



作者 | 厘米 来源 | 自动驾驶下半场
点击下方卡片,关注“自动驾驶之心”公众号

>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
2025年夏天,上一年端到端的热度还没有散去。
即使端到端的概念在各家各显神通的公关稿下已经面目全非;即使面对突然发布的 FSD 的正面竞争,我们还没有获得明显的优势;似乎一夜之间,VLA 的宣传攻势像素级复制去年的端到端。

毕竟,技术切换期是最好的占领用户心智的机会,也是证明团队研发优势的最佳时机。
拿到端到端最大红利的理想汽车,试图用 VLA 来巩固自己的领先优势;用端到端的 Tech Vision 获得珍贵量产订单的元戎启行,希望通过 VLA 提升辅助驾驶的上限;小鹏汽车同样,作为一家以 AI 为核心的公司,早已在具身智能和 VLA 上深耕多年,把它应用到辅助驾驶中可谓得心应手。
不过,这次似乎和端到端浪潮不太一样。相较于之前行业普遍达成研发共识的局面,这一次不少团队选择了刻意回避。
被公众认为长期处于第一梯队的华为 ADS 明确表示,WA(World Model + Action)才是实现自动驾驶的终极方案;蔚来在低速场景用世界模型展示了一些类似 VLA 的体验,但在对外宣传时却讳莫如深;最近开始用户体验的地平线,虽然表现惊艳,却只强调自己在认真做端到端,对于 VLA 则显得唯恐避之不及。
如果说 2023-2024 年端到端的浪潮是“共识之下的竞速”,那么 2025 年的 VLA 则更像是“分歧之中的探索”。
为何?VLA 不够先进吗?还是说观望的团队另有理由?在探究原因之前,我们先看什么是VLA。
什么是 VLA?
VLA,全称 Vision-Language-Action Model,最早在学术界兴起,用于探索如何通过视觉和语言来指导机器人或自动驾驶系统的决策。它的基本思想是:
通过 视觉模块感知环境;
通过 语言模块将任务或目标以自然语言的形式表述;
最终由 动作模块将理解转化为可执行的驾驶行为。
换句话说,VLA 试图将“人类的驾驶本能”映射为“可解释的语言指令”,再转化为“机器的操作”。在理想状态下,它既能具备端到端的强大感知-决策一体化优势,又能通过语言让系统更具可解释性和可控性。

Wayve 的 LINGO 系列 是 VLA 的代表性探索之一。2023 年,Wayve 发布了 LINGO-1,这是第一个将自然语言与端到端驾驶相结合的模型,能够边驾驶边用自然语言解释自己的决策。2024 年,Wayve 又发布了 LINGO-2,在 VLA 上进一步提升,强调通过语言交互让人类可以更直观地理解和引导自动驾驶系统。具体能力包括:
实时语言提示调整行为(如“靠边停”,“左转”等);
可向模型提问,如“红绿灯是什么颜色?”并获得实时回答;
提供连贯的驾驶注释,以解释驾驶行为
在第一版Lingo发布时,Wayve表示,他们让测试驾驶员,一边执行动作,一边说出自己执行的原因,用这种方式完成语言数据,驾驶动作,感知数据的三方对齐。
而在后续的实践中,随着多模态模型的不断发展,也有了许多直接使用大模型进行语言因果推理进行数据收集的工作,例如CoVLA,就是一种降低数据收集成本的方式。
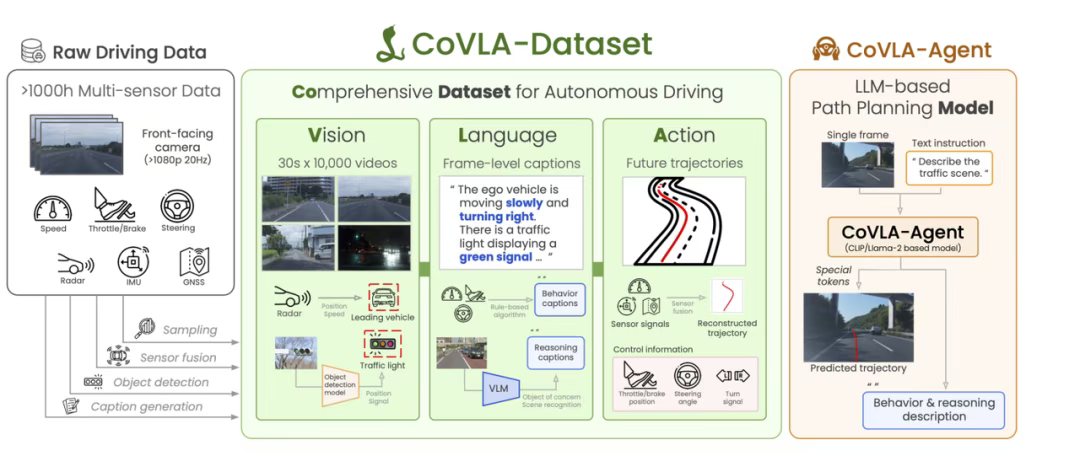
而OpenDriveVLA将 2D/3D 视觉 token 与语言 进行融合,并通过模型生成控制轨迹,在Nuscenes上取得了最优结果。
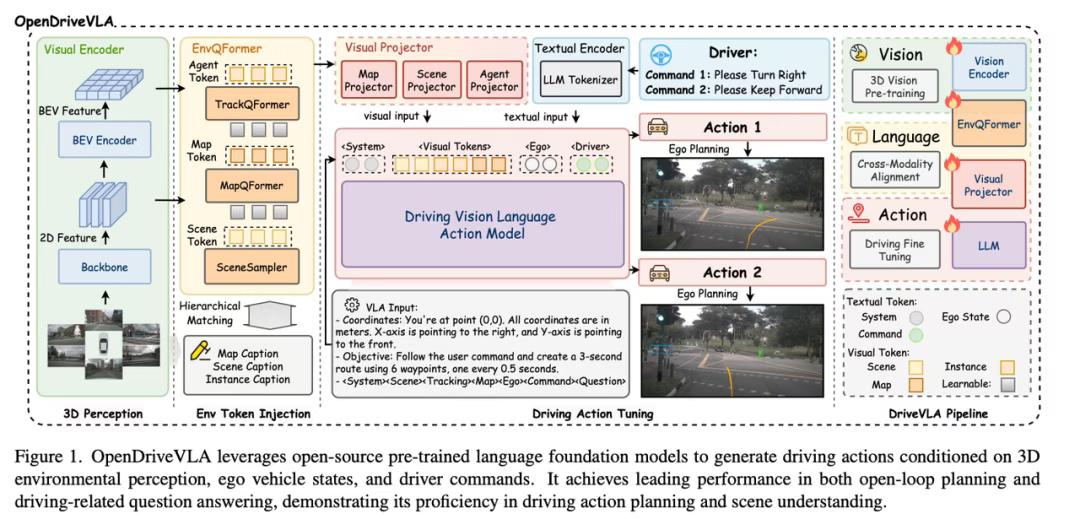
这些研究为 VLA 在辅助驾驶领域的应用提供了理论和工程基础。
同样的,不仅在辅助驾驶领域,在具身智能领域VLA的应用更加火热,毕竟,这也是具身智能区别于传统机器人公司最重要的特质。
例如Google Deepmind 发布的RT1就将视觉(图像帧)+ 语言任务描述 共同输入给模型,输出低层机器人控制动作,例如末端执行器的位姿等,后续RT2也将网络数据引入,突破了单纯依赖机器人数据的瓶颈,通过 互联网视觉-语言知识 → 机器人控制迁移,提升泛化与推理能力。
一切看上去非常自然,通过网络数据提升认知能力,再迁移到具身智能或者辅助驾驶任务上,自然能够有更好的泛化能力。
优点如此明显,似乎不跟随就会掉队,但是还是不少团队保持着怀疑的态度。
端到端与 VLA 的分歧
VLA 接受了语言给的泛化馈赠,但是所有的礼物都标好了价格。
首先,自然语言在驾驶任务中的表达往往存在模糊性与不完备性:例如“慢一点”或“小心前方”之类的描述缺乏精确的动作约束,而许多驾驶行为(如油门微调、瞬时避让)本身也难以通过自然语言完全描述,回想我们开车的行为,是否所有的行为都能通过语言描述清楚呢?
这种语言-动作不对称性已在多模态学习研究中被广泛讨论。例如OpenVLA就明确表示强调语言主要在任务级别有效,而非细粒度控制。这种“语言-动作不对称”问题导致 VLA 在监督学习中不可避免地存在噪声。

驾驶场景对实时性有极高要求,而多模态 Transformer 同时处理视觉、语言与动作的推理开销远高于传统感知-决策-控制链路。例如典型开源 VLA 模型OpenVLA约7B参数,推理阶段需要约 15 GB GPU 显存,单卡运行约 6 Hz。而目前辅助驾驶行业,一般系统运行速度至少要在10HZ左右。
这意味着 VLA 在实际部署中可能遭遇推理延迟的问题,尤其在需要毫秒级反应的紧急场景下更为突出。需要非常强大的实时算力储备,例如小鹏选择用自研的更高算力芯片来解决这个问题。
不仅如此,语言和空间的对齐关系并不能总是稳定,例如常见的靠边停车指令,有无公交车道,有无自行车道,都存在动作上的歧义。
在这些限制下,实际上,目前行业内辅助驾驶的VLA一般用于上层任务的分配,指令的发放,而轨迹的输出和执行依然由原有模型来完成,也需要一些兜底的方式来防止不合理的输出。
或许也是因为此,部分团队对VLA抱着怀疑的态度,依然选择深入攻克现有的感知输入,动作输出的VA(VisionAction)方案。在足够谨慎训练范式下,即使没有语言模块,VA 模型内部仍会形成对环境状态的向量化表示,可以看作是“内隐世界模型”。例如地平线,华为。
地平线的坚持与结果
在这场分歧中,地平线的态度颇具代表性。这个月,地平线开启了HSD的大规模试驾,媒体们交口称赞,但是问及是否是VLA时,负责人直接否认,这不是VLA。
即使在能够准确识别前方直行可以进入待行区,即使能够对周围的车辆进行危险标识,即使在防御性驾驶上表现非常好,我们依然只得到了一句话,这不是VLA。
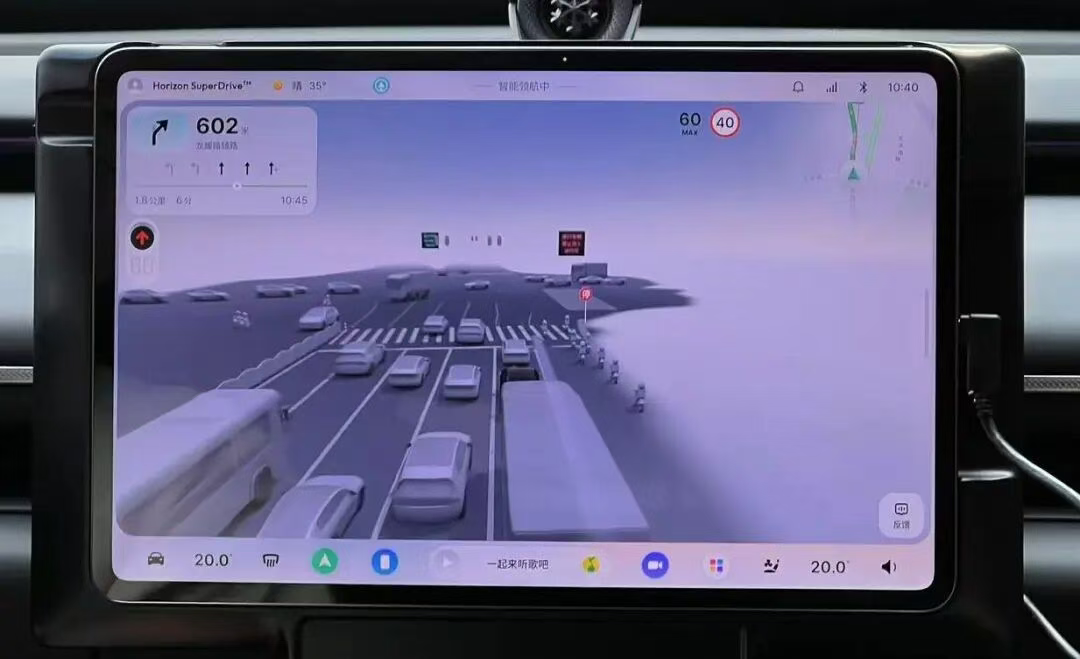
但是我依然感受到了与其他端到端模型的区别,整个系统在试驾的过程中表现非常统一,没有快速和低速时的割裂感,没有低速的过于谨慎,也没有快速的莽撞感。
这其实说明了HSD深度神经网络作为核心决策引擎,充分发挥神经网络的泛化能力。使用了平衡的数据分布。在不同场景和城市环境下,模型实现自适应行为,并在不同道路条件下保持一致的用户体验。
而很明显能感觉到“老司机”驾驶数据得到了充分利用,并对数据进行筛选与优化,确保训练数据最贴合人类日常驾驶习惯。由此训练的模型在决策和动作上更符合人的直觉,从而增强了用户信任。
在端到端的研发过程中,一定会遇到很多黑盒网络带来的不合理的轨迹和决策,也一定会有团队成员提出我们要不要使用一个外挂的模块,用这个模块去解决这些问题,这样能最快得到结果。
例如施工区域,我们挂一个施工区域规则;不常见的红绿灯,我们再挂一个红绿灯规则;前方我们要右转,但是视野不是很好,我们再挂一个不良视野规则;这些都是非常直觉的做法,也很容易获得更好的结果。
但是做到最后,我们会发现,这还是我们最初设计的端到端吗?
但是似乎地平线不是这么做的,用更难的方式来解决,尽量避免引入非必要的兜底模块,不追求短平快的结果。这保证了系统在 demo 阶段到量产开发过程中的模块最小化,同时维持了整体架构的简洁性和可维护性。乃至于我们试驾的车型上,甚至激光雷达输入也直接被屏蔽了,也要防止感知团队过多依赖激光雷达。
这些都能反映出来,地平线的研发逻辑:如果方向是明确的,就按这个方向去进行,旁枝末节尽量少。这也是一种Stay Focused,在竞争如此激烈,迭代极其迅速的辅助驾驶领域,非常难得。
在研发中的坚持不会白费,众人称HSD为“中国版FSD” 。
真正的一段式架构降低了时延,横纵向协同控车让方向盘非常稳定,目标位置也很明确。对激光雷达的谨慎使用意味着这一套系统也可以提供纯视觉的版本,加上地平线软硬件一体的方案,也会具备更好的成本优势。
写在最后
从 2023 年马斯克带着 FSD 闯红灯开始,端到端进入了我们的视野。不到三年时间,它从广泛怀疑,到众人追捧,再到成为行业基础名词。
但是端到端的概念并未过时,VLA 某种程度上也是一种端到端系统。我想称现在为“后端到端时代”。
不难发现,即使到了今天,在辅助驾驶领域,我们一直遇到的是缺乏足够对世界理解能力的问题。
语言或许能成为辅助驾驶系统的“另一只眼睛”,但是否是必需品,仍未有定论。语言是一种新的输入维度,某种程度上类似激光雷达,高度抽象也具有很好的能力,它能对我们提供帮助,但是辅助驾驶依然没有银弹。
有团队用更大的算力,引入新的语言维度,用VLA来解决问题;而地平线选择用自研的J6P上,用成本相对可控的方式,来解决遇到的问题。
在众人追捧端到端时,我写如果你相信靠端到端就能实现L4,那么你该改行了。在后端到端时代,真正的关键问题可能是:行业究竟需要新的道路,还是需要把脚下的路走得更稳?
我相信每个团队都会有自己的答案,每种答案都会有自己的机会。
参考文献
Wayve. LINGO-1: Open-loop driving with natural language explanations. 2023. https://wayve.ai/thinking/lingo-natural-language-autonomous-driving/
Wayve. LINGO-2: Closed-loop Vision-Language-Action driving. 2024. https://wayve.ai/thinking/lingo-2-driving-with-language/
Arai, H., Miwa, K., Sasaki, K., Yamaguchi, Y., Watanabe, K., Aoki, S., & Yamamoto, I. CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving. WACV 2025. https://arxiv.org/abs/2408.10845
Zhou, X. OpenDriveVLA: Towards End-to-end Autonomous Driving with Vision-Language-Action Models. 2025. https://arxiv.org/abs/2503.23463
Kim, M. J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., & Finn, C. OpenVLA: An Open-Source Vision-Language-Action Model. 2024. https://arxiv.org/abs/2406.09246
Brohan, A., et al. RT-2: Vision-Language-Action Models. 2023. https://arxiv.org/abs/2307.15818
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









