 SAM3:多模态分割新突破
SAM3:多模态分割新突破




点击下方卡片,关注“大模型之心Tech”公众号
本文只做学术分享,如有侵权,联系删文
从SAM1到SAM3,Meta做了什么?
Meta在AI领域的持续创新,特别是在视觉模型方面,已经取得了巨大的突破。从2023年发布的SAM1开始,Meta就开始了对“可提示图像分割”(Promptable Visual Segmentation, PVS)的探索,推出了一个可以通过简单的图像框选、点击或语义提示来完成图像分割的革命性模型。这一开创性工作迅速吸引了业界的关注,标志着计算机视觉技术进入了一个新的时代。更多大模型前沿进展,欢迎加入『大模型之心tech知识星球』
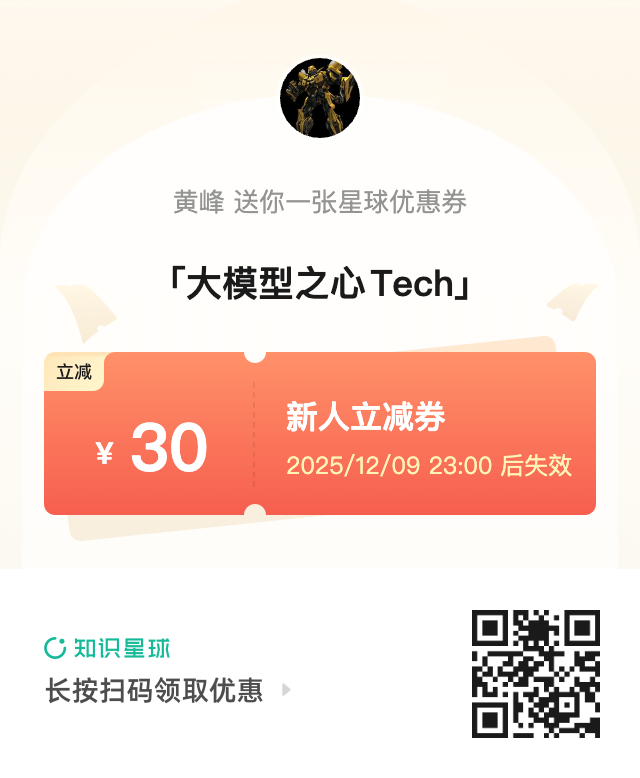
紧接着,SAM2(2024年发布)在架构上进行了重要优化,增强了对视频分割和动态场景的支持,同时提升了模型的稳定性和精度。SAM2强化了模型对多个实例的跟踪能力,使得该模型不仅在静态图像中表现出色,也能够应对视频中复杂的物体动态变化。
然而,SAM3的发布更是让人瞠目结舌。相比于SAM1和SAM2,SAM3不仅在精度上达到了全新高度,还拥有更强大的多模态支持,能够通过语音、文本、图像等多种输入方式进行精准的物体分割。通过全新的Promptable Concept Segmentation(PCS)任务,SAM3在开放词汇概念分割和多物体跟踪方面,达到了前所未有的精准度和灵活性。PCS让SAM3能够应对更复杂的开放词汇概念,不仅仅是简单的物体分割,而是可以识别并分割任何你想要的对象,无论是猫、狗,还是“黄色的出租车”,甚至是“城市中的小巷子”。
SAM1、SAM2,到SAM3,每一次进化都是一次飞跃
技术指标 | SAM1 | SAM2 | SAM3 |
|---|---|---|---|
| 模型尺寸 | 较小,适用于实时推理 | 优化了模型结构,更高效 | 增强了计算能力,支持更复杂任务 |
| 推理速度 | 实时,适用于单物体分割 | 提升了视频分割能力 | 实时视频与图像分割,支持多物体 |
| 支持的提示方式 | 图像框选、点击 | 加强了视频跟踪功能 | 多模态提示:图像、文本、语音 |
| 多物体跟踪 | 单一物体分割 | 支持视频中的多物体跟踪 | 实现更高精度的多物体跟踪与标识 |
| 长上下文处理 | 限制性较强 | 增强了视频帧间关联 | 支持长上下文语义推理,提升视频场景分析能力 |
| 开源贡献 | 基础版本 | 加强了稳定性和效率 | 完全开源,涵盖更多应用场景 |
想让SAM3分割一个图像中的物体?轻轻一点,它就能精准搞定!不止如此,它还会跟踪视频里的物体,就像给视频装上了AI眼睛,视频中的猫咪,它一眼就能分割出,不管它在后面跑还是藏在角落,SAM3都能一一搞定!
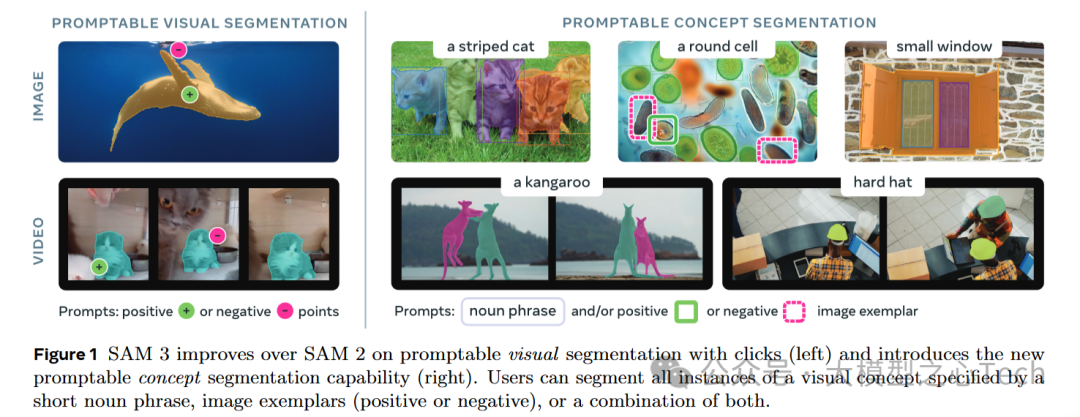
概念分割?SAM3说分就分!输入个名词短语(比如“条纹猫”),SAM3瞬间就能在图片或视频中找到所有符合这个概念的物体,分割得又快又准,完美呈现!就像有个超能助手,想分什么物体就分什么物体,完全不挑食!
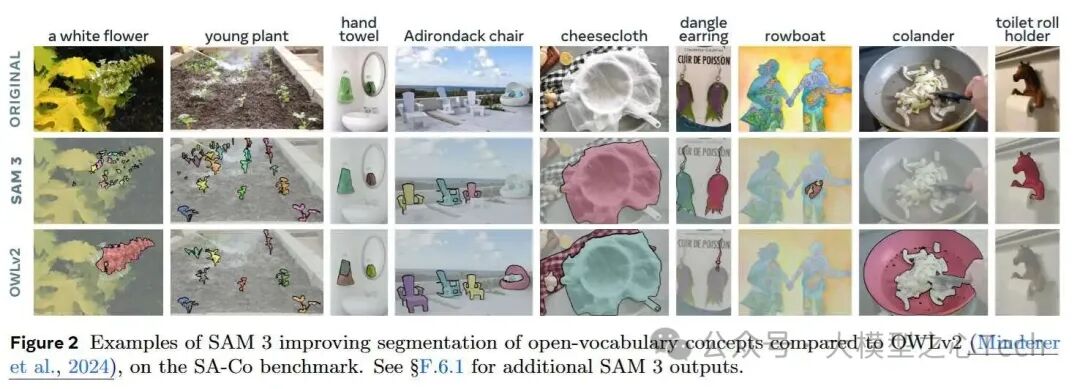
让我们来看个分割大PK,SAM3和OWLv2谁更强?
原始图像:一堆花花草草,椅子、毛巾混在一起。
SAM3:精准到每一片叶子,分割完美!花朵、椅子,各个独立,边界清晰,毫无重叠。
OWLv2:嗯……就像混乱的拼图,植物们挤成一团,分割不清,边界模糊,真的是“分不清哪个是哪个”。
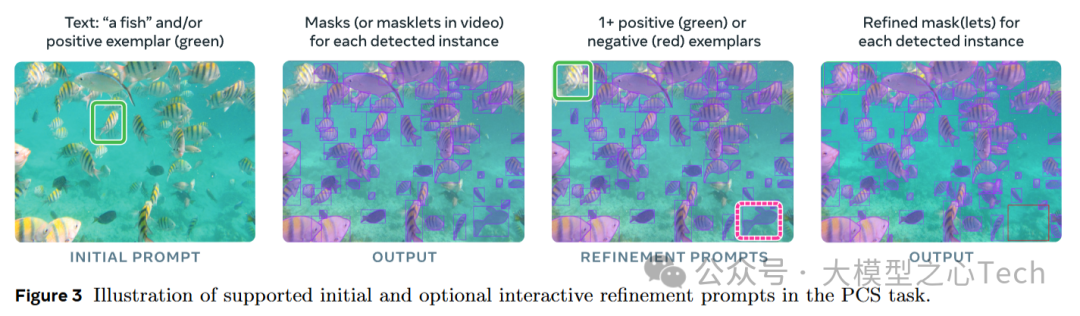
在Promptable Concept Segmentation (PCS) 任务中,通过正面示例(绿色框)和负面示例(红色框),SAM3能够根据用户反馈调整分割结果,使其更加精确。
技术解读
什么是SAM3的核心技术?
我想Promptable Concept Segmentation(PCS)应该是第一个出现在大家脑海中的。 它让SAM3不仅分割物体,还能根据概念进行识别。比如你说“红色车”,它能识别出所有“红色车”实例,不管它们在图像的哪个位置,甚至视频中的哪一帧!
接下来,我将详细解析SAM3的技术实现路线。 先来看一个技术路线框架图。
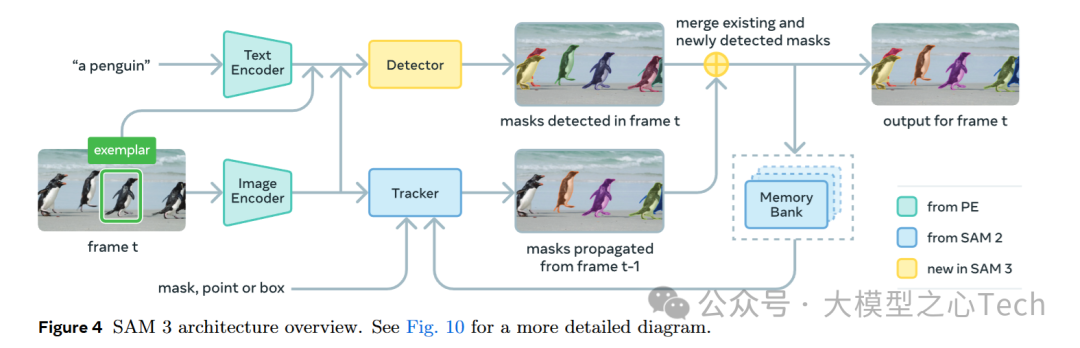
在这个框架图中,SAM3的架构展示了它如何处理图像和视频中的概念分割任务。以下是图中各个组件的解读:
Text Encoder: 这个组件将文本输入(如“a penguin”)转化为模型可以理解的特征向量。SAM3使用这些文本特征来理解用户希望分割的物体概念。
Exemplar: SAM3允许用户提供示例图像(如图中的企鹅)来作为输入,帮助模型理解用户所要分割的物体。这种输入方式有助于模型识别图像中的所有符合描述的实例。
Detector : 检测器负责在图像或视频帧中识别物体,生成初步的分割掩码(mask)。检测器根据输入的文本或示例来寻找符合条件的物体,并给出物体位置。
Tracker : 跟踪器用于在视频中的连续帧之间追踪已检测到的物体。它接收来自先前帧的分割结果,并将这些结果应用于当前帧的物体。这确保了视频中的物体分割结果是一致的,不会丢失物体的身份。
Memory Bank: 记忆库存储了已检测到的物体信息(如它们的特征和位置),并帮助模型在多个帧之间保留对物体的理解。这使得模型能够在视频中长时间追踪物体,并确保物体身份的一致性。
Mask Merging: 在视频中,SAM3会将来自当前帧的分割掩码与前一帧的掩码进行合并,以保持分割的一致性,避免物体在不同帧之间的身份错乱。
值得注意的是,在SAM3中,检测器和记忆库的工作原理从SAM2中继承,并经过进一步的优化和增强,以提升对复杂场景的适应能力。
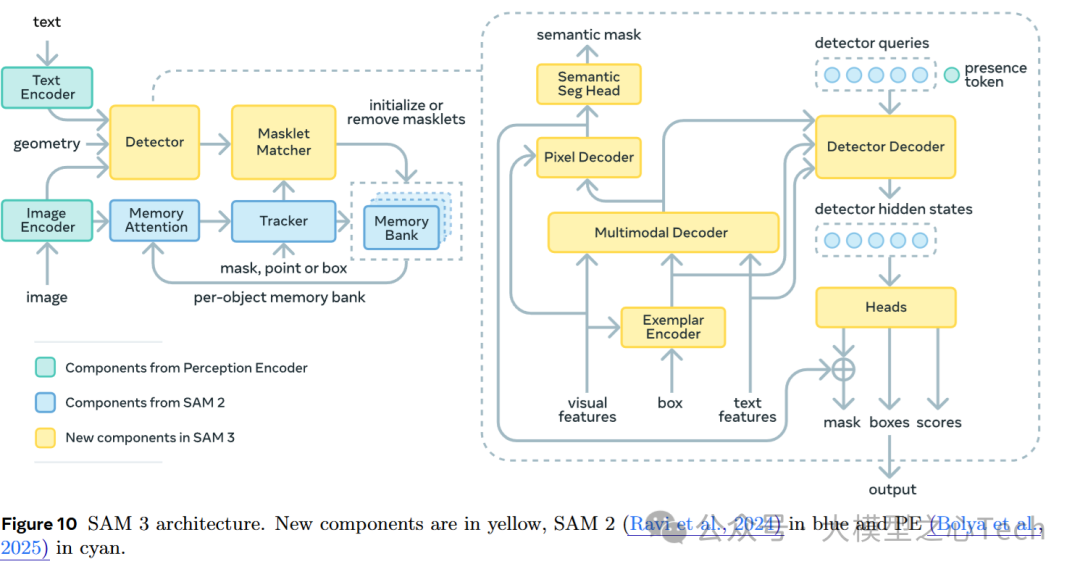
具体来看,Detector模块是SAM3中的核心组件,负责生成物体的分割掩码、边界框和物体评分。它接收来自图像编码器(Image Encoder)和文本编码器(Text Encoder)的输入,通过一系列的操作,最终输出每个物体的位置和类别。它的关键组件包括:
Pixel Decoder:像素解码器接收来自图像编码器的特征,帮助恢复图像中的细节信息,并生成物体的语义掩码
Multimodal Decoder:这个解码器负责将来自文本和图像的特征融合,通过跨模态的解码操作进行处理,最终生成物体的分割结果。多模态解码器可以处理文本、图像和示例输入,使得SAM3在理解复杂提示和场景时更为灵活。
Exemplar Encoder:示例编码器用于处理输入的示例图像(如“这是一只企鹅”),它将示例图像编码为特征,供解码器使用,以帮助模型更好地理解用户的目标物体。
Detector Decoder:检测解码器负责将检测到的查询(例如物体的类别和位置)转化为最终的输出。这个模块通过自注意力(self-attention)机制和交叉注意力(cross-attention)机制,将图像、文本、示例等多模态信息进行融合,并生成物体的边界框、分割掩码等信息。
Heads:接收解码器的输出,并对每个物体的分割掩码、边界框和评分进行最终处理。通过迭代框体细化,SAM3能够细化物体的定位结果,提高检测精度,减少误检。
Presence Token:用于标记物体是否出现在当前帧中。这个模块通过区分全局信息(物体是否在图像中出现)和局部信息(物体的具体位置),解决了在图像中物体缺失或信息不足时的分割问题。
SAM3的惊艳表现
下面是对SAM3在不同任务中的结果分析。
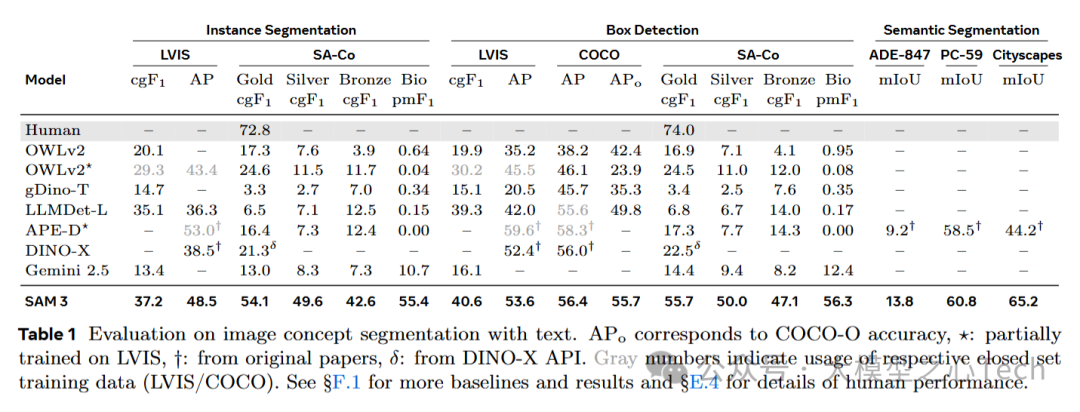
SAM3的结果在各项图像概念分割任务中表现突出,具体表现为:
SAM3在不同数据集上的表现: 无论是在LVIS、COCO还是OdinW13上,SAM3都展现了优越的性能,特别是在零-shot学习和多模态输入(文本和图像结合)上,能够在没有大量标注数据的情况下进行有效的物体分割。
多模态能力强: SAM3在结合文本提示和图像示例时,通过其T+I模式显著提升了分割效果,证明了其在多模态任务中的优势。
跨任务的适应能力: SAM3能够在多种不同任务和数据集上表现出色,特别是在实例分割和概念分割任务中,展示了强大的泛化能力。

除此之外,Meta还将SAM3与MLLMs进行了组合。在这里,MLLM(如Qwen2.5-VL、GPT-4等)用于生成更加复杂的文本查询。传统的SAM模型通过框选或点击物体来进行分割,而SAM3 Agent通过文本生成查询(如“a fish”或更复杂的名词短语)来指导SAM3执行物体分割任务。
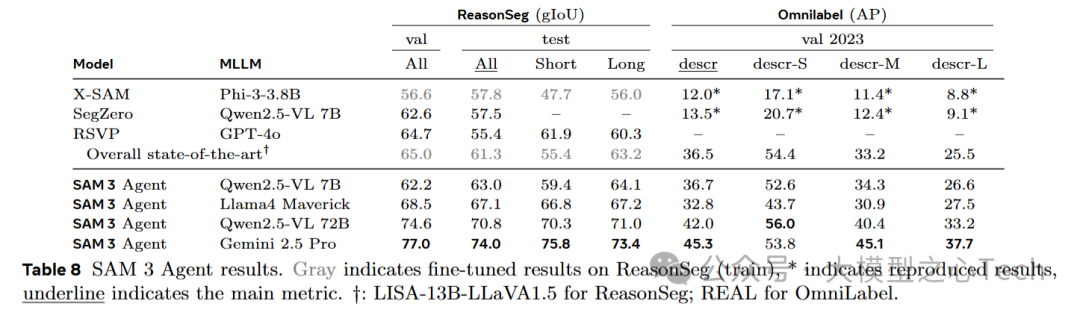
零-shot表现: 结合MLLM后,SAM3 Agent在多个数据集上进行了零-shot测试,证明了其强大的推理能力和灵活性。例如,在ReasonSeg和OmniLabel任务中,SAM3 Agent在没有额外训练数据的情况下超越了以往的模型,表现出色。
RefCOCO和RefCOCOg数据集上的结果: SAM3 Agent在这些基准数据集上表现也很优秀,超越了之前的零-shot模型,说明了这种多模态(文本和视觉)结合的方式对复杂任务的解决能力。
尾声
从SAM1到SAM3,Meta在视觉AI领域的技术进步不仅仅是一次次的架构优化,而是一场无声的进攻,悄无声息地重塑着我们的世界。
SAM1打开了视觉分割的新纪元,然而,这不过是冰山一角。
SAM2在架构上做出巧妙调整,以便更精准地捕捉和分析动态视频场景,那些你我平凡生活中无法察觉的瞬间,却成了自动驾驶、视频监控等领域的生死攸关之物。
SAM3不仅仅局限于静态图像和视频的分割,它能穿越复杂的多模态场景(智能家居、医疗影像、自动驾驶等),以一种难以捉摸的方式,在这些领域中悄然发挥巨大影响。其强大的多模态交互和开放词汇分割能力,使得AI在面对复杂任务时,展现出一种令人不寒而栗的灵活性。
在这个智能化、万象更新的未来,AI是否会成为我们不可逃避的命运,抑或是我们已经步入了一个无人能控的全新秩序?


















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









