




庆的密码学课程实验罢了:(
要求:
(1)对于维吉尼亚密码,练习使用密钥对明文进行加密生成密文;
明文:ATTACKATDAWN,密钥:LEMONLEMONLE,密文:LXFOPVEFRNHR。
(2)对于维吉尼亚密码,练习使用密钥对密文进行解密得到明文的操作;
例1:课后习题,对于下面是一段经过维吉尼亚加密的密文,请你找出它的密钥并解密出原文。
密文如下:
CHREEVOAHMAERATBIAXXWTNXBEEOPHBSBQMQEQERBWRVXUOAKXAOSXXWEAHBWGJMMQMNKGRFVGXWTRZXWIAKLXFPSKAUTEMNDCMGTSXMXBTUIADNGMGPSRELXNJELXVRVPRTULHDNQWTWDTYGBPHXTFALJHASVBFXNGLLCHRZBWELEKMSJIKNBHWRJGNMGJSGLXFEYPHAGNRBIEQJTAMRVLCRREMNDGLXRRIMGNSNRWCHRQHAEYEVTAQEBBIPEEWEVKAKOEWADREMXMTBHHCHRTKDNVRZCHRCLQOHPWQAIIWXNRMGWOIIFKEE
例2:选做:课本例题3.12(P59页)
思路:测试重复出现的二个字母的组合:TN,PM,QF,XG,PJ,UCW,JA,JH,WV,
密文如下:
BZGTNPMMCGZFPUWJCUIGRWXPFNLHZCKOAPGLKYJNRAQFIUYRAVGNPANU
MDQOAHMWTGJDXGOMPJPTKAAVZIUIWKVTUCWBWNFWDFUMPJWPMQGPTN
WXTSDPLPMWJAXUHHXWPFXXGVAPFNTXVFKOYIRBOQJHCBVWVFYCGQFGU
SUBDWVIYATJGTBNDKGHCTMTWIUEFJITVUGJHHIMUVJICUWYQWYGGUWPU
UCWIFGWUANILKPHDKOSPJTTWJQOJHXLBJAPZHVQWPDYPGLLGDBCHTGIZCC
MEGVIIJLIFFBHSMEGUJHRXBOG)UBDNASPEUCWNGWSNWXTSDPLPMWJAIUHU
MWPSYCTUWFBMIAMKVBNTDMMIQNBVDKILQSSDYVWVXIGDQFIBHSLEAVDBXG
OLGDBCHTGIZVNFQFKTNGRWX UDCTGKWCOXIXKZPPFDZG
(3)练习针对维吉尼亚密码,使用Kasiski测试确定密钥长度;
(4)Kasiski和重合指数法来确定秘钥长度;
(5)练习使用拟重合指数法确定密钥内容。
实现:
str1 = "CHREEVOAHMAERATBIAXXWTNXBEEOPHBSBQMQEQERBWRVXUOAKXAOSXXWEAHBWGJMMQMNKGRFVGXWTRZXWIAKLXFPSKAUTEMNDCMGTSXMXBTUIA" \
"DNGMGPSRELXNJELXVRVPRTULHDNQWTWDTYGBPHXTFALJHASVBFXNGLLCHRZBWELEKMSJIKNBHWRJGNMGJSGLXFEYPHAGNRBIEQJTAMRVLCRREM" \
"NDGLXRRIMGNSNRWCHRQHAEYEVTAQEBBIPEEWEVKAKOEWADREMXMTBHHCHRTKDNVRZCHRCLQOHPWQAIIWXNRMGWOIIFKEE" # 实验的例一
str2 = "BZGTNPMMCGZFPUWJCUIGRWXPFNLHZCKOAPGLKYJNRAQFIUYRAVGNPANUMDQOAHMWTGJDXGOMPJPTKAAVZIUIWKVTUCWBWNFWDFUMPJWPMQGPTN" \
"WXTSDPLPMWJAXUHHXWPFXXGVAPFNTXVFKOYIRBOQJHCBVWVFYCGQFGUSUBDWVIYATJGTBNDKGHCTMTWIUEFJITVUGJHHIMUVJICUWYQWYGGUWP" \
"UUCWIFGWUANILKPHDKOSPJTTWJQOJHXLBJAPZHVQWPDYPGLLGDBCHTGIZCCMEGVIIJLIFFBHSMEGUJHRXBOGUBDNASPEUCWNGWSNWXTSDPLPMW" \
"JAIUHUMWPSYCTUWFBMIAMKVBNTDMMIQNBVDKILQSSDYVWVXIGDQFIBHSLEAVDBXGOLGDBCHTGIZVNFQFKTNGRWXUDCTGKWCOXIXKZPPFDZG" # 实验的例二
dict_char = {} # 以char为key,num为value
for i in range(65, 91):
dict_char[chr(i)] = i - 65
dict_num = {v: k for k, v in dict_char.items()} # 调转dict_char的键与值
def virginia(k, p='', c=''):
"""
维吉尼亚加解密函数,密钥必须传入,传入明文则通过密钥解码(优先),传入密文则通过密钥加密,需要手动写出具体参数
:param k: 密钥 str
:param p: 明文 str
:param c: 密文 str
:return: 解码结果 str
"""
dict_char = {} # 以char为key,num为value
for i in range(65, 91):
dict_char[chr(i)] = i - 65
dict_num = {v: k for k, v in dict_char.items()} # 调转dict_char的键与值
# 原理:(明文+密钥)%26=密文 <-> 明文=(密文-密钥)%26
if c == '':
for i in range(len(p)):
c += dict_num[(dict_char[p[i]] + dict_char[k[i % len(k)]]) % 26]
return c
elif p == '':
for i in range(len(c)):
p += dict_num[(dict_char[c[i]] - dict_char[k[i % len(k)]]) % 26]
return p
def kasisiki(c):
"""
kasisiki测试法,统计的出现的次数最高的双字符串与它们的出现位置,需要靠你自己来判断gcd
:param c:密文, 二维str列表 [str1,str2,...]
:return: 二维列表,str&int [[x1,x2...],[y1,y2...],...[str_x,str_y...]]
"""
list_returning = [] # 返回值
list_num = [] # 统计每个双字符串出现的频率,简单来说,有许多如CH,TH的字符串它们出现的次数可能是4次,5次,我们只关心出现次数最高的
for i in range(len(c) - 1):
list_num.append(c.count(c[i] + c[i + 1]))
list_char = [] # 假如出现次数最高是5次,那么这里将存放所有出现了5次的双字符
for i in range(len(c) - 1):
if c.count(c[i] + c[i + 1]) == max(list_num) and c[i] + c[i + 1] not in list_char:
list_char.append(c[i] + c[i + 1])
for char in list_char:
list_index = []
for i in range(len(c) - 1):
if c[i] + c[i + 1] == char: # 检测那些双字符出现的位置
list_index.append(i)
list_returning.append(list_index)
return list_returning + [list_char] # 拼接两个列表后返回
def comprehensive_index_method(c):
"""
使用重合指数法求密钥长度
重合指数法:在密文c按照某个长度切割后,对于每一组切割后的密文来说,在其中随机选取两个字符,其相同的可能性接近0.065(每一组都接近0.065)
:param c: 密文 str
:return: 密钥长度 int
"""
list_match = []
for C_len in range(1, len(c)): # 密钥长度最长为密文长度,所以for到len(c)即可
list_str1 = [''] * C_len
for i in range(len(c)): # 按列切割密文
list_str1[i % C_len] += c[i]
list_ans = []
for x in list_str1:
fenmu = len(x) * (len(x) - 1) / 2 # 分母为Cn2,代表所有的可能性
fenzi = 0 # 分子就是在分母的那些情况中,在选取出来的两个字符中有多少是相同的
for i in range(len(x)):
for j in range(i + 1, len(x)): # 双重循环计算所有选取的可能性,i+1是为了去重,避免选择的范围达到n^2的情况
if x[i] == x[j]: # 两个字符相同
fenzi += 1
try: # 这个try解决一个小bug
list_ans.append("%.4f" % (fenzi / fenmu)) # 取4位小数
except ZeroDivisionError: # 当密钥长度超过密文长度的一半是就会出现空列,这时我们直接跳过那一列就行了
pass
# print(f"密钥长度为{C_len}的时候重合指数列表为", list_ans)
D_value = 0 # 这个变量与下面的for用来计算在列表中与0.065有着最小差值的数
for i in list_ans:
D_value += abs(float(i) - 0.065)
# print("与0.065的差值的平均值为:", D_value / len(list_ans))
list_match.append(D_value / len(list_ans))
return list_match.index(min(list_match)) + 1 # 因为是索引值,所以+1
def rate_method(c):
"""
使用频率法(基于单表代换)猜测密钥内容,结果需要你自己判断(感觉没jb用就是了,因为这个方法需要极其大量的密文进行判断,这里一般没用)
:param c: 密文
:return: 各个字母出现的频率 dict {"A":float_A,"B":float_B,...,"Z":float_Z}
"""
# print("\n使用频率法(基于单表代换)猜测密钥内容,在密文中:")
dict_char = {} # 以char为key,num为value
for i in range(65, 91):
dict_char[chr(i)] = i - 65
dict_num = {v: k for k, v in dict_char.items()} # 调转dict_char的键与值
list_temp = []
for i in range(26):
# print(dict_num[i], "出现的次数为:", str1.count(dict_num[i]), "\t频率为:", str1.count(dict_num[i]) / len(str1))
list_temp.append(c.count(dict_num[i]) / len(c))
# print("似乎与英语中字母的出现的频率没有显然的相似性,所以这个方法行不通\n")
for i in dict_num.keys():
dict_char[dict_num[i]] = list_temp[i]
return dict_char
def coincidence_mutual_index_method(c, c_len):
"""
使用重合互指数的方法来求密钥内容
:param c_len: 密钥长度
:param c: 密文 str
:return: 密文内容 str
"""
# 下面的三个字典都是常数
dict_char = {} # 以char为key,num为value
for i in range(65, 91):
dict_char[chr(i)] = i - 65
dict_num = {v: k for k, v in dict_char.items()} # 调转dict_char的键与值
dict_rate_org = {'E': 0.12702, 'T': 0.09056, 'A': 0.08167, 'O': 0.07507, 'I': 0.06966, 'N': 0.06749, 'S': 0.06327,
'H': 0.06094, 'R': 0.05987, 'D': 0.04253, 'L': 0.04025, 'C': 0.02782, 'U': 0.02758, 'M': 0.02406,
'W': 0.02360, 'F': 0.02228, 'G': 0.02015, 'Y': 0.01974, 'P': 0.01929, 'B': 0.01492, 'V': 0.00978,
'K': 0.00772, 'J': 0.00153, 'X': 0.0015, 'Q': 0.00095, 'Z': 0.00074} # 根据统计学中得到现实中的英文字母的频率:
list_str1 = [''] * c_len # 按密钥长度将密文按列切割
for i in range(len(c)):
list_str1[i % c_len] += c[i]
C = '' # 密钥
# print("每一位密钥的重合指数:")
for char in range(len(list_str1)): # char是每一列的密文,所以每次for求出一位密钥
list_rate = []
for num in dict_num.keys():
# new_char是偏移1,2,3...位后的这列密文,如ABD偏移一位变成BCE
new_char = ''
for j in list_str1[char]:
# (明文+密钥)%26=密文 -> 明文=(密文-密钥)%26
new_char += dict_num[(dict_char[j] - num) % 26]
rate_i = 0
for i in dict_char.keys():
# 重要概念!重合指数R = ∑ pi * qi (‘a’ <= i <= ‘z’) p代表现实中自然语言的概率,q表示在位移后的密文中出现的几率
new_rate = new_char.count(i) / len(new_char) # q
org_rate = dict_rate_org[i] # p
rate_i += org_rate * new_rate # 这里就代表p * q
list_rate.append("%.4f" % rate_i) # 统计字母在该列密文中的出现频率
# print(f"第{char}位密钥的重合指数序列:{list_rate}")
list_match = []
for i in list_rate: # 这个for与for后的min用来计算列表中与0.065有着最小的差值的元素,其索引+1就是密钥在dict_num中的key
list_match.append(abs(float(i) - 0.065))
C += dict_num[list_match.index(min(list_match))] # 最外层的for没次只能求出一位密钥,所以要进行拼接
# print(f"上面列表中与0.065的最小差值为:{'%.5f' % min(list_match)},\t是第{list_match.index(min(list_match)) + 1}位,\t是字母:{dict_num[list_match.index(min(list_match))]}")
return C
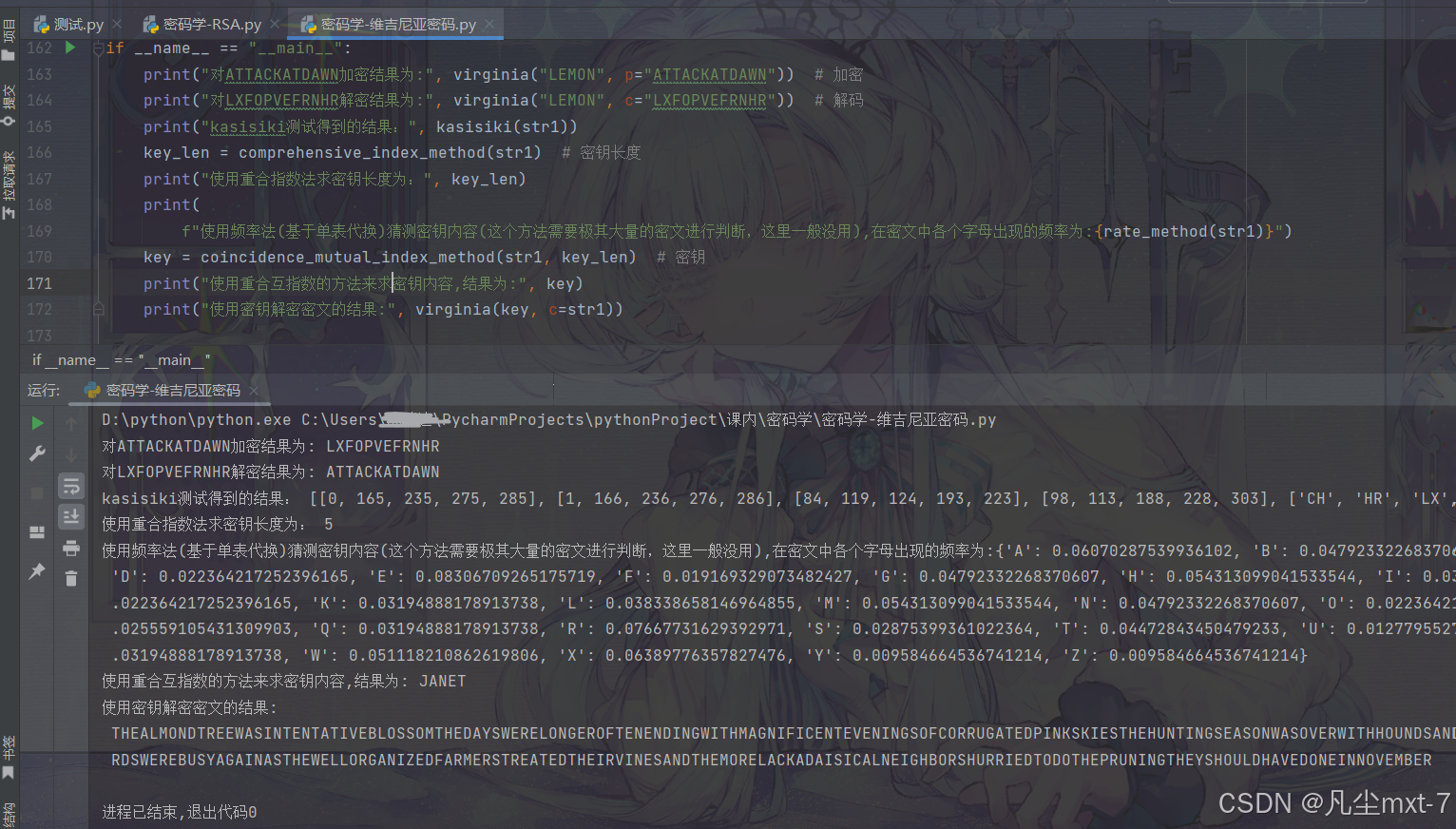
if __name__ == "__main__":
print("对ATTACKATDAWN加密结果为:", virginia("LEMON", p="ATTACKATDAWN")) # 加密
print("对LXFOPVEFRNHR解密结果为:", virginia("LEMON", c="LXFOPVEFRNHR")) # 解码
print("kasisiki测试得到的结果:", kasisiki(str1))
key_len = comprehensive_index_method(str1) # 密钥长度
print("使用重合指数法求密钥长度为:", key_len)
print(
f"使用频率法(基于单表代换)猜测密钥内容(这个方法需要极其大量的密文进行判断,这里一般没用),在密文中各个字母出现的频率为:{rate_method(str1)}")
key = coincidence_mutual_index_method(str1, key_len) # 密钥
print("使用重合互指数的方法来求密钥内容,结果为:", key)
print("使用密钥解密密文的结果:", virginia(key, c=str1))
运行效果图:
有任何问题可向作者提出,庆的同学除外。


















 1257
1257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









