




自动驾驶技术在长尾场景(低频率、高风险的安全关键场景) 中表现仍存在显著短板——这类场景虽不常见,却占自动驾驶事故的很大比例,且会导致驾驶员接管率急剧上升。
传统模块化自动驾驶系统(感知-预测-规划分阶段)存在“误差累积”问题:各阶段的微小误差会逐步放大,导致整体性能难以提升;而端到端方法直接将传感器输入映射为控制动作或者自车的轨迹,具备更强的适应性和统一优化能力,被认为是解决长尾场景问题的潜在方向。
而当前端到端方法主要分为两类,但均无法很好应对长尾场景:
小规模任务特定模型:将原始传感器数据转化为BEV地图、交互图等结构化中间表示,通过多任务学习联合优化感知、预测、规划。这类模型在常规场景表现稳定,但上下文推理能力弱、对未见过的场景泛化差,难以处理长尾场景中的复杂交互(如突发遮挡、模糊意图)。
大规模预训练模型(如VLM):依托海量世界知识和强推理能力,衍生出“视觉-语言-动作(VLA)”框架——模仿人类从场景理解到决策的流程,在模糊或罕见场景中展现出更强的可解释性。但VLA面临两大核心挑战:一是长尾QA数据稀缺,多数公开数据集聚焦轨迹标注,缺乏原始视觉数据,且现有VLA专用QA数据集极少覆盖长尾场景;二是稀疏数据下微调效率低,长尾场景发生率低,模型难以从有限数据中有效学习。
论文链接:https://arxiv.org/abs/2509.15968v1
开源链接:https://github.com/FanGShiYuu/CoReVLA
CoReVLA
核心设计:“Collect-and-Refine”双阶段框架
为解决上述问题,CoReVLA提出持续学习的双阶段框架,通过“数据收集(Collect)”与“行为优化(Refine)”循环,提升长尾场景下的决策能力。整体流程如figure 1所示,分为预阶段(SFT)、第一阶段(接管数据收集)、第二阶段(DPO优化)三部分。
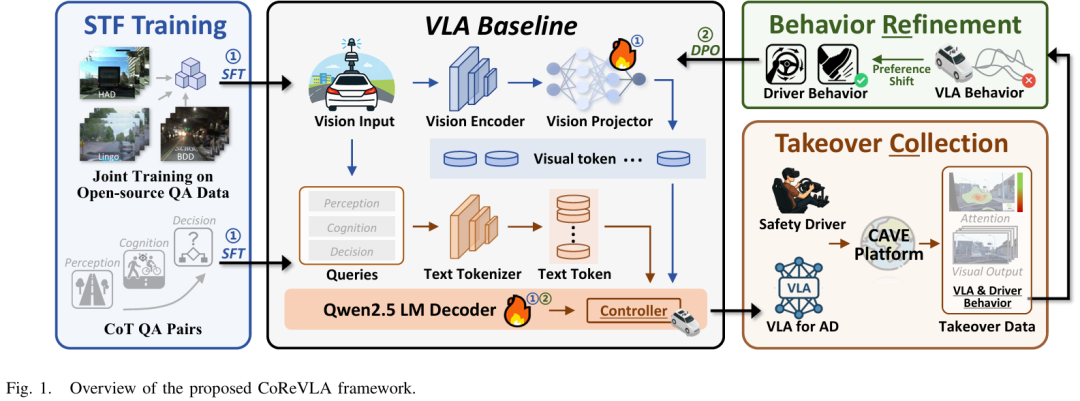
预阶段:基于QA数据的监督微调(SFT)
此阶段的目标是让VLA模型建立自动驾驶领域的基础认知,为后续长尾场景学习铺垫。
QA数据集构建:整合LingoQA、BDD、HAD三个开源数据集,形成70GB领域专用数据。数据格式设计贴合人类推理逻辑:每个样本包含5帧1秒间隔的连续图像(捕捉动态场景),以及思维链(CoT)格式的结构化QA对(分为“场景认知”和“安全驾驶策略学习”两类),既提升模型可解释性,也确保行为合理性。
LoRA微调策略:选择Qwen2.5VL-7B作为基础模型,采用低秩适应(LoRA)对模型关键组件微调——仅更新“视觉投射器”(提升视觉-文本语义对齐能力)和“LLM骨干网络”(增强驾驶相关问题的理解与推理),避免全量微调的高计算成本。
微调目标函数:采用自回归交叉熵损失,优化LoRA引入的可训练参数,公式如下:
其中, 为图像序列,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









