




 本文详细介绍了Hive的安装过程,包括环境配置、XML文件修改、MySQL集成等关键步骤,并演示了基本操作如创建数据库、表,加载数据及查询。
本文详细介绍了Hive的安装过程,包括环境配置、XML文件修改、MySQL集成等关键步骤,并演示了基本操作如创建数据库、表,加载数据及查询。
Hive的概念介绍
白话讲
Hive是一个镶嵌在hadoop上的一个壳子
只是把SQL语句翻译成MapReduce
然后去查找HDFS上的数据
还可以理解成一个映射
Hive还有一个功能就是把HDFS上的数据映射成一张表

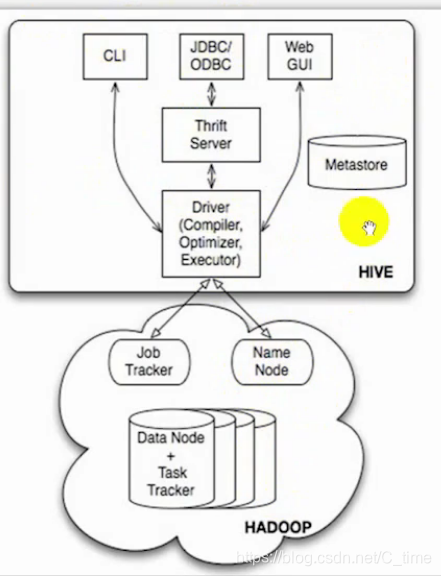
看图就能看出来
Hive基于Hadoop
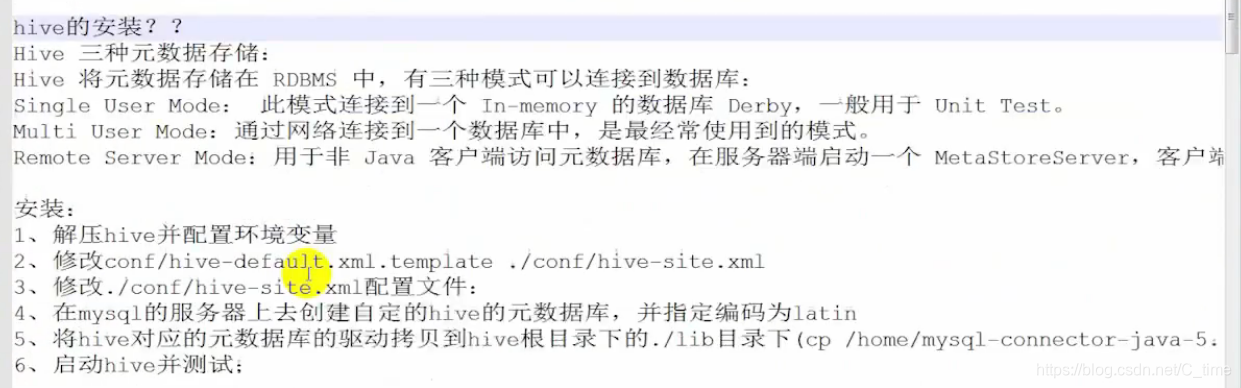
Hive的安装
将安装包拖到home下 看下面的操作
解压
改名
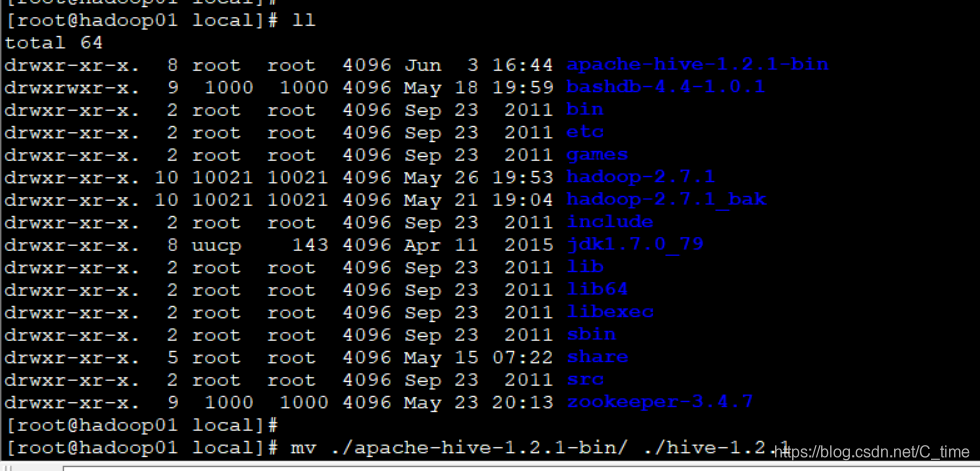
看看hive的结构
然后配置环境变量
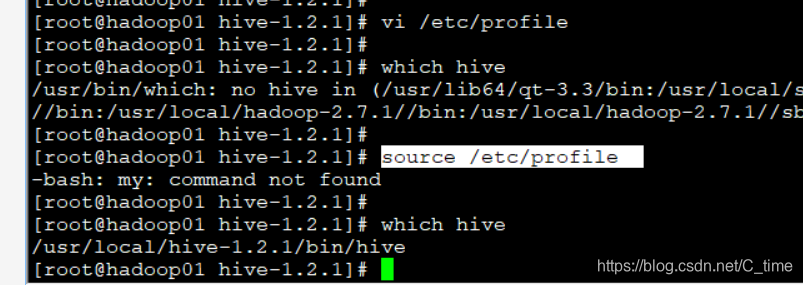
vi /etc/profile

查看是否配好环境变量 要先source一下再which
这样截图上第一步就完成了
2.修改…xml
先改个名
mv ./conf/hive-default.xml.template ./conf/hive-site.xml
然后我们要修改其中内容
不过就是那个 太麻烦使用shell
我们将文件复制到home然后拖出来改
暂时不使用notepad的NTP连接功能

然后注释 和其他内容都删掉 只留这个
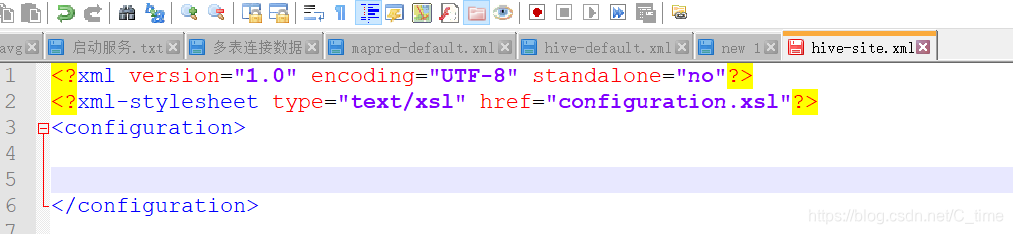
然后通过下面的文件地址复制相关内容配置
找hive-default.xml.template的地址
https://github.com/mrmichalis/hadoop-cdh/blob/master/hive/conf/hive-default.xml.template
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定元数据存储的数据库信息-->
<property>
<name>hive.default.fileformat</name>
<value>TextFile</value>
</property>
<!--指定元数据存储元数据的连接驱动-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/onhive</value>
</property>
<!--指定元数据存储元数据的连接用户名-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--指定元数据存储元数据的连接用户名密码-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!---->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
具体就这么点
覆盖conf的那个文件
这里问你是否覆盖 要输yes不然就不覆盖了
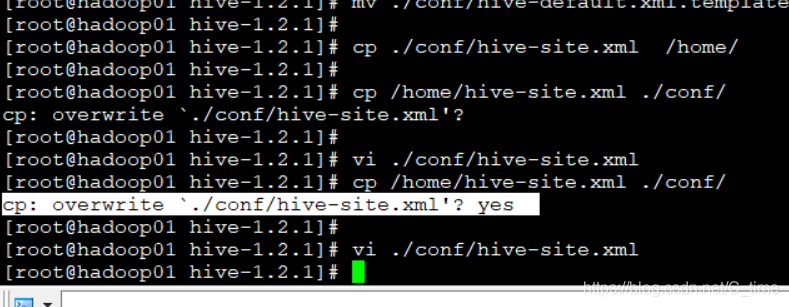
这样第三步也完成了
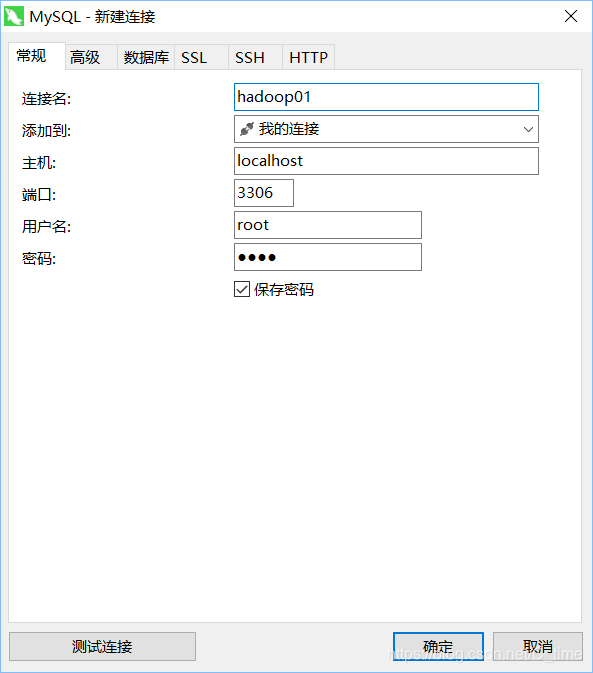
4.在mysql上创建对应的…
新建一个连接 用户名密码端口号都是刚刚的
请注意 这里是错误的
哪里错了呢 新建连接这个错了 主机 写错了
而且现在还没有下mysql Linux版的
因为视频上根本没说 一句话带过了 先略过 后面说
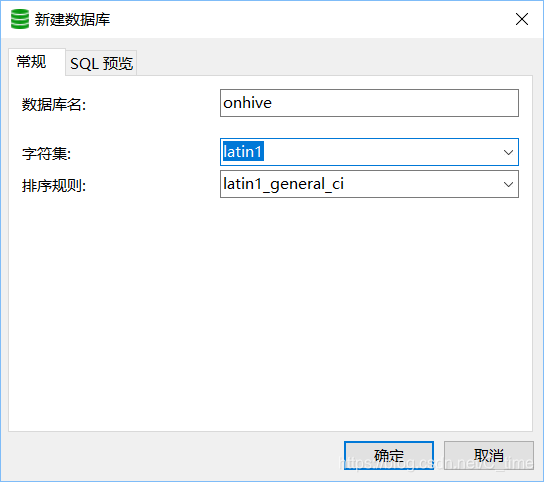
新建的数据库名字是onhive 跟配置文件一样 还有编码格式latin1
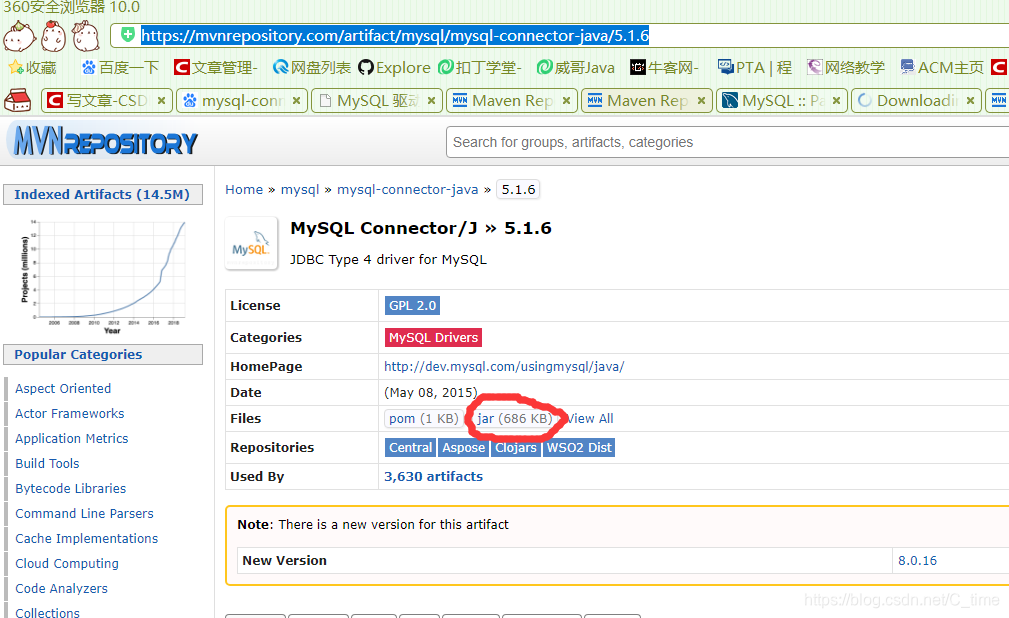
先拷贝 jar包吧
5.然后把jar包拷贝到…
注意版本

jar包
https://mvnrepository.com/artifact/mysql/mysql-connector-java/5.1.6
6.启动测试 先启动集群
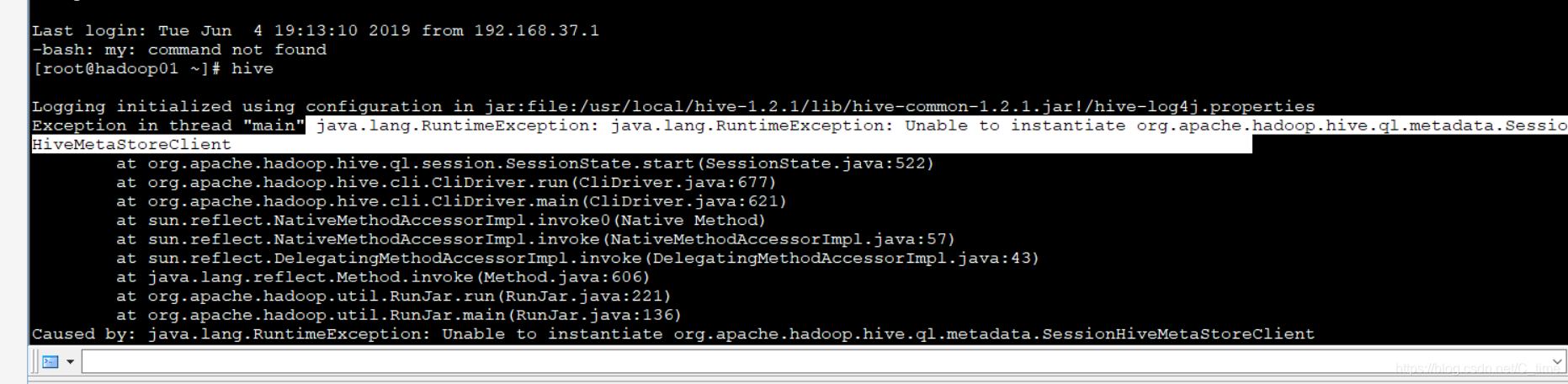
输入hive命令 这样我就失败了

到这来 hive是初步安装完成
我们现在需要安装在Linux上安装mysql
在002博客我们修改了yum的默认配置
使用本地的源 第三个
不过我试了 安装不上 所以 我们需要在线安装
所以需要修改 使用第一个
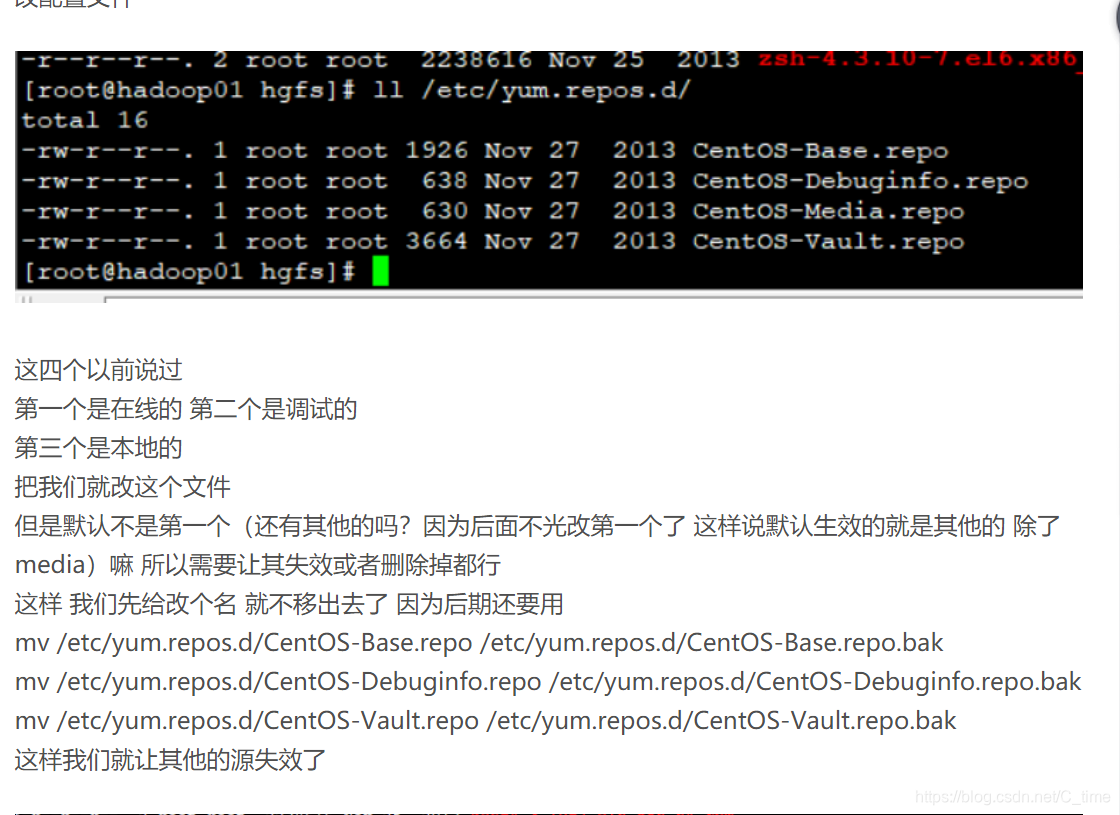
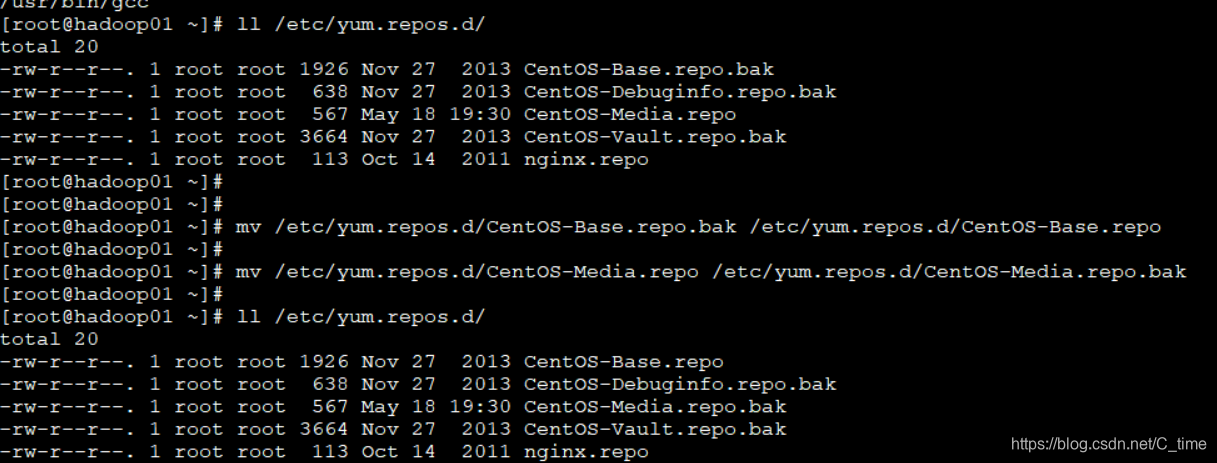
mv /etc/yum.repos.d/CentOS-Base.repo.bak /etc/yum.repos.d/CentOS-Base.repo
mv /etc/yum.repos.d/CentOS-Media.repo /etc/yum.repos.d/CentOS-Media.repo.bak
ll /etc/yum.repos.d/
这样改完了 我们下载
下面的两个文件 使用yum
yum -y install mysql-server.x86_64 mysql-devel.x86_64
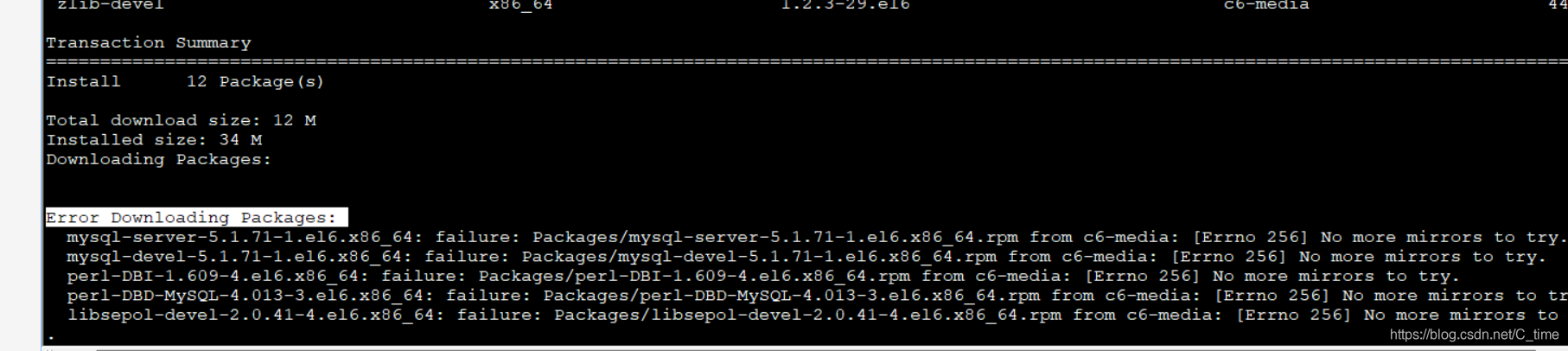
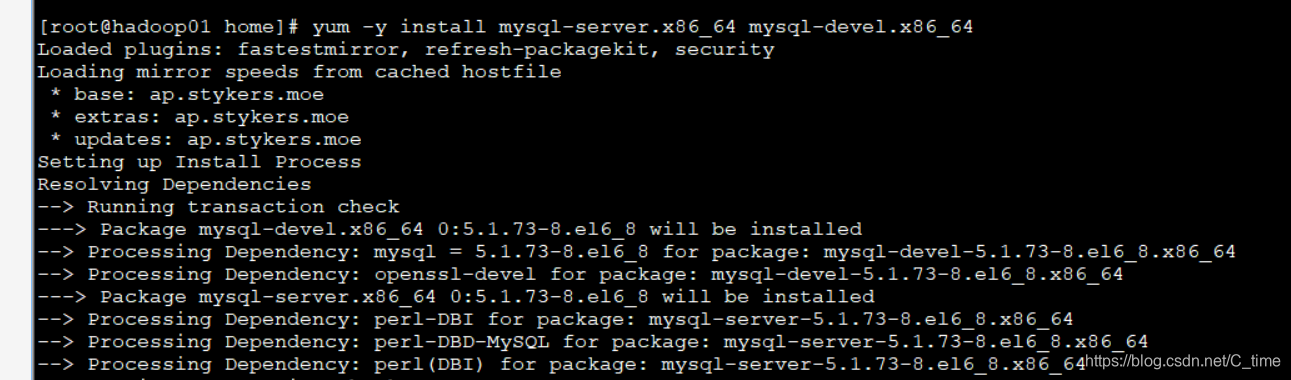
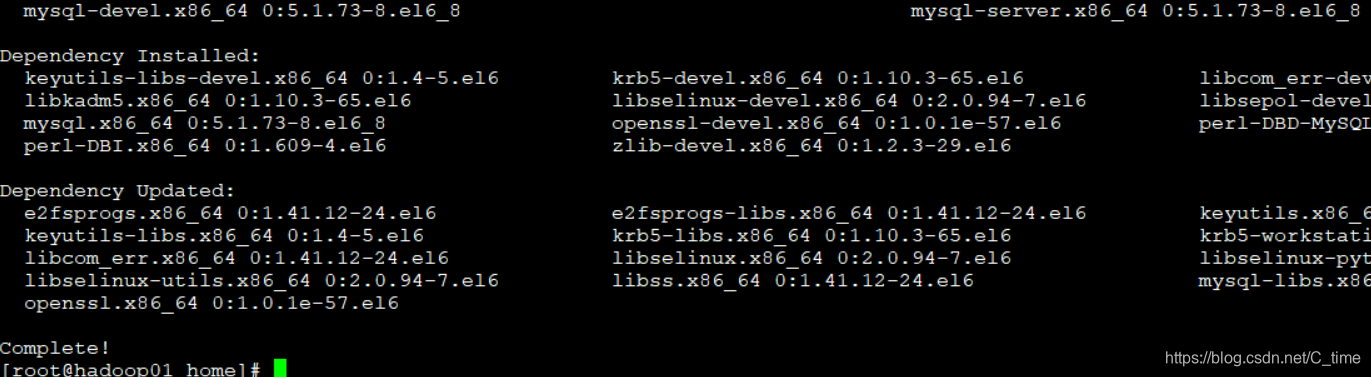
这一步应该在下载之前 查看mysql相关的东西 我们找出那两个需要下载的 不然也不知道怎么写出来这么长的名字啊 哈哈
yum list | grep mysql
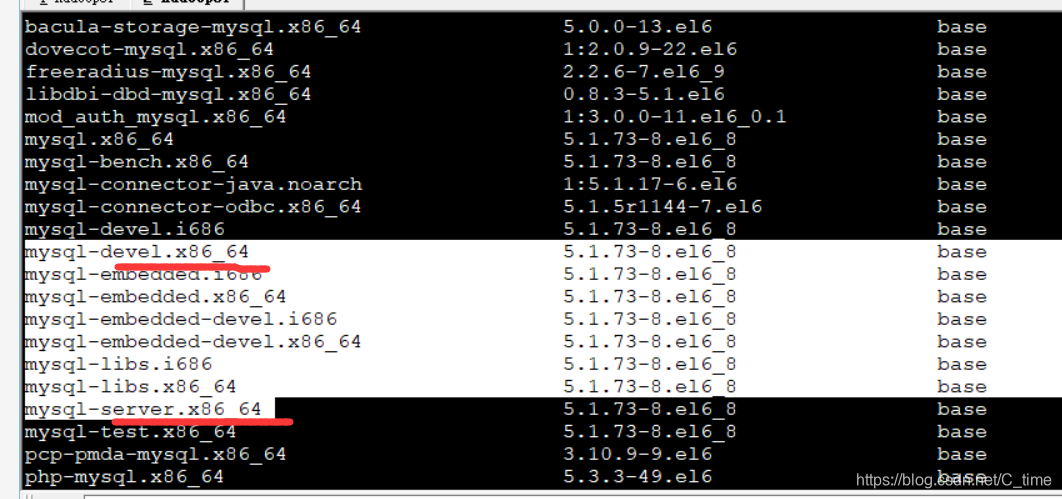
然后下载完了就需要配置了

1.启动数据库服务
service mysqld start
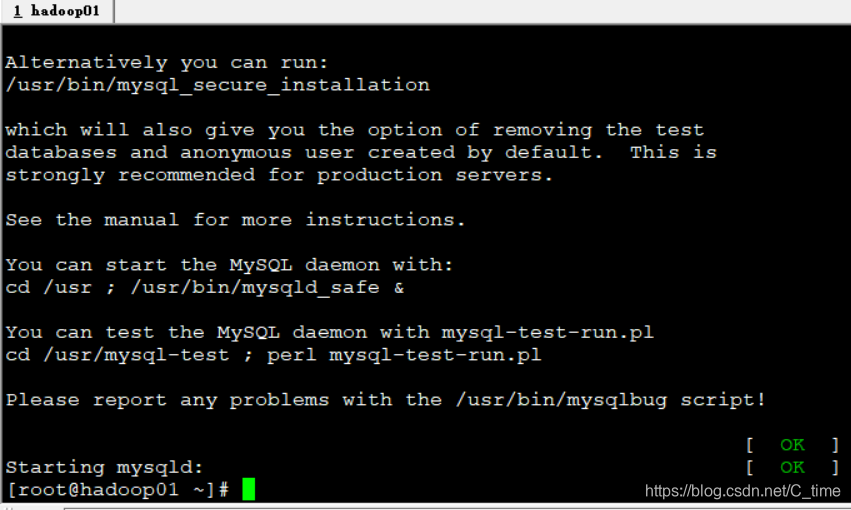
2.设置开机启动mysqld服务
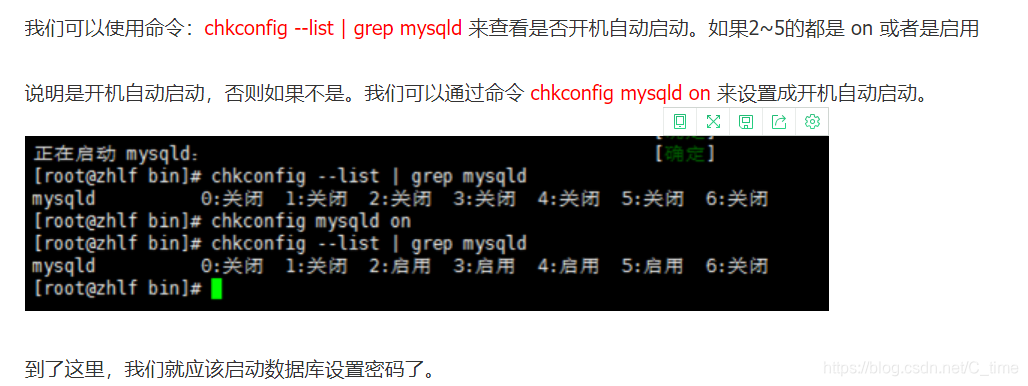
3.设置密码
这个设置仅有一次机会 如果设置错了 请百度再次设置
我们设置为之前安装hive时的配置文件 用户名密码都是root
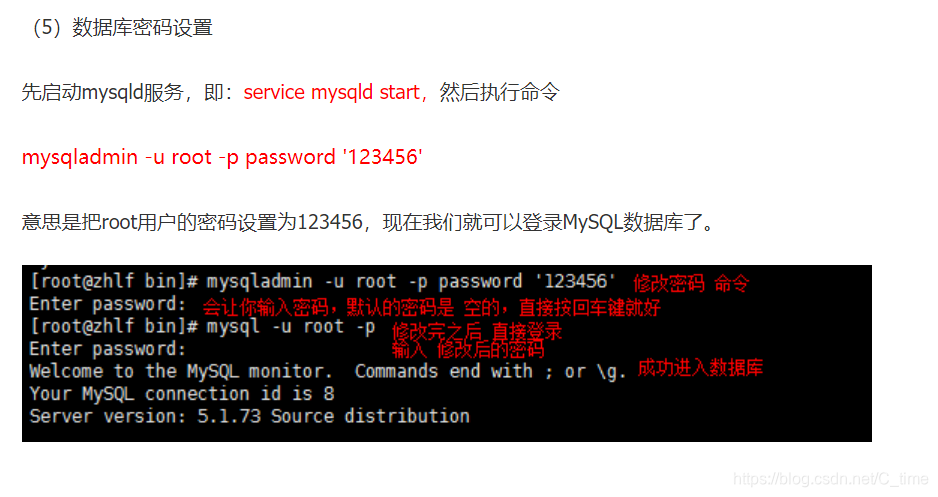
4.然后登陆
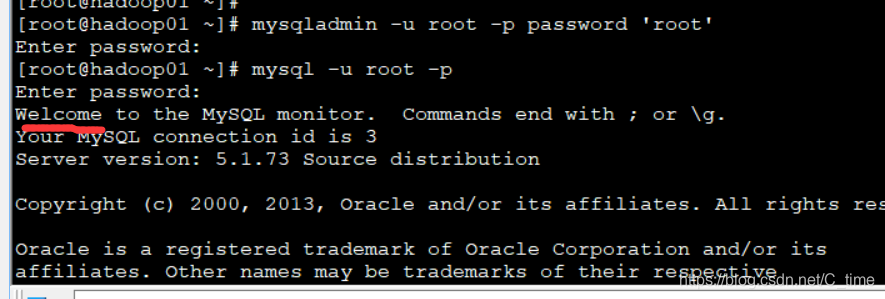
5.设置navicat远程连接
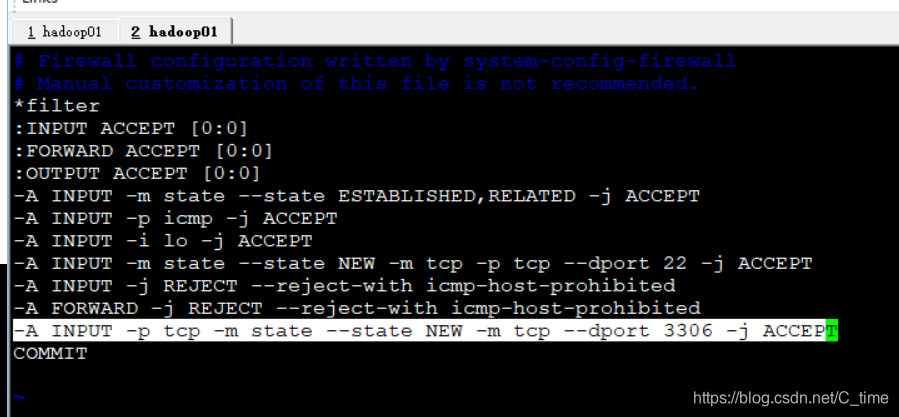
先添加开放3306端口
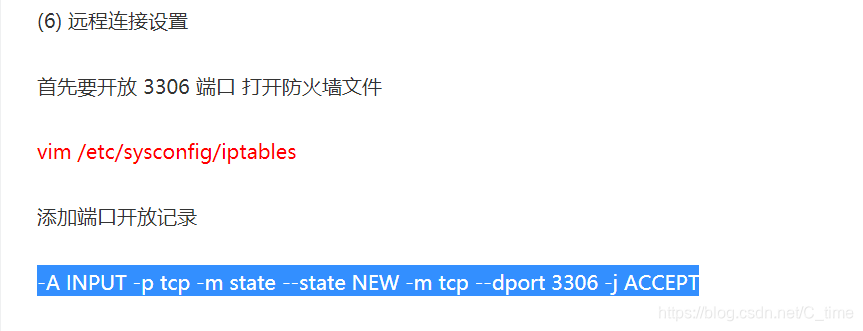
-A INPUT -p tcp -m state --state NEW -m tcp --dport 3306 -j ACCEPT
然后授权
两种方法
第一种我个人感觉麻烦
直接使用第二种
一句话搞定
记得刷新
https://www.cnblogs.com/blogforly/p/5997553.html

然后设置连接
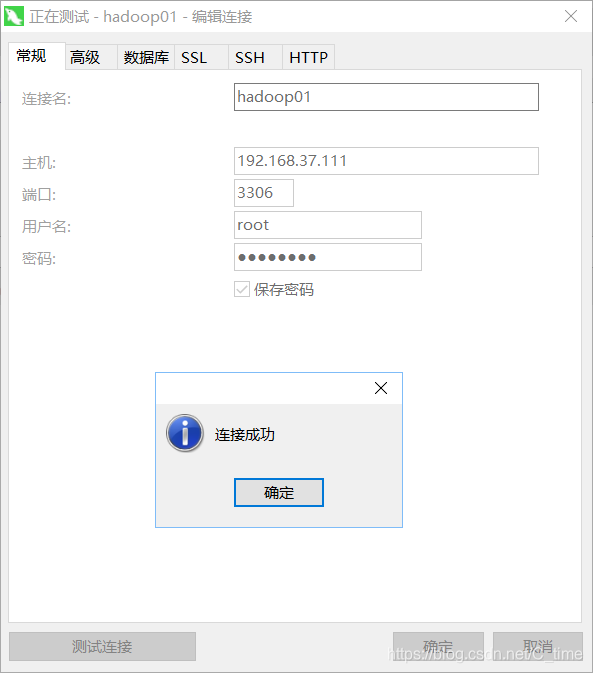
没问题的
上面
然后吧
我们建个数据库
跟hive配置文件要匹配
onhive名字
注意编码格式
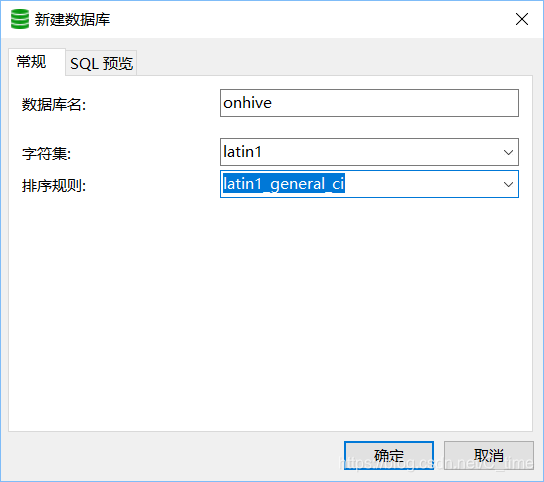
这样都安好了
我们再次启动hive试试
先启动集群
然后hive还是错了
service mysqld status 查看是否启动mysql服务
这个东西我又搞了一晚上
百度
改了又改
还重装了一遍
还是错误
最后
看了个帖子
真的搞不懂
为什么
抓狂!!!一晚上啊

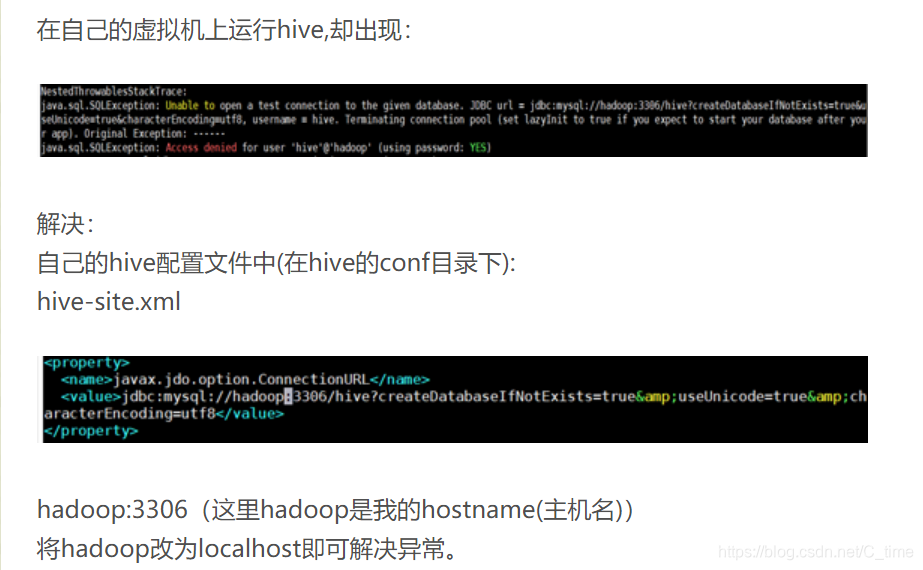
我将hadoop01
改成localhost就好了
原来onhive数据库是没有表的
现在打开一看
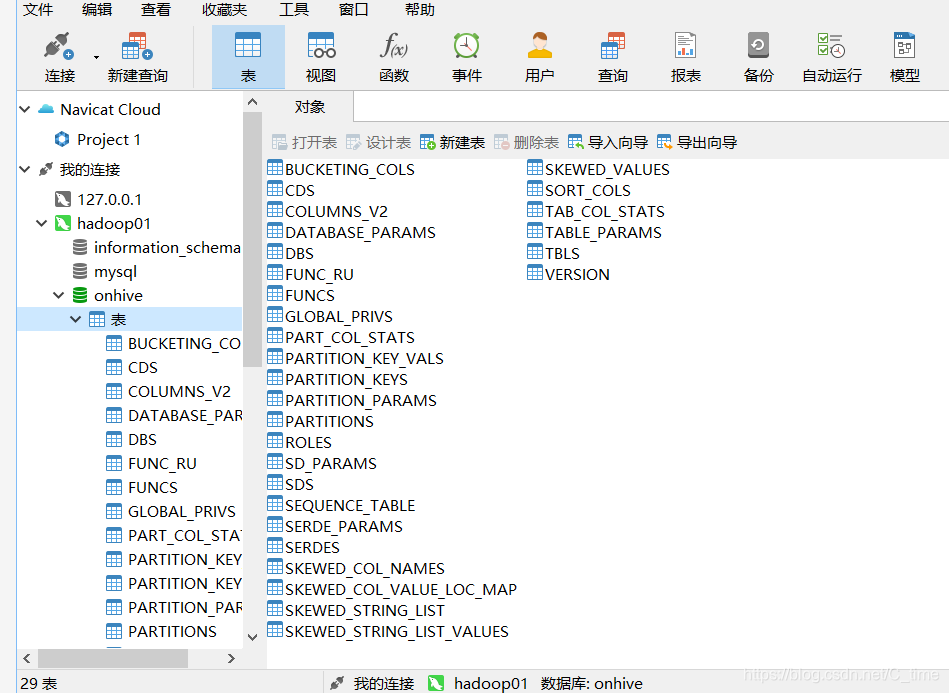
这些信息就是我们的元数据
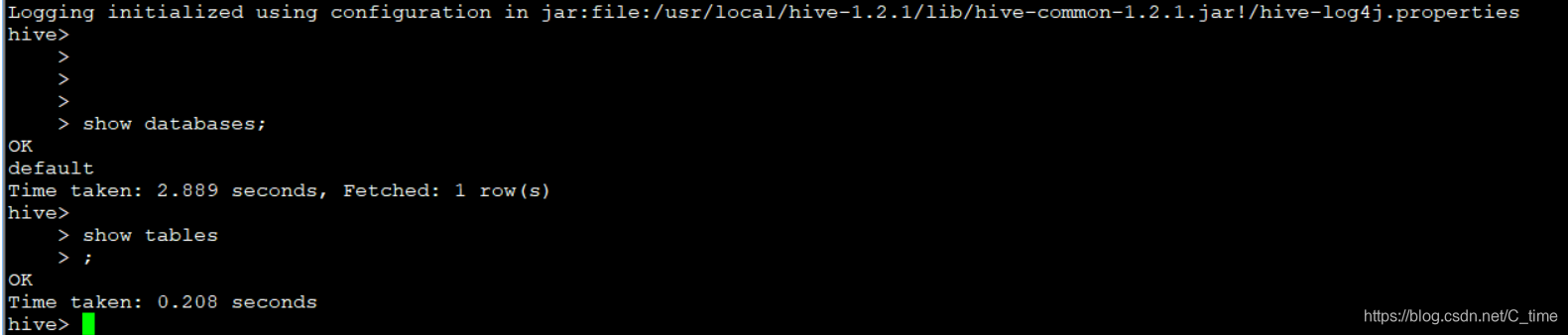
输入两个命令试试
show databases;
就一个默认的
show tables;
没有内容
Hive的基本命令

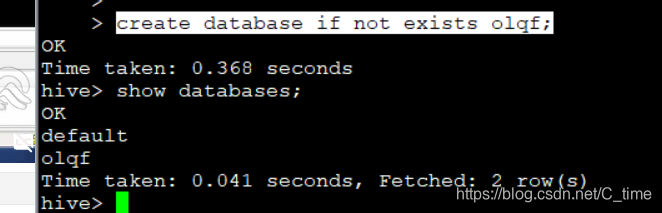
创建数据库 create database if not exists olqf;
查看所有数据库 show databases;
切换到某个数据库 use olqf;
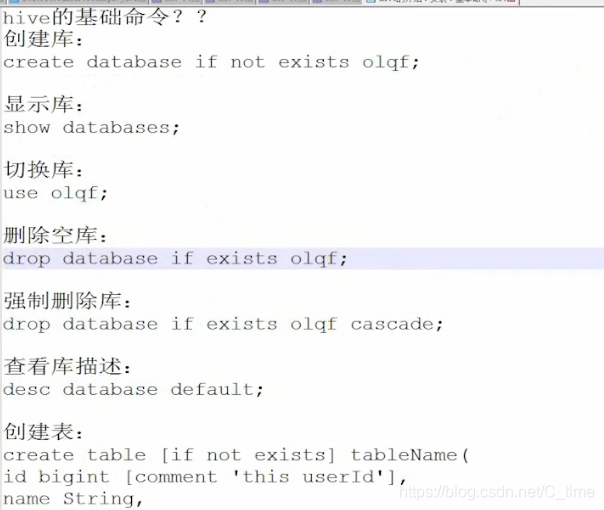
删除 空 的 数据库 drop database if exists olqf; 不是空的不能删除
要加cascade才能强制删除非空数据库
desc database olqf;
查看库的描述信息
下面还有具体位置

- hdfs数据仓库的根目录
hdfs dfs -ls /user/hive/warehouse

然后就可以看到我们新创建的库的目录
数据库文件就是加上.db
创建表
comment是注释


三个字段 id name sex
id有个描述注释
下面表也有个描述注释
然后字段的分隔符是\t 是数据源之间的 就是这张表所指向的数据的列与列之间的分隔符是\t
然后这张表所指向的数据的行与行之间的是\n
最终存储的文件格式为文本文件格式
create table if not exists u1(
id bigint comment 'this userId',
name String,
sex tinyint
)
comment 'this is table of user'
row format delimited fields terminated by '\t'
lines terminated by '\n'
stored as textfile
;
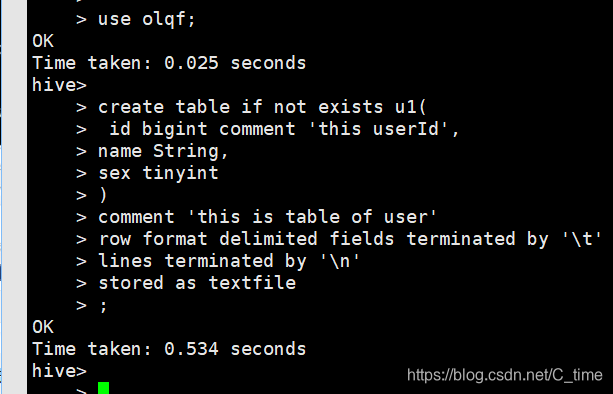
在olqf数据库创建表
然后我们查看一下
hdfs dfs -ls /user/hive/warehouse/olqf.db

弄个u1传上来 tab键分隔
现在u1这个文件再home下的olddata(刚建的)目录下
即在Linux系统上
怎么加载到hive上呢
加载数据
load data local inpath '/home/olddata/u1' into table u1;
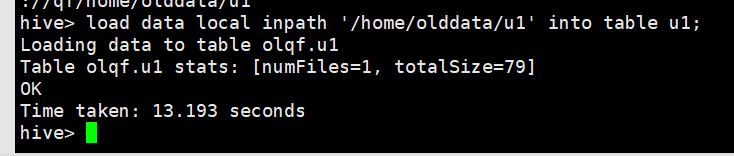
然后我们查看数据仓库 hdfs下的
hdfs dfs -ls /user/hive/warehouse/olqf.db/u1
u1表下多了个u1文件

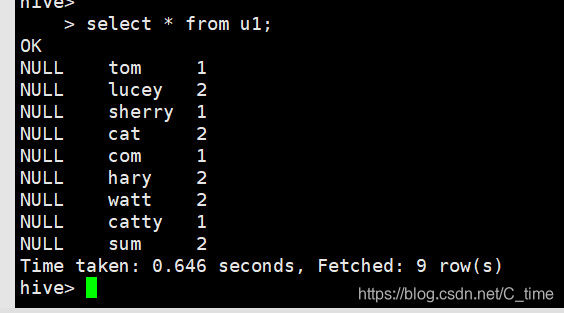
然后我们查表select * from u1;

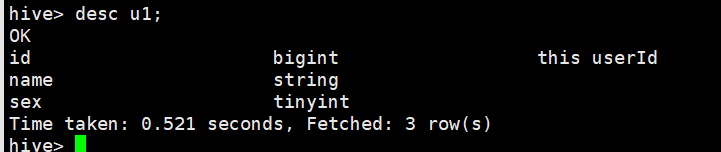
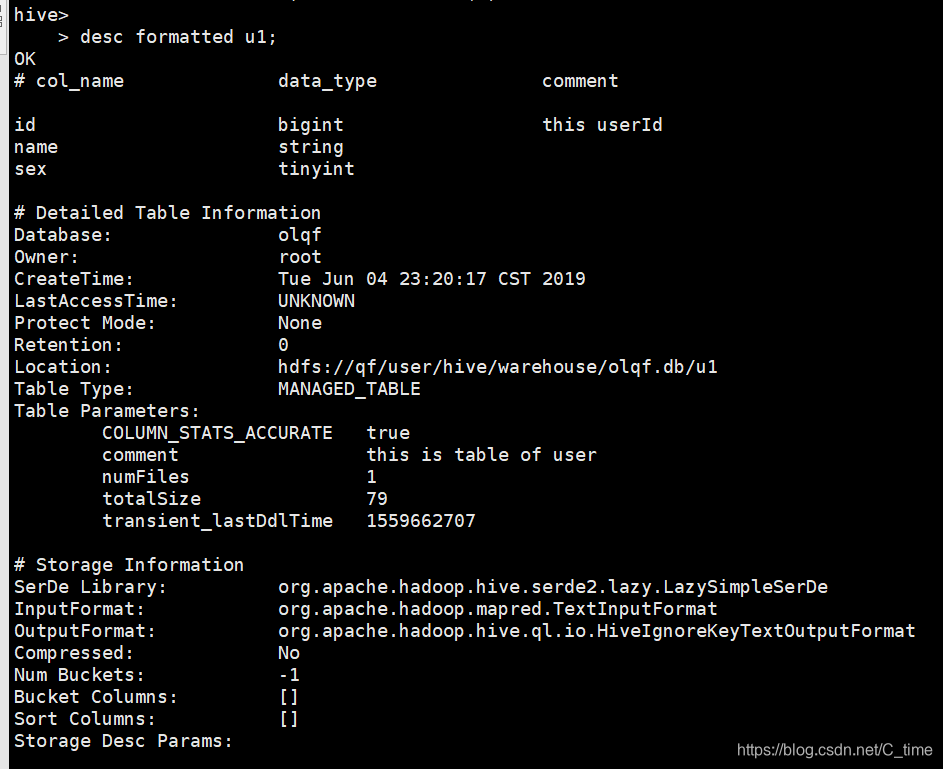
查看表描述
desc u1;
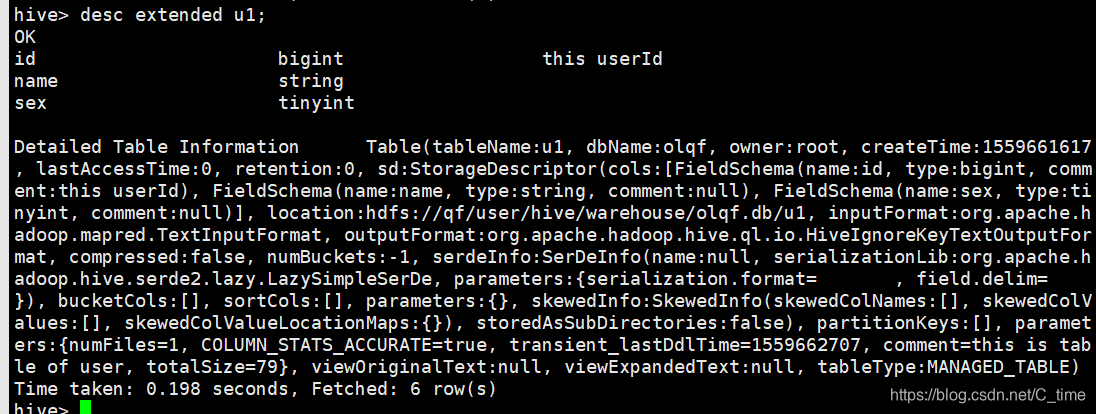
desc extended u1;
desc formatted u1;
show create table u1;
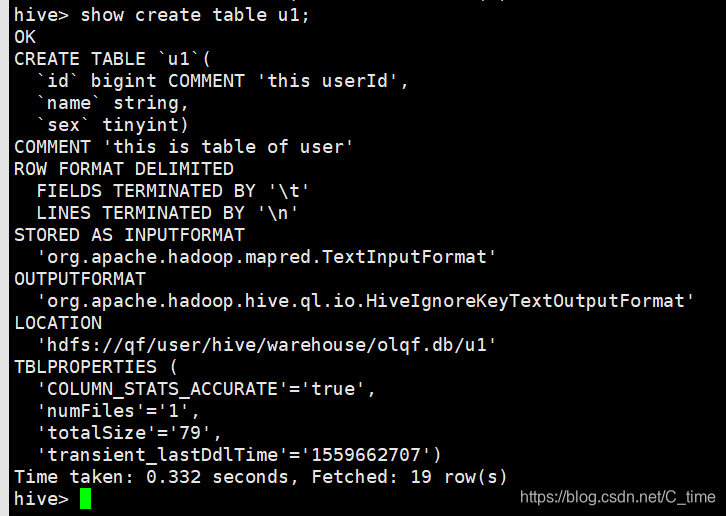
创建表的本质:
- 在hdfs中对应的库下面创建目录
- 在元数据表中添加对应信息
加载数据的本质
- 将数据copy或者是移动到表目录下面即可
然后创建一个u3 内容跟u1一样
1使用hdfs查看仓库目录

2.同样我们可以打开navicat 查看已经创建的表 那个多的u1是我在olqf库外面创建的 创建错了
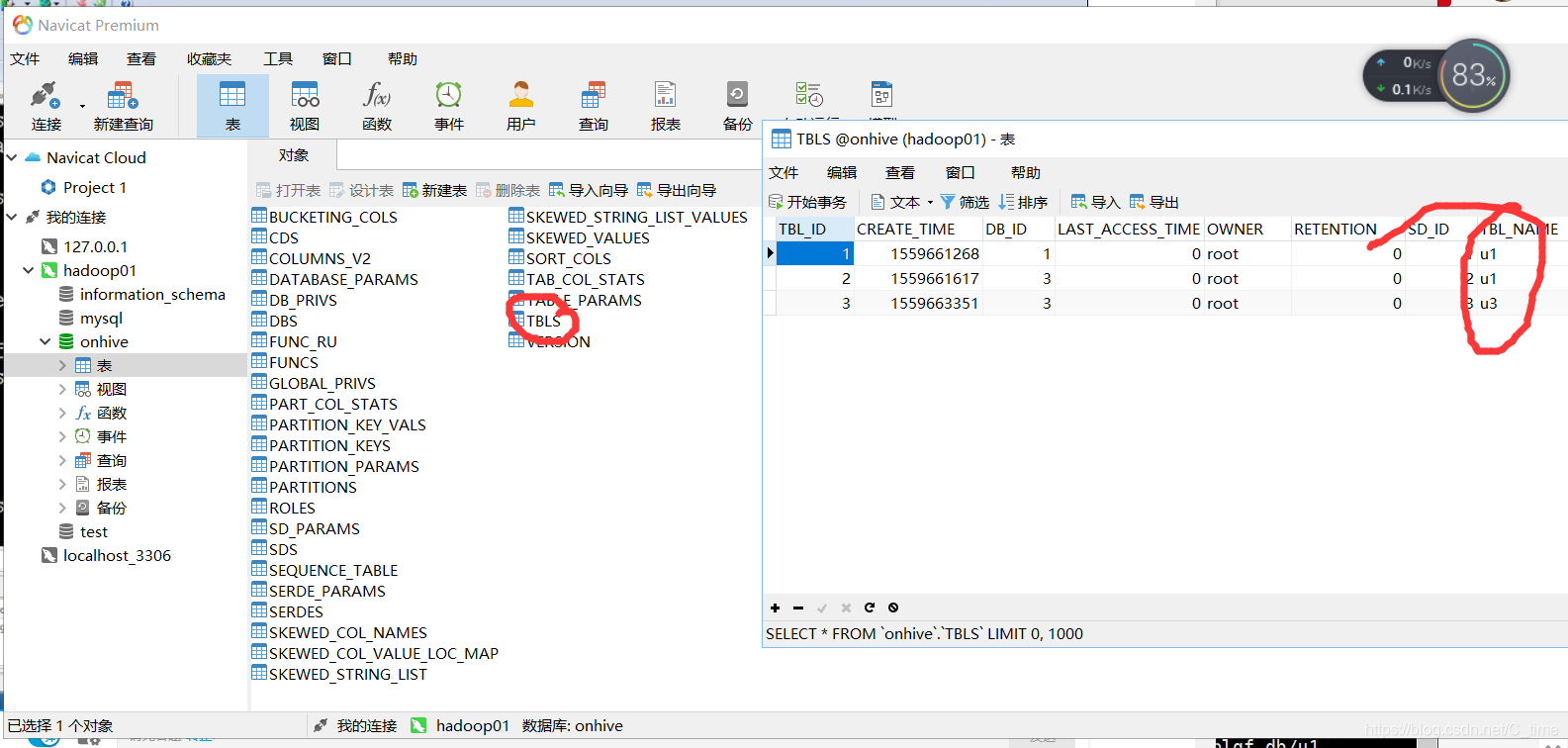
3.自己查看.select 没有内容
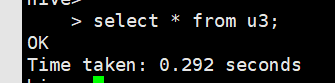
加载数据(第1种方式上传)
load data local inpath ‘/home/olddata/u1’ into table u1;
我们原来使用这句
去掉local之后
就代表从hdfs加载数据
先将u1内容表传到hdfs根目录下

然后上传(第二种方式上传)
load data inpath '/u1' into table u3;
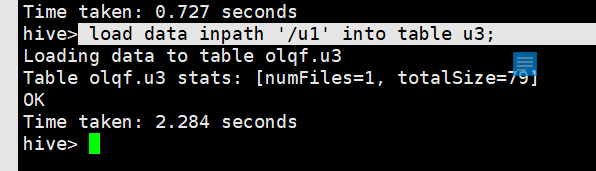
然后好了
上传成功 有内容了
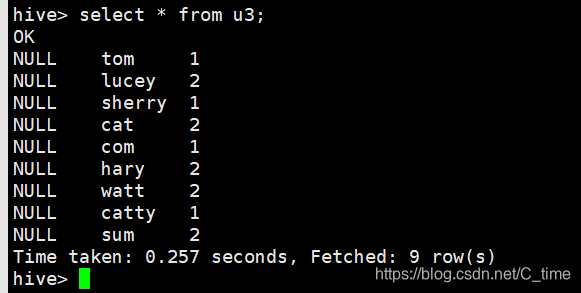
这样u3表下多一个数据文件

然后创建一个u2
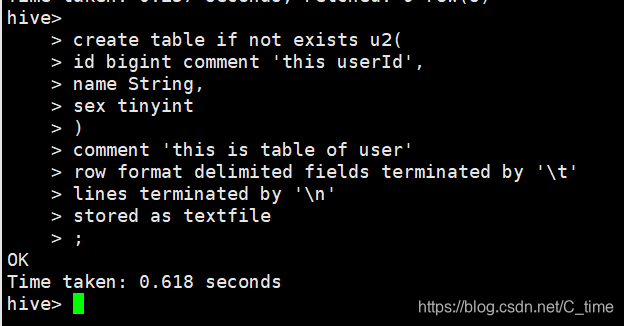
这样u2是没有东西的
我们还有另外一种传数据的方式
insert into u2
select id,name,sex
from u1
;
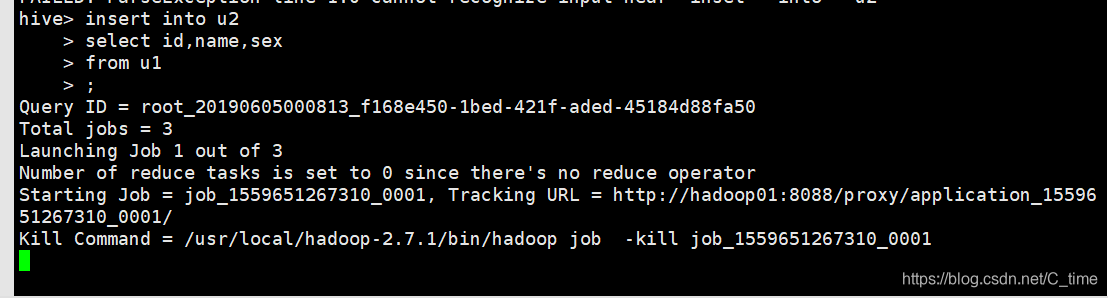
注意它把insert语句转为三个job任务跑动
跑完后我们看下
select * from u2;
查询表 和mysql几乎一样
删除表
drop table if exists u1;
我们重新进入到hive 注意不是在olqf库里了 删除那个多余的u1
果然没了

创建外部表external
create external table if not exists log(
id string comment 'this is id column',
phonenumber bigint,
max string,
ip string,
url string,
title string,
colum1 string,
colum2 string,
colum3 string,
upflow int,
downflow int
)
comment 'this is log table'
row format delimited fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
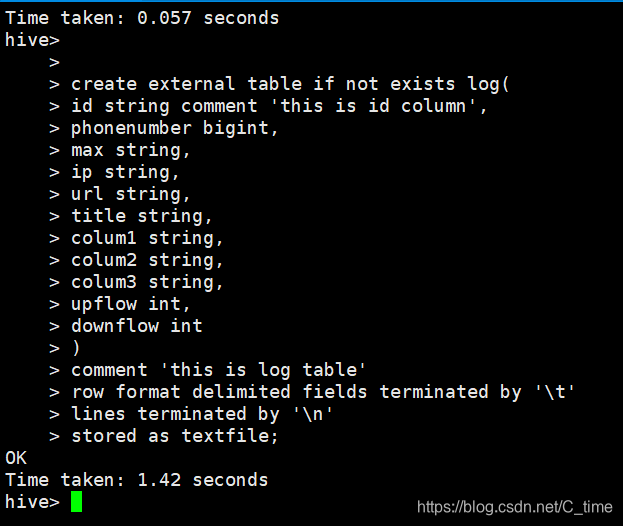
外部表类型不一样
加载数据
load data local inpath ‘/home/olddata/data.log’ overwrite into table log;
没有数据文件爱你
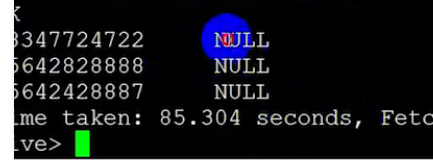
就截图看视频的把 那个null就不管了 视频的也有问题
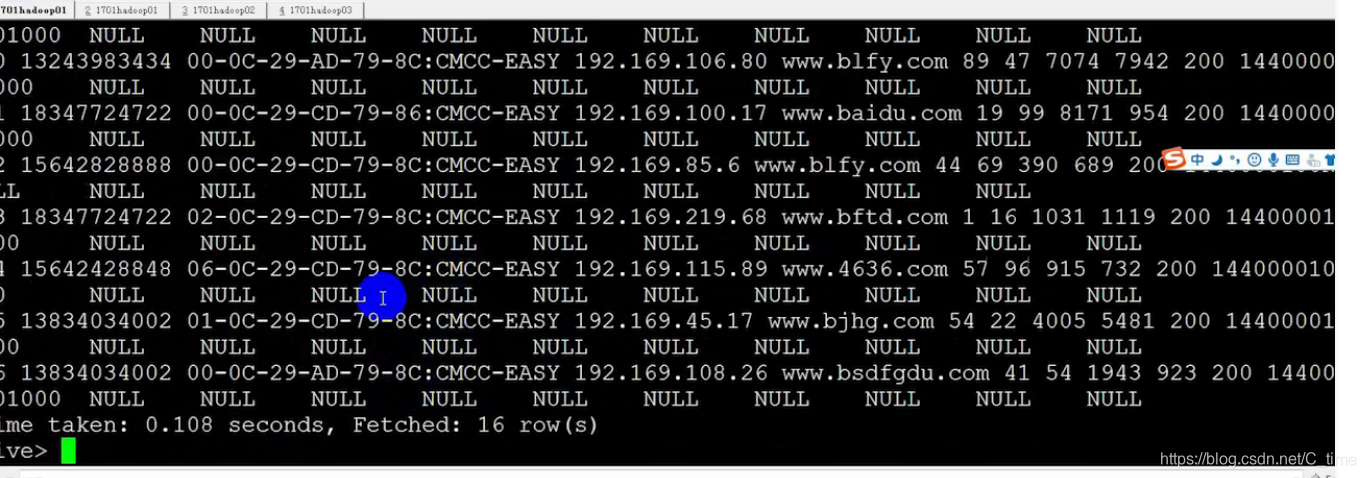
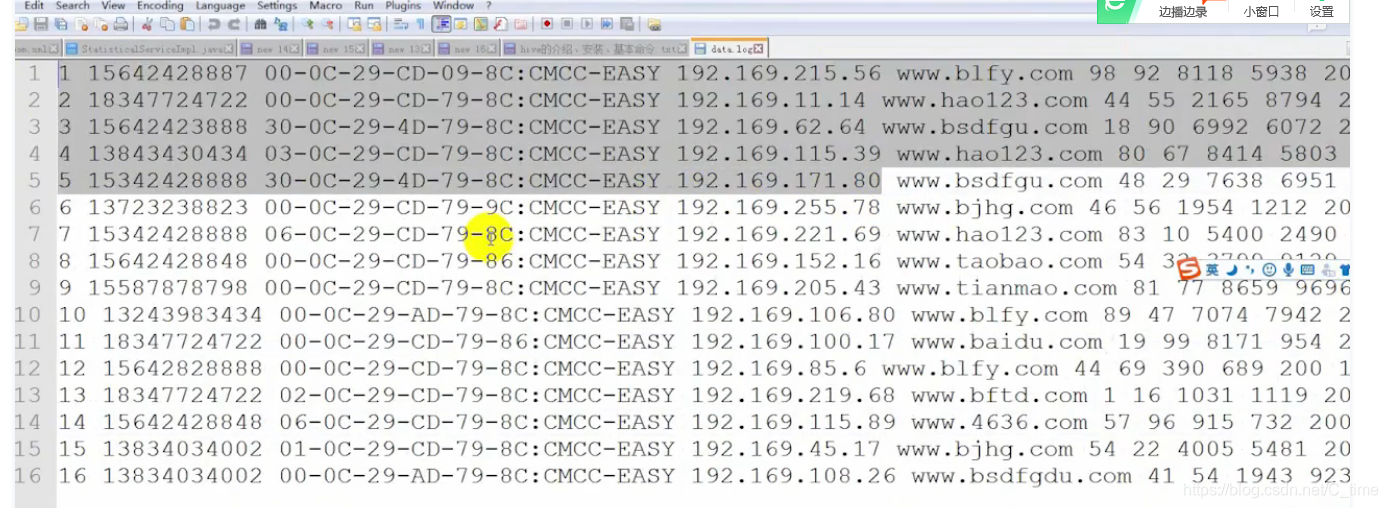
看上面两张图 明明没有问题
为什么会读出这么多NULL呢
我们数一下 (其实是视频数的)
总共有十一个字段 hive读出来十一个值后有出来了十个NULL
所以原来hive把这十一个值当成了一个字段
原因就是我们写数据时用空格分开了
而建表时字段间隔是\t
所以出错了
所以
hive是读时模式 读的时候才去确定字段类型 间隔 对的话就对 不对就用NULL代替
关系型数据库是写时模式 mysql的话如果不对就不让插入了 就报错了
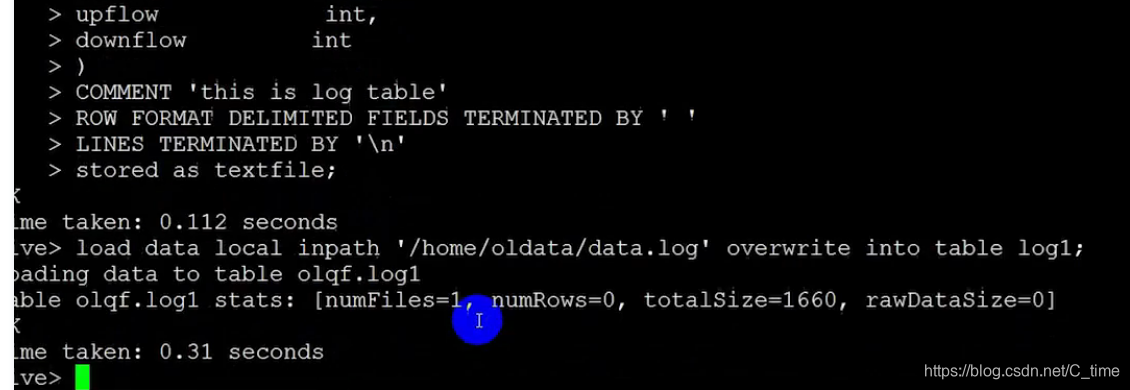
这样重新创建表log1使用空格分隔
create external table if not exists log1(
id string comment 'this is id column',
phonenumber bigint,
max string,
ip string,
url string,
title string,
colum1 string,
colum2 string,
colum3 string,
upflow int,
downflow int
)
comment 'this is log table'
row format delimited fields terminated by ' '
lines terminated by '\n'
stored as textfile;
然后加载数据进表
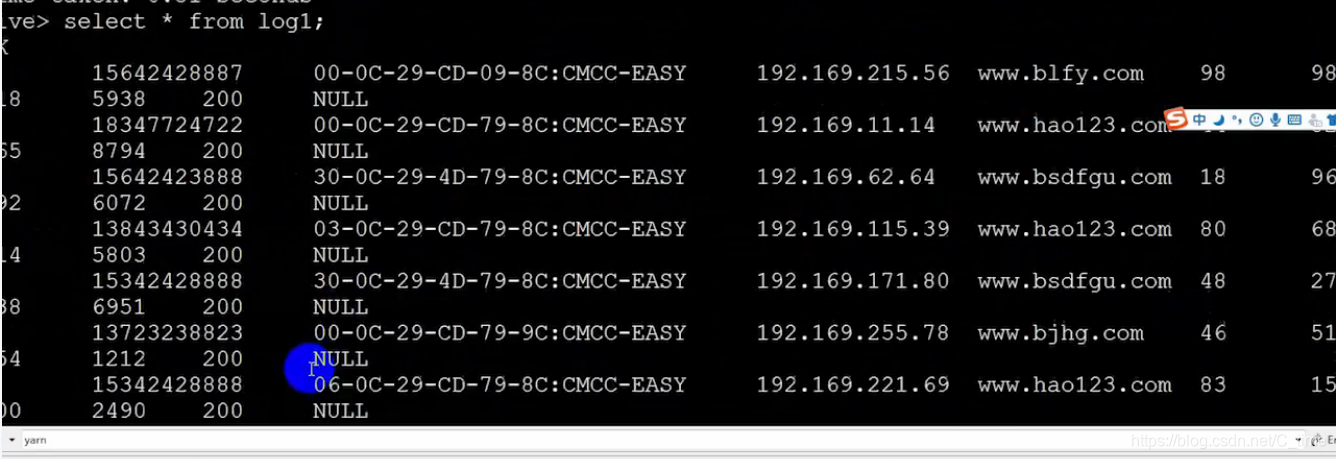
现在再查询就没有NULL了 正常了
 现在来查询一下
现在来查询一下
上行流量加下行流量的前三名的总和
根据手机号分组
根据上下行流量总和ud排序
取前三名
select
l.phonenumber,
sum(l.upflow + l.downflow) as ud
from log1 l
group by l.phonenumber
order by ud desc
limit 3
;
数据表还有有问题的
不过结果已经出来了
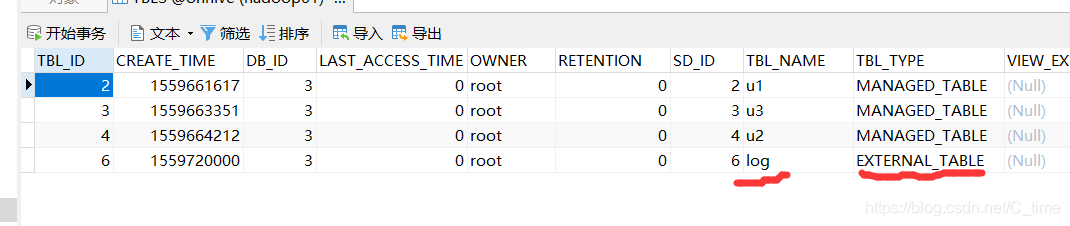
外部表和内部表的区别

删除内部表u2
删除之前还有
删除之后就没有目录了

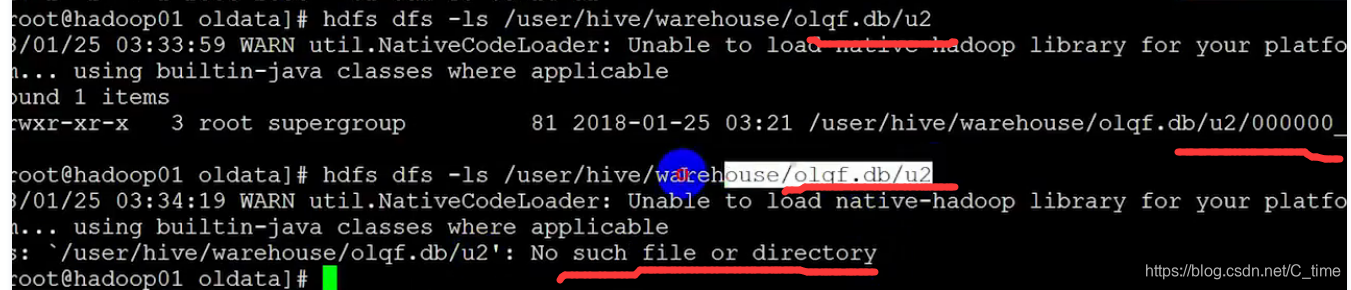
删除外部表
hdfs仓库仍然还有


这个自己看看
xsehll6安装步骤
工具在d盘
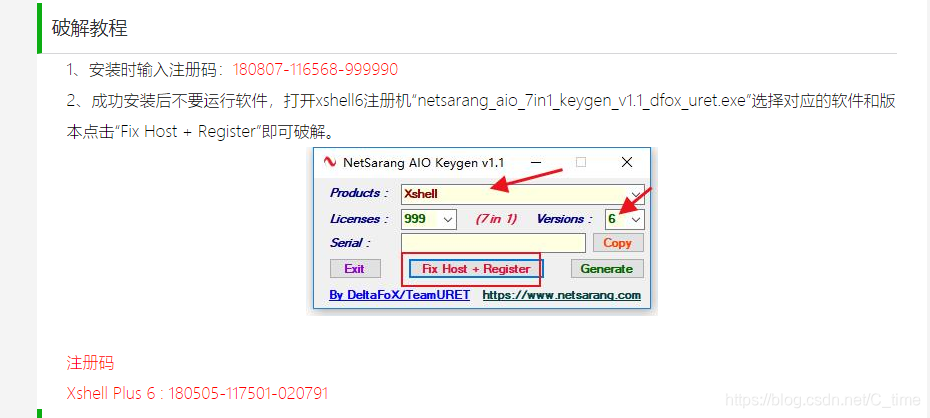

















 2496
2496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









