




目录
包含Python全套编程资料(数据分析)、学习路线图、软件安装包等!【学习资源分享】!
转义字符
在Python中,某些符号具有特殊意义。当需要这些符号作为普通字符时,需使用反斜杠(\)进行转义。
常见转义字符如下:
| 转义符号 | 意义 |
| \\ | 代表一个反斜杠字符\ |
| \' | 代表一个单引号字符' |
| \" | 代表一个双引号字符" |
| \b | 退格符(BS),将当前位置移到前一列 |
| \n | 换行符(LF),将当前位置移到下一行开头 |
| \t | 水平制表(HT)(跳到下一个TAB位置) |
| \r | 回车符(CR),将当前位置移到本行开头 |
| \uXXXX | Unicode字符,XXXX 是四位十六进制数【print('\u03B1')】 |
| 转义字符很多。同学们可以课后了解更多。 | |
以下为各转义字符示例:
反斜杠\\:
print("这是反斜杠: \\") # 反斜杠本身需要转义,即\\表示一个反斜杠字符。输出:
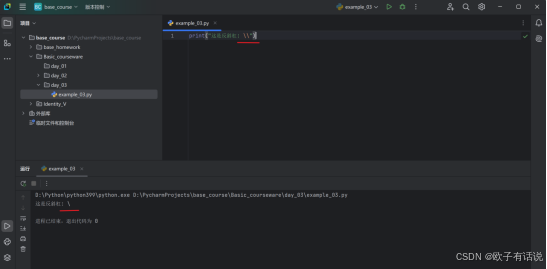
单引号\':
print('他\'s 在学习 Python。')输出:
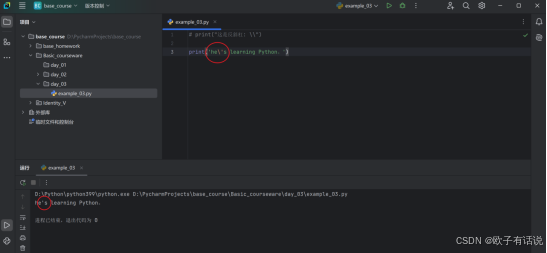
双引号\":
print("她说了 \"你好!\"")输出:
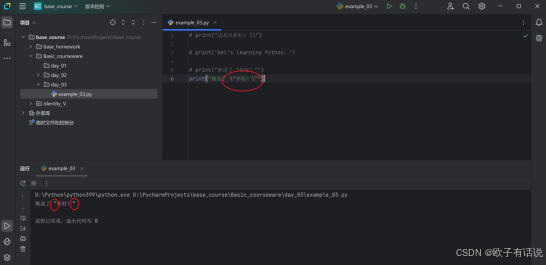
退格符\b:
print("1234\b5678")输出:
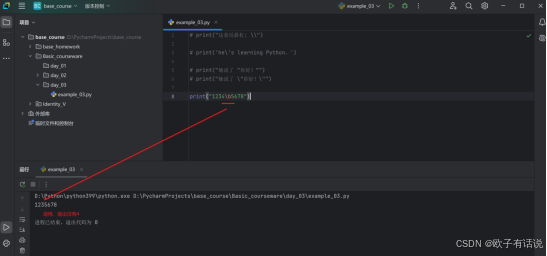
换行符\n:
print("第一行\n第二行")输出:
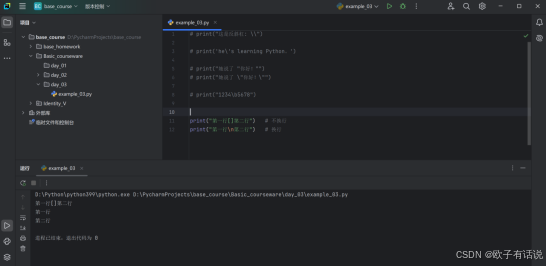
水平制表符\t:
print("列1\t列2\t列3")
print("值1\t值2\t值3")输出:
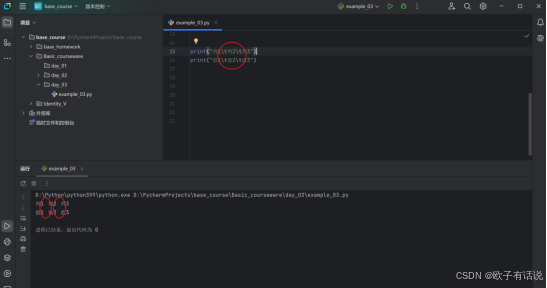
回车符 \r:
print("回车\r返回")输出:
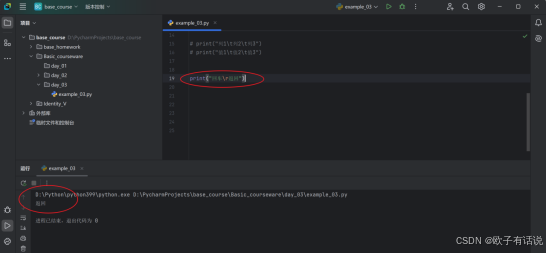
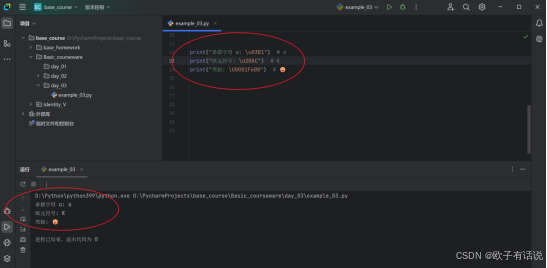
Unicode字符\u:【Unicode是字符集,可以在最后面查看编码格式了解更多】
print("希腊字母 α: \u03B1") # α
print("欧元符号: \u20AC") # €
print("笑脸: \U0001F600") # ��输出:
简单的字符串操作
字符串加法拼接:
a = 'I love '
b = 'Python'
print(a + b)输出:I love Python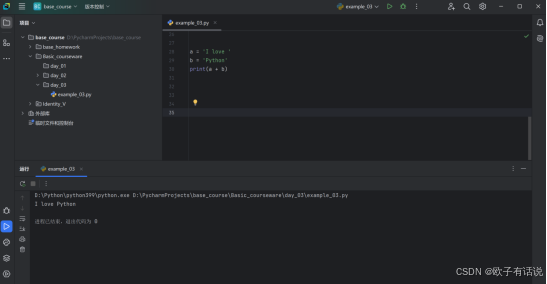
字符串乘法复制:
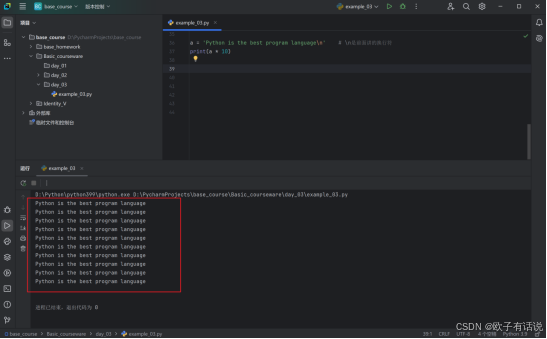
a = 'Python is the best program language\n' # \n是前面讲的换行符
print(a * 10)输出:
原始字符串表示方式:
在Python中,原始字符串是一种特殊类型的字符串,它不会处理转义字符。这对于需要包含大量反斜杠的路径或正则表达式特别有用。
定义方式:在字符串前面加r或R来创建一个原始字符串(r和R是大小写不敏感,所以都可以使用。)
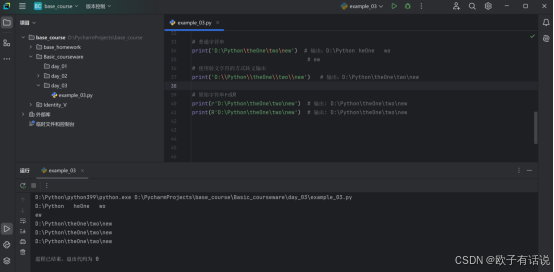
# 普通字符串
print('D:\Python\theOne\two\new') # 输出:D:\Python heOne wo
# ew
# 使用转义字符的方式转义输出
print('D:\\Python\\theOne\\two\\new') # 输出:D:\Python\theOne\two\new
# 原始字符串r或R
print(r'D:\Python\theOne\two\new') # 输出: D:\Python\theOne\two\new
print(R'D:\Python\theOne\two\new') # 输出: D:\Python\theOne\two\new输出:
说明:
从示例中可以看到。使用转义字符会有些繁琐。而直接使用r或R之后,就能表示原始的字符串了。
应用场景:
-
- 文件路径(例如:D:\Python\theOne\two\new)
- url路径地址(例如:https://www.baidu.com/)
- 正则表达式(在第19课会讲,这里不放它的示例)
数据类型:布尔类型、NoneType 类型
我们在第2节课了解过数字类型(int和float)、字符串类型(str),这节课则在讲两种类型:bool类型和NoneType 类型
布尔类型
布尔(bool)类型是Python中最基本的数据类型之一,它只有两个值:True和False。它们通常用于逻辑判断和条件控制。
True:表示真
False:表示假
布尔类型的定义和使用:
定义方式:布尔类型的值必须首字母大写。
a = True
b = False
"""单看布尔值,没有什么作用,一般需要【配合逻辑判断】使用,见下面的示例"""
"""对于【配合条件控制】使用,在后面的课程中会用到"""用于逻辑判断:
使用比较运算符进行逻辑判断,返回布尔值。
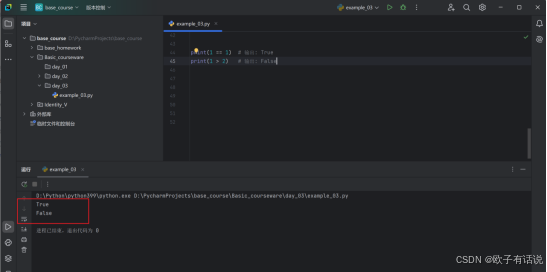
print(1 == 1) # 输出: True
print(1 > 2) # 输出: False输出:
说明:
代码运行结果,一个为True,一个为False;
代码中的“==”是用来判断左右两边是否相等,“>”用来判断左边的值是否大于右边的值。
bool()函数:
bool() 函数可以用来检查一个值是否为真或假。
True:表示数据逻辑为真。
False:表示逻辑为假
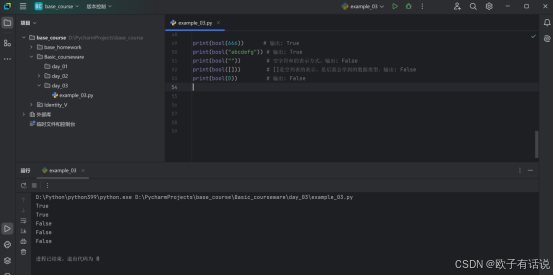
print(bool(666)) # 输出: True
print(bool("abcdefg")) # 输出: True
print(bool("")) # 空字符串的表示方式。输出: False
print(bool([])) # []是空列表的表示。是后面会学到的数据类型。输出: False
print(bool(0)) # 输出: False输出:
NoneType 类型
None 是 Python 中的一种特殊数据类型,表示没有值。它是 NoneType 数据类型的唯一值。
None 的定义与使用:
定义方式:None 表示没有值,不同于空字符串或数字0。
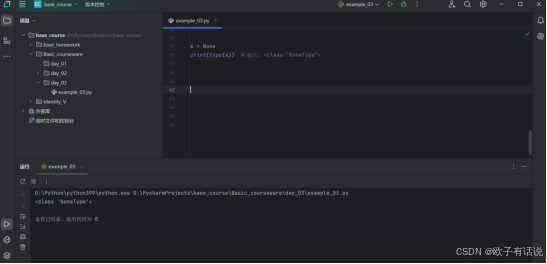
x = None
print(type(x)) # 输出: <class 'NoneType'>输出:
其它示例:
# 定义 None 变量
none_var = None
# 比较 None 和其他类型
empty_string = ''
zero_int = 0
print(type(none_var)) # 输出: <class 'NoneType'>
print(type(empty_string)) # 输出: <class 'str'>
print(type(zero_int)) # 输出: <class 'int'>输出:
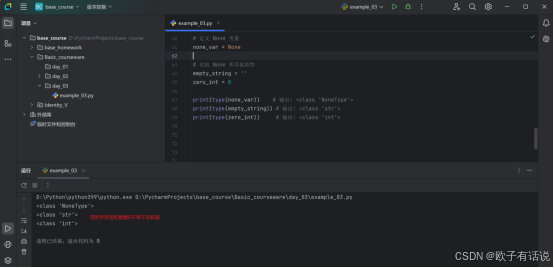
说明:
空字符串或者整数0,仍然为其本身的类型。与None表示的NoneType有着本质区别。
运算符:比较运算符、身份运算符
比较运算符:
比较运算符有时候也被称为关系运算符,用于对参与运算的两个操作数进行比较。比较结果会返回bool值Ture/False。
| 符号 | 描述 |
| == | 判断作用两个操作书之间的结果是否相等。是-则返回Ture;否-则返回False。 |
| != | 不等于。判断两个操作数直接是否不等于。不等于-Ture;等于-Flase |
| > | 大于。左侧操作数>右侧操作数。 大于返回Ture;反之False |
| < | 小于。左侧操作数>右侧操作数。 小于返回Ture;反之False |
| >= | 大于等于。左侧操作数>=右侧操作数。 大于或等于返回Ture,小于返回False。 |
| <= | 小于等于。左侧操作数>=右侧操作数。 小于或等于返回Ture,大于返回False。 |
示例集:
不等于 !=示例:
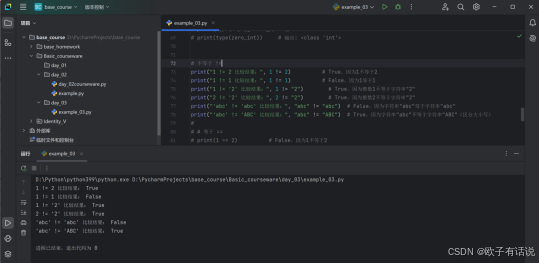
# 不等于 !=
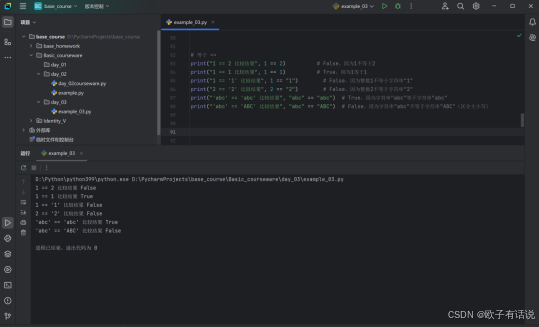
print("1 != 2 比较结果:", 1 != 2) # True,因为1不等于2
print("1 != 1 比较结果:", 1 != 1) # False,因为1等于1
print("1 != '2' 比较结果:", 1 != "2") # True,因为整数1不等于字符串"2"
print("2 != '2' 比较结果:", 2 != "2") # True,因为整数2不等于字符串"2"
print("'abc' != 'abc' 比较结果:", "abc" != "abc") # False,因为字符串"abc"等于字符串"abc"
print("'abc' != 'ABC' 比较结果:", "abc" != "ABC") # True,因为字符串"abc"不等于字符串"ABC"(区分大小写)
# 【自行尝试,不做过于详细的示例】运行结果:
等于 ==示例:
# 等于 ==
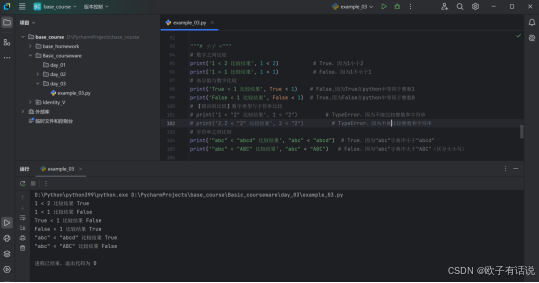
print("1 == 2 比较结果", 1 == 2) # False,因为1不等于2
print("1 == 1 比较结果", 1 == 1) # True,因为1等于1
print("1 == '1' 比较结果", 1 == "1") # False,因为整数1不等于字符串"1"
print("2 == '2' 比较结果", 2 == "2") # False,因为整数2不等于字符串"2"
print("'abc' == 'abc' 比较结果", "abc" == "abc") # True,因为字符串"abc"等于字符串"abc"
print("'abc' == 'ABC' 比较结果", "abc" == "ABC") # False,因为字符串"abc"不等于字符串"ABC"(区分大小写)
# 【自行尝试,不做过于详细的示例】运行结果:
小于 <示例:
# 小于 <
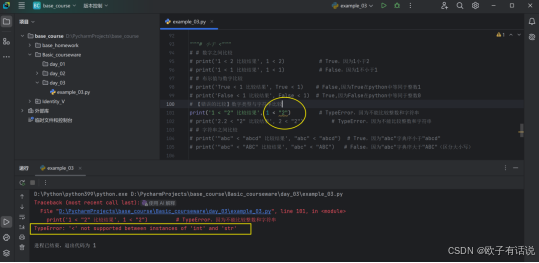
# 数字之间比较
print('1 < 2 比较结果', 1 < 2) # True,因为1小于2
print('1 < 1 比较结果', 1 < 1) # False,因为1不小于1
# 布尔值与数字比较
print('True < 1 比较结果', True < 1) # False,因为True在python中等同于整数1
print('False < 1 比较结果', False < 1) # True,因为False在python中等同于整数0
# 【错误的比较】数字类型与字符串比较
# print('1 < "2" 比较结果', 1 < "2") # TypeError,因为不能比较整数和字符串
# print('2.2 < "2" 比较结果', 2 < "2") # TypeError,因为不能比较整数和字符串
# 字符串之间比较
print('"abc" < "abcd" 比较结果', "abc" < "abcd") # True,因为"abc"字典序小于"abcd"
print('"abc" < "ABC" 比较结果', "abc" < "ABC") # False,因为"abc"字典序大于"ABC"(区分大小写)
# 【自行尝试,不做过于详细的示例】运行结果1:注释整数和字符串比较语句的输出结果
运行结果2:数字类型和字符串比较。会报错。
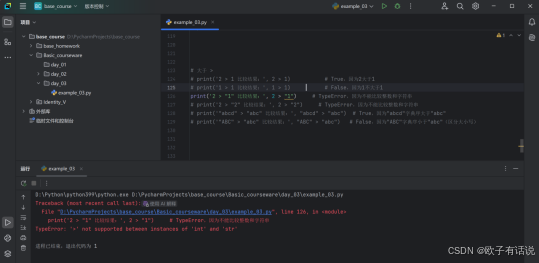
小于或等于 <=:
print('1 <= 2 比较结果:', 1 <= 2) # True,因为1小于等于2
print('1 <= 1 比较结果:', 1 <= 1) # True,因为1等于1
# print('1 <= "2" 比较结果:', 1 <= "2") # TypeError,因为不能比较整数和字符串
# print('1.2 <= "2" 比较结果:', 1.2 <= "2") # TypeError,因为不能比较浮点数和字符串
print('"abc" <= "abcd" 比较结果:', "abc" <= "abcd") # True,因为"abc"字典序小于等于"abcd"
print('"abc" <= "ABC" 比较结果:', "abc" <= "ABC") # False,因为"abc"字典序大于"ABC"(区分大小写)
# 【自行尝试,不做过于详细的示例】运行结果1:

运行结果2:
大于>:
# 大于 >
print('2 > 1 比较结果:', 2 > 1) # True,因为2大于1
print('1 > 1 比较结果:', 1 > 1) # False,因为1不大于1
# print('2 > "1" 比较结果:', 2 > "1") # TypeError,因为不能比较整数和字符串
# print('2 > "2" 比较结果:', 2 > "2") # TypeError,因为不能比较整数和字符串
print('"abcd" > "abc" 比较结果:', "abcd" > "abc") # True,因为"abcd"字典序大于"abc"
print('"ABC" > "abc" 比较结果:', "ABC" > "abc") # False,因为"ABC"字典序小于"abc"(区分大小写)
# 【自行尝试,不做过于详细的示例】运行结果1:
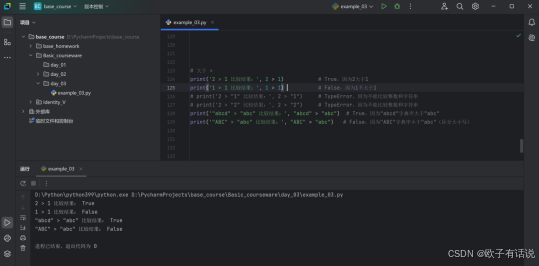
运行结果2:
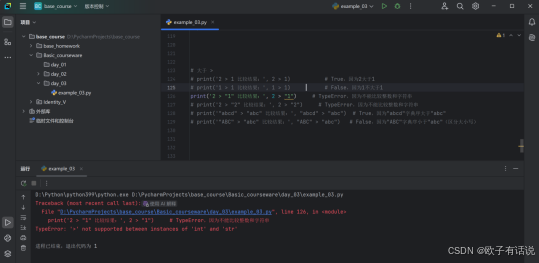
大于或等于 >=:
运行结果1:
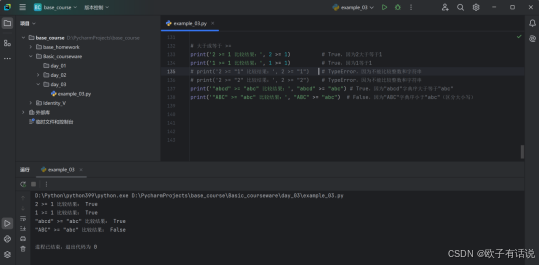
运行结果2:
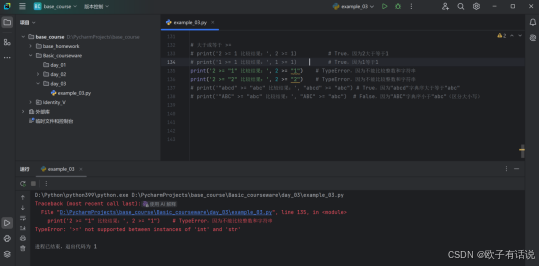
注意:字符串比较是基于字典序进行的。【了解即可】
字典序:就是类似与字典中单词的排列顺序。
比如,在字典中,单词是按字母顺序排列的。例如,“apple”排在“banana”之前,因为“a”在“b”之前
具体步骤:
- 逐字符比较:从左到右逐个字符进行比较。
- 字符编码值:每个字符都有一个对应的编码值(如ASCII或Unicode【最后面有讲解字符编码的内容】),这些编码值决定了字符的大小关系。
- 停止条件:一旦发现某个字符不同,就可以确定两个字符串的顺序;如果前面的所有字符都相同,则较短的字符串排在前面。
比如:
"abc" < "abd":(输出: True,因为在第三个字符处'b'小于'd');c(编码值为99)小于d(编码值为100),因此"abc"排在"abd"前面。
身份运算符:
身份运算符用于比较两个数据(值)是否指向同一个内存地址。
| 符号 | 描述 |
| is | 如果两个变量指向同一个值(即它们的内存地址相同), 则表达式 x is y 返回 True。<is是判断两个标识符是不是引用自一个值> |
| is not | 如果两个变量不指向同一个值(即它们的内存地址不同), 则表达式 x is not y 返回 True。<is not 是判断两个标识符是不是引用不同值> |
身份运算符:is
is 用来判断两个数据内存引用地址是否相同,
如果相同,结果为真 True,
如果不相同,结果为假 False。
见如下示例:
a = 123
b = 123
# 上面的变量 a 和变量 b 都指向同一个值 123 ,所以值相同,那么地址是否相同呢?
# 我们可以使用 id() 函数获取它们的地址,然后再用 is 关键字进行判断。
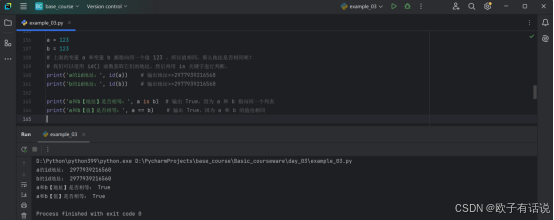
print('a的id地址:', id(a)) # 输出地址
print('b的id地址:', id(b)) # 输出地址
print('a和b【地址】是否相等:', a is b) # 输出 True,因为 a 和 b 指向同一个列表
print('a和b【值】是否相等:', a == b) # 输出 True,因为 a 和 b 的值也相同运行结果展示:
但是,值相同的数据,地址一定相等吗?再看看下面的示例:
# 我们分别引入两个列表(列表暂时没有学习,引入进来了解is的用处),列表是可变数据类型。
c = [1, 2, 3]
d = [1, 2, 3]
# 变量 c 和变量 d 看起来是不是值一模一样呢?我们可以使用==的方式判断。
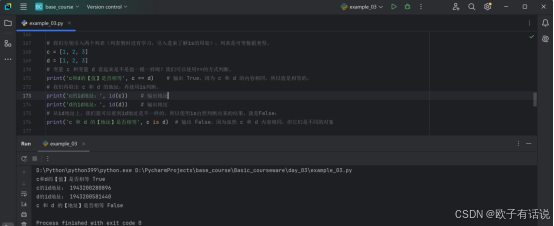
print('c和d的【值】是否相等', c == d) # 输出 True,因为 c 和 d 的内容相同,所以值是相等的。
# 我们再取出 c 和 d 的地址,再使用is判断。
print('c的id地址:', id(c)) # 输出地址
print('d的id地址:', id(d)) # 输出地址
# 从id地址上,我们就可以看到id地址是不一样的。所以使用is自然判断出来的结果,就是False。
print('c 和 d 的【地址】是否相等', c is d) # 输出 False,因为虽然 c 和 d 内容相同,但它们是不同的对象运行结果展示:
总结:两个字面量相同的数据,内存地址未必相同,就像两个双胞胎,长的相同,但是是两个独立的个体。
身份运算符:is not
is not 用来判断两个数据内存引用地址是否不同,如果不同,结果为真 True,如果相同,结果为假 False
使用示例:
# 我们讲上面的示例反过来使用is not判断,观察期返回值:
# 示例 1
a = 123
b = 123
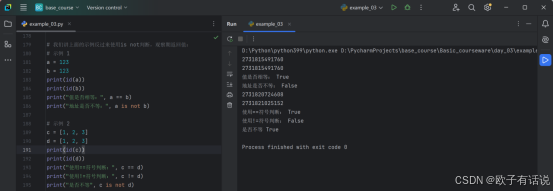
print(id(a))
print(id(b))
print(a == b)
print(a is not b)
# 示例 2
c = [1, 2, 3]
d = [1, 2, 3]
print(id(c))
print(id(d))
print("使用==符号判断:", c == d)
print("使用!=符号判断:", c != d)
print(c is not d)运行结果:
注意点:
is 和 == 的区别:
is:用来比较两个数据是否存储在同一地址。(可以理解为,两边'身份证'是不是同一个)
==:用来比较两个数据的内容是不是相等。
is not 和 != 的区别:
is not:用来比较两个数据是否存储在不同的地址。
!=:用来比较两个数据的内容是否不相等。
字符编码:
前面的转义字符中,提到了\u作为Unicode字符转义的作用。
下面是对各种编码格式的讲解:
ASCII编码:(了解即可)
这是最早的字符编码标准。
仅包含128个字符(编码从0~127),包括英文字母(大小写)、数字、一些标点符号和控制字符。
ASCII编码采用8位二进制表示(原始的ASCII是7个字节,但是计算机应用中,通常采取8位的拓展版本来存储和处理)。
在python中,
我们可以使用ord()函数查询其ASCII码,
再用bin()输出其二进制表示方式,
再使用chr()将二进制(或ASCII码)输出为具体字符。
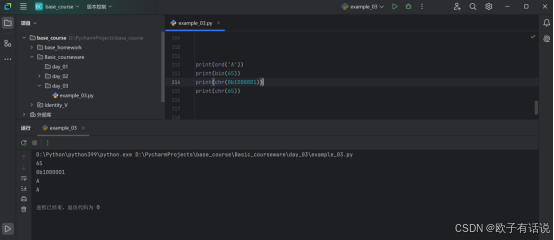
print(ord('A')) # 输出其ACLL码为:65
print(bin(65)) # 输出二进制形式为:0b1000001
print(chr(0b1000001)) # 输出为:A运行结果:
Unicode 编码:(了解即可)
一种全球化的字符集标准,旨在支持世界上几乎所有的书写系统。定义了每一字符的唯一编码(包括ASCII编码的值)
其几乎包含涵盖世界上所有语言的字符,包括各种语言的字母、符号、标点符号和特殊符号。
编码范围:0~1,114,111(共1,114,112个字符)(十六进制表达方式:从 0x0000 到 0x10FFFF)
我们同样可以使用ord()函数获取Unicode码点,
再用hex()函数输出其16进制表达方式,
再使用chr()方法反向输出:
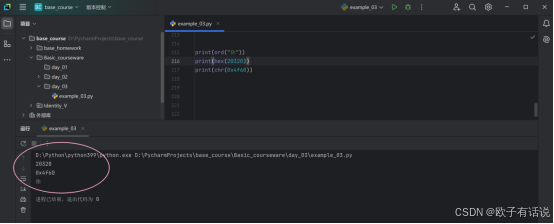
print(ord("你"))
print(hex(20320))
print(chr(0x4f60))运行结果:
UTF-8 编码
定义:UTF-8是Unicode的一种实现编码方式,兼容ASCII。
特点:
英文字母小写,阿拉伯数字和常用符号是一个字节一个字符。
汉字是三个字节一个字符。
在python中。我们可以使用encode()转换为UTF-8编码:(encode()默认编码是UTF-8)
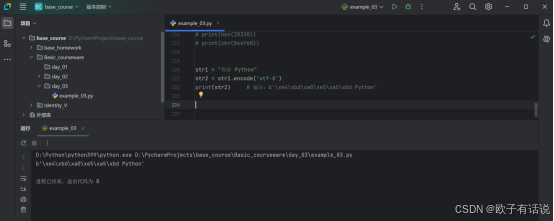
str1 = "你好 Python"
str2 = str1.encode('utf-8')
print(str2) # 输出:b'\xe4\xbd\xa0\xe5\xa5\xbd Python'运行结果:
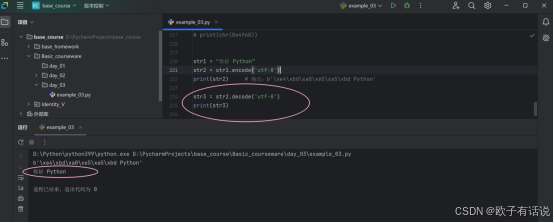
我们还可以使用decode()方法进行解码:
str1 = "你好 Python"
str2 = str1.encode('utf-8')
print(str2) # 输出:b'\xe4\xbd\xa0\xe5\xa5\xbd Python'
str3 = str2.decode('utf-8')
print(str3)运行结果:
注意事项:
python3的统一编码格式为:utf-8
可以在每个文件开头设置:(这是针对Unix-like系统的特定用法。)
#!/usr/bin/python3
# coding: utf8 #!/usr/bin/python3:这个叫做Shebang 行。用来告诉操作系统使用哪个解释器来执行当前脚本。
解释>>>#!/usr/bin/python3 指定了使用 /usr/bin/python3 这个路径下的 Python 3 解释器来运行这个脚本。(这个路径切换成自己电脑里面解释器安装的路径即可!)
使用场景>>>在 Unix 和 Linux 系统中,如果你希望直接通过命令行运行 Python 脚本而不需要显式地调用 python3 命令,可以使用 Shebang 行。
例如,假设你的脚本名为 myscript.py,并且它有 Shebang 行 #!/usr/bin/python3,那么你可以直接在终端中运行:
./myscript.py而不需要输入 python3 myscript.py。
# coding: utf8:这个是编码声明。可以帮助避免潜在的编码问题。默认情况下都是使用 UTF-8 编码的。
使用场景>>>如果你的源代码文件中包含了例如中文、表情符号等非ASCII字符的,最好显式地声明编码为 UTF-8,确保这些字符被正确解析。
另外:这两行特别的注释,最好放在第一行和第二行。否则,python会忽略这两行的注释。
UTF-8 编码:在大多数现代开发环境中,UTF-8 已经是默认编码,因此通常不需要特别指定。但是,在某些特定情况下(如旧版本的编辑器或特殊配置),显式声明编码仍然是有益的。
这一章节就先讲到这里,课件文档需要的同学,可以【点击此处】获取。


















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









