 MySQL学习与实践
MySQL学习与实践




 这篇博客主要记录了MySQL的安装、重装与配置过程,包括在Ubuntu上的安装与卸载,以及遇到的问题和解决方法。此外,还探讨了MySQL的查询缓存、分析器、优化器和执行器的工作原理,强调了长连接与短连接的管理,以及事务隔离级别的概念。内容还涉及到了日志系统,包括redo log和binlog,以及它们在数据恢复和备份中的作用。最后,提到了索引模型和事务管理,对数据库性能优化提出了一些建议。
这篇博客主要记录了MySQL的安装、重装与配置过程,包括在Ubuntu上的安装与卸载,以及遇到的问题和解决方法。此外,还探讨了MySQL的查询缓存、分析器、优化器和执行器的工作原理,强调了长连接与短连接的管理,以及事务隔离级别的概念。内容还涉及到了日志系统,包括redo log和binlog,以及它们在数据恢复和备份中的作用。最后,提到了索引模型和事务管理,对数据库性能优化提出了一些建议。
2018.12.18
ubuntu14.04上之前安装mysql且用着没问题,今天检查mysql服务状态:sudo /etc/init.d/mysql status
显示mysql stop/waiting
启动服务sudo /etc/init.d/mysql start
显示mysql start: Job failed to start
检查/etc/mysql 的访问权限是755没问题,重启虚拟机没用,
也没继续考虑其他问题,算了,卸载了重装:
卸载:
sudo apt-get remove mysql-*
dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg -P
安装:
sudo apt-get install mysql-server
sudo apt-get install mysql-client
检查mysql服务状态:sudo /etc/init.d/mysql status
显示mysql start/running, process 12418
客户端连接:mysql -hlocalhost -uroot -p123456
ok了
2018.12.18
又是更改默认字符集utf8 # vi /etc/mysql/my.cnf
又出现问题 mysql start: Job failed to start
通过查看 cat /var/log/mysql/error.log
发现 [ERROR] /usr/sbin/mysqld: unknown option '--Skip-external-locking'
应该是复制网上的代码,产生的错误,码的!
S改成s后,成功restart sudo /etc/init.d/mysql restart
导出表到目录/var/lib/mysql-files/zone
发现ERROR 1 (HY000): Can't create/write to file '/var/lib/mysql-files/zone/areas.txt' (Errcode: 13 - Permission denied)
于是chmod 777 ./zone
mysql图形界面
ubuntu 16.04系统下 安装mysql服务,及安装图形化管理界面
sudo apt-get install mysql-workbench
2019.1.8
在插入大二进制文件(音乐)时,需要使用BLOB字段,修改配置:
mysql> show global variables like '%timeout%';
mysql> SET GLOBAL connect_timeout = 43200;
mysql> show global variables like 'max_allowed_packet';
mysql> set global max_allowed_packet=1024*1024*16;
01 | 基础架构:一条SQL查询语句是如何执行的?

Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
连接器:如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
建立连接的过程通常是比较复杂的,所以我建议你在使用中要尽量减少建立连接的动作,也就是尽量使用长连接。
但是全部使用长连接后,你可能会发现,有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
为此:1. 定期断开长连接。2. 重新初始化连接资源
查询缓存:查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
分析器:词法分析(识别字符串分别代表什么),语法分析(识别语法正确性)
优化器:选择使用索引;决定表的join顺序
执行器:检查查询权限,遍历表的行
02 | 日志系统:一条SQL更新语句是如何执行的?
引擎提供读写,server的执行器提供逻辑计算
WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志(和内存),再写磁盘,也就是先写粉板,等不忙的时候再写账本。
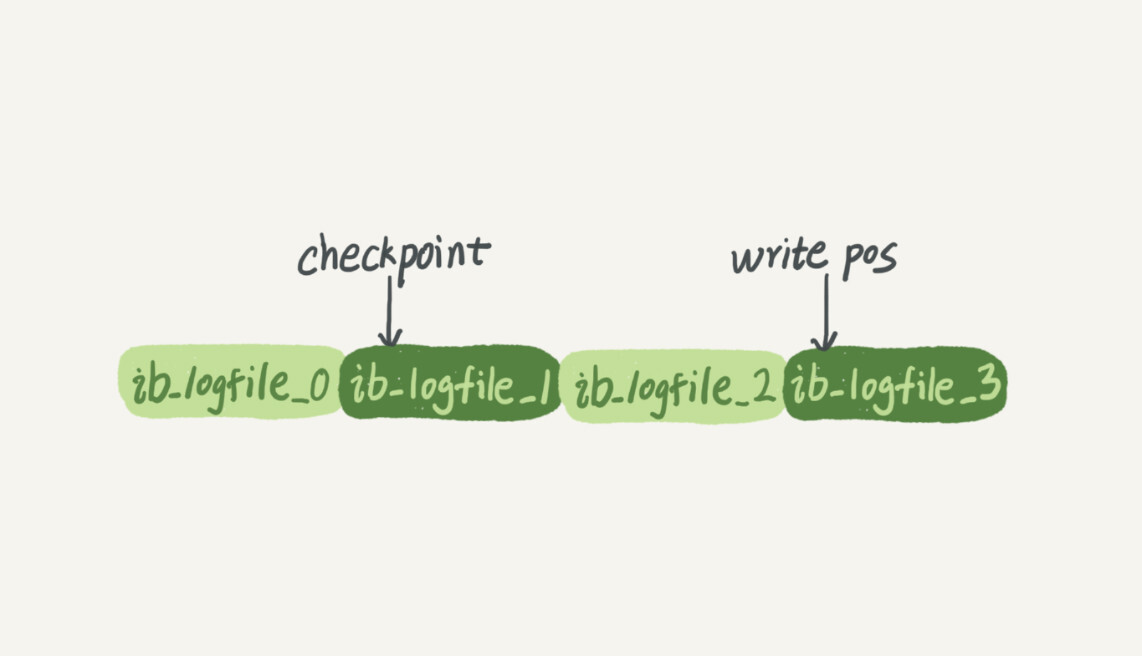
图为innodb引擎的日志redolog: checkpoint(粉板),writepos(账本),有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
为什么会有两份日志呢?
因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;Redo log不是记录数据页“更新之后的状态”,而是记录这个页 “做了什么改动”。
binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。Binlog有两种模式,statement 格式的话是记sql语句, row格式会记录行的内容,记两条,更新前和更新后都有。
redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。

当Commit命令发出之后,binlog日志会被写入各自线程的标准I/O缓存,然后Flush将每个线程的日志写入操作系统的文件缓存,此文件缓存为共享的,最后执行sync操作,将系统文件缓存中的日志写入至磁盘中。
commit是一个命令,“提交这个事务”,包含了整个提交过程(也就是说两次redolog和一次binlog操作,都是在你的这个commit命令中做的),Commit表示两个日志都生效了。如果两种log都写完成了,但是redolog没有写磁盘,物理机挂了,redolog在内存中就丢失了吧,再启动跟磁盘中的binlog就不一致,后期恢复数据的时候会有问题。因此innodb_flush_log_at_trx_commit 这个参数设置成 1 的时候,表示每次事务的 redo log 都直接持久化到磁盘。这个参数我建议你设置成 1,这样可以保证 MySQL 异常重启之后数据不丢失。
实际上,因为是两阶段提交,这时候redolog只是完成了prepare, 而binlog又失败,那么事务本身会回滚,所以这个库里面数据是提交之前的值。如果redolog是完整的,(包括了prepare和commit),就直接认为成功,不去判断binlog。
其核心就是, redo log 记录的,即使异常重启,都会刷新到磁盘;而 bin log 记录的, 则主要用于备份。
当需要恢复到指定的某一秒时,比如某天下午两点发现中午十二点有一次误删表,需要找回数据,那你可以这么做:
首先,找到最近的一次全量备份,如果你运气好,可能就是昨天晚上的一个备份,从这个备份恢复到临时库;
然后,从备份的时间点开始,将备份的binlog依次取出来,重放到中午误删表之前的那个时刻。
这样你的临时库就跟误删之前的线上库一样了,然后你可以把表数据从临时库取出来,按需要恢复到线上库去。
‘‘我自己的备份策略是设置一个16小时延迟复制的从库,充当后悔药,恢复时间也较快。再两天一个全备库和binlog,作为救命药,最后时刻用。这样就比较兼顾了。’’
‘‘如果支持恢复到最近7天任意时点,在库不大且备份空间足够的情况下,可一个全备+隔天一个增量来做,但保留最近7天的binlog。’’
‘‘2.响应一次SQL我理解是要同时操作两个日志文件,也就是写磁盘三次(redolog两次 binlog 1次)’’
03 | 事务隔离:为什么你改了我还看不见?
简单来说,事务就是要保证一组数据库操作,要么全部成功,要么全部失败。在 MySQL 中,事务支持是在引擎层实现的。你现在知道,MySQL 是一个支持多引擎的系统,但并不是所有的引擎都支持事务。比如 MySQL 原生的 MyISAM 引擎就不支持事务,这也是 MyISAM 被 InnoDB 取代的重要原因之一。
SQL 标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )。下面我逐一为你解释:
读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
Oracle 数据库的默认隔离级别其实就是“读提交”,因此对于一些从 Oracle 迁移到 MySQL 的应用,为保证数据库隔离级别的一致,你一定要记得将 MySQL 的隔离级别设置为“读提交”。
为什么建议你尽量不要使用长事务:
长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间。长事务还占用锁资源,也可能拖垮整个库。
MySQL 的事务启动方式有以下几种:
显式启动事务语句, begin 或 start transaction。提交语句是 commit,回滚语句是 rollback。
set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个 select 语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行 commit 或 rollback 语句,或者断开连接。
因此,我会建议你总是使用 set autocommit=1, 通过显式语句的方式来启动事务。此时,在没有begin 或 start transaction的情况下,自动提交事务。
对于一个需要频繁使用事务的业务,建议你使用 commit work and chain 语法:
在 autocommit 为 1 的情况下,用 begin 显式启动的事务,如果执行 commit 则提交事务。如果执行 commit work and chain,则是提交事务并自动启动下一个事务,这样也省去了再次执行 begin 语句的开销。同时带来的好处是从程序开发的角度明确地知道每个语句是否处于事务中。
避免长事务:
在开发过程中,尽可能的减小事务范围,少用长事务,如果无法避免,保证逻辑日志空间足够用,并且支持动态日志空间增长。监控Innodb_trx表,发现长事务报警。
04 | 深入浅出索引(上)
索引的常见模型
三种数据结构: 哈希表, 有序数组, 搜索树, 还有调表, LSM树,
哈希表: 等值查询,
有序数组: 等值查询, 范围查询, 只适用于静态存储引擎,
索引不只在内存中, 还要写在磁盘上,
对于新的数据库, 其使用的数据模型决定了其试用场景,
InnoDB, mysql最广泛的存储引擎, B+树,
主键索引又称聚簇索引, 叶子存储整行数据
非主键索引也成二级索引, 叶子存储主键值( 主键要存储两次, 因此主键长度越小越好)
然而, 如果只有一个索引, 且必须是唯一索引, 则将这个索引设计为主键
回表( 扫描两次, 先扫非主键索引树, 再回来扫主键索引树, 拿出数据)
索引维护: 页分裂, 页合并
自增主键: 插入数据时, 不产生页分裂
05 | 深入浅出索引(下)
覆盖索引, 前缀索引, 索引下推,
重建索引, 并重建主键索引, 可以 alter table T engine=InnoDB
根据分组结果, 获取指定字段的集合 group_concat
左连接查询
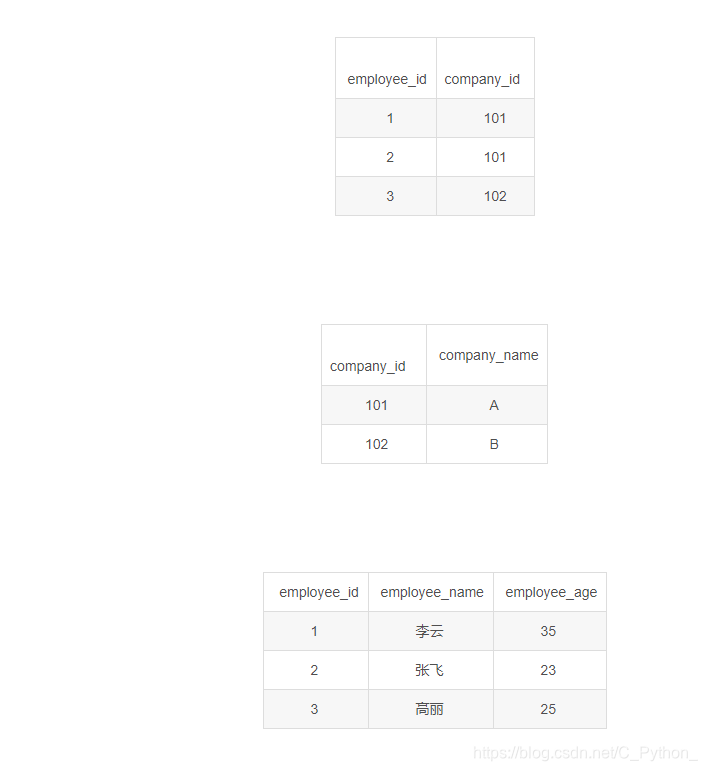
查询A公司, 年龄在30岁的员工姓名

查询所有软件sid 以及相应的最新版本
Table Create Table
------ ---------------------------------------
soft CREATE TABLE `soft` (
`sid` varchar(100) DEFAULT NULL,
`version` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
子查询使用了DISTINCT, 于是主查询的GROUP BY就会保留子查询ORDER BY 的第一条记录, 否则不会
SELECT * FROM (
SELECT DISTINCT(sid),version -- 对软件id去重, 保留相应所有版本号
FROM soft
ORDER BY
-- 然后对版本号,由大到小排序
SUBSTRING_INDEX(version, '.', 1 )*-1,
SUBSTRING_INDEX(SUBSTRING_INDEX(version, '.', 2 ),'.',-1)*-1,
SUBSTRING_INDEX(version, '.', -1 )*-1
) AS a GROUP BY sid -- 最后分组, 获得最大的版本号

















 1951
1951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









