




 本文详述了从HBase迁移数据至HDFS的全过程,包括代码实现、配置详解及集群部署步骤。通过IDEA开发环境,演示了两种运行方式:变量配置打包上传与加载XML配置本地运行。
本文详述了从HBase迁移数据至HDFS的全过程,包括代码实现、配置详解及集群部署步骤。通过IDEA开发环境,演示了两种运行方式:变量配置打包上传与加载XML配置本地运行。
不算两种方法
就是一种使用变量写配置 然后打包jar到服务器运行
另一种加载xml配置文件 使用idea本地运行
贴代码
/**
* 作者:Shishuai
* 文件名:HBase2HDFS
* 时间:2019/8/17 16:00
*/
package com.qf.mr;
import cn.qphone.mr.Demo1_HBase2HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellScanner;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
//不要导错了包 org.apache.hadoop.mapred.FileOutputFormat 这个不对
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class HBase2HDF_SDemo1 extends ToolRunner implements Tool {
private Configuration configuration;
private final String HDFS_KEY = "fs.defaultFS";
private final String HDFS_VALUE = "hdfs://qf";
private final String MR_KEY = "mapreduce.framework.name";
private final String MR_VALUE = "yarn";
private final String HBASE_KEY = "hbase.zookeeper.quorum";
private final String HBASE_VALUE = "hadoop01:2181,hadoop02:2181,hadoop03:2181";
private Scan getScan(){
return new Scan();
}
static class HBase2HDFSMapper extends TableMapper<Text, NullWritable> {
private Text k = new Text();
/**
* 001 column=base_info:age, timestamp=1558348072062, value=20
* 001 column=base_info:name, timestamp=1558348048716, value=lixi
*
*
* 001 base_info:age 20 base_info:name lixi
*/
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//1. 创建StringBuffer用于拼凑字符串
StringBuffer sb = new StringBuffer();
//2. 遍历result中的所有的列簇
CellScanner scanner = value.cellScanner();
int index = 0;
while(scanner.advance()){
//3. 获取到当前的cell,然后决定拼串的方式
Cell cell = scanner.current();
if(index == 0){
sb.append(new String(CellUtil.cloneRow(cell))).append("\t");
index++;
}
sb.append(new String(CellUtil.cloneQualifier(cell))).append(":")
.append(new String(CellUtil.cloneValue(cell))).append("\t");
}
//4. 输出
k.set(sb.toString());
context.write(k, NullWritable.get());
}
}
@Override
public int run(String[] args) throws Exception {
configuration = getConf();
//2. 获取到job
Job job = Job.getInstance(configuration);
//3. map,reduce(mapper/reducer的class,还要设置mapper/reducer的输出的key/value的class)
job.setMapperClass(HBase2HDFSMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//4. 输出和输入的参数(输入的目录和输出的目录)
TableMapReduceUtil.initTableMapperJob("user_info", getScan(), HBase2HDFSMapper.class,Text.class, NullWritable.class, job);
FileOutputFormat.setOutputPath(job, new Path(args[0]));
//5. 设置驱动jar包的路径
job.setJarByClass(Demo1_HBase2HDFS.class);
//6. 提交作业(job)
return job.waitForCompletion(true) ? 0 : 1;// 打印提交过程的日志记录并且提交作业
}
@Override
public void setConf(Configuration configuration) {
//1. 保证连接hdfs、连接yarn、连接hbase
configuration.set(HDFS_KEY,HDFS_VALUE);
configuration.set(MR_KEY,MR_VALUE);
configuration.set(HBASE_KEY,HBASE_VALUE);
this.configuration = configuration;
}
@Override
public Configuration getConf() {
return configuration;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(HBaseConfiguration.create(), new HBase2HDF_SDemo1(), args);
}
}
/**
* 作者:Shishuai
* 文件名:HBaseUtils
* 时间:2019/8/17 16:01
*/
package com.qf.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import java.io.IOException;
import java.util.Iterator;
public class HBaseUtilsDemo {
private final static String KEY = "hbase.zookeeper.quorum";
private final static String VALUE = "hadoop01:2181,hadoop02:2181,hadoop03:2181";
private static Configuration configuration;
static {
//1. 创建配置对象
configuration = HBaseConfiguration.create();
configuration.set(KEY, VALUE);
}
public static Admin getAdmin(){
try {
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
return admin;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
public static Table getTable(){
return getTable("user_info");
}
private static Table getTable(String tablename) {
try {
Connection connection = ConnectionFactory.createConnection(configuration);
return connection.getTable(TableName.valueOf(tablename));
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
public static void showResult(Result result) throws IOException {
StringBuffer stringBuffer = new StringBuffer();
CellScanner scanner = result.cellScanner();
while(scanner.advance()){
Cell cell = scanner.current();
stringBuffer.append("Rowkey=").append(new String(CellUtil.cloneRow(cell))).append("\t")
.append("columnfamily=").append(new String(CellUtil.cloneFamily(cell))).append("\t")
.append("cloumn=").append(new String(CellUtil.cloneQualifier(cell))).append("\t")
.append("value=").append(new String(CellUtil.cloneValue(cell))).append("\t").append("\n");
}
System.out.println(stringBuffer.toString());
}
public static void showResult(Filter filter) throws IOException {
if(filter instanceof SingleColumnValueFilter){
SingleColumnValueFilter singleColumnValueFilter = (SingleColumnValueFilter)filter;
singleColumnValueFilter.setFilterIfMissing(true);
}
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = getTable().getScanner(scan);
Iterator<Result> iterator = scanner.iterator();
while(iterator.hasNext()){
Result result = iterator.next();
showResult(result);
}
}
public static void close(Admin admin){
if(admin != null){
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void close(Table table){
if(table != null){
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void close(Admin admin, Table table){
close(admin);
close(table);
}
}
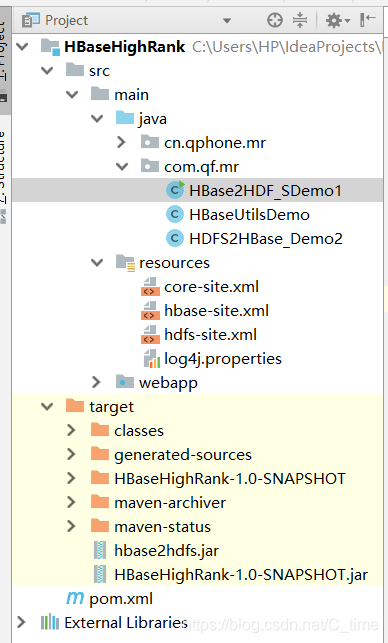
这样两个文件写好后 idea右侧的maven projects
点击package打包 jar包会打到target目录下
我这重新改了下名字 然后复制 上传到服务器 我直接跟以前一样 放到/home下了
然后hadoop jar hbase2hdfs.jar com.qf.mr.HBase2HDF_SDemo1 /04
或者yarn jar hbase2hdfs.jar com.qf.mr.HBase2HDF_SDemo1 /04
都行 记得先启动集群
还有 hbase
本来启动 start-hbase.sh即可
可是最近不知道咋回事
得先启动02 03 的regionserver
hbase-daemon.sh start regionserver
再启动01的master
hbase-daemon.sh start master
这样就好了
然后运行jar包命令即可
注意 如果是第一次运行hbase
你可能会遇到找不到hbase相关类的错误
请看这篇博客 Hbase代码打包为jar上传到服务器运行出现如下错误 Exception in thread “main” java.lang.NoClassDefFoundError… …
然后到hdfs服务器查看你自己的输出目录下的结果
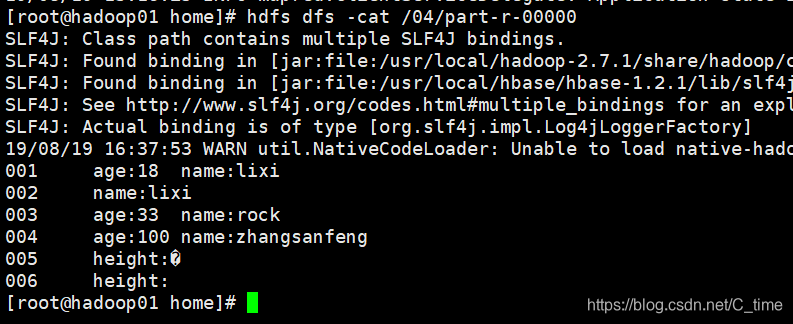
我看了下 没有错误
对了我的hbase数据是
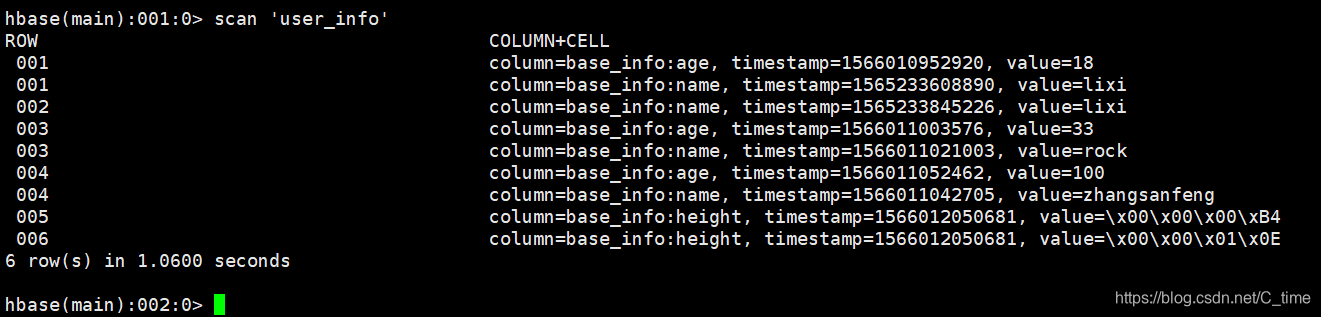
自己编写数据试试即可
第二种方法
代码不同之处在于
1.路径
//5. 设置驱动jar包的路径
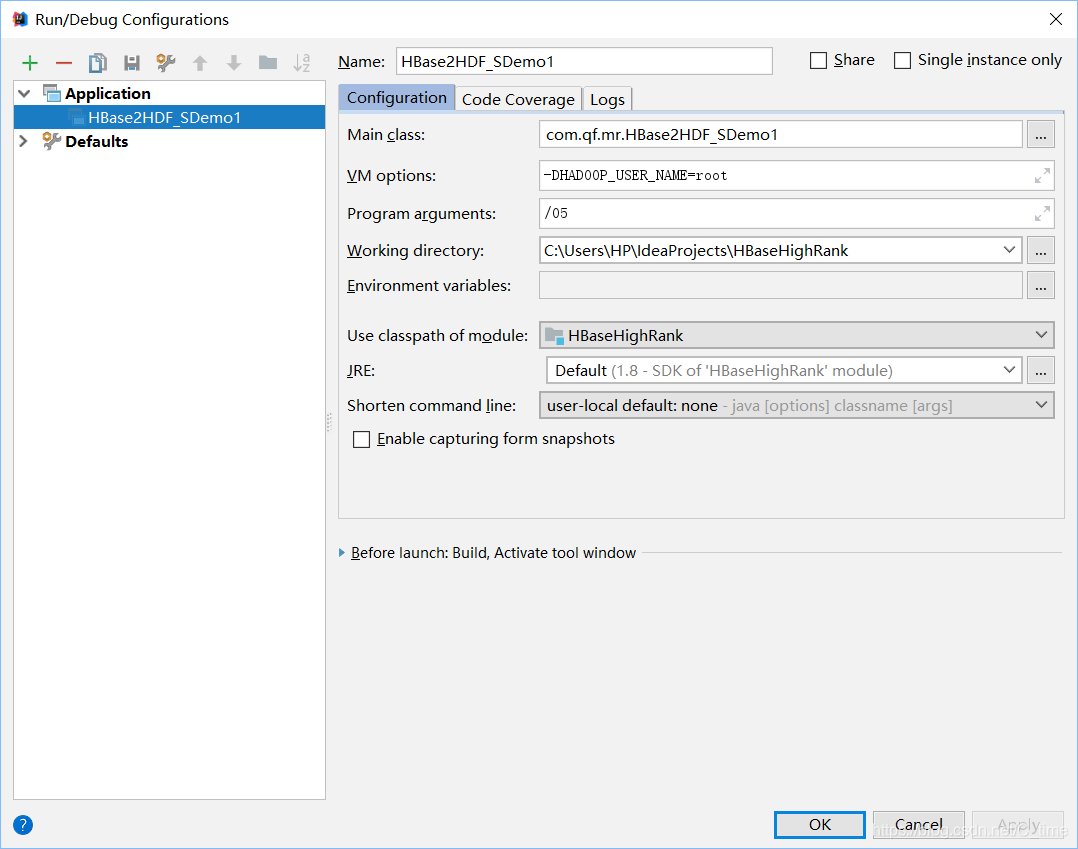
job.setJar("C:\\Users\\HP\\IdeaProjects\\HBaseHighRank\\target\\HBaseHighRank-1.0-SNAPSHOT.jar");
// job.setJarByClass(Demo1_HBase2HDFS.class);
这个路径 是在你改好所有东西后 重新打包出来的jar包路径
就是现在先package一个 右击copy绝对路径 先填上就行
然后弄完配置再打一个覆盖原先的即可
这个jar包就放在target目录下就行 不用移动
2.这个换成加载配置文件
@Override
public void setConf(Configuration configuration) {
//1. 保证连接hdfs、连接yarn、连接hbase
// configuration.set(HDFS_KEY,HDFS_VALUE);
// configuration.set(MR_KEY,MR_VALUE);
// configuration.set(HBASE_KEY,HBASE_VALUE);
configuration.addResource("core-site.xml");
configuration.addResource("hbase-site.xml");
this.configuration = configuration;
}
3.然后 将那三个配置文件弄过来
弄好之后就点击运行即可
在过程中我也遇到一个错误 你也可以参考
idea运行hbase出现IllegalArgumentException: java.net.UnknownHostException: qf和ExceptionInInitializerError
感觉是有idea更快似的
运行完之后 去hdfs服务器查看结果即可
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- hdfs的默认的内部通信uri -->
<!--配置hdfs文件系统的命名空间-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://qf</value>
</property>
<!--配置操作hdfs的缓存大小-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--配置临时数据存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hahadoopdata/tmp</value>
</property>
<!-- 指定zk的集群地址 用来协调namenode的服务 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
</configuration>
hdfs-site.xml
?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--副本数 也叫副本因子 不是容错嘛-->
<!--副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--块大小_hadoop2_128M_hadoop1_64M_hadoop3.0_256M-->
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<!--hdfs的元数据存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hahadoopdata/dfs/name</value>
</property>
<!--hdfs的数据存储位置-->
<property>
<name>dfs.datanode.dir</name>
<value>/home/hahadoopdata/dfs/data</value>
</property>
<!--指定hdfs的虚拟服务名-->
<property>
<name>dfs.nameservices</name>
<value>qf</value>
</property>
<!--指定hdfs的虚拟服务名下的namenode的名字-->
<property>
<name>dfs.ha.namenodes.qf</name>
<value>nn1,nn2</value>
</property>
<!--指定namenode的rpc内部通信地址-->
<property>
<name>dfs.namenode.rpc-address.qf.nn1</name>
<value>hadoop01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.qf.nn2</name>
<value>hadoop02:8020</value>
</property>
<!--指定namenode的web ui界面地址-->
<property>
<name>dfs.namenode.http-address.qf.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.qf.nn2</name>
<value>hadoop02:50070</value>
</property>
<!--指定jouranlnode数据共享目录 namenode存放元数据信息的Linux本地地址 这个目录不需要我们自己创建-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/qf</value>
</property>
<!--指定jouranlnode本地数据共享目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hahadoopdata/jouranl/data</value>
</property>
<!-- 开启namenode失败进行自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--指定namenode失败进行自动切换的主类 datanode存放用户提交的大文件的本地Linux地址 这个目录不需要我们自己创建-->
<property>
<name>dfs.client.failover.proxy.provider.qf</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--防止多个namenode同时active(脑裂)的方式 采用某种方式杀死其中一个-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://qf/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<!--将hbase的分布式集群功能开启-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/zkdata</value>
</property>
</configuration>
idea的配置

















 1672
1672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









