






前言
在上一篇文章中,写了stable diffusion的扩散原理,其中讲到noise predictor可以将将text prompt和depth map作为条件控制来生成图片。而depth map是controlNet根据我们输入的图片生成的。
我在刚学习stable diffusion的时候,我以为controlNet就是U-Net(noise predictor),在后面的学习中才明白这是两码事,那么controlNet到底是什么呢?
ControlNet
ControlNet是一种神经网络,用来处理我们输入的图片,以此更精准的控制图像的生成。这是我输入的图片:

然后生成图片:

controlNet1.1提供了14个模型,除了可以根据图片生成深度图,还可以检测图片边缘和识别人体姿势等。
control_v11p_sd15_canny
control_v11p_sd15_mlsd
control_v11f1p_sd15_depth
control_v11p_sd15_normalbae
control_v11p_sd15_seg
control_v11p_sd15_inpaint
control_v11p_sd15_lineart
control_v11p_sd15s2_lineart_anime
control_v11p_sd15_openpose
control_v11p_sd15_scribble
control_v11p_sd15_softedge
control_v11e_sd15_shuffle
control_v11e_sd15_ip2p
control_v11f1e_sd15_tile
在stable diffusion webui中启用ControlNet,然后选择控制的类型即可。
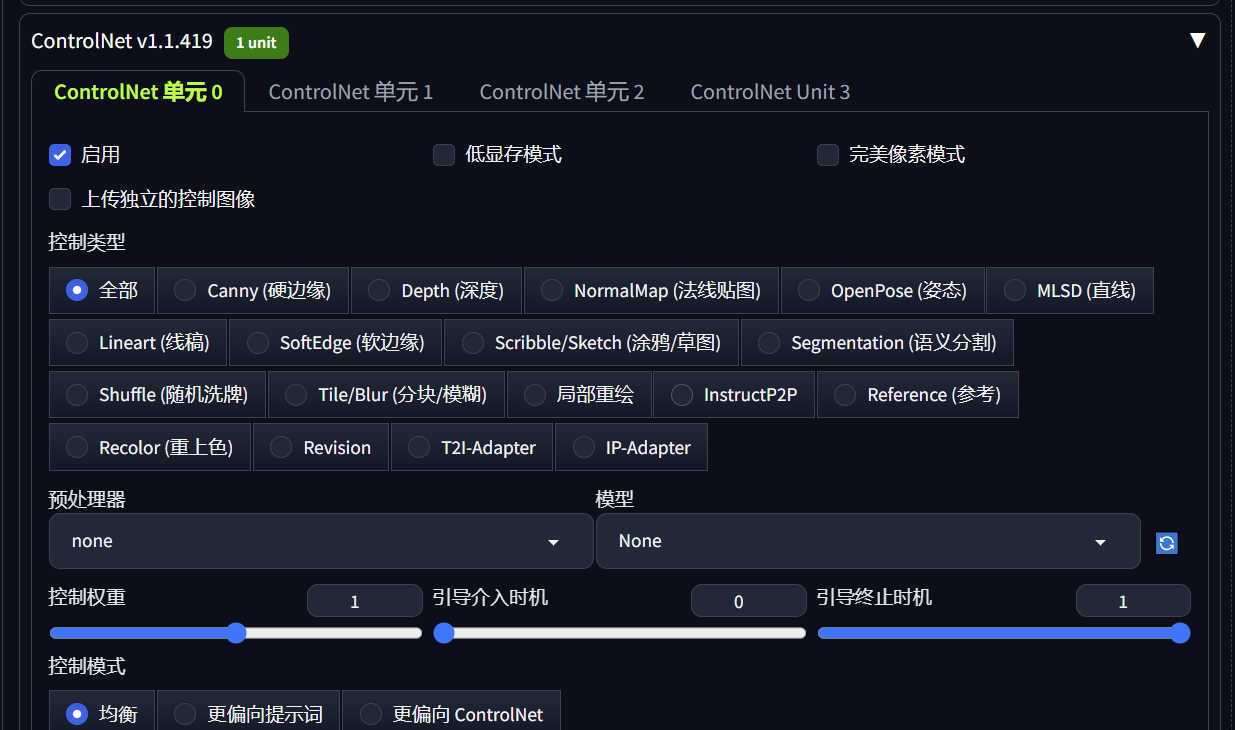
下面的预处理器和模型表示的就是上面列举的controlNet模型,选择控制类型,webui就会显示相应的预处理器和模型。
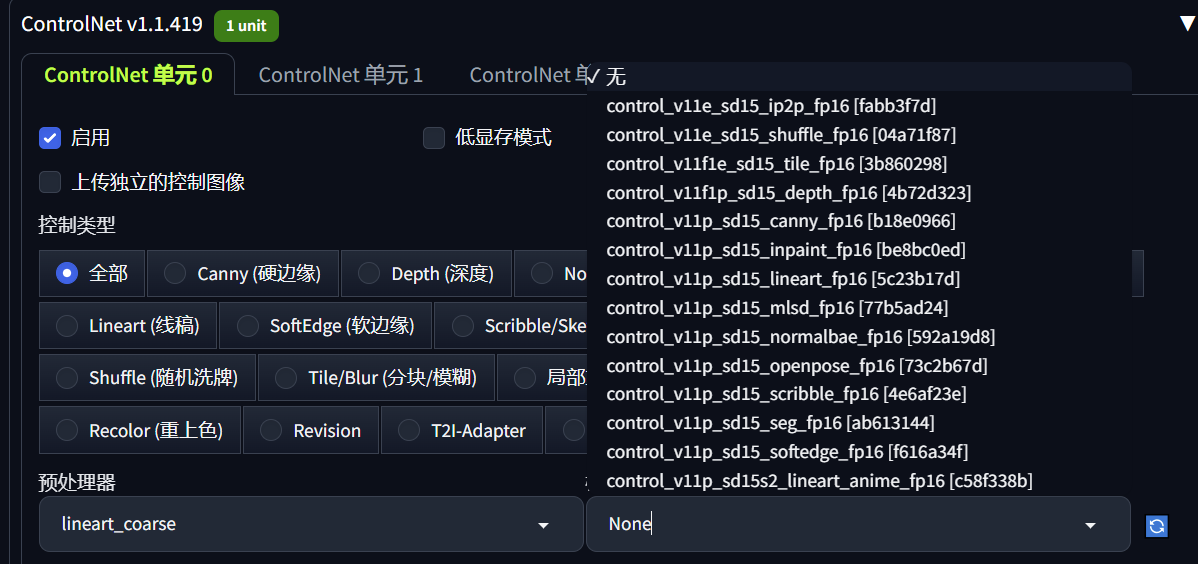
这里就挑选几个比较有代表性的,以上面摩托车图片为例,演示一下controlNet是如何控制图像生成的。这里先看看depth map。
depth map
查了一下资料,depth map是这么解释的:depth map是与编码深度信息的原始图像大小相同的简单灰度图像。完全白色表示对象离您最近。越黑意味着越远。

这就是通过depth的controlNet生成的深度图。然后U-Net会将这个depth map作为控制图片生成的条件。
candy
candy是一个边缘检测的预处理器,可以提取图像的轮廓。

如图,整张图片的轮廓被提取出。
lineart
lineart将白色背景和黑色线条的图像转换为线稿或素描,能较好的还原场景中的线条。

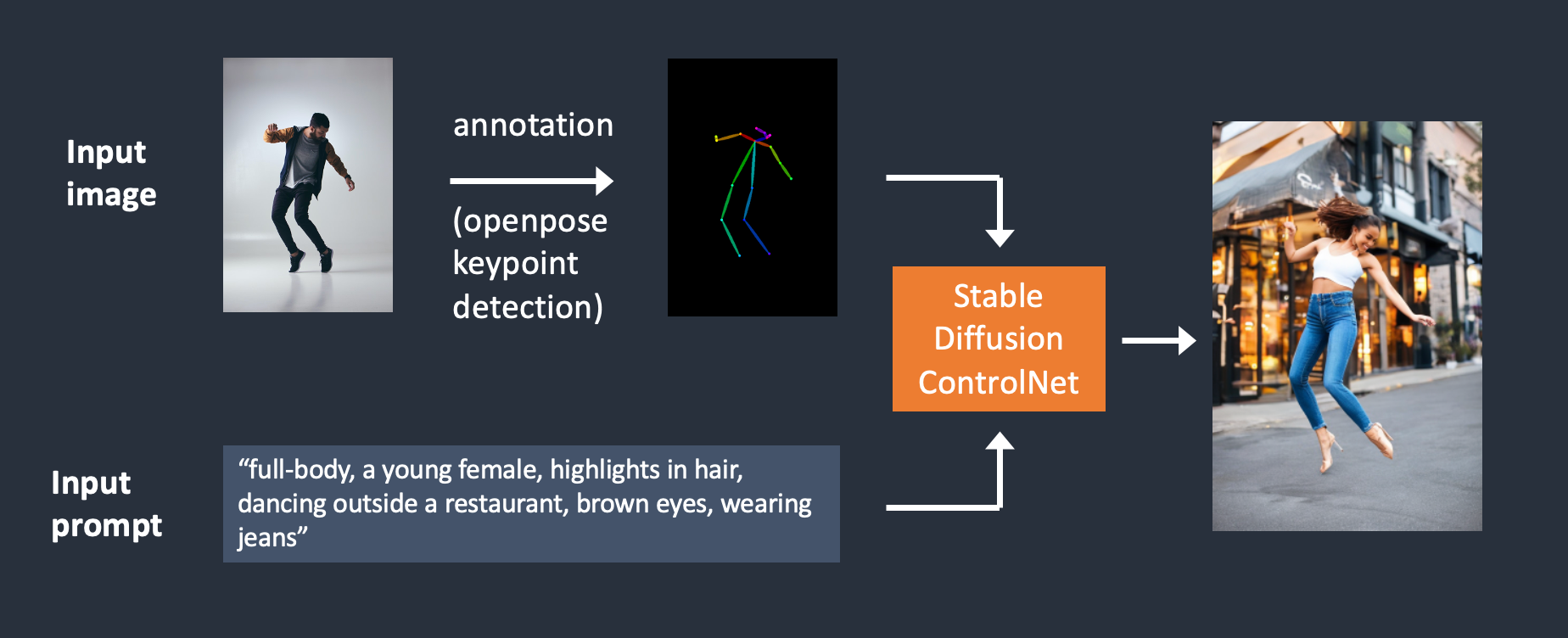
openpose
OpenPose可检测人体关键点,如头部、肩部、手部等的位置。它可用于复制人体姿势,而无需复制服装、发型和背景等其他细节。
通常,openpose用来指定人体姿势、复制其他图片的构图、把涂鸦变成专业形象等。
除此之外,openpose也提供了面部、手部单独的预处理器。

Lineart_anime
Lineart_anime预处理器用于生成动漫风格的线稿或素描,如图所示。

而Lineart_anime_denoise预处理器是在Lineart_anime模型的基础上,进行噪声消除或降噪处理,让线条更明显。

这里就使用Lineart_anime_denoise预处理器来生成图片。
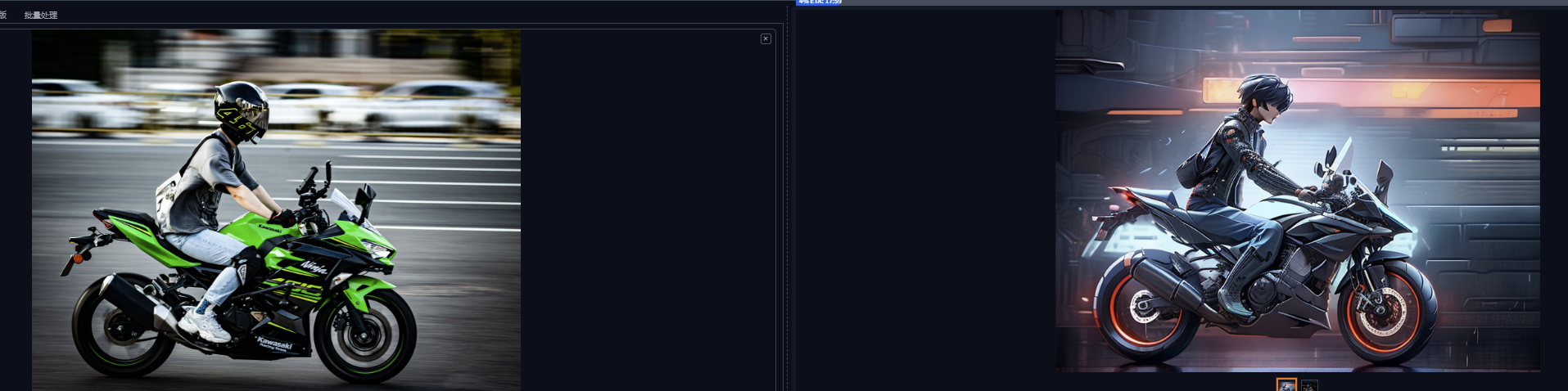


可以看到目标图像是按照我们输入图像来生成的。
结语
使用controlNet提取图片的图像信息,以此来控制输出图片的内容。除此之外,还有几个controlNet模型,有兴趣的可以尝试一下。

















 4691
4691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









