



LLM研究中的开放挑战
2023年8月16日 • Chip Huyen
在我的一生中,我从未见过如此多的聪明人致力于同一个目标:让大语言模型(LLMs)变得更好。在与工业界和学术界许多人士交谈后,我注意到了出现的十个主要研究方向。前两个方向,幻觉和上下文学习,可能是当今讨论最多的。我对第3(多模态性)、第5(新架构)和第6(GPU替代品)最感兴趣。
1. 减少和测量幻觉
幻觉已经是一个被广泛讨论的话题,所以我将简短说明。当AI模型编造内容时,就会发生幻觉。对于许多创造性用例来说,幻觉是一个特性。然而,对于大多数其他用例,幻觉是一个缺陷。我最近参加了一个关于LLM的专家小组讨论,与会者包括Dropbox、Langchain、Elastics和Anthropic,他们认为公司采用LLM进行生产的主要障碍是幻觉。
减少幻觉并开发衡量幻觉的指标是一个蓬勃发展的研究课题,我已经看到许多初创公司专注于这个问题。还有一些临时的技巧可以减少幻觉,例如在提示中添加更多上下文、链式思维、自我一致性,或者要求模型在回答中简洁明了。
要了解更多关于幻觉的信息:
- 自然语言生成中幻觉的调查 (Ji et al., 2022)
- 语言模型幻觉如何滚雪球 (Zhang et al., 2023)
- 对ChatGPT在推理、幻觉和互动性方面的多任务、多语言、多模态评估 (Bang et al., 2023)
- 对比学习减少对话中的幻觉 (Sun et al., 2022)
- 自我一致性改善语言模型中的链式思维推理 (Wang et al., 2022)
- SelfCheckGPT:零资源黑盒幻觉检测用于生成性大语言模型 (Manakul et al., 2023)
- NVIDIA的NeMo-Guardrails提供了一个简单的事实核查和幻觉检测示例。
2. 优化上下文长度和上下文构建
绝大多数问题都需要上下文。例如,如果我们问ChatGPT:“最好的越南餐厅是哪家?”,所需的上下文是“在哪里”,因为越南最好的越南餐厅与美国最好的越南餐厅是不同的。
根据这篇很酷的论文SituatedQA (Zhang & Choi, 2021),很大一部分信息寻求问题的答案依赖于上下文,例如自然问题NQ-Open数据集中大约有16.5%的比例。就我个人而言,我怀疑这个比例对于企业用例来说会更高。例如,假设一家公司为客户服务构建了一个聊天机器人,为了让这个聊天机器人能够回答任何关于任何产品的客户问题,所需的上下文可能是该客户的历史记录或该产品的信息。
由于模型从提供的上下文中“学习”,这个过程也被称为上下文学习。

上下文长度对于检索增强生成(RAG)——检索增强生成 (Lewis et al., 2020)——尤其重要,它已成为LLM行业用例的主要模式。对于那些尚未被RAG热潮席卷的人来说,RAG的工作分为两个阶段:
阶段1:分块(也称为索引)
- 收集所有你希望你的LLM使用的文档
- 将这些文档分成可以输入到你的LLM中以生成嵌入的块,并将这些嵌入存储在向量数据库中。
阶段2:查询
- 当用户发送查询时,比如“我的保险单是否涵盖这种药物X”,你的LLM将这个查询转换为嵌入,我们称之为QUERY_EMBEDDING
- 你的向量数据库获取与QUERY_EMBEDDING最相似的嵌入的块
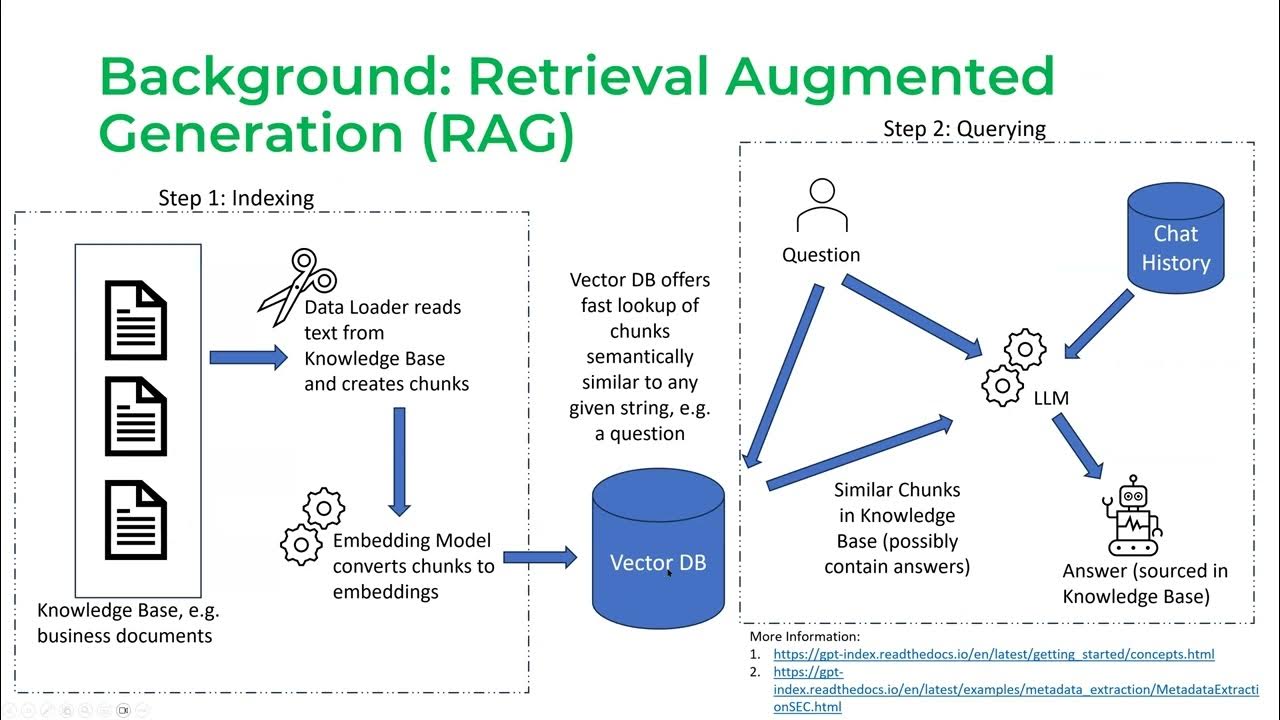
截图来自Jerry Liu关于LlamaIndex的演讲 (2023)
上下文长度越长,我们可以挤进上下文的块就越多。模型可以访问的信息越多,它的回答就会越好,对吧?
不一定。模型可以使用的上下文量以及模型使用它的效率是两个不同的问题。与努力增加模型上下文长度并行的是使上下文更高效的努力。有些人称之为“提示工程”或“提示构建”。例如,最近引起热议的一篇论文是关于模型在索引的开头和结尾理解信息的能力要比在中间好得多——迷失在中间:语言模型如何使用长上下文 (Liu et al., 2023)。
3. 整合其他数据模式
多模态性,我认为,强大而又被低估了。多模态性有很多原因。
首先,在许多用例中需要多模态数据,特别是在那些处理混合数据模式的行业,如医疗保健、机器人技术、电子商务、零售、游戏、娱乐等。例如:
- 通常,医疗预测需要文本(例如医生的笔记、患者的问卷)和图像(例如CT、X光、MRI扫描)。
- 产品元数据通常包含图像、视频、描述,甚至表格数据(例如生产日期、重量、颜色)。你可能希望根据用户的评论或产品照片自动填充缺失的产品信息。你可能希望用户能够使用视觉信息(如形状或颜色)搜索产品。
其次,多模态性有望大幅提升模型性能。一个能够理解文本和图像的模型难道不应该比只能理解文本的模型表现更好吗?基于文本的模型需要如此多的文本,以至于有一个现实的担忧是我们很快就会用完互联网数据来训练基于文本的模型。一旦我们用完了文本,我们就需要利用其他数据模式。
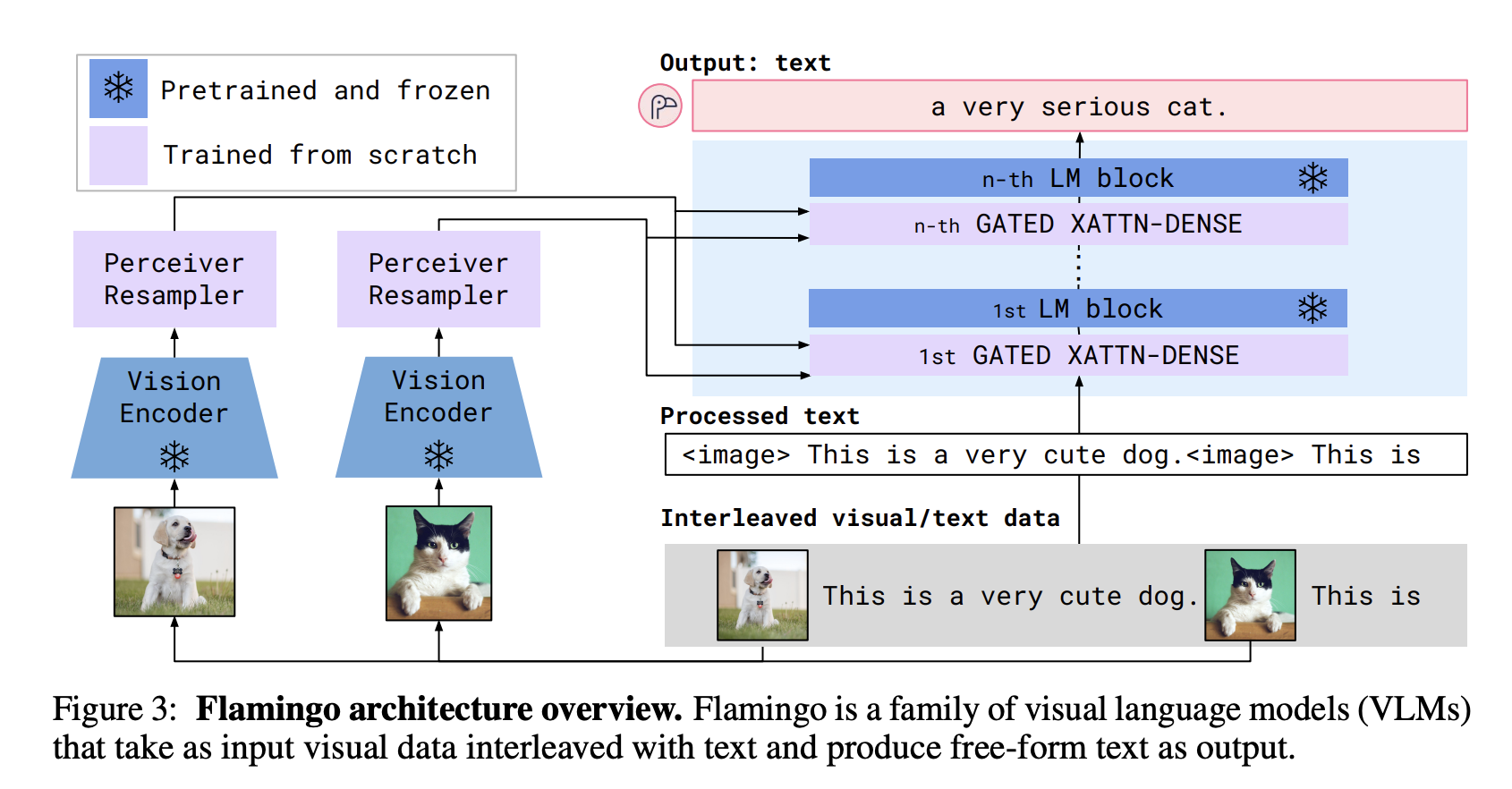 Flamingo架构 (Alayrac et al., 2022)
Flamingo架构 (Alayrac et al., 2022)
一个我特别感兴趣的应用是多模态性可以使视障人士能够浏览互联网并在现实世界中导航。
一些很酷的多模态工作:
- [CLIP] 从自然语言监督中学习可迁移的视觉模型 (OpenAI, 2021)
- Flamingo:一个用于少样本学习的视觉语言模型 (DeepMind, 2022)
- BLIP-2:使用冻结的图像编码器和大型语言模型引导语言-图像预训练 (Salesforce, 2023)
- KOSMOS-1:语言不是全部:对齐感知与语言模型 (Microsoft, 2023)
- PaLM-E:一个具身的多模态语言模型 (Google, 2023)
- LLaVA:视觉指令微调 (Liu et al., 2023)
- NeVA:NeMo视觉和语言助手 (NVIDIA, 2023)
我一直致力于一篇关于多模态性的文章,希望很快能分享出来!
4. 使LLMs更快更便宜
当GPT-3.5在2022年11月下旬首次发布时,许多人对在生产中使用它的延迟和成本表示担忧。然而,从那时起,延迟/成本分析迅速发生了变化。在半年内,社区找到了一种方法,创建了一个在性能上非常接近GPT-3.5的模型,但所需的内存占用仅为GPT-3.5的不到2%。
我的收获是:如果你创造出足够好的东西,人们会找到一种方法让它变得快速和便宜。
| 日期 | 模型 | 参数数量 | 量化 | 微调所需内存 | 可以在…上训练 |
|---|---|---|---|---|---|
| 2022年11月 | GPT-3.5 | 1750亿 | 16位 | 375GB | 许多,许多机器 |
| 2023年3月 | Alpaca 7B | 70亿 | 16位 | 15GB | 游戏台式机 |
| 2023年5月 | Guanaco 7B | 70亿 | 4位 | 6GB | 任何Macbook |
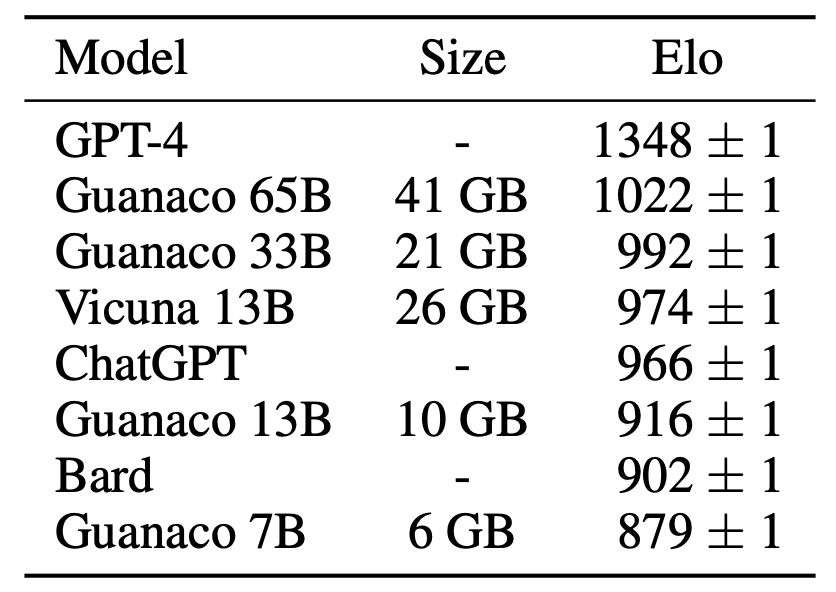
以下是Guanaco 7B与ChatGPT GPT-3.5和GPT-4的性能比较,如Guanaco论文中所报告的。警告:一般来说,性能比较远非完美。LLM评估非常非常困难。
四年前,当我开始撰写后来成为书籍Designing Machine Learning Systems中的模型压缩部分时,我写了四种主要的模型优化/压缩技术:
- 量化:迄今为止最通用的模型优化方法。量化通过使用更少的比特来表示模型的参数来减少模型的大小,例如,不是使用32位来表示一个浮点数,而是只用16位,甚至4位。
- 知识蒸馏:一种方法,其中一个小模型(学生)被训练来模仿一个更大的模型或模型集合(教师)。
- 低秩分解:这里的核心理念是用低维张量替换高维张量以减少参数数量。例如,你可以将一个3x3张量分解为3x1和1x3张量的乘积,这样你就有6个参数而不是9个参数。
- 剪枝
所有这四种技术在今天仍然相关且流行。Alpaca是使用知识蒸馏训练的。QLoRA结合使用了低秩分解和量化。
5. 设计一种新的模型架构
自2012年的AlexNet以来,我们已经看到许多架构流行与过时,包括LSTM、seq2seq。与这些相比,Transformer非常持久。它自2017年以来一直存在。这个架构还能流行多久是一个很大的问号。
开发一种新的架构来超越Transformer并不容易。在过去的6年中,Transformer已经得到了如此多的优化。这种新架构必须在人们今天关心的规模上,在人们关心的硬件上运行。附注:Transformer最初是由谷歌设计的,旨在TPUs上快速运行,只是后来在GPU上进行了优化。
2021年,围绕Chris R的实验室的S4有很多兴奋点——参见Efficiently Modeling Long Sequences with Structured State Spaces (Gu et al., 2021)。我不确定它发生了什么。Chris R的实验室仍然非常致力于开发新的架构,最近与初创公司Together合作开发了他们的架构Monarch Mixer (Fu et al., 2023)。
他们的关键想法是,对于现有的Transformer架构,注意力的复杂性是序列长度的二次方,MLP的复杂性是模型维度的二次方。具有次二次方复杂性的架构会更有效。

我相信许多其他实验室也在研究这个想法,尽管我不知道有任何公开的尝试。如果你知道的任何,请告诉我!
6. 开发GPU的替代品
自2012年的AlexNet以来,GPU一直是深度学习的主导硬件。事实上,AlexNet之所以受欢迎的一个公认的原因是,它是第一篇成功使用GPU训练神经网络的论文。在GPU之前,如果你想训练一个AlexNet规模的模型,你将不得不使用数千个CPU,就像谷歌在AlexNet发布前几个月发布的论文中所述。与数千个CPU相比,几个GPU对于博士生和研究人员来说要容易获得得多,从而引发了深度学习研究的繁荣。
在过去的十年中,许多大公司和小公司都尝试创建用于AI的新硬件。最著名的尝试是谷歌的TPUs、Graphcore的IPUs(IPUs发生了什么?)和Cerebras。SambaNova筹集了超过10亿美元来开发新的AI芯片,但似乎已经转向成为一个生成性AI平台。
有一段时间,人们对量子计算有很多期待,主要参与者有:
- IBM的QPU
- 谷歌的量子计算机在今年早些时候的《自然》杂志上报告了量子错误减少的一个重大里程碑。其量子虚拟机器可以通过Google Colab公开访问
- 研究实验室,如麻省理工学院量子工程中心、马克斯·普朗克量子光学研究所、芝加哥量子交换、橡树岭国家实验室等。
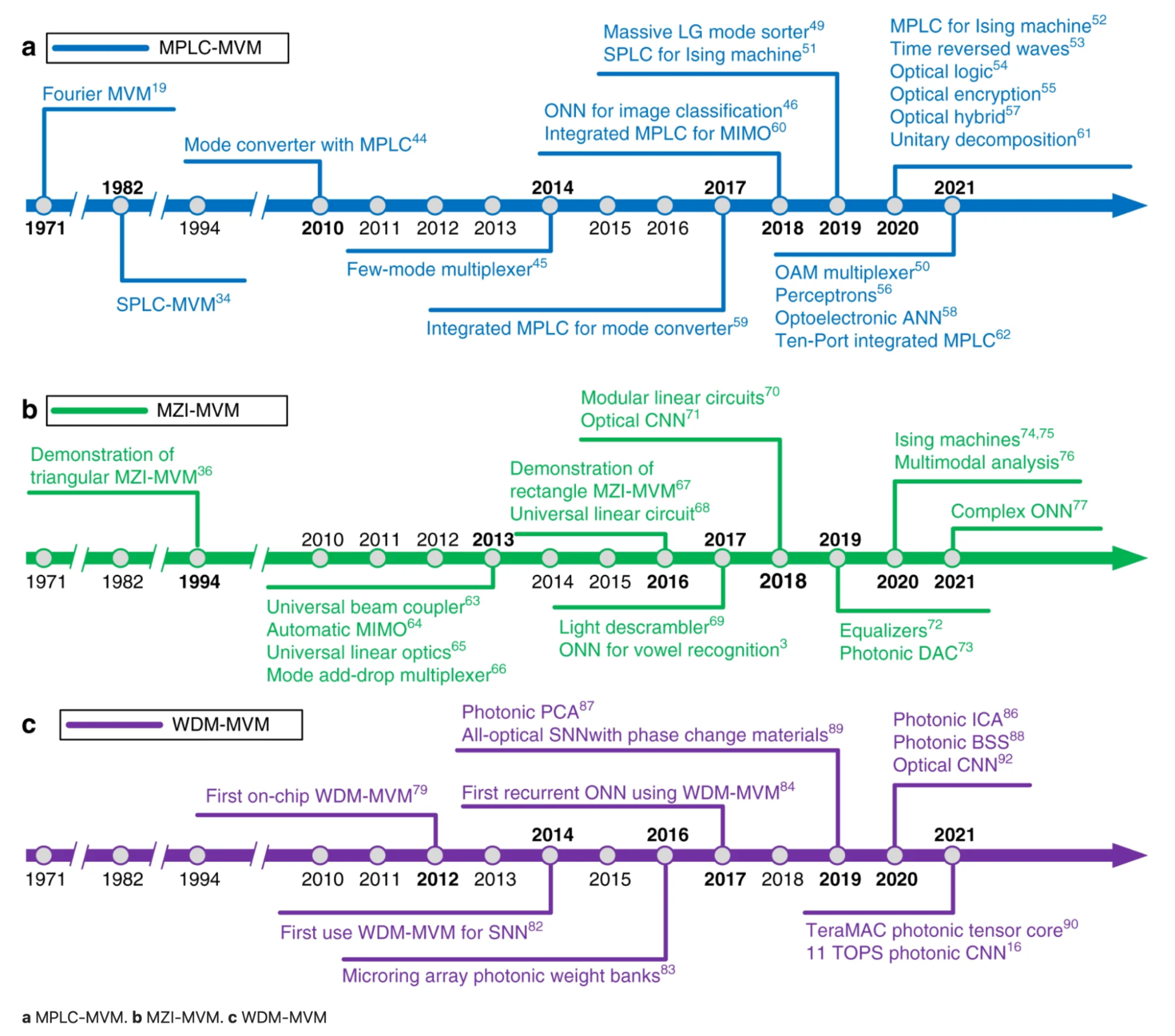
另一个同样令人兴奋的方向是光子芯片。这是我最不了解的方向——所以如果我错了,请纠正我。今天的现有芯片使用电力来移动数据,这消耗了大量电力并产生了延迟。光子芯片使用光子来移动数据,利用光速实现更快、更高效的计算。这个领域的各种初创公司已经筹集了数亿美元,包括Lightmatter(2.7亿美元)、Ayar Labs(2.2亿美元)、Lightelligence(超过2亿美元)和Luminous Computing(1.15亿美元)。
下面是三种主要的光子矩阵计算方法进展的时间线,来自论文Photonic matrix multiplication lights up photonic accelerator and beyond(Zhou等人,《自然》2022年)。三种不同的方法是平面光转换(PLC)、马赫-曾德尔干涉仪(MZI)和波分复用(WDM)。
7. 使代理可用
代理是能够采取行动的LLM,例如浏览互联网、发送电子邮件、进行预订等。与本文中讨论的其他研究方向相比,这可能是最新兴的方向。
由于其新颖性和巨大的潜力,人们对代理有着狂热的迷恋。Auto-GPT现在是GitHub上按星数排名第25位的最受欢迎的仓库。GPT-Engineering是另一个受欢迎的仓库。
尽管有兴奋点,但人们仍然怀疑LLM是否足够可靠和高效,能够被赋予行动的能力。
不过,已经出现的一个用例是使用代理进行社会科学研究,例如著名的斯坦福实验,该实验表明,一个由生成代理组成的小型社会产生了新兴的社会行为:例如,从只有一个用户指定的观念,即一个代理想要举办情人节派对开始,代理们在接下来的两天内自主传播派对的邀请,结识新朋友,互相邀请参加派对……(生成代理:人类行为的互动模拟,Park等人,2023年)
这个领域最著名的初创公司可能是Adept,由两位Transformer的共同作者(尽管两者都已离开)和一个前OpenAI副总裁共同创立,到目前为止已经筹集了将近5亿美元。去年,他们有一个演示,展示他们的代理浏览互联网并将新账户添加到Salesforce。我期待着看到他们新的演示。
8. 改进从人类偏好中学习
RLHF,从人类偏好中进行强化学习很酷,但有点不靠谱。如果人们找到一种更好的方法来训练LLM,我并不会感到惊讶。对于RLHF有很多开放性问题,例如:
1. 如何在数学上表示人类偏好?
目前,人类偏好是通过比较来确定的:人工标注者确定回答A是否优于回答B。然而,它并没有考虑到回答A比回答B好多少。
2. 什么是人类偏好?
Anthropic公司根据三个轴来衡量他们模型回答的质量:有益、诚实和无害。参见宪政AI:通过AI反馈实现无害性(Bai等人,2022年)。
DeepMind试图生成最令大多数人满意的回答。参见微调语言模型以在具有不同偏好的人群中找到共识(Bakker等人,2022年)。
另外,我们希望AI能够采取立场还是希望一个对任何可能引起争议的话题都避而不谈的普通AI?
3. 考虑到文化、宗教、政治倾向等方面的差异,谁的偏好是“人类”偏好?
在获取能够充分代表所有潜在用户的训练数据方面存在很多挑战。
例如,对于OpenAI的InstructGPT数据,没有65岁以上的标注者。标注者主要是菲律宾和孟加拉国人。参见InstructGPT:使用人类反馈训练语言模型以遵循指令(Ouyang等人,2022年)。

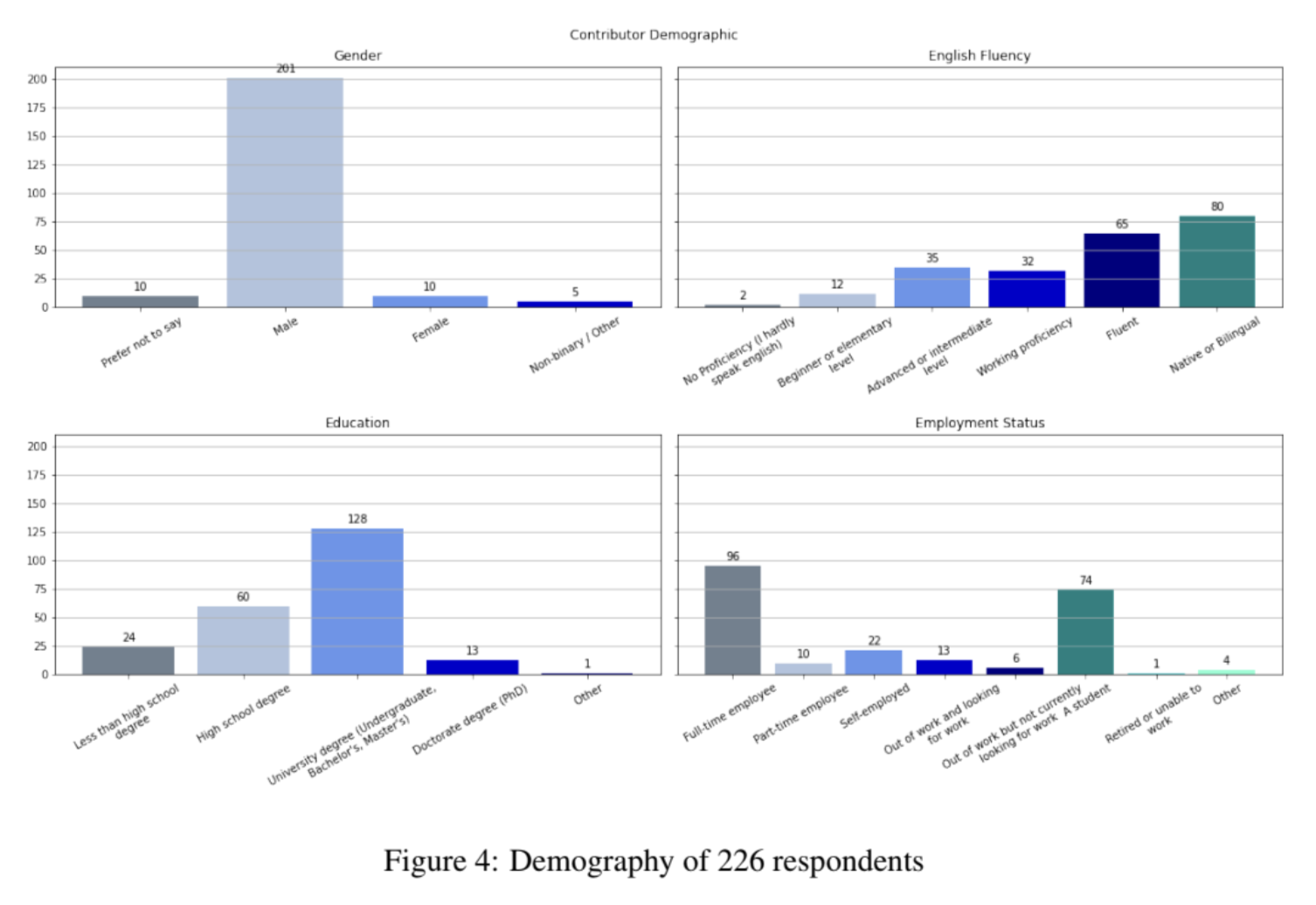
社区主导的努力,虽然在意图上是值得称赞的,但可能会导致数据偏差。例如,对于OpenAssistant数据集,222名受访者中有201名(90.5%)自称为男性。Jeremy Howard在Twitter上有很棒的讨论。参见Twitter讨论。
9. 改进聊天界面的效率
自从ChatGPT以来,关于聊天是否适合各种任务的讨论有很多。
- 自然语言是懒惰的用户界面(Austin Z. Henley,2023年)
- 为什么聊天机器人不是未来(Amelia Wattenberger,2023年)
- 哪些类型的问题需要通过对话来回答?以AskReddit问题为例的案例研究(Huang等人,2023年)
- AI聊天界面可能成为阅读文档的主要用户界面(Tom Johnson,2023年)
- 与LLMs互动时尽量减少聊天(Eugene Yan,2023年)
然而,这并不是一个新讨论。在许多国家,特别是在亚洲,聊天作为超级应用的界面已经使用了大约十年。Dan Grover早在2014年就进行了这个讨论。
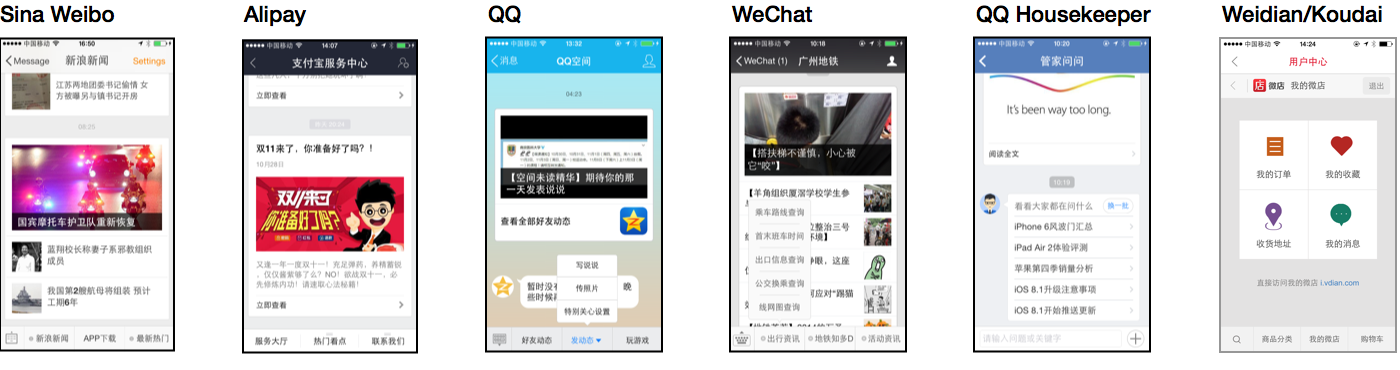 聊天作为中国应用通用界面(Dan Grover,2014年)
聊天作为中国应用通用界面(Dan Grover,2014年)
讨论在2016年再次变得紧张,当时许多人认为应用已经死了,聊天机器人将是未来。
- 关于聊天作为界面(Alistair Croll,2016年)
- 聊天机器人趋势是一个大误解吗?(Will Knight,2016年)
- 机器人不会取代应用。更好的应用会取代应用(Dan Grover,2016年)
就我个人而言,我喜欢聊天界面,原因如下:
- 聊天是一个每个人,甚至是没有接触过电脑或互联网的人都能快速学会使用的界面。当我在2010年代初期在肯尼亚的一个低收入住宅区(我们可以说是贫民窟吗?)做志愿者时,我被那里每个人通过短信在手机上做银行业务的舒适度所震撼。那个社区里没有人有电脑。
- 聊天界面是可访问的。如果你的手很忙,你可以使用语音而不是文本。
- 聊天也是一个非常强大的界面——你可以提出任何请求,它都会给出回答,即使回答不是很好。
然而,我认为聊天界面在某些方面可以改进。
-
每轮多则消息
目前,我们基本上假设每轮只有一条消息。这不是我和我朋友们的短信方式。通常,我需要多则消息来完成我的想法,因为我需要插入不同的数据(例如图像、位置、链接),我在之前的消息中忘记了某事,或者我只是不想把一切都放进一个巨大的段落中。
-
多模态输入
在多模态应用的领域中,大多数精力都花在了构建更好的模型上,而很少花在构建更好的界面上。以Nvidia的NeVA聊天机器人为例。我不是UX专家,但我怀疑这里可能有UX改进的空间。
P.S.对NeVA团队说声抱歉,即使有这样的界面,你们的工作还是很棒的!
-
将生成性AI整合到你的工作流程中
Linus Lee在他的演讲生成AI界面超越聊天中很好地涵盖了这一点。例如,如果你想询问关于你正在处理的图表中某一列的问题,你应该能够指向那列并提出问题。
-
编辑和删除消息
用户输入的编辑或删除会如何改变与聊天机器人的对话流程?
10. 为非英语语言构建LLMs
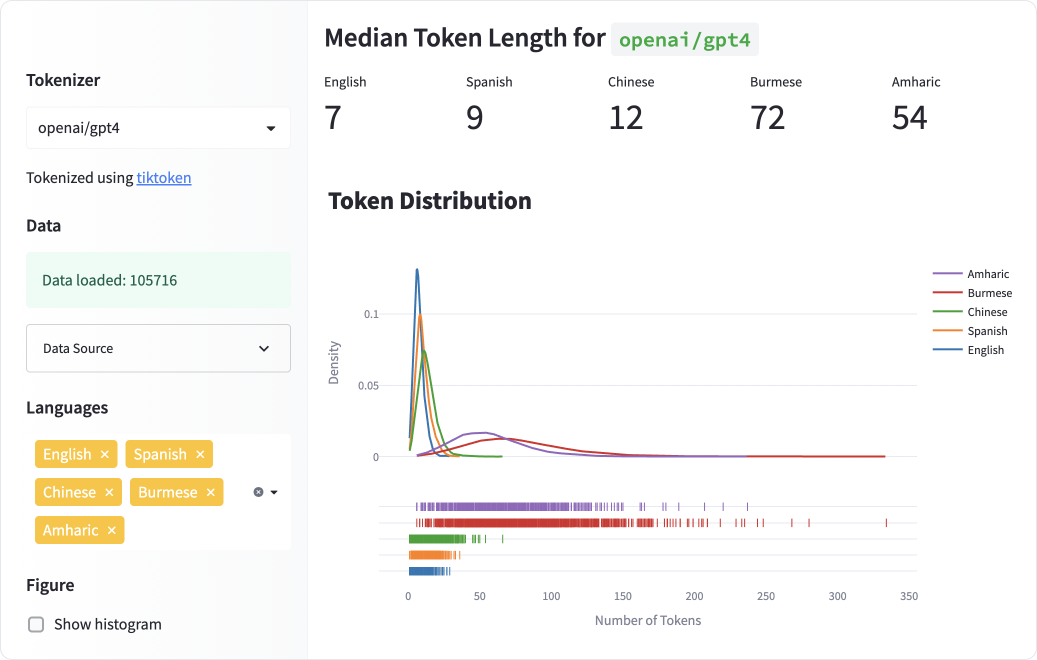
我们知道,当前的以英语为先的LLMs对于许多其他语言来说都不好用,无论是在性能、延迟和速度方面。参见:
- ChatGPT超越英语:全面评估多语言学习中的大型语言模型(Lai等人,2023年)
- 所有语言都不是(被标记)平等的(Yennie Jun,2023年)
以下是我所知道的一些举措。如果你有其他指向,我愿意在这里加入它们。
- Aya:一个加速多语言AI进展的开源科学倡议
- Symato:越南语ChatGPT
- Cabrita:使用葡萄牙语数据微调InstructLLaMA
- Luotuo-Chinese-LLM
- Chinese-LLaMA-Alpaca
- Chinese-Vicuna
一些早期读者告诉我,他们认为我不应该包括这个方向,原因有两个。
- 这不是一个研究问题,而是一个后勤问题。我们已经知道如何做。只需要有人投入资金和努力。这并不完全正确。大多数语言被认为是低资源的,例如,它们与英语或中文相比,拥有更少的高质量数据,可能需要不同的技术来训练大型语言模型。参见:
- 低资源语言:过去的工作回顾和未来挑战(Magueresse等人,2020年)
- JW300:一个覆盖广泛的低资源语言平行语料库(Agi等人,2019年)
- 那些更悲观的人认为,在未来,许多语言将会消亡,互联网将分为两种语言的宇宙:英语和普通话。这种思想流派并不新鲜——有人记得Esperando吗?
AI工具(例如机器翻译和聊天机器人)对语言学习的影响仍然不清楚。它们是会帮助人们更快地学习新语言,还是会完全消除学习新语言的需求?
结论
哇,有这么多的论文要引用,我毫不怀疑我仍然错过了一大堆。如果有你认为我遗漏的地方,请告诉我。
要查看另一个视角,请查看这篇全面的论文大型语言模型的挑战和应用(Kaddour等人,2023年)。
上述一些问题比其他问题更难。例如,我认为第10点,为非英语语言构建LLMs,只要有足够的时间和资源,会更容易。
第1点,减少幻觉,将更难,因为幻觉只是LLMs在做它们概率性的事情。
第4点,使LLMs更快更便宜,将永远不会完全解决。在这个领域已经有如此多的进展,而且还会有更多,但我们永远不会缺少改进的空间。
第5点和第6点,新架构和新硬件,是非常具有挑战性的,但随着时间的推移,它们是不可避免的。由于架构和硬件之间的共生关系——新架构需要为常见的硬件进行优化,硬件需要支持常见的架构——它们可能由同一家公司解决。
这些问题的解决不会只依靠技术知识。例如,第8点,改进从人类偏好中学习,可能更多的是一个政策问题而不是技术问题。第9点,改进聊天界面的效率,更多的是一个UX问题。我们需要更多非技术背景的人与我们合作来解决这些问题。
你最感兴趣的研究方向是什么?你认为解决这些问题的最有希望的解决方案是什么?我很想知道你的看法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









