



自动驾驶中有“纯血vla"吗?
Q1:每个数据集的相机数量不一样,这里是怎么处理的?
每个数据集的相机数量不同。VLM模型能够支持不同数量图像的输入,因此在Prompt中可以提供不同数量的图像token输入,模型能够自动处理,无需明确指定相机数量。
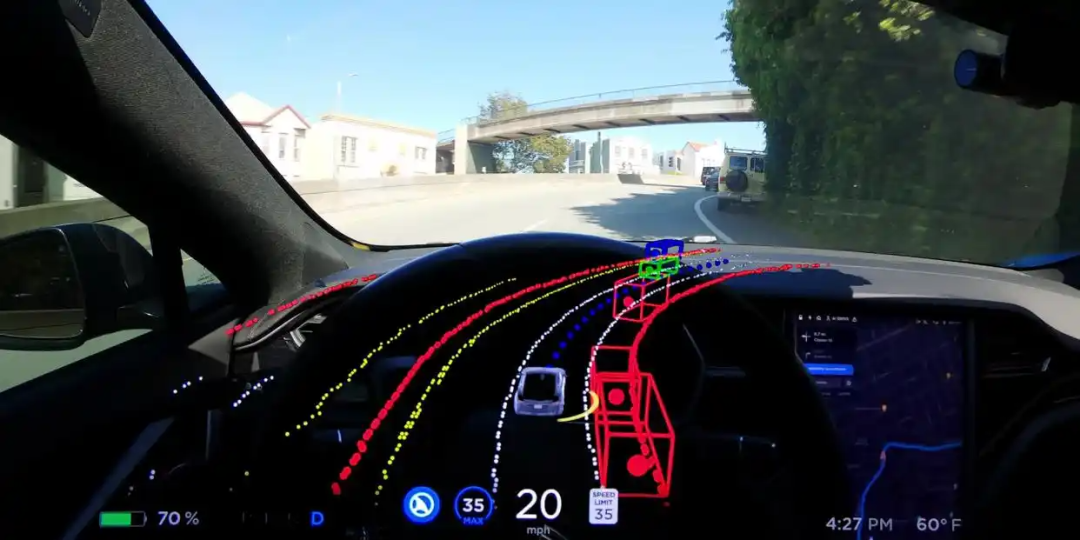
Q2:vla中的action是怎么做的,直接用大模型输出文本形式的轨迹吗?
对于轨迹输出,我们直接通过模型以文本形式输出,并在Prompt中限制输出格式为XY坐标。数据中的QA部分,包括轨迹预测,均基于当前车辆坐标系给出。
本文内容均出自『自动驾驶之心知识星球』,星球内部汇总了诸多关于端到端和VLA的学术界和工业界的问题讨论、技术交流、大佬问答及岗位分享!更多内容欢迎加入知识星球,和4000人一起同行~

Q3:输出轨迹是在图片上的坐标吗?
最后通过视频验证结果,输出的轨迹并非图像坐标,而是相对于当前车辆的坐标。例如,当前车辆坐标为原点(0,0)(0,0)(0,0),预测结果为相对于该原点的(x,y)(x,y)(x,y)值。若需映射到图像,则需更多相机内参数据。不同数据集提供的数据各异:如NuScenes数据集包含相机内参,而Motioniary等数据集则无,因此难以映射至原始图像。我们的最终数据也未提供这部分信息。

Q4:有没有遇到输出的轨迹格式 vla没有遵循给的prompt这个问题?
关于轨迹输出格式问题,GPT-2.5模型整体遵循格式能力较强,但偶现格式不符情况。此时会重新生成结果,并通过Python编程进行轨迹格式规范化处理。在对比测试中发现,未经训练的VRM模型(如GPT)直接输出指定格式结果时表现欠佳,但经过我们的数据训练后效果显著提升。
我们的数据本身包含特定的格式要求,因此模型的输出格式符合预期。对于未经训练的原始模型,我们通过增强对比和格式限制来优化输出,例如要求以JSON格式呈现,并严格规定关键词或预设坐标的键值对形式。这种方式虽然可能与预期格式不完全一致,但能有效提取和处理结果。
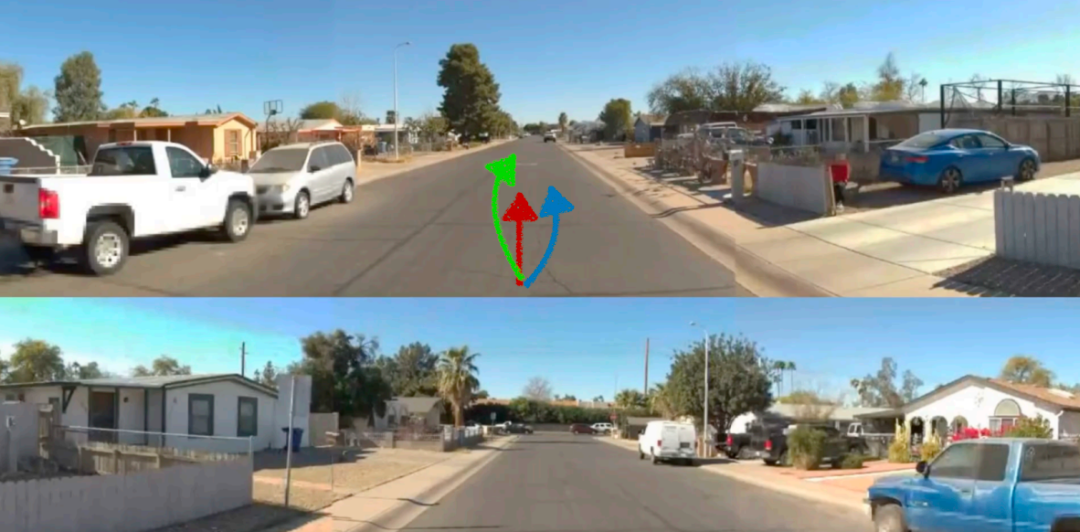
Q5:vla输出的轨迹直接执行和轨迹预测预测的轨迹这两个轨迹有什么区别吗?
VLA轨迹预测与传统方法的区别在于:通过QA训练使模型获得场景理解能力,包括多模态轨距预测、路灯检测、自车运动预测(加速/减速/转向),以及导航指令解释。这种训练还能提升模型对动态物体(如车辆行人)轨迹的预测能力,从而增强整体预测性能。
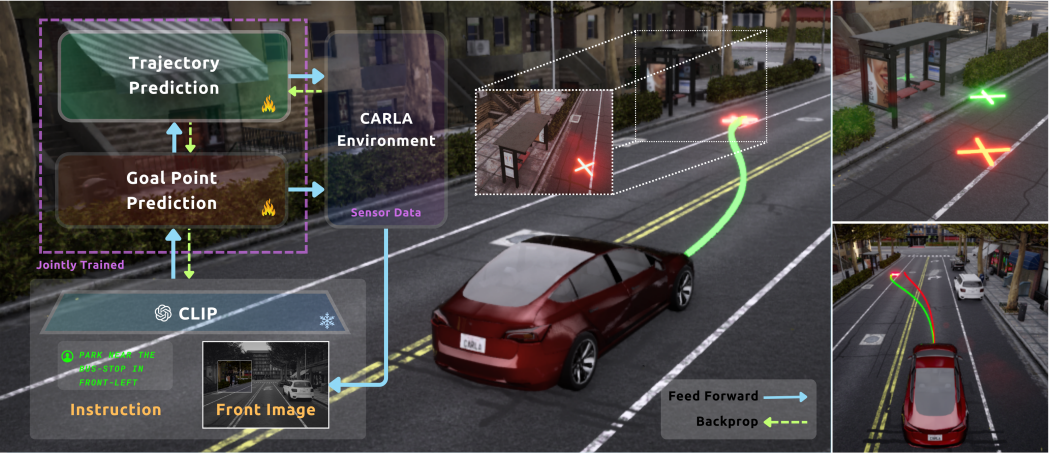
VLA 数据集制作相关问题汇总
有相关数据集制作的同学可以参考~
Q1:Impromptu VLA做数据集时有遇到什么困难吗?这个数据集制作的时候就是用的各个数据集中选取的非结构化场景吗?
在数据集构建过程中,我们遇到了若干挑战。最初考虑的工作数据集存在访问失效的情况,部分数据集因数据质量问题被排除。例如,CSScape数据集中存在坐标异常问题:连续多帧坐标相同后出现突变,这可能是由于采样间隔过长所致。此外,不同数据集的坐标格式存在差异(如经纬度坐标与相对坐标),导致轨迹转换后出现不合理现象,例如前进方向与轨迹数值不匹配的情况。
我们还发现部分数据集的采集方式存在异常,如运动中的摄像头位移。针对这些问题,我们通过规则化方法剔除了不合理轨迹数据。在场景分类标准的制定过程中,我们进行了大量探索,最终确定了分类方案。 Prompt设计方面也遇到挑战,特别是在自车速度路径规划(speed pass plan)和动态物体速度路径规划预测时,由于格式相似导致模型混淆。我们通过添加special token和额外约束条件解决了这个问题。
最终数据集由各数据集的典型场景组成,经过严格筛选。但部分数据集(如Mockery)存在场景连续性不足的问题。Mockery 的场景可能被分割为多个片段。我们发现,某些连续场景(如转弯)被切分为三段,导致中间出现时间空缺。在提取轨迹并计算速度与加速度时,会观察到明显的跳变。最初我们未注意到这一问题,但在后续数据处理过程中进行了修正和剔除。
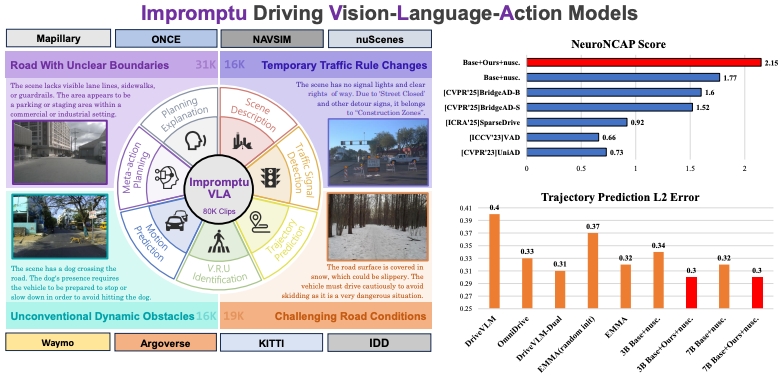
Q2:不同数据集如何对齐呢?不同数据集格式包括给到的数据都不太一样
数据集对齐方面,我们并非直接提供原始数据(如经纬度或相对坐标),而是将其统一转换为自车坐标系下的相对位移。对齐后的数据以 QA 格式组织,涵盖端到端轨迹预测、动态物体预测及速度路径规划(Speed Path Plan)模块。若数据集中缺失部分信息(如检测物体),则对应 QA 也不会生成,因此并非所有数据集均包含完整 QA。

Q3:自己做的数据集的格式是怎么样的?输入是图像和前1.5秒的轨迹点,输出是未来5s的轨迹点吗?结构是怎么样的?
输入数据格式如下:图像作为输入,前 1.5 秒轨迹点用于预测未来 5 秒轨迹点(端到端轨迹预测任务)。数据格式遵循 SANA 标准,前 6 类 QA 与 SANA 一致,第 7 类为新增的端到端预测任务,以确保数据完整性。具体结构可参考 SANA 或访问我们的 GitHub/HuggingFace 页面查看数据格式说明。

三年期间星球内部一直聚焦在自动驾驶最前沿的技术方向,多模态大模型、VLM、VLA、闭环仿真、世界模型、扩散模型、端到端自动驾驶、规划控制、多传感器融合等近40个技术方向的内容。涵盖了目前所有主流的方法论,并形成了技术路线,适合入门进阶的同学做进一步提升。
社区成员主要分布在头部的自驾/具身/互联网公司、Top高校实验室、还有一些传统的机器人公司。形成工业界+学术界互补的态势。如果您真的有需要,想要做系统提升、和更多的同行业人员交流,欢迎加入。开学季大额优惠,微信扫码加入~~

『自动驾驶之心知识星球』目前集视频 + 图文 + 学习路线 + 问答 + 求职交流为一体,是一个综合类的自驾社区,已经超过4000人了。我们期望未来2年内做到近万人的规模。给大家打造一个交流+技术分享的聚集地,是许多初学者和进阶的同学经常逛的地方。
更有料的是:星球内部为大家梳理了近40+技术路线,无论你是咨询行业应用、还是要找最新的VLA benchmark、综述和学习入门路线,都能极大缩短检索时间。星球还为大家邀请了数十位自动驾驶领域嘉宾,都是活跃在一线产业界和工业界的大佬(经常出现的顶会和各类访谈中哦)。欢迎随时提问,他们将会为大家答疑解惑。除了上面的问题,我们还为大家梳理了很多其它的内容:
端到端自动驾驶如何入门?一段式/二段式量产中如何使用?
传统规划控制想转端到端VLA,求学习路线图!
自动驾驶多模态大模型预训练数据集有哪些?求自动驾驶VLA微调数据集?
多传感器融合现在还适合就业吗?
3DGS和闭环仿真如何结合?应用中需要考虑哪些元素?
世界模型是个啥?业内如何应用,研究还有切入点么?
业内哪家公司前景好一些,适合跳槽,都有什么岗位开放招聘?求星主内推~
博士入学,哪个方向容易出成果?
闭环强化学习如何入门?
端到端自动驾驶学习路线推荐。
......
我们会不定期和一线的学术界&工业界大佬畅聊自动驾驶发展趋势,探讨技术走向和量产痛点:
这是一个认真做内容的社区,一个培养未来领袖的地方。星球内部梳理了近40+自动驾驶技术方向,同时也有面向求职的问答梳理。

针对入门学习的同学,我们更是准备了全栈方向的学习课程,非常适合0基础的小白。

我们还和多家自动驾驶公司建立了岗位内推机制,欢迎大家随时艾特我们。第一时间将您的简历送到心仪公司的手上。
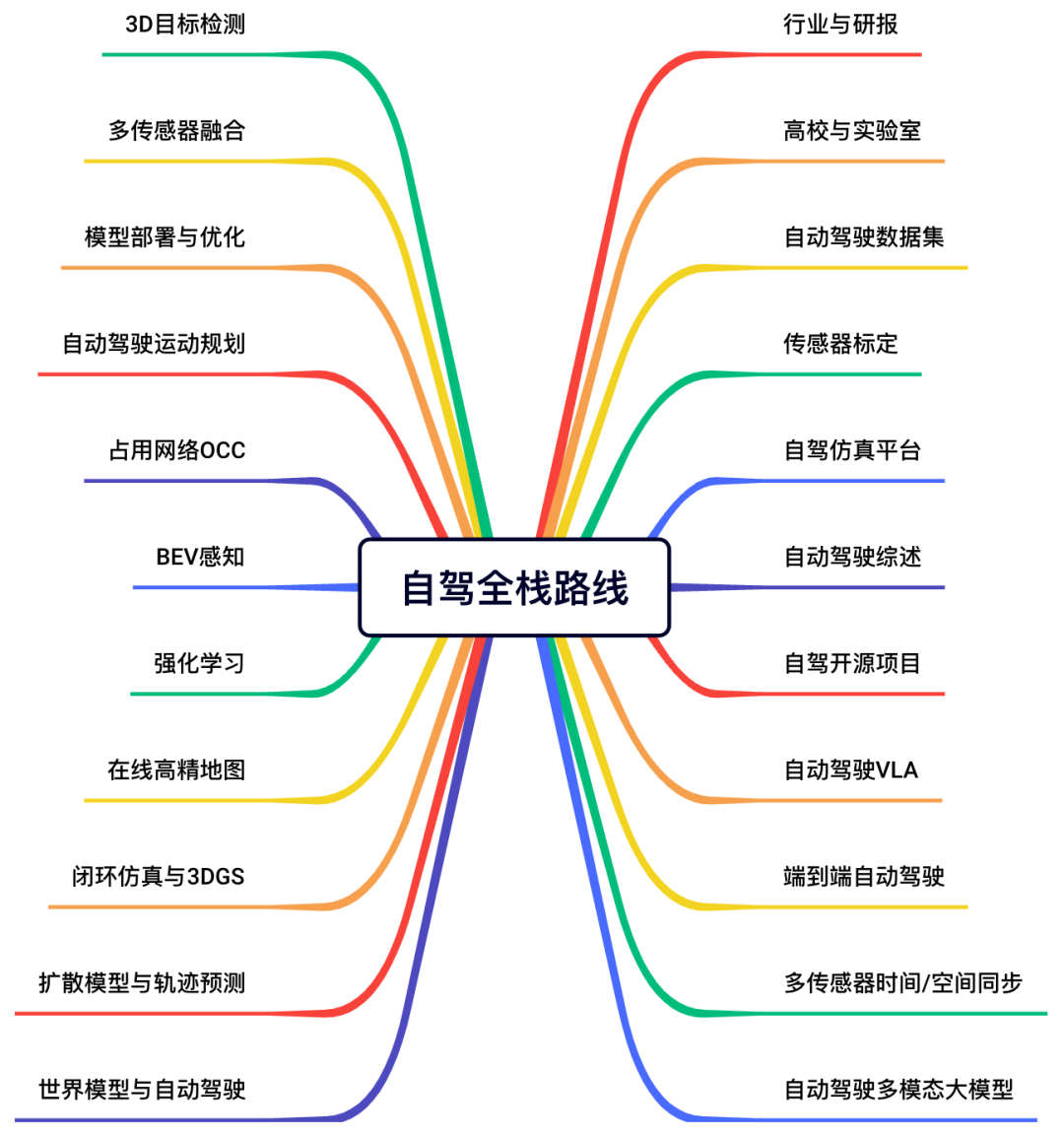
针对入门者,我们整理了完备的小白入门技术栈和全栈路线图。
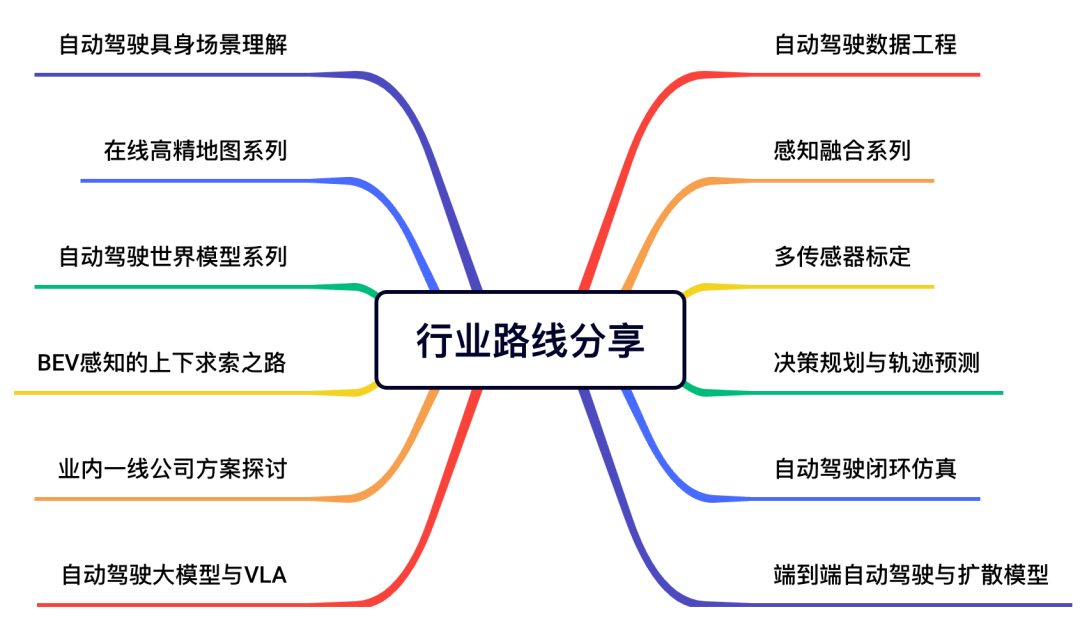
已经从事相关研究的同学,我们也给大家提供了很多有价值的产业体系和项目方案。
欢迎和我们一起打造完整的自驾生态。


















 3979
3979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









