



什么是Transformer
一句话: Seq2seq model with self-attention
Seq2seq model
是什么
Seq2Seq(Sequence to Sequence) 指的是一种模型结构,用于 将一个序列映射为另一个序列。
它最初被提出是为了解决 机器翻译 任务,例如:
输入序列(英文句子):“I love cats”
输出序列(中文句子):“我喜欢猫”
基本结构
典型代表:RNN
适合处理输入为序列信息(sequence)
| 模块 | 作用 | 举例 |
|---|---|---|
| Encoder(编码器) | 读取输入序列,并把它压缩成一个上下文向量(context vector) | 把英文句子编码为语义表示 |
| Decoder(解码器) | 逐步生成输出序列,每次根据之前已生成的词和上下文向量预测下一个词 | 根据语义表示生成中文句子 |
1️⃣ Encoder 阶段:
- 输入一个序列 x=[x1,x2,…,xn]x = [x_1, x_2, …, x_n]x=[x1,x2,…,xn]
- 经过循环神经网络(RNN、LSTM、GRU)逐步更新隐藏状态(其实就是模型内部“记忆”,即 内部向量)
- 最后一个隐藏状态
hn被认为是整个句子的语义表示(context vector)
2️⃣ Decoder 阶段:
- Decoder 也是一个 RNN,它在每个时间步根据上一个词和 context vector 生成下一个词
- 不断迭代,直到生成结束符
<EOS>。
缺陷
- **难以并行->**训练速度慢、难以利用 GPU 的并行计算优势
- **长程依赖问题->**梯度衰减(遗忘信息)、爆炸(不稳定):改进 LSTM、GRU
- **信息压缩瓶颈->**Encoder 的最后一个隐藏状态
hn要作为整句的语义总结(context vector)传给 Decoder,面向长句不佳
基础知识解析
1 文字转向量(X to a)
Transformer 接收的输入不是文字,而是一个二维矩阵。
X
∈
R
n
×
d
model
X \in \mathbb{R}^{n \times d_{\text{model}}}
X∈Rn×dmodel
所以第一步要把句子拆分成一个个 Token(最小单位)。
# 句子转Token:分词方式有很多,如 字级分词、词级分词、子词分词(Transformer标准做法)
今天天气不错->[今, 天, 天, 气, 不, 错] # 字级分词
第二步就是将这些Token转为数字。每个 token 都会被查到一个整数 ID(索引),对应词表(vocab)里的位置,于是就可以用数字序列代替句子。
# Token转ID:
vocab:
今 → 1012
天 → 1035
气 → 2345
不 → 765
错 → 990
[今, 天, 天, 气, 不, 错]->[1012, 1035, 1035, 2345, 765, 990]
但是上面得到的数字序列只是一个标签,并没有实际的含义,于是第三步通过 embedding 层 把它们映射到语义空间(高维向量)。
Embedding 是一个可学习矩阵:(语义是在训练过程中理解浮现的,即是经过大量数据喂出来的)
E
∈
R
∣
V
∣
×
d
model
E \in \mathbb{R}^{|V| \times d_{\text{model}}}
E∈R∣V∣×dmodel
∣V∣:词表大小(如 50,000)d_modeld:每个词向量维度(如 512 或 768)
这样就可以把 token转向量:
# 索引转向量
今 → [0.12, -0.34, 0.56, ..., 0.87] # 如,一共 512 维
天 → [0.22, -0.15, 0.78, ..., -0.33]
...
[1012, 1035, 1035, 2345, 765, 990]->[[...512维...], [...512维...], ...] # shape=[6,512]
因为 Transformer 没有循环结构(不像 RNN),它本身不知道词的先后顺序(eg. “今天天气不错” 和 “天气今天不错” 对模型来说可能是同一个序列(不区分顺序))。
所以第四步就是要额外加入一个 位置编码(Positional Encoding)(本质上是一个和转向量后的数据相同shape的向量,比如这里的PE矩阵就是 [6,512],然后让两个矩阵相加),让模型知道“第几个词”。

而这个PE矩阵每个项的值是通过公式算出来的(公式已知且确定,和哈希类似),所以模型想要知道当前分词的位置只需要逆向公式即可。
总流程如下:
“今天天气不错。”
↓ 分词
[今, 天, 天, 气, 不, 错]
↓ 转索引
[1012, 1035, 1035, 2345, 765, 990] → 形状 [6, 1]
↓ 词嵌入
[[...512维...], [...512维...], ...] → 形状 [6, 512]
↓ 加上位置编码PE矩阵
X = [[x1], [x2], ..., [x6]] → 形状 [6, 512]
这个 X 就是送入 Transformer Encoder 的输入矩阵。接下来模型才会对它进行 Q,K,V 映射、注意力计算等步骤。
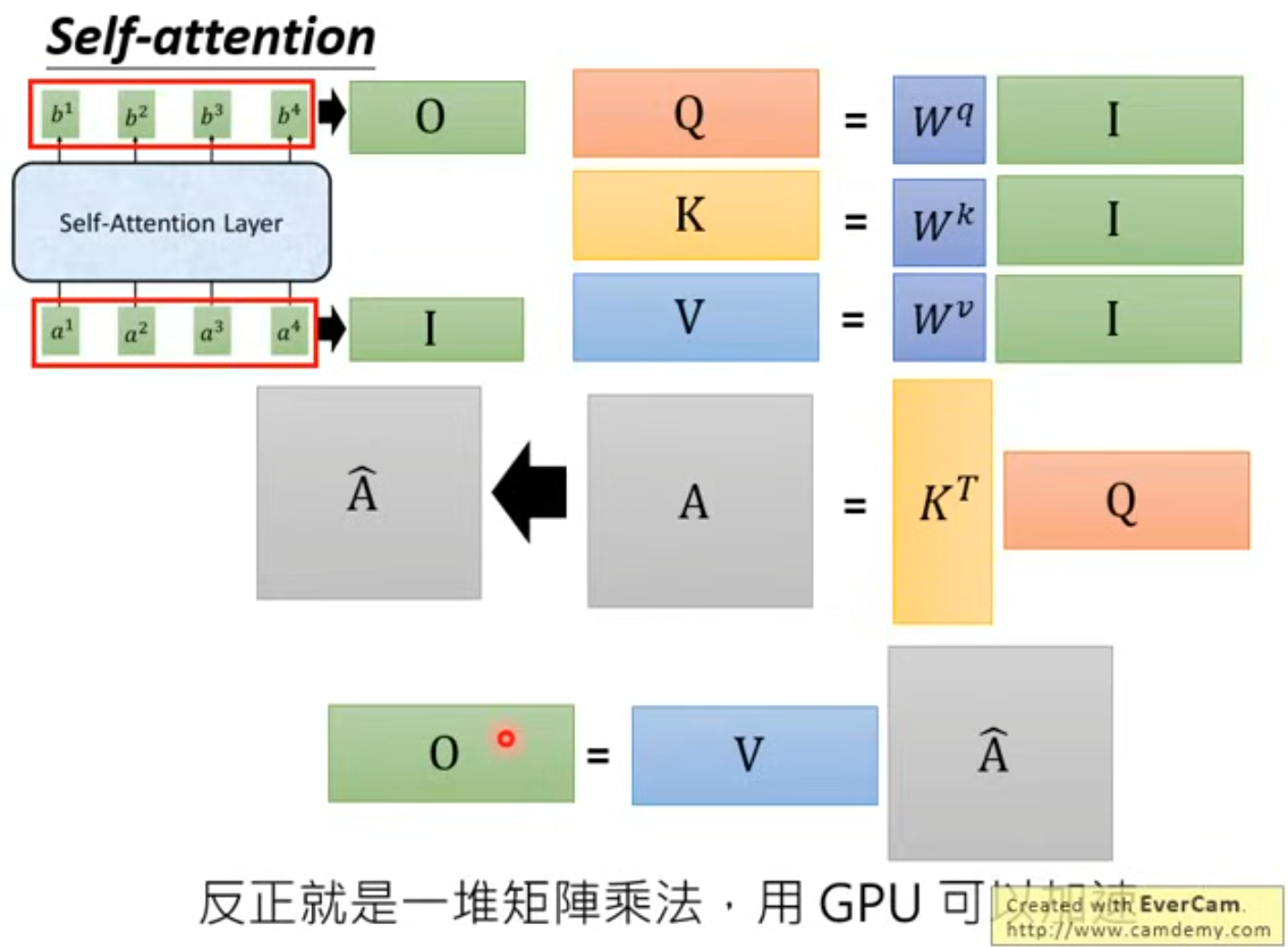
2 Self-attention(a to b)
setp 1 QKV映射
所谓的QKV映射,就是将输入的向量,乘上Wq Wk Wv权重矩阵(都是 可学习参数)
(下面的例子中,4其实就代表上面例子的512)

- ( Q, K, V ):分别是 Query(查询)、Key(键)、Value(值)
在 Transformer 里:
- 每个词都会生成自己的 Q、K、V 向量
- Q 决定它要“查询什么”
- K 决定它“提供什么信息”
- V 是它“具体携带的信息”
step 2 q对k做attention
首先是获取一个中间值 α
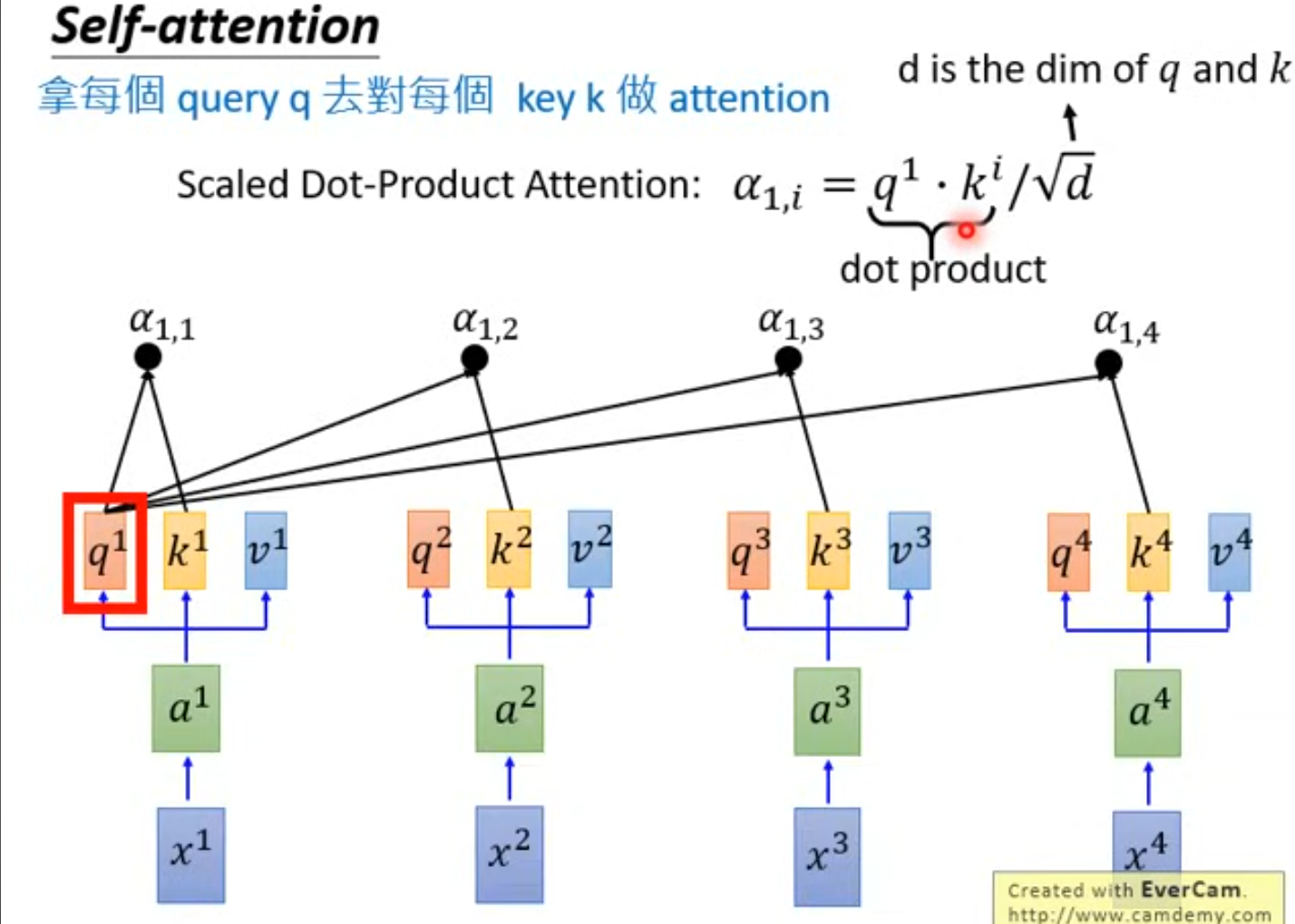
然后是做一个 softmax,得到第二个中间值 α`

最后再将 α` 和 v 相乘,将结果相加,得到 bi
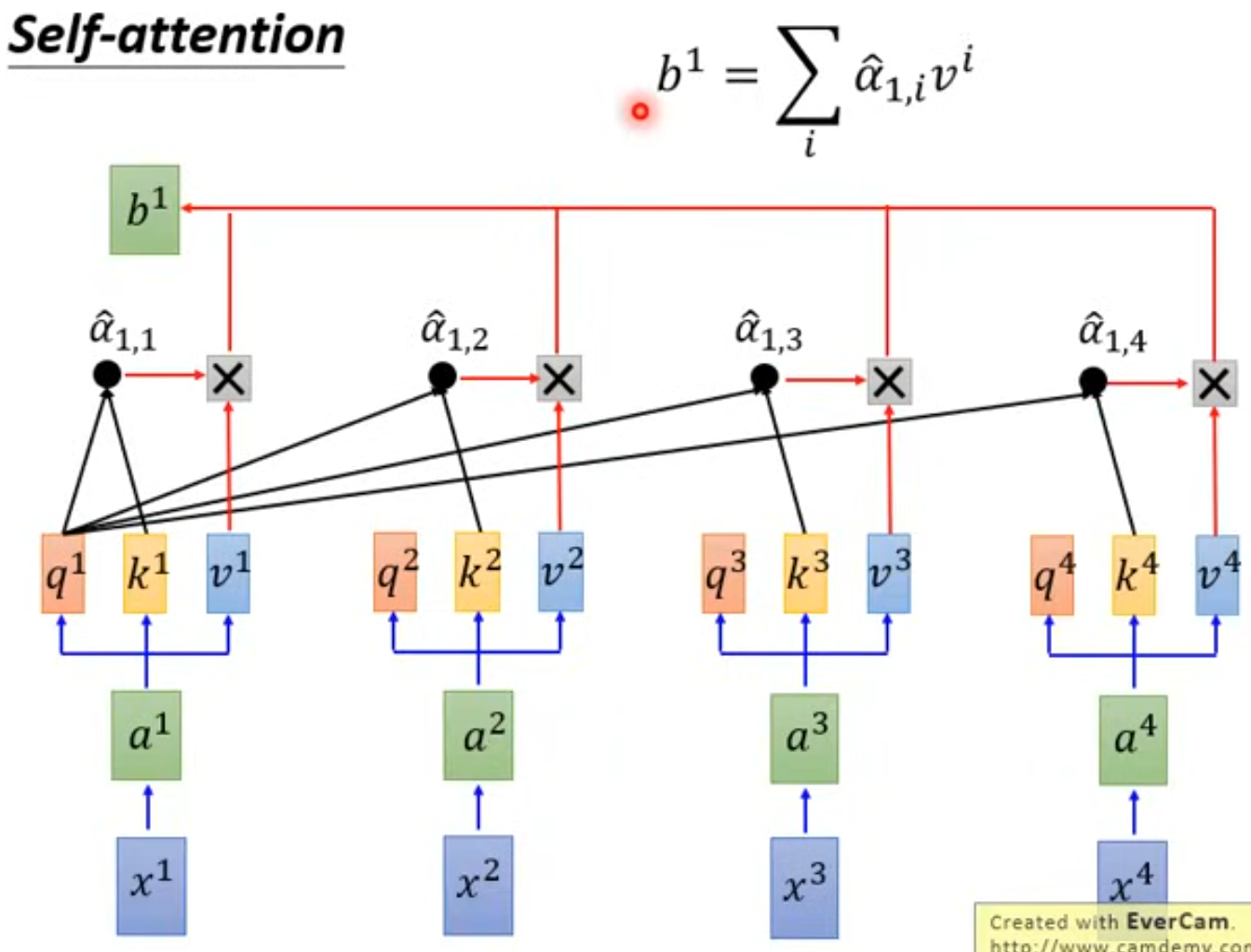
这样其实就可以通过调节 v 的参数,调整模型对任意Token的注意力(比如如果让v3=0,那对x3这个字的关注就会变少)
而且上述过程可以并行:
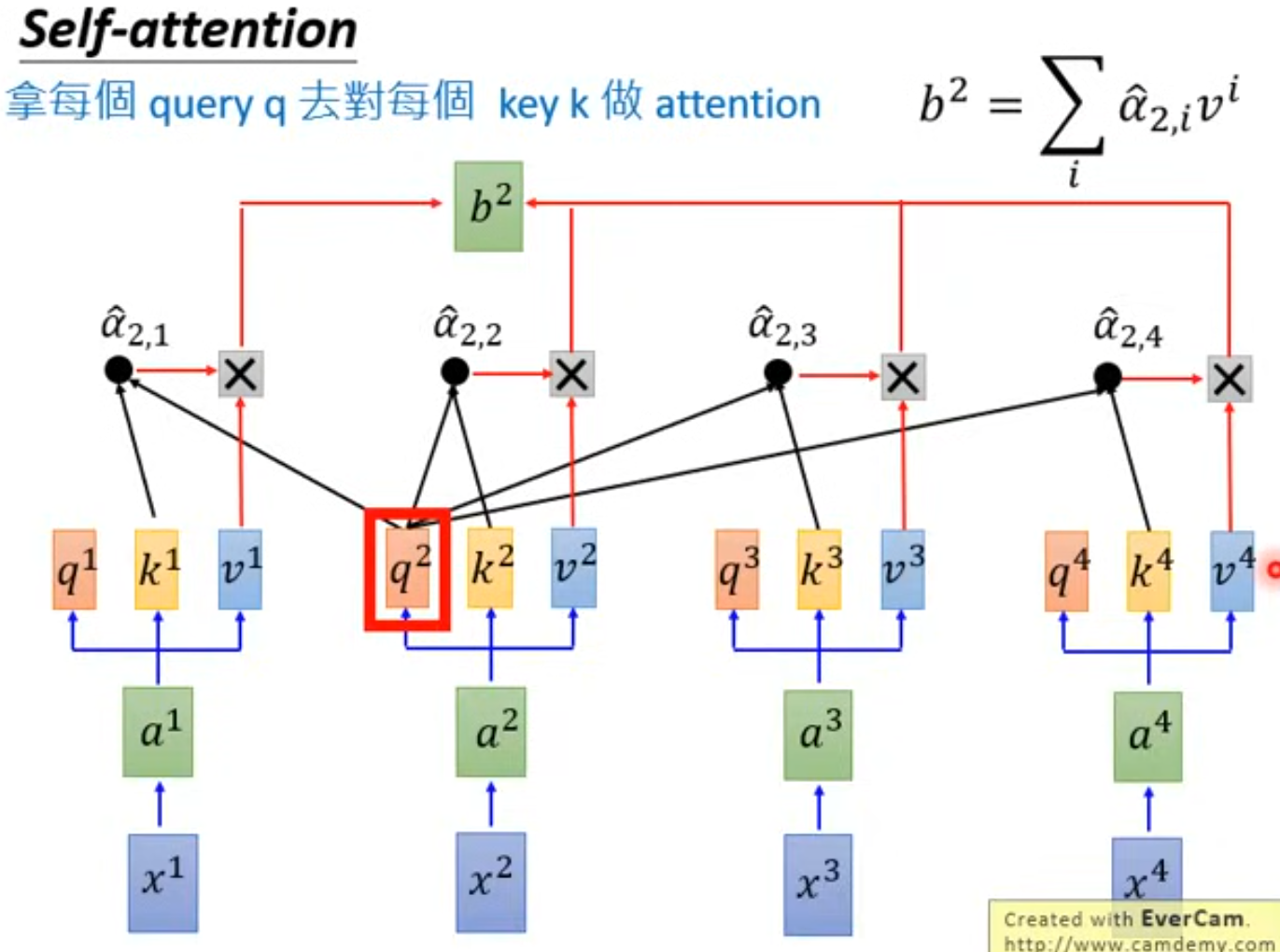
为什么可以并行?因为可以化作矩阵同时计算

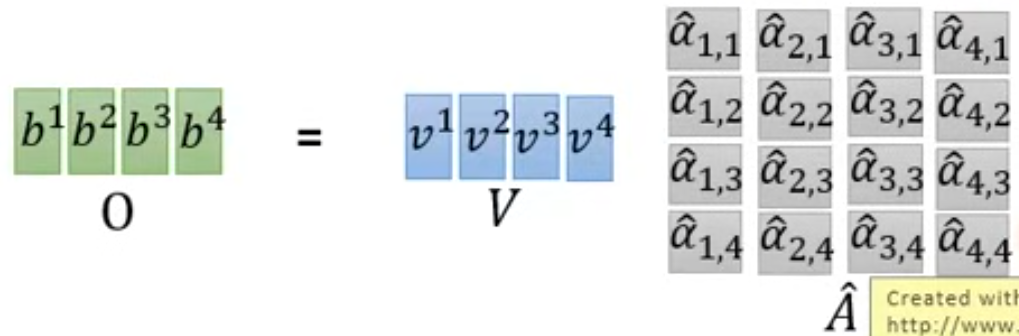
总结:self-attention层 的 Input 到 Output,其实就是一堆矩阵乘法
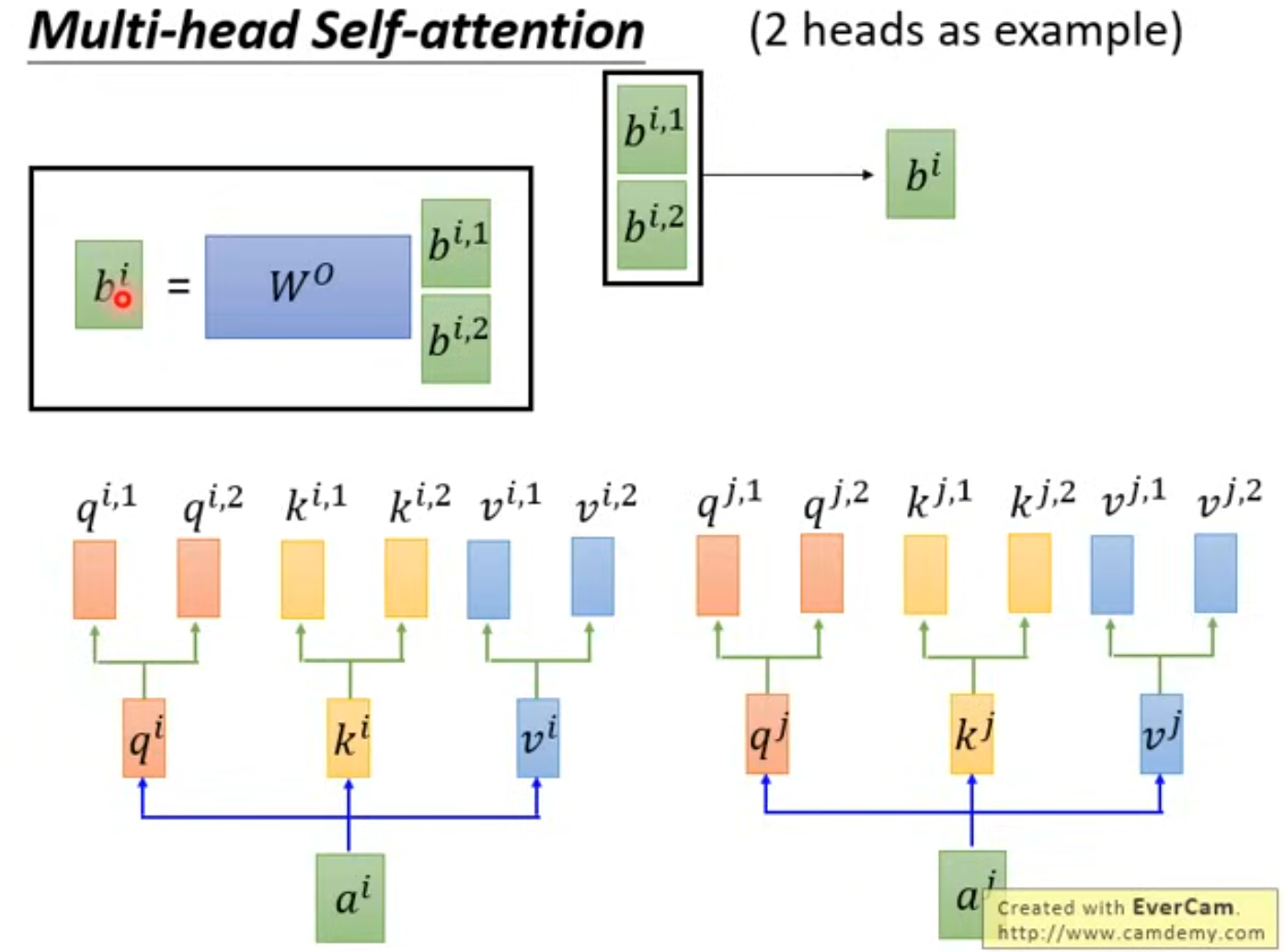
3 Multi-Head Self-Attention(多角度理解一句话)
类似卷积核,不同卷积核关注同一图片的不同特征信息,多头注意力机制 的目的也是为了多个角度理解语义。
| 对比维度 | CNN 卷积核 | Multi-Head Attention |
|---|---|---|
| 参数多样性 | 多个卷积核权重 | 多组 (W_Q, W_K, W_V) |
| 特征提取视角 | 每个卷积核提取不同局部模式(边缘、角点等) | 每个注意力头学习不同语义关系(主谓、修饰、时态等) |
| 结果融合 | 多个 feature map 拼接 | 多个 head 的输出拼接 |
| 最终目标 | 获取更丰富的空间特征 | 获取更全面的语义依赖 |
区别在于:
- CNN 的卷积核是局部感受野(看邻近像素);
- Attention 的每个头是全局感受野(能看整个序列)。
比如:我爱北京天安门,3个头
| 注意力头 | 关注的语义 |
|---|---|
| Head 1 | 主语 → 动作(我 → 爱) |
| Head 2 | 动作 → 宾语(爱 → 北京) |
| Head 3 | 实体连接(北京 → 天安门) |
实际的矩阵计算也很方便:
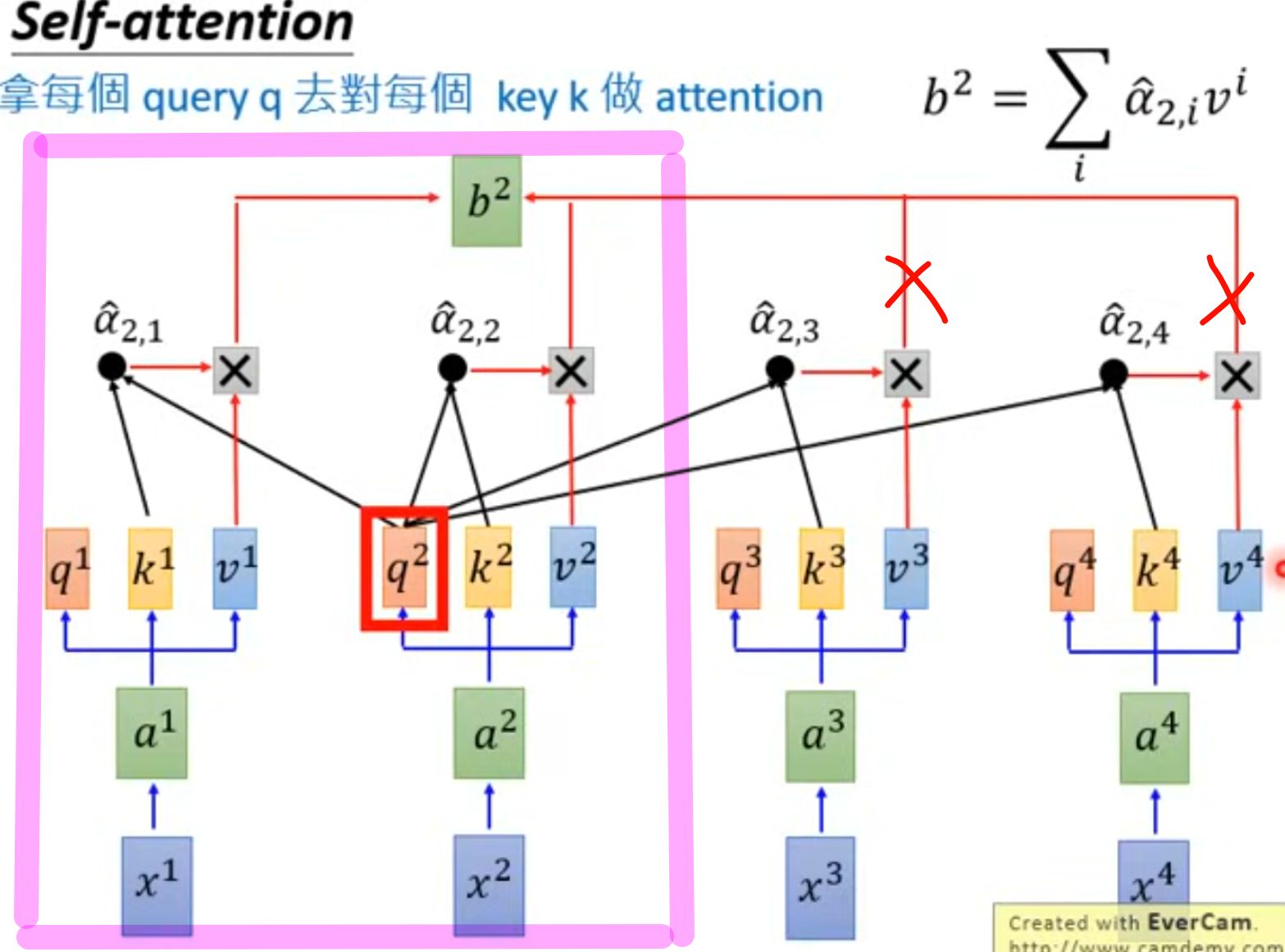
Masked Multi-Head Self-Attention
掩码多头注意力机制 相对于多头注意力机制,其 真正的区别只在于:是否“遮住未来的信息”。
如下图所示,圈出的粉色框,正是**“第 2 个 token 的 masked self-attention 可见区域”**。它表示在生成第 2 个输出时,模型只使用自己和之前的内容,不会看未来的内容。
即,b2 的运算是:
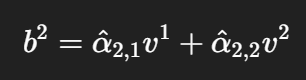
Transformer框架
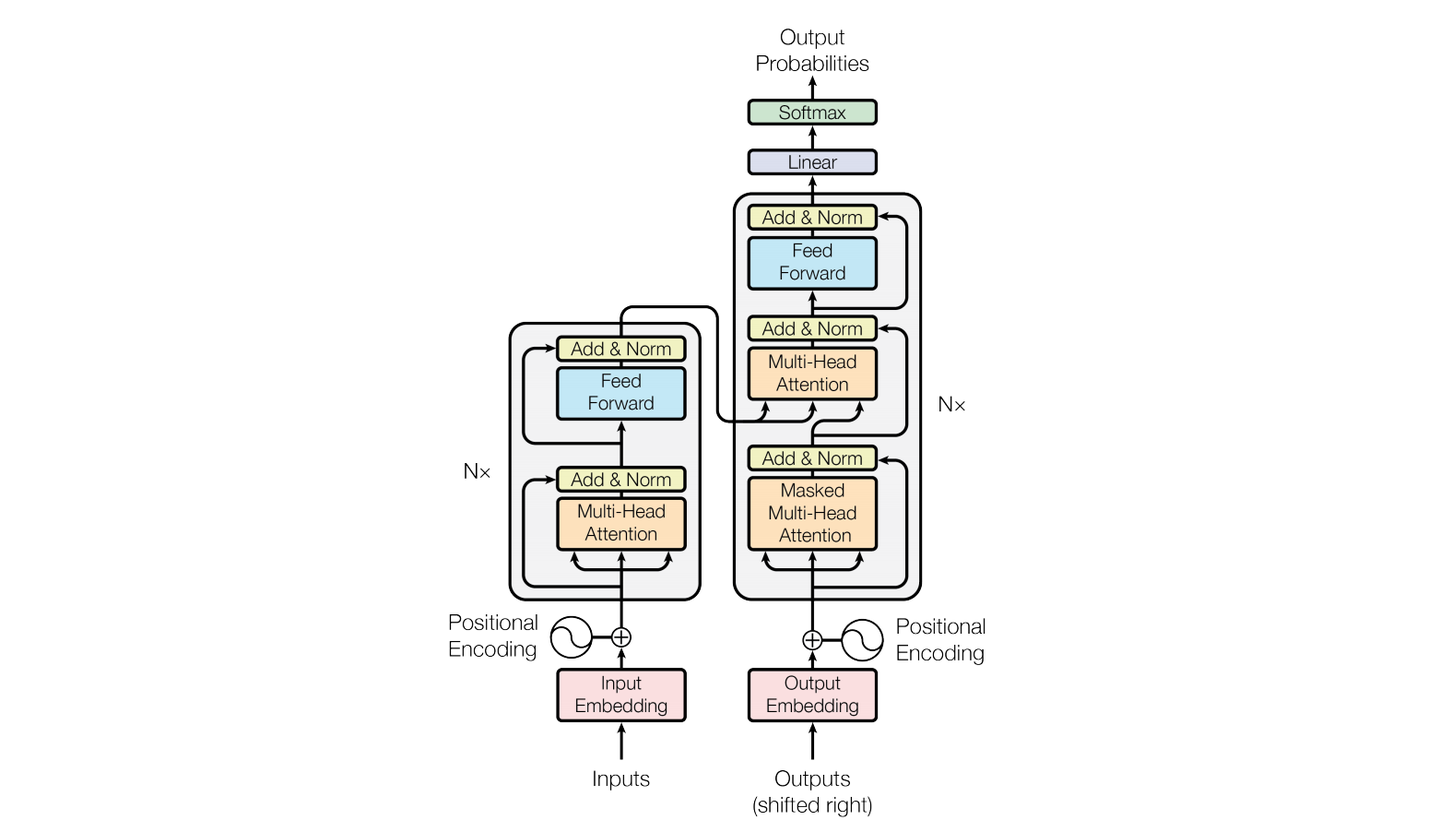
在之前的基础知识讲解中,我们其实已经攻克的最难的部分,也解决了模型的输入问题,Encoder 部分也差不多了。下面再来系统讲解一下:
Embedding-句转vec
略(见 基础知识解析 1)
Encoder-理解语义
功能
理解输入序列的语义,并把这种理解转化为高维向量表示,供解码器或下游任务使用。
框架
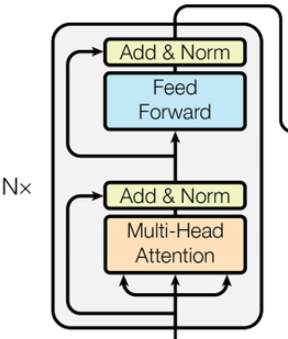
- **Add:**表示残差网络,是为了保证模型学习稳定性的(不退步)
- Norm:表示归一化,为了稳定训练、加快收敛、防止梯度爆炸/消失(Transformer 使用 LayerNorm)
- Feed Forward:表示前馈神经网络,是进行非线性加工和语义升华的模块(激活函数 Relu)
这里对比一下 LayerNorm 和 BatchNorm 的区别:
| 对比项 | Batch Normalization | Layer Normalization |
|---|---|---|
| 归一化维度 | 跨样本(对 batch 维度取均值) | 样本内(对特征维度取均值) |
| 是否依赖 batch size | ✅ 是 | ❌ 否 |
| 适用场景 | CNN、小批量图像训练 | RNN、Transformer(序列任务) |
Decoder-输出句子(vec形式)
功能
根据语义生成输出
框架
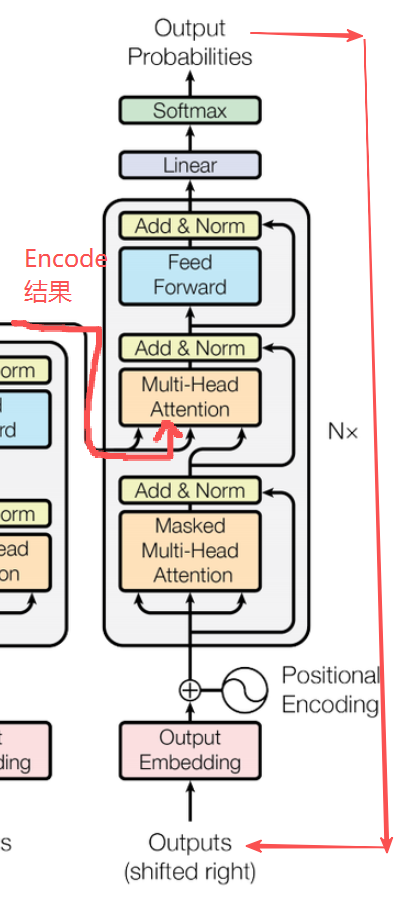
注意:这里解码器的输入有两个,一个是Encoder的结果 R1,一个是当前生成序列的结果 R2 (瞻前顾后)
其中,R1直接送往多头自注意力机制,R2需要先经过掩码多头自注意力机制进行加工,再和R1一起去。
Encoder和Decoder的总结表:
| 模块 | 功能 | 输入 | 输出 | 类比 |
|---|---|---|---|---|
| Encoder | 理解输入内容,提取语义特征 | Token向量序列 | 上下文语义表示序列 | “阅读理解器” |
| Decoder | 根据语义生成输出 | Encoder结果 + 已生成的词 | 预测下一个词 | “语言生成器” |
Output-vec转句子
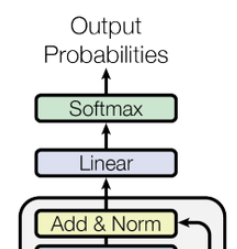
step 1 线性变换(Linear Projection)
通过一个线性层(即矩阵乘法 + 偏置项)映射到词表维度
公式:yi=zi·Wo+bo
其中,Wo 是线性层权重矩阵,bo 是偏置项,每个 yi 表示该位置上所有词的置信度分数。
step 2 Softmax 转为概率分布
Softmax 将所有 logit 转换成概率分布。
于是:
- 每个位置上,模型会给出“下一个词是哪个”的概率;
- 概率最大的那个词(Argmax)就是模型预测的输出。
step 3 查表输出文本
根据概率分布选择概率最大的那个索引对应的字输出
总结
针对具体例子来说,我们已知:
-
词表里有5个词
索引 词 1 我 2 爱 3 你 4 们 5 。 -
线性权重矩阵
Wo.shape=4x5 (4:表示一个字的向量dim,5:词表长度)
# Decoder 输出
Z=[[0.2,−0.1,0.5,0.7],[...],[...]] # Z1=[0.2,−0.1,0.5,0.7]
⬇️线性层 # y=z·Wo+bo,
y=[[0.82,0.52,0.39,0.47,0.68], # z1对应在词表中的置信度 logit
[...],
[...]]
⬇️softmax # 转概率
o=[[0.26,0.19,0.17,0.18,0.20],[...],[...]]
⬇️查表
o1概率最高的是 0.26 这项,对应索引1,表示 “我”,输出
o2...
推荐大家看看:李宏毅老师讲的Transformer


















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









