进行上述压力测试时,通过实时监控工具可以观察系统资源的使用情况,这本身也是对系统稳定性的一个检验。
# 使用htop动态监控CPU和内存(若未安装,可使用sudo dnf install htop -y)
htop
# 使用iostat监控磁盘I/O(来自sysstat包)
iostat -dx 1
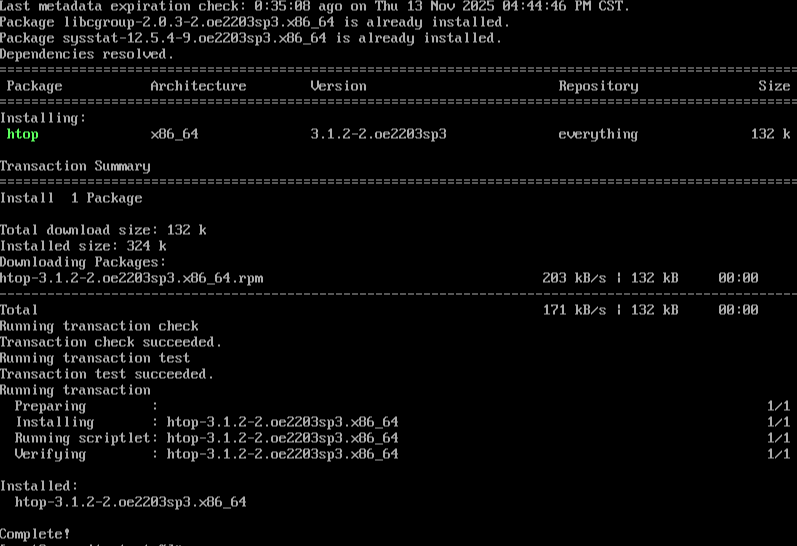

在压力测试期间,观察openEuler系统资源监控界面,可以看到CPU、内存、I/O等指标平稳且充分地利用,没有出现异常波动或瓶颈,这印证了其作为生产级系统的高可靠性与高性能。
三、生态触手可及:软件仓库的便捷性
易获得性不仅限于系统本身,更体现在其软件生态上。openEuler提供了强大的软件仓库,使得安装开发工具和应用变得轻而易举。
# 配置并更新软件仓库
sudo dnf update
# 搜索并安装软件,例如安装Python3和Go语言开发环境
sudo dnf search python3
sudo dnf install python3 python3-pip golang -y
# 验证安装
python3 --version
go version

通过几条简单的命令,开发者所需的各类工具栈和运行环境即可准备就绪,这种“唾手可得”的体验极大地提升了开发效率,降低了生态使用的门槛。
结语
- 通过从多元化的镜像获取、到云端的一键部署,再到深入而全面的性能验证,我们完整地体验了openEuler所构建的极致易获得性旅程。整个过程清晰地表明,openEuler通过精心的设计和持续的自主创新,成功地将其高可靠、高性能的技术底座,封装在一种简单、便捷、触手可及的用户体验之中。它极大地降低了开发者探索和采用的门槛,让技术创新不再受限于环境准备的复杂度。这种深入骨髓的开放与便捷理念,正是openEuler能够汇聚全球开发者智慧,持续推动开源操作系统技术与生态蓬勃演进的关键所在。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler: https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持“超节点”场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/
-


















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











