



点击下方卡片,关注“自动驾驶之心”公众号
基于可控扩散模型的生成式主动学习:长尾轨迹预测新方法
韩国DGIST、美国高通研究院与韩国KAIST ICCV25中稿的工作,本文提出 生成式主动学习框架GALTraj,首次将可控扩散模型应用于轨迹预测的长尾问题,通过尾样本感知生成技术动态增强稀有场景数据,在WOMD和Argoverse2数据集上使长尾指标FPR₅相对降低47.6%(从0.42→0.22),整体预测误差minFDE₆降低14.7%(从0.654→0.558)。
论文标题:Generative Active Learning for Long-tail Trajectory Prediction via Controllable Diffusion Model
论文链接:https://arxiv.org/abs/2507.22615
主要贡献:
首次将生成式主动学习应用于轨迹预测任务,提出 GALTraj 框架,通过可控扩散模型驱动的交通模拟增强长尾学习效果,无需修改模型结构。
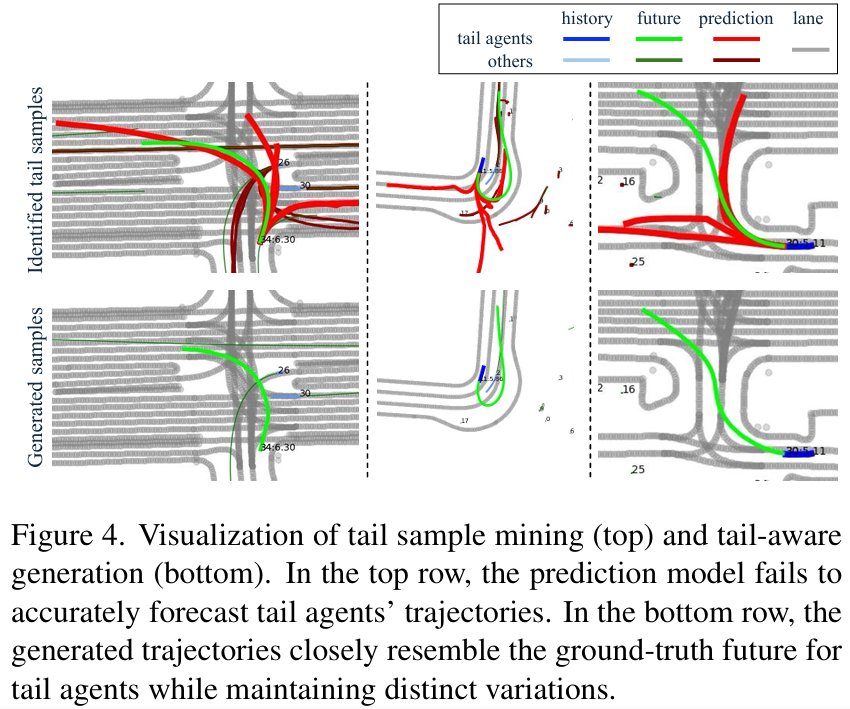
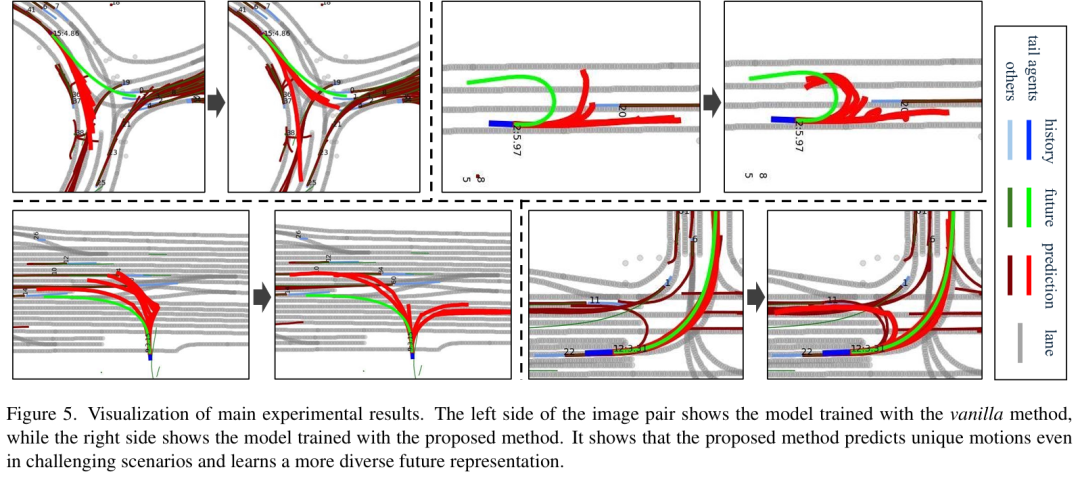
设计尾部感知生成方法,对交通场景中的尾部代理、头部代理和相关代理分配差异化扩散引导,生成兼具真实性、多样性且保留尾部特征的场景。
在多个数据集(WOMD、Argoverse2)和骨干模型(QCNet、MTR)上验证,显著提升尾部样本预测性能,同时改善整体预测精度。
算法框架:
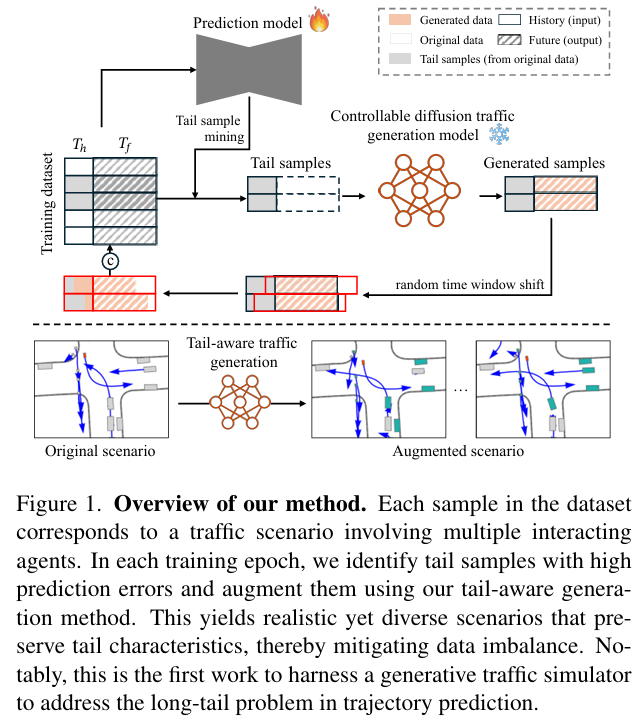
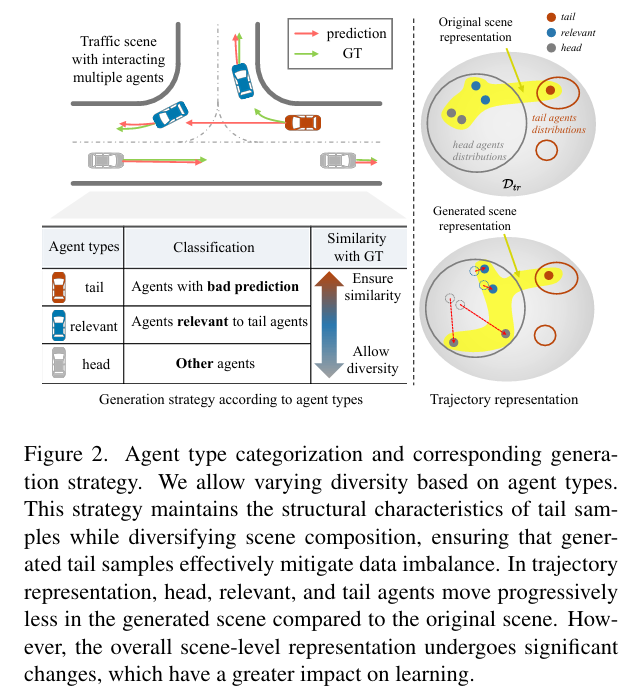
实验结果:
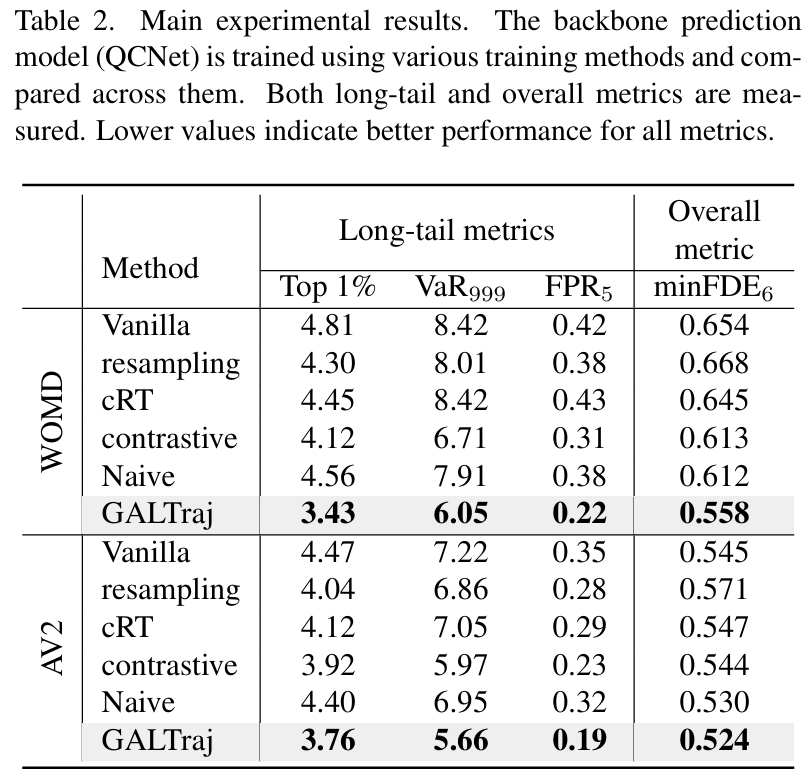
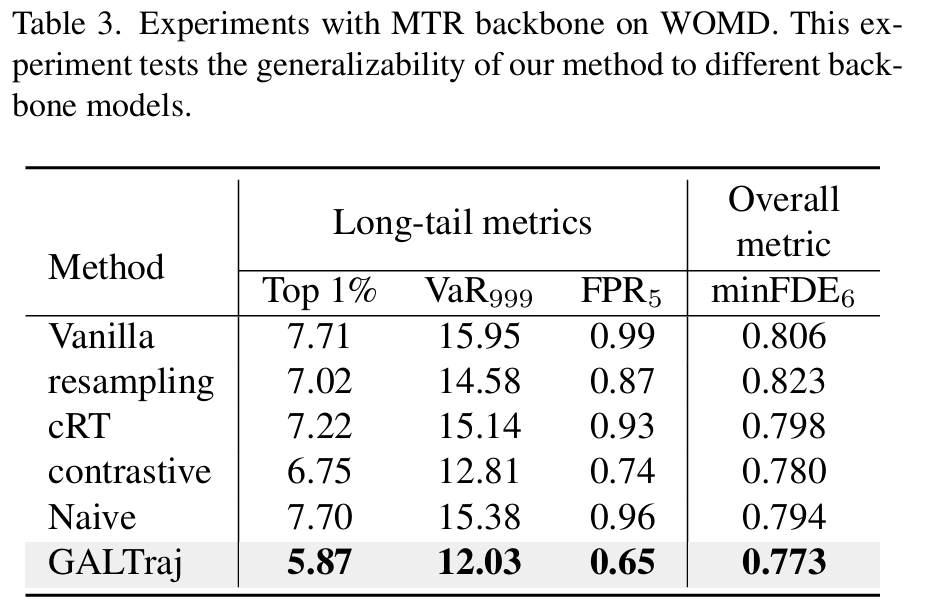
可视化:
本文均出自自动驾驶之心知识星球,欢迎加入我们!

上海交大提出TopoLiDM:基于拓扑感知扩散模型实现可解释、高保真激光雷达点云生成
上交大与特文特大学联合提出 TopoLiDM 框架,通过拓扑正则化的图扩散模型实现高保真激光雷达生成,在 KITTI-360 数据集上以 22.6% 的 FRID 下降率和 9.2% 的 MMD 下降率超越现有最优方法,同时保持 1.68 样本/秒的实时生成速度。
论文标题:TopoLiDM: Topology-Aware LiDAR Diffusion Models for Interpretable and Realistic LiDAR Point Cloud Generation
论文链接:https://arxiv.org/abs/2507.22454
代码:https://github.com/IRMVLab/TopoLiDM 自驾,IROS 2025
主要贡献:
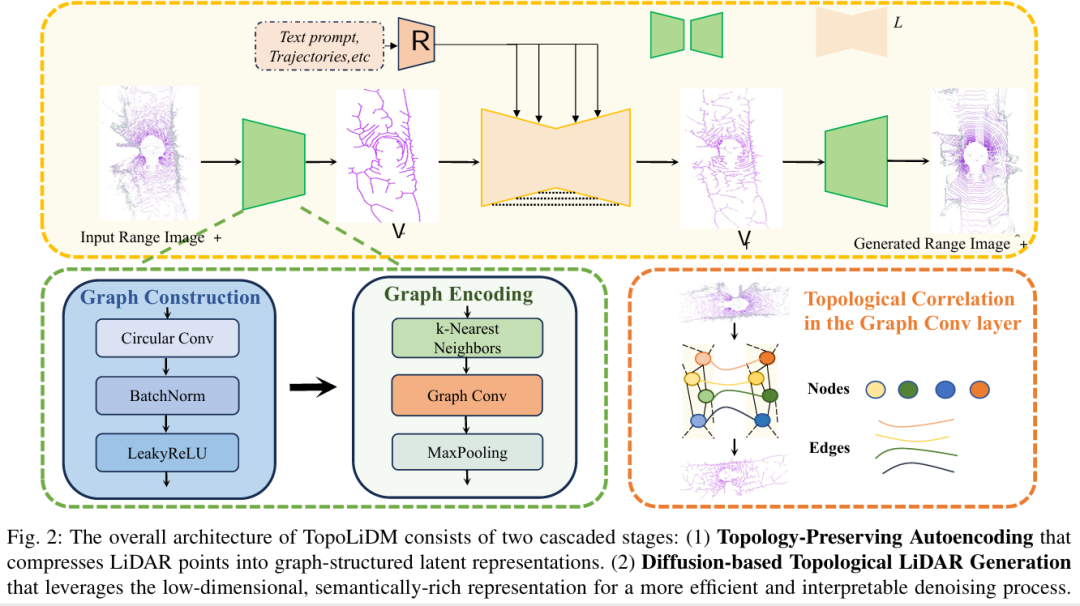
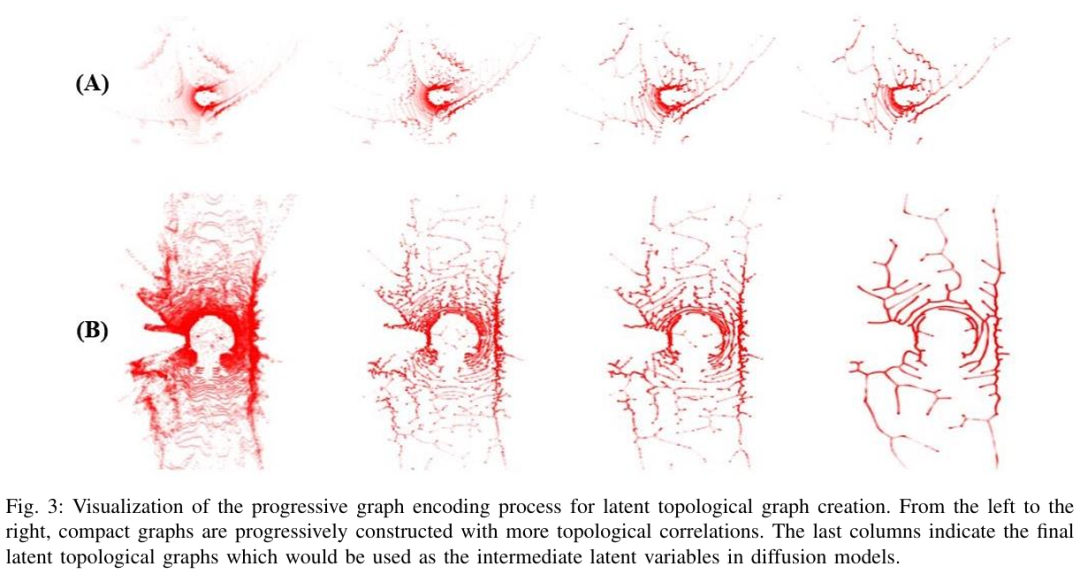
拓扑感知的LiDAR扩散模型框架:提出了TopoLiDM,一种创新性框架,将图神经网络(GNNs)与扩散模型在拓扑正则化下集成。该方法采用紧凑的拓扑图作为潜在表示,实现了快速、可解释且高保真的LiDAR点云生成。
拓扑感知VAE模块设计:设计了拓扑感知的变分自编码器(Topology-aware VAE),通过图构建和多层图卷积提取潜在图表示,并引入0维持久同调(Persistent Homology, PH)约束。该模块能够捕获长距离依赖关系,确保生成的LiDAR场景符合真实世界环境的全局拓扑规则。
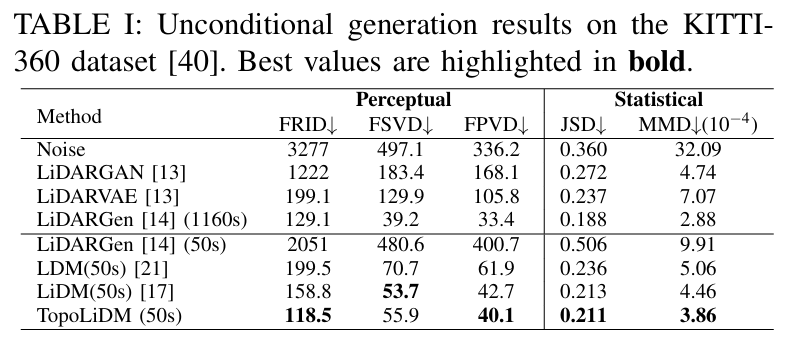
卓越的性能表现:在KITTI-360数据集上的广泛实验表明,TopoLiDM在关键指标上显著超越现有最先进方法。具体而言,在Fréchet Range Image Distance (FRID)指标上降低了22.6%,在Minimum Matching Distance (MMD)指标上降低了9.2%。同时保持快速推理速度(平均1.68样本/秒),展示了实际应用潜力。
算法框架:
实验结果:
可视化:
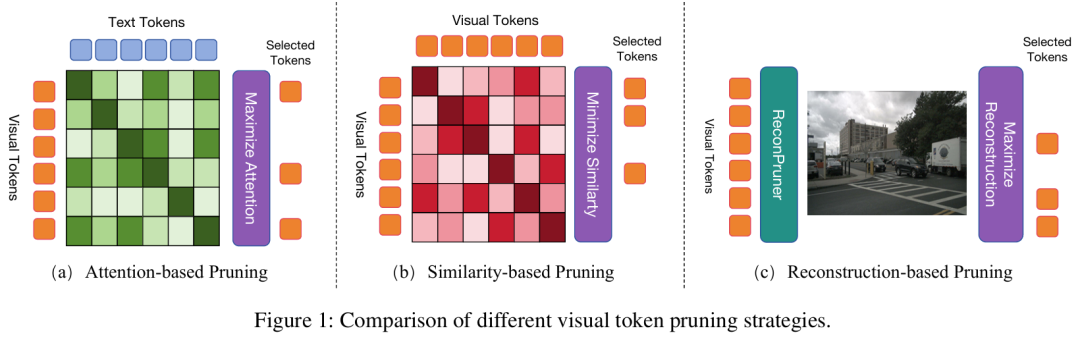
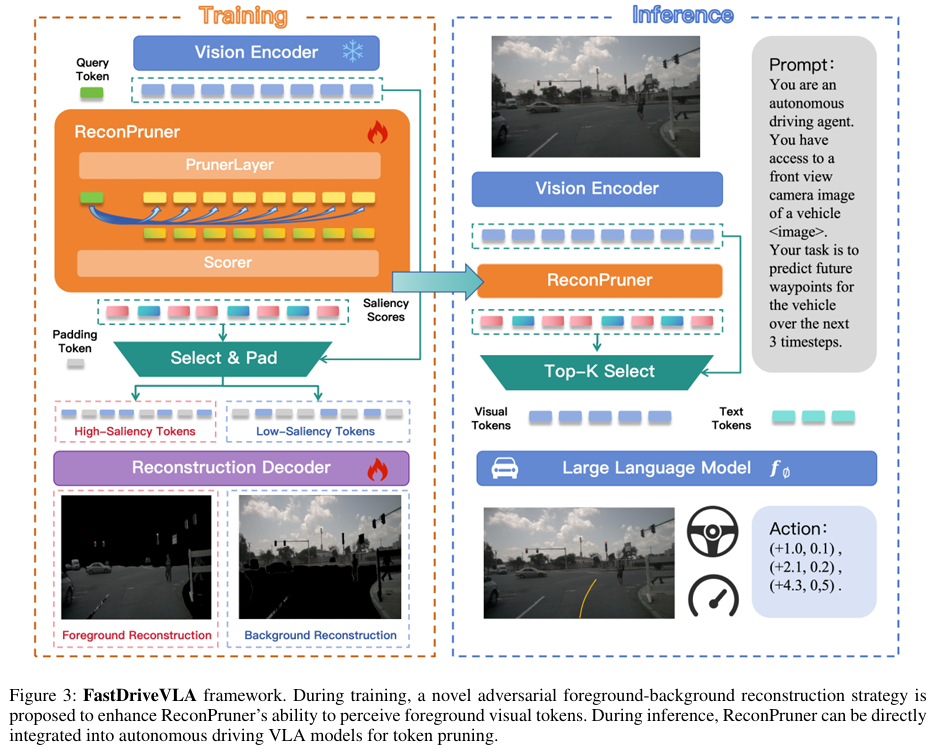
FastDriveVLA:基于重建式令牌剪枝的高效端到端自动驾驶
北大 & 小鹏 提出基于重建的视觉Token剪枝框架FastDriveVLA,通过对抗性前景-背景重建策略,在50%剪枝率下保持99.1%轨迹精度并降低碰撞率2.7%。
论文标题:FastDriveVLA: Efficient End-to-End Driving via Plug-and-Play Reconstruction-based Token Pruning
论文链接:https://arxiv.org/abs/2507.23318
主要贡献:
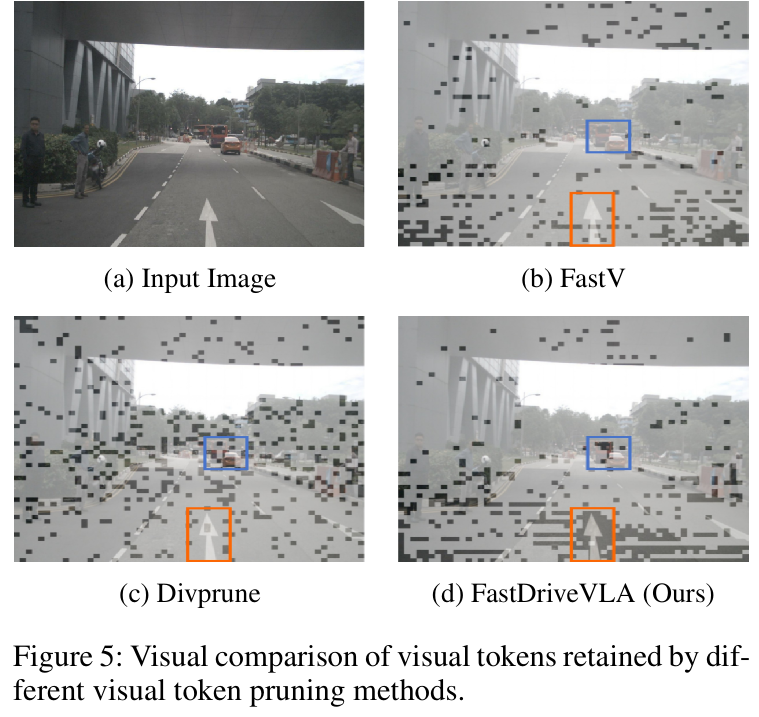
提出了 FastDriveVLA,一种基于重建的新型视觉令牌修剪框架,区别于现有的基于注意力和基于相似度的修剪方法。
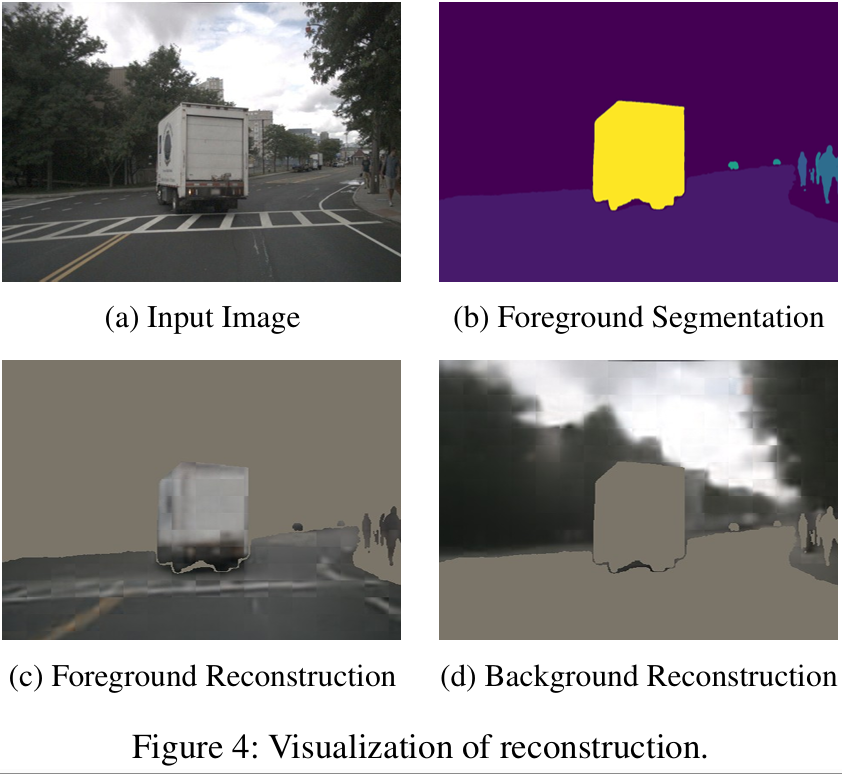
设计了 ReconPruner,一种通过 MAE 风格像素重建训练的即插即用修剪器,并引入新型对抗性前景 - 背景重建策略以增强其识别有价值令牌的能力。
构建了 nuScenes-FG 数据集,该数据集包含针对自动驾驶场景的前景分割标注,共 241k 图像 - 掩码对。
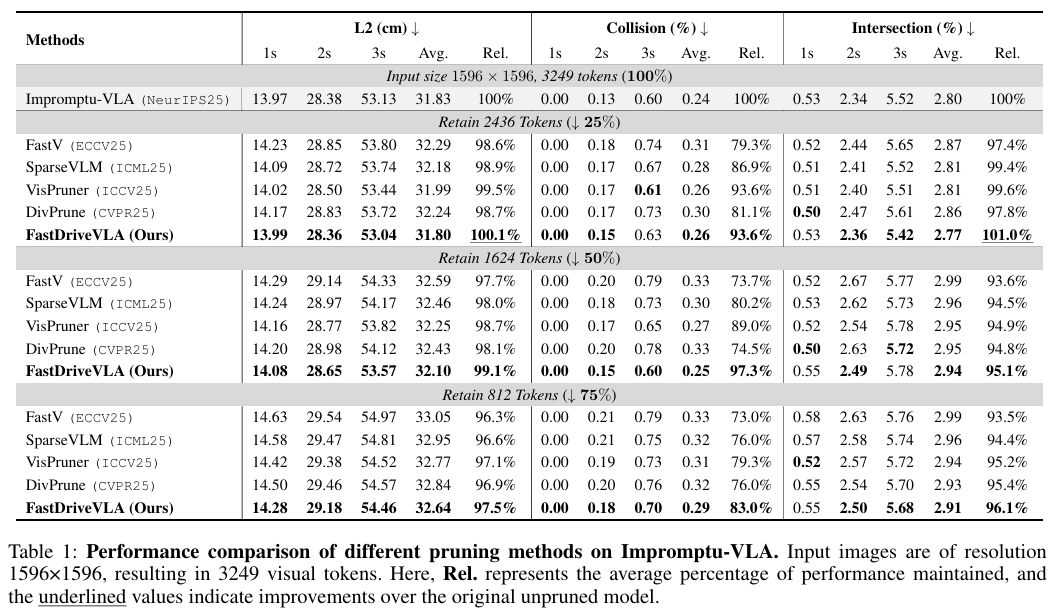
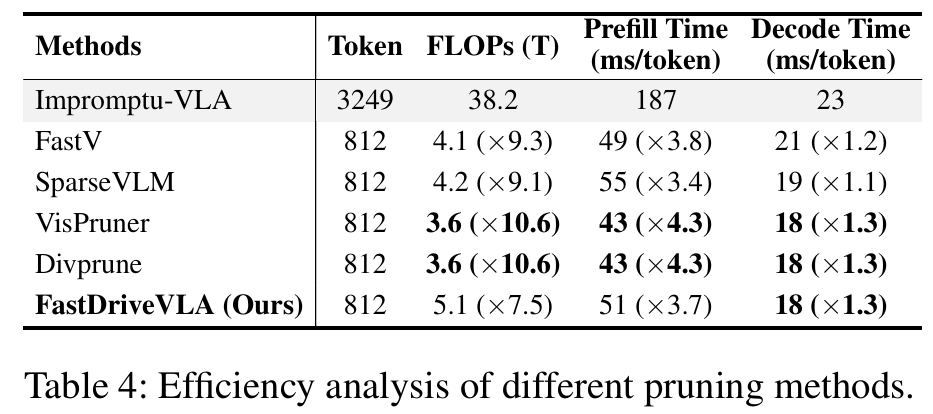
所提方法专为端到端自动驾驶 VLA 模型设计,在 nuScenes 开环规划基准上实现了 SOTA 性能。
算法框架:
实验结果:
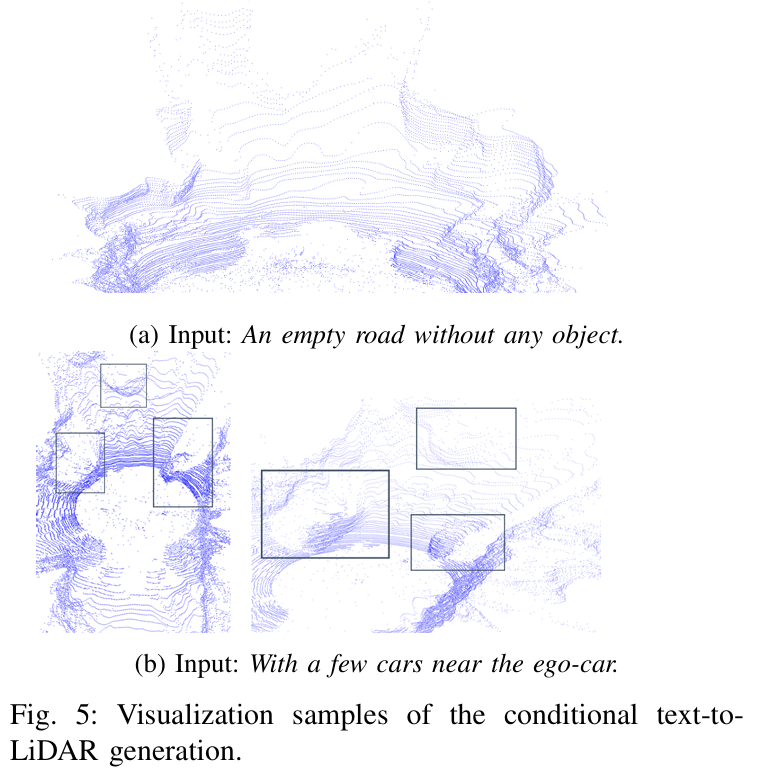
可视化:
TUM首创语言大模型驱动自动驾驶,复杂路况像人类一样决策
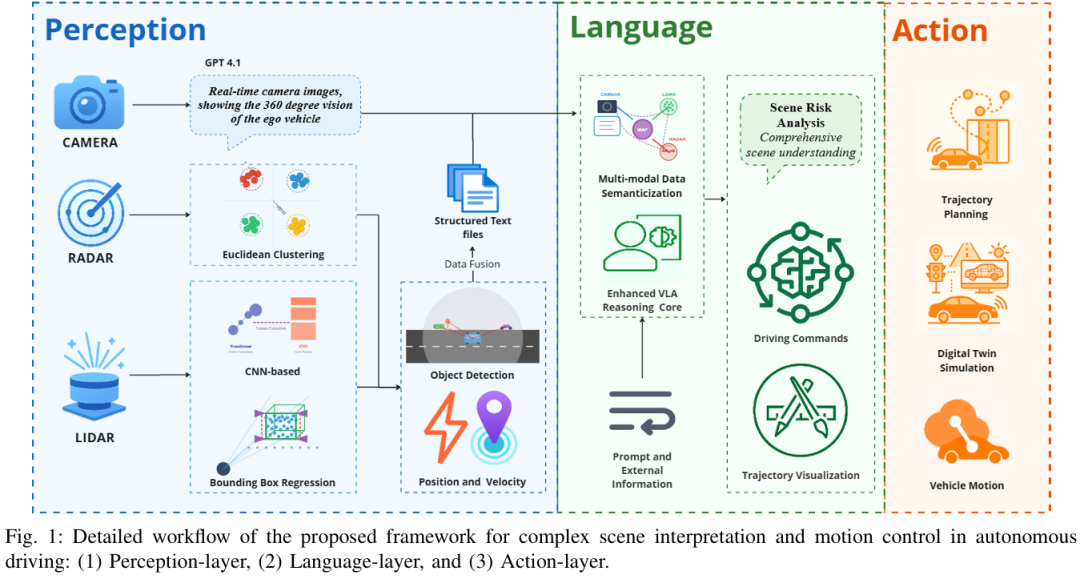
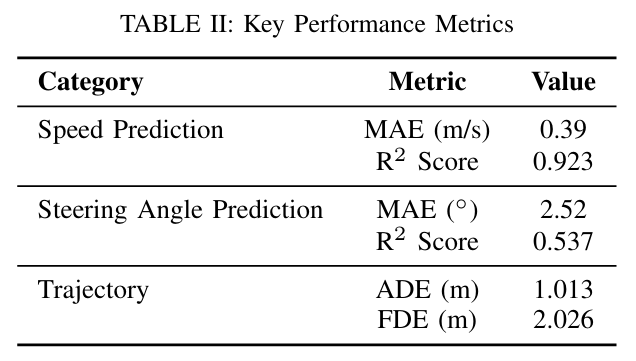
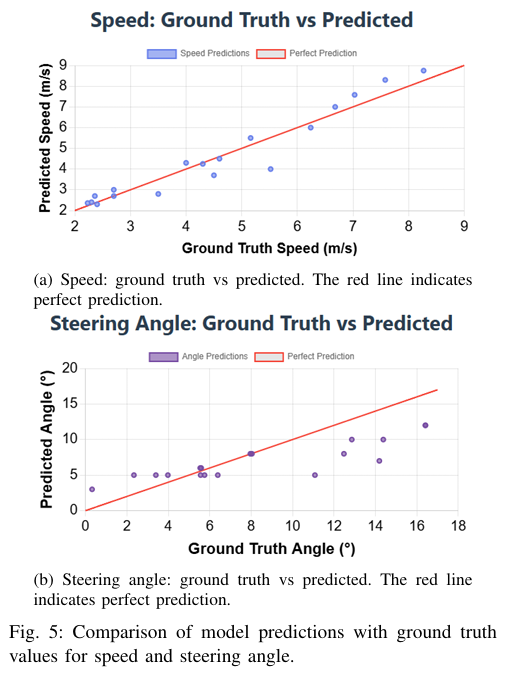
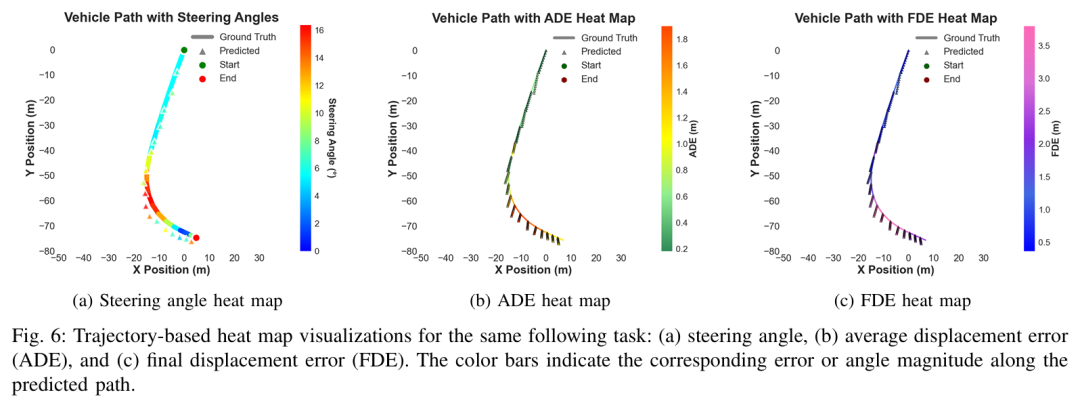
TUM提出了一种统一的感知-语言-动作(PLA)框架,通过整合多传感器融合和GPT-4.1增强的视觉-语言-动作推理核心,实现了自适应自动驾驶的上下文感知决策,在nuScenes数据集的城市交叉路口场景中,速度预测的平均绝对误差(MAE)降至0.39 m/s、R²分数达0.923,轨迹跟踪的平均位移误差(ADE)为1.013米。
论文标题:A Unified Perception-Language-Action Framework for Adaptive Autonomous Driving
论文链接:https://arxiv.org/abs/2507.23540
主要贡献:
提出统一的感知 - 语言 - 动作(PLA)框架,将多模态感知与基于大语言模型(LLM)的推理及运动规划紧密耦合,实现复杂城市环境下连贯且自适应的决策。
开发多传感器语义融合模块,整合激光雷达(LiDAR)、雷达和相机数据生成结构化场景描述,提升空间精度与语义丰富度。
通过 LLM 驱动的上下文推理增强对未见过场景(如施工区、突发行人行为)的泛化能力,实现鲁棒决策。
在含施工区的城市路口场景中验证了框架的有效性,展现出低预测误差与稳健的导航性能。
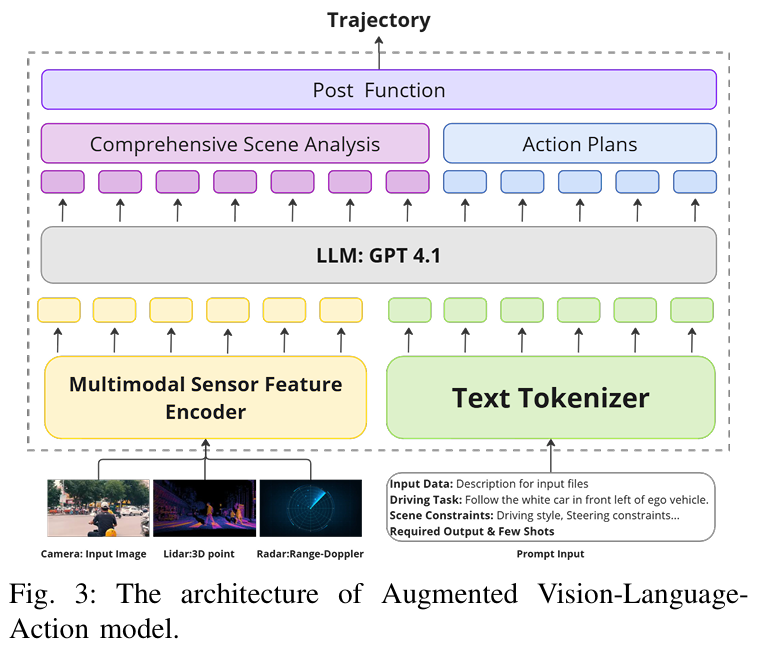
算法框架:
实验结果:
可视化:

星球内部为大家梳理了近40+技术路线,无论你是咨询行业应用、还是要找最新的VLA benchmark、综述和学习入门路线,都能极大缩短检索时间。星球还为大家邀请了数十位自动驾驶领域嘉宾,都是活跃在一线产业界和工业界的大佬(经常出现的顶会和各类访谈中哦)。欢迎随时提问,他们将会为大家答疑解惑。
我们是一个认真做内容的社区,一个培养未来领袖的地方。


我们还和多家自动驾驶公司建立了岗位内推机制,欢迎大家随时艾特我们。第一时间将您的简历送到心仪公司的手上。
针对入门者,我们整理了完备的小白入门技术栈和路线图。


















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









