



 本文探讨了如何使用泛型实现数组列表和链表,包括增删查改的基本操作。泛型提供了一种方式来避免重复代码,允许数据结构存储不同类型的元素。在数组列表的实现中,通过Object数组来绕过泛型不能创建数组的限制。链表的实现利用结点结构,提供了更灵活的数据插入性能。文章还对两者进行了性能对比,指出链表在插入操作上的优势。
本文探讨了如何使用泛型实现数组列表和链表,包括增删查改的基本操作。泛型提供了一种方式来避免重复代码,允许数据结构存储不同类型的元素。在数组列表的实现中,通过Object数组来绕过泛型不能创建数组的限制。链表的实现利用结点结构,提供了更灵活的数据插入性能。文章还对两者进行了性能对比,指出链表在插入操作上的优势。
本文将实现容器的基本功能,增删查减,以及泛型的使用,还会对数组列表和链表做性能的对比。
数组列表
泛型
我们知道,数组列表可以是很多种类型的,在写这个方法的时候,如果我们只写了int类的数组列表,那么这个数组列表就只能实现int类的,如果我们下一次想存储String类型的,就必须要重新写一个几乎一模一样的方法,只不过将类型改变了,泛型则很好地解决了这个问题,下面介绍泛型的使用方法
实现泛型其实很简单,在类或者接口名的后面加上尖括号<>,尖括号内可以为任意字符或字符串,代表一个基本类型,我们习惯用E表示元素elements,此外,将可替代基本类型全部改为尖括号里面的元素,代表一个类,以后实现的时候将这个元素改变为要用的类型就好了
增删查改的基本实现
public interface IList<E> {
//添加数据
public void add(E e);
//删除数据
public void delete(int index);
//修改
public void update(int index, E newE);
//获取元素
public E get(int index);
//获取元素个数
public int size();
//添加数组
public void addarray(MyArrayList<E> marraylist);
//插入元素,在index之后
public void insert(E e,int index);
}
提供一个借口,规定方法,之后的数组列表和链表都将实现这个接口。
public class MyArrayList<E> implements IList<E> {
Object[] myarray;
int num=0;
值得注意的是,泛型并不能创建数组对象,我们用Object来替代泛型的功能,Object是所有类的父类,因此可以储存所有类型的元素
// 添加数据
public void add(E e) {
Object newarray[] = new Object[num + 1];
for (int i = 0; i < num; i++) {
newarray[i] = myarray[i];
}
newarray[num] = e;
num++;
myarray = newarray;
}
创建一个新的数组,并让它的长度等于原来的长度+1,然后再把原来的数组值赋给新的数组,加上新的元素后,让原来的数组等于新的数组
// 删除数据
public void delete(int index) {
Object newarray[] = new Object[num - 1];
for (int i = 0; i < index; i++) {
newarray[i] = myarray[i];
}
for (int i = index; i < num-1; i++) {
newarray[i] = myarray[i+1];
}
num--;
myarray = newarray;
}
原理同增加一样
// 修改
public void update(int index, E newE) {
Object newarray[] = new Object[num];
for (int i = 0; i < index; i++) {
newarray[i] = myarray[i];
}
newarray[index] = newE;
for (int i = index + 1; i < num; i++) {
newarray[i] = myarray[i];
}
myarray = newarray;
}
// 获取元素
public E get(int index) {
return (E)myarray[index];
}
// 获取元素个数
public int size() {
return num;
}
// 添加数组
public void addarray(MyArrayList<E> marraylist) {
Object newarray[] = new Object[num + marraylist.num];
for (int i = 0; i < num; i++) {
newarray[i] = myarray[i];
}
for (int i = 0; i <marraylist.num; i++) {
newarray[i+num] = marraylist.get(i);
}
num+=marraylist.num;
myarray = newarray;
Arrays.sort(myarray);
}
// 插入元素,在index之后
public void insert(E e, int index) {
Object newarray[] = new Object[num + 1];
for (int i = 0; i < index; i++) {
newarray[i] = myarray[i];
}
newarray[index] = e;
for (int i = index + 1; i < num+1; i++) {
newarray[i] = myarray[i - 1];
}
num++;
myarray = newarray;
}
链表
结点
在链表中数据的存储不是连续的,数据与数据之间的联系由一个个结点来实现,一个结点中储存着属性信息,也储存着下一个结点。
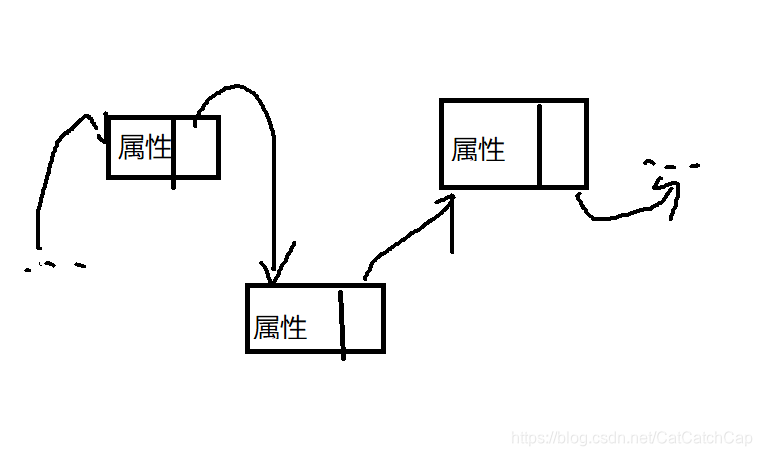
链表的优点
相对于数组列表来说,链表可以很方便地实现新数据的插入,只需要将前一个结点和插入数据的结点连接,然后插入数据结点和后一个结点连接就可以了。而如果数组列表要做这件事的话就必须要将插入点后的数据全部后移一个位置,从性能上来说,链表在插入数据这方面要优于数组列表。
增删查改的实现
public class MyLinkList<E> implements IList<E>{
private class Node<E>{
E e;
Node<E> nextnode;
public Node() {}
public Node(E e) {
this.e=e;
}
}
结点储存数据信息和下一个结点
int size=0;
Node<E> head=new Node<>(),tail=head;
每链表要有头结点和尾结点,初始设置头结点和尾结点都是同一个且为空值
//添加
public void add(E e) {
Node<E> newnode=new Node<>(e);
tail.nextnode=newnode;
tail=newnode;
size++;
}
默认在末尾添加新数据,让原来的尾结点的下一个结点为新节点,让新节点为尾结点
//删除
public void delete(int index) {
Node<E> cur=head.nextnode,pre=head;
for(int i=0;i<index;i++) {
pre=cur;
cur=cur.nextnode;
}
pre.nextnode=cur.nextnode;
size--;
}
//更改
public void update(int index, E newe) {
Node<E> temp=head.nextnode;
for(int i=0;i<index;i++) {
temp=temp.nextnode;
}
temp.e=newe;
}
//获得大小
public int size() {
return size;
}
//添加链表
public void addlist(MyLinkList<E> mll) {
this.tail.nextnode=mll.head.nextnode;
this.tail=mll.tail;
size+=mll.size;
}
//插入新数据
public void insert(E e, int index) {
Node<E> innode=new Node<>(e);
Node<E> pre=head.nextnode,cur=pre.nextnode;
for (int i = 0; i < index; i++) {
pre=cur;
cur=cur.nextnode;
}
pre.nextnode=innode;
innode.nextnode=cur;
size++;
}
//读取链表
public E get(int index) {
Node<E> temp=head.nextnode;
for (int i = 0; i < index; i++) {
temp=temp.nextnode;
}
return temp.e;
}

















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









