




点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享多媒体顶会ACM MM的自动驾驶场景目标检测SOTA新工作!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群加入,也欢迎添加小助理微信AIDriver005
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Xiaojian Lin 等
编辑 | 自动驾驶之心
🧭 导读
在自动驾驶场景下的目标检测任务中,如何精准建模多尺度语义信息,一直是影响检测精度与部署效率的关键难题。当前主流架构(如 YOLO、DETR)在追求轻量化和速度的同时,往往牺牲了特征一致性与层次表达能力,难以同时兼顾小目标检测与复杂场景理解。
为此,本文提出了一种 兼顾检测鲁棒性与部署效率的新型检测框架 Butter。该框架在 Neck 层引入两项核心创新:
频率一致性增强模块(FAFCE):融合高频细节增强与低频噪声抑制,提升边界分辨率;
渐进式层次特征融合网络(PHFFNet):逐层融合语义信息,引入空间感知机制,强化多尺度特征表达。
通过上述设计,Butter 实现了对多尺度目标的结构化建模,并在 Cityscapes、KITTI 等数据集上以极低参数量超越现有 SOTA 方法的检测精度,充分展示了其在真实自动驾驶场景下的适应性与工程落地潜力。

论文链接:https://www.arxiv.org/pdf/2507.13373
代码仓库:https://github.com/Aveiro-Lin/Butter
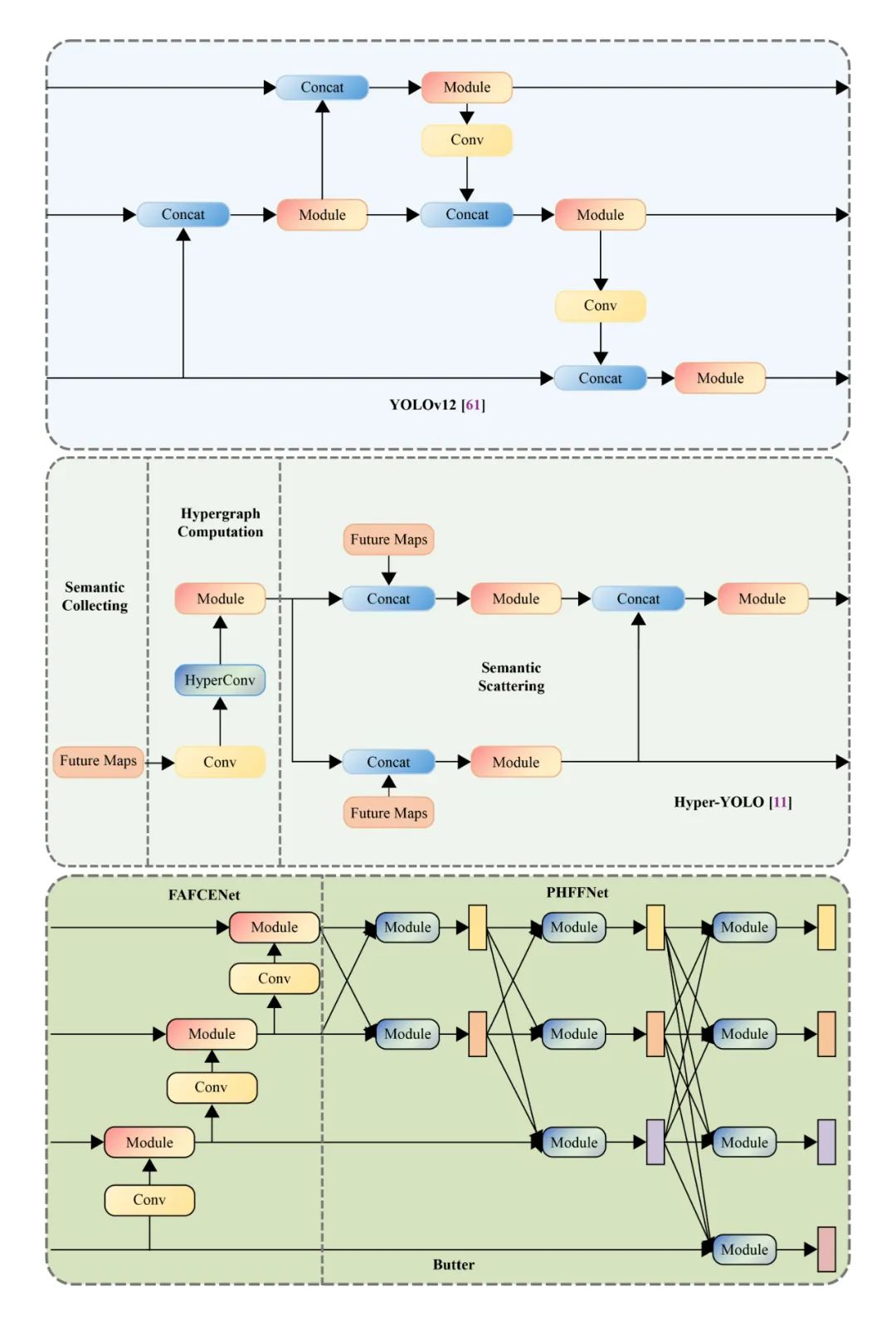
 动机
动机
在自动驾驶目标检测系统中,Neck 部署结构的设计对于平衡检测精度与模型效率至关重要。尽管当前已有多种轻量化方法被广泛应用(如 YOLO 系列),但这些方法常常在追求速度的同时,牺牲了特征表达的完整性与频率一致性,导致小目标漏检率高、边缘模糊、响应不稳定等问题,难以适应真实复杂路况。
现有 Neck 结构的常见问题主要集中在两类:
频率混叠:当前方法往往在上采样或融合阶段破坏了特征的频率结构,缺乏显式的频率建模机制,导致特征表达能力下降。
融合过程僵化:大多数 Neck 采用固定结构进行信息堆叠,无法根据不同尺度或语义层次进行动态融合,建模缺乏层次感,导致检测器感知能力受限。
为了克服上述结构性瓶颈,本文提出了一个 兼顾频率建模与多尺度融合的新型 Neck 框架 —— Butter,通过解耦式设计实现精度与效率的统一。
核心贡献:
本文设计了一个 频率一致性增强模块(FAFCE),首次在 Neck 层引入频域滤波思想,有效增强目标边界特征,抑制背景噪声。
提出 分层融合结构 PHFFNet,通过渐进式语义聚合提升多尺度表达能力,并引入空间感知机制。
本文在 Cityscapes、KITTI和BDD100K 等多个自动驾驶数据集上进行了广泛实验,验证了所提结构在多目标检测中的优势。
方法具备良好的 通用性与部署适配性,适用于主流 SOTA 检测器,具备轻量化潜力,可用于高性能自动驾驶视觉系统部署。
📘 方法简述
为了实现在复杂道路场景中的高精度目标检测与结构感知,本文提出了一个新颖的多阶段联合优化的目标检测框架Butter,其整体框架如图2所示。该模型专为自动驾驶环境中的单目图像目标检测任务设计,致力于在保证检测精度的同时,提升对遮挡物、结构边缘和语义层级的感知能力。
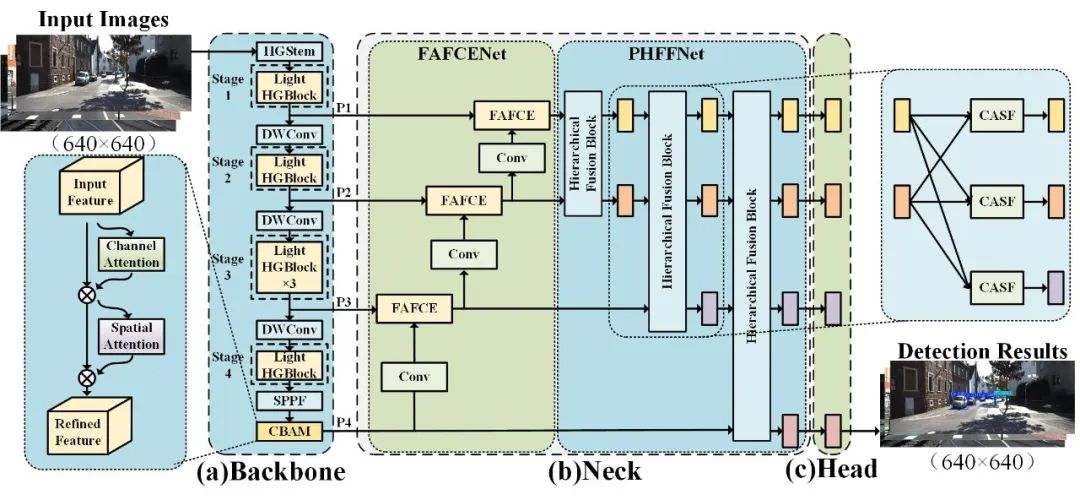
1)流程从一张尺寸为 640×640 的单目图像开始,经由 Backbone 模块中的 HGStem 提取初始特征;随后,这些特征将通过一系列轻量化 HGBlock、深度可分离卷积(DWConv)、以及卷积注意力模块(CBAM) 进行进一步细化,然后送入 Neck 模块。Neck 模块由两部分组成:FAFCENet 与 PHFFNet。在 Neck 模块之后,模型在 Head 层使用四个输出头,生成包括类别标签、置信度分数和边界框等在内的最终检测结果。
2)左下角的 CBAM 模块对通道与空间注意力进行建模,引导网络关注关键特征区域。
3)右上角的分层融合模块(Hierarchical Fusion Block)通过上下文感知空间融合模块(CASF)实现多层级的特征交互。图中水平方向箭头表示特征交换,斜向箭头表示上采样与下采样过程。
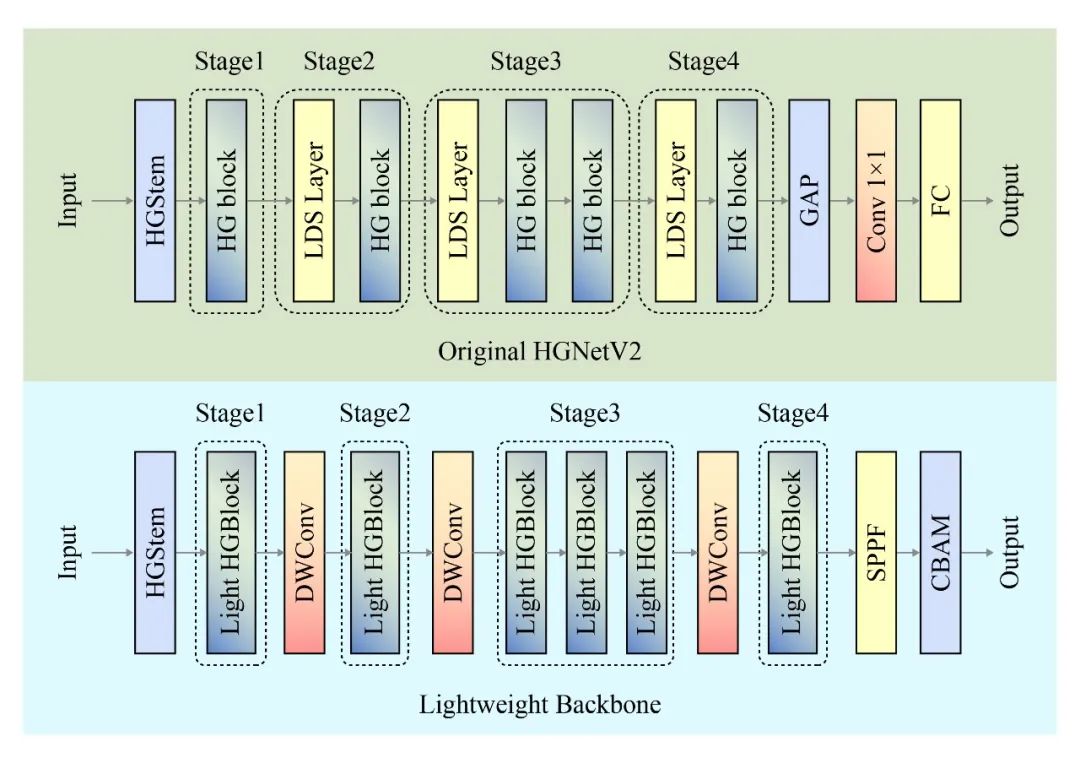
🔍 (1) Backbone轻量化改进
在 Backbone 设计中,本文以 HGNetV2 为基础进行轻量化改进,构建了更适用于自动驾驶场景的主干网络。我们提出的轻量级 HGBlock 用 GhostConv、RepConv、DWConv 和 LightConv 等模块替代传统卷积层,从而显著减少参数量,提升推理效率。
进一步地,我们将 Stage2 至 Stage4 中原有的 LDS 模块 替换为更具代表性的 DWConv 模块,在保持特征表达能力的同时优化计算开销。为增强特征提取与表达能力,我们在 Stage4 阶段后引入了 SPPF 模块(Spatial Pyramid Pooling Fast) 与 CBAM 注意力模块(Convolutional Block Attention Module),用于进行多尺度语义增强与注意力引导。
这种模块引入顺序的设计,避免了低层特征提取阶段过早引入复杂运算导致的学习干扰,同时充分利用高层特征的上下文信息,对目标进行更精确的识别与定位。整体策略在 保证实时性 的同时,增强了网络在复杂驾驶环境中的多尺度感知与判别能力。
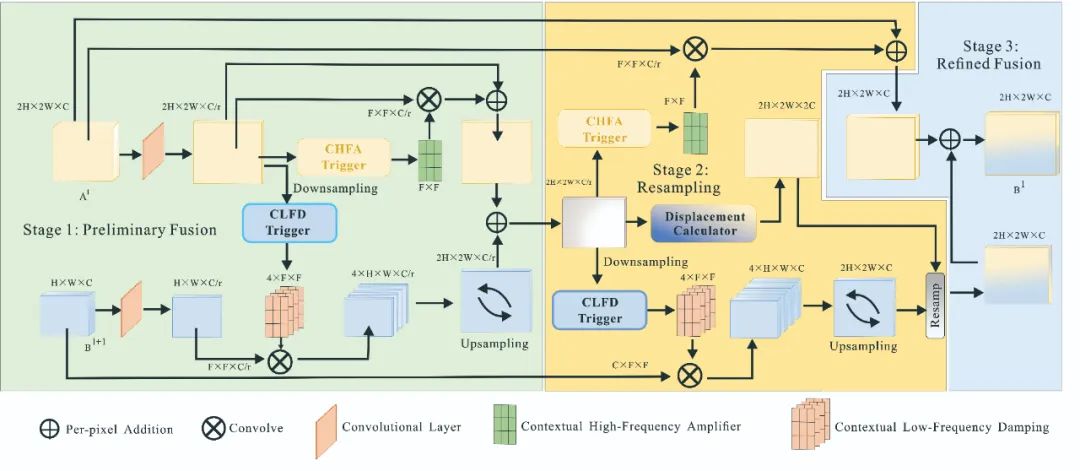
📝 (2) 频率自适应特征一致性增强(FAFCE)组件
在自动驾驶目标检测中,特征融合常因低层语义信息缺失、高层空间细节丢失,导致语义不一致与边界错位,进而影响小目标识别与边界检测。为此,Butter 引入 频率自适应特征一致性增强(FAFCE) 模块,通过 高频增强 与 低频抑制 两种机制,提升多尺度特征融合的准确性和鲁棒性。
特征融合基本形式:
传统特征融合可表示为:
其中, 是 Backbone 提取的第 层特征图, 是 层的融合特征, 是带可学习参数的上采样操作。但该方式容易造成特征模糊和边界弱化。
高频增强(High-Frequency Amplifier):
FAFCE 通过增强高频分量,提取目标边界细节,形式为:
其中 为高频增强操作, 为可学习的滤波器矩阵, 表示逐元素乘。
低频抑制(Low-Frequency Damping):
通过抑制不相关的低频成分,强化判别区域:
其中 为低频抑制操作, 是可学习参数。
FAFCE 共包含三个阶段以逐步提升融合效果:
阶段1:初步融合(Preliminary Fusion)
其中 和 为特征权重矩阵。
阶段2:重采样(Resampling)
为空间位置对齐函数,用于匹配高低层特征的空间结构。
阶段3:精细融合(Refined Fusion)
最终输出的融合特征 会传递至 Neck 中的 PHFFNet 模块,提升边界感知和目标定位精度。
整体而言,FAFCE 通过频率增强机制,在保证轻量化的同时,显著提升了特征融合的一致性与精度,特别适用于自动驾驶等对边界与小目标敏感的任务场景。
📑 (3) 分层渐进特征融合网络(PHFFNet)组件
为了进一步提升特征层间的表达与对齐能力,Butter 模型引入了 Progressive Hierarchical Feature Fusion Network(PHFFNet) 模块,实现多层次特征的高效融合。PHFFNet 采用从低层向高层的逐级融合策略,有效缓解了非相邻层之间的语义差异,特别是在自动驾驶这类对目标边界要求较高的场景中,显著提升了检测准确性与对齐效果。
分层特征融合的数学表达:
PHFFNet 通过以下三个步骤实现逐层融合:
1. 初始融合阶段
将低层特征
与
进行融合,得到中间特征:
2. 中间融合阶段
将上一步结果
与更高层的
融合,得到:
3. 最终融合阶段
继续与
融合,得到最终融合特征
:
其中, 、 、 为可学习的融合权重矩阵,用于控制不同层特征的融合强度。
空间动态权重机制(CASF)
PHFFNet 内置的 CASF(Context-Aware Spatial Fusion) 机制能动态地为不同空间位置的多层特征分配权重,从而增强模型对不同尺度与空间目标的适应性。该机制可通过如下公式表达:
其中, 表示来自层 的特征向量在位置 的投影, 是空间融合权重,且满足归一性约束:
该设计确保了每个位置上的融合结果是多层特征的平衡表达,有效抑制了特征冲突与冗余,有助于复杂场景下的目标检测表现提升。
🧪 实验结果
📊 (1) 定量分析
本文在三个主流自动驾驶数据集上对 Butter 模型进行了全面评估,包括 KITTI、BDD100K 和 Cityscapes,并与多个主流轻量级检测方法进行了对比。
在 KITTI 数据集上,Butter 在 mAP@50 上达到 94.4%,比当前最优方法 TOD-YOLOv7 高出 1.2 个百分点,而计算量(GFLOPs)仅为后者的约 1/3,展示了出色的 性能与效率平衡。
在 BDD100K 和 Cityscapes 数据集上,Butter 分别取得 53.7% 和 53.2% 的 mAP@50,显著优于同为轻量级的 Hyper-YOLO-S 方法,尤其在 Cityscapes 上提升达到 1.6。同时,Butter 模型的 参数量 比 Hyper-YOLO-S 减少了约 64%,显示出更优的 部署适应性。
综上,Butter 在保持检测精度领先的同时,显著降低了 模型复杂度,兼顾 检测性能、效率 和 可部署性,在多个数据集上实现了最优的综合性能。
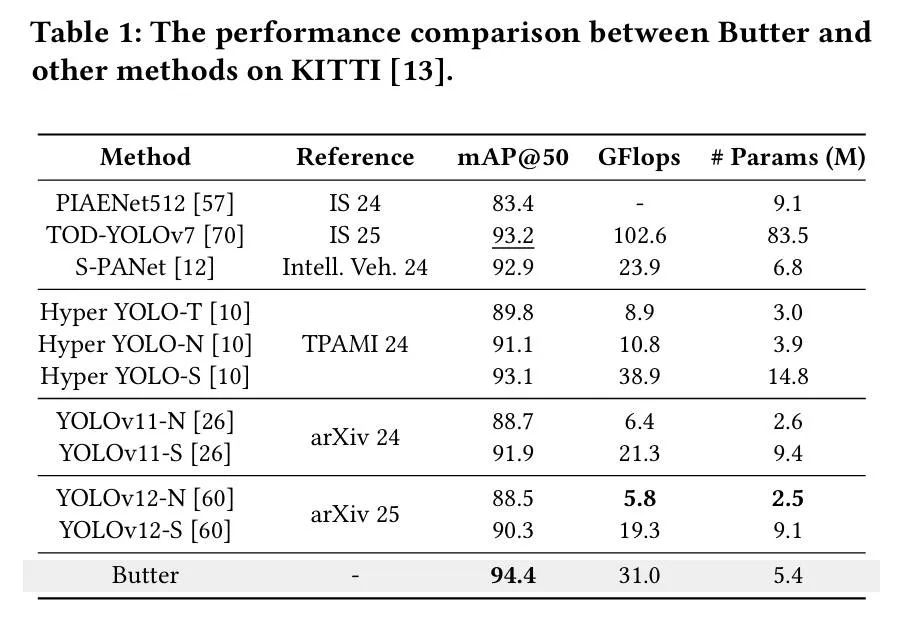
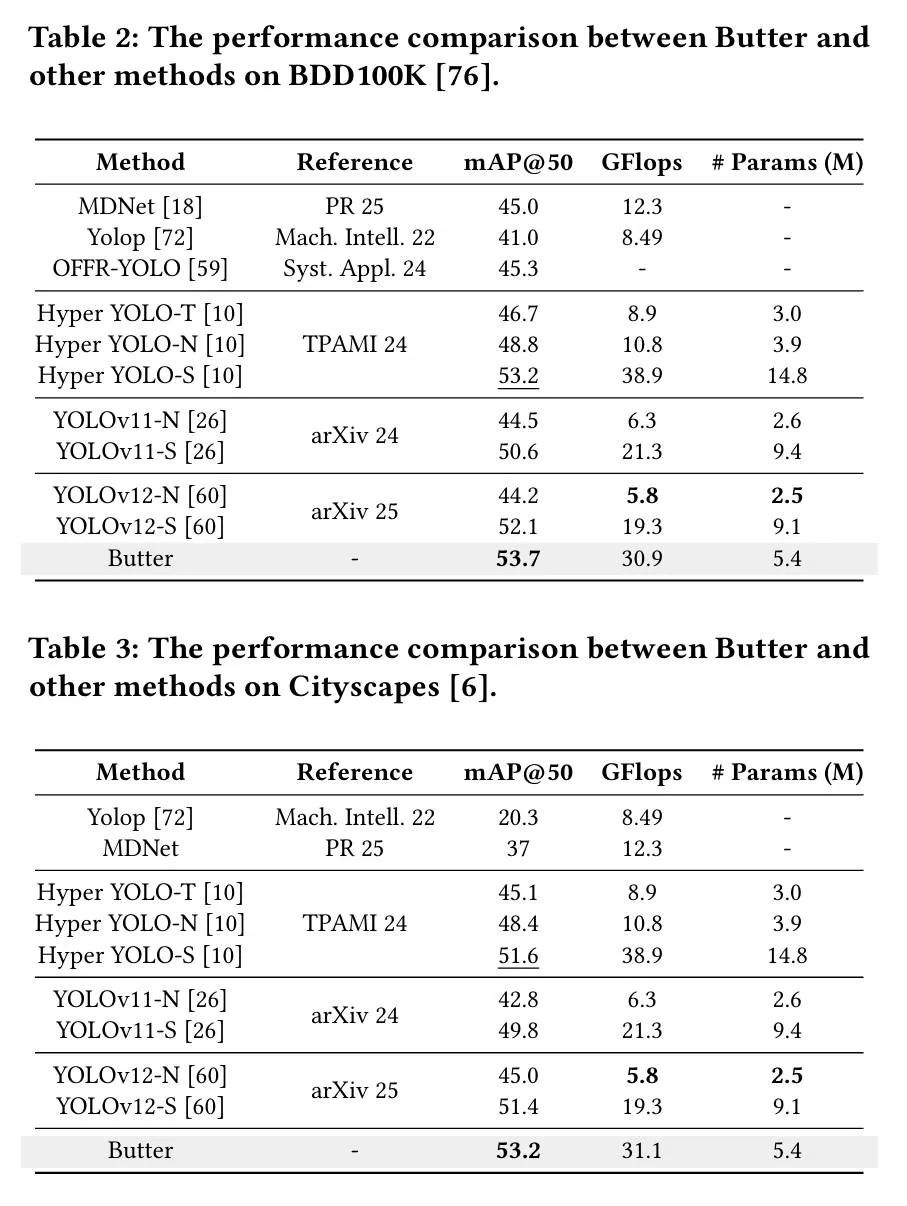
🎯 (2) FAFCE 定性分析
为了进一步验证 FAFCE(Feature-Aware Fusion and Context Enhancement) 模块对目标检测性能的提升作用,本文对其 感受野变化 和 注意力热力图 进行了对比分析,如图 5 和图 6 所示。
在图 5 中,我们观察到:
在 未使用 FAFCE 模块 的情况下,模型的特征响应主要集中在图像中心区域,响应范围较窄,颜色变化不明显,说明模型的感受野较小,无法充分利用图像中的上下文信息。
而 引入 FAFCE 后,图像的响应区域更广泛,颜色对比明显增强,反映出模型对图像上下文和细节的关注程度显著提升。
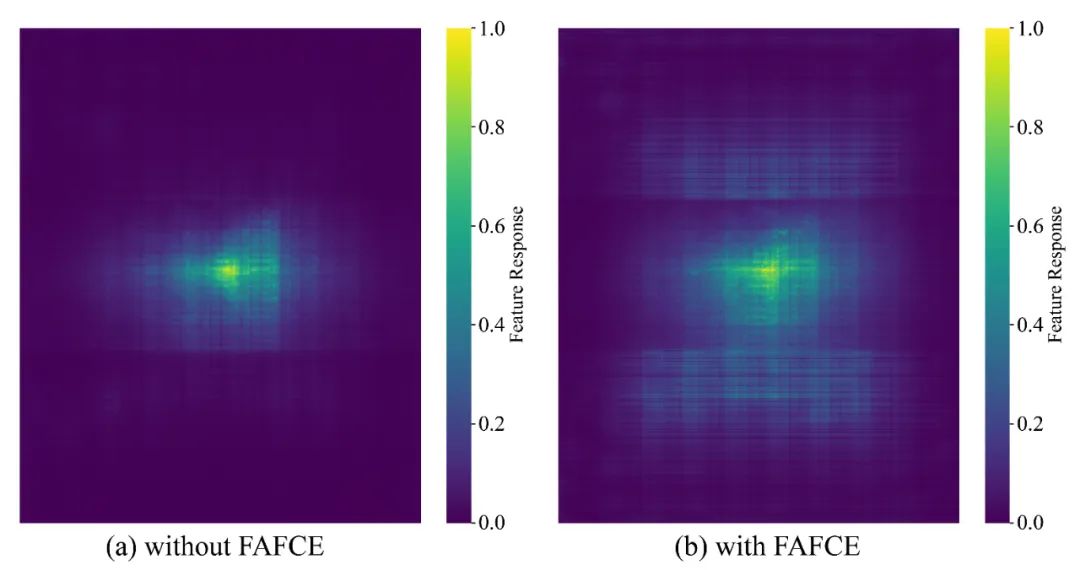
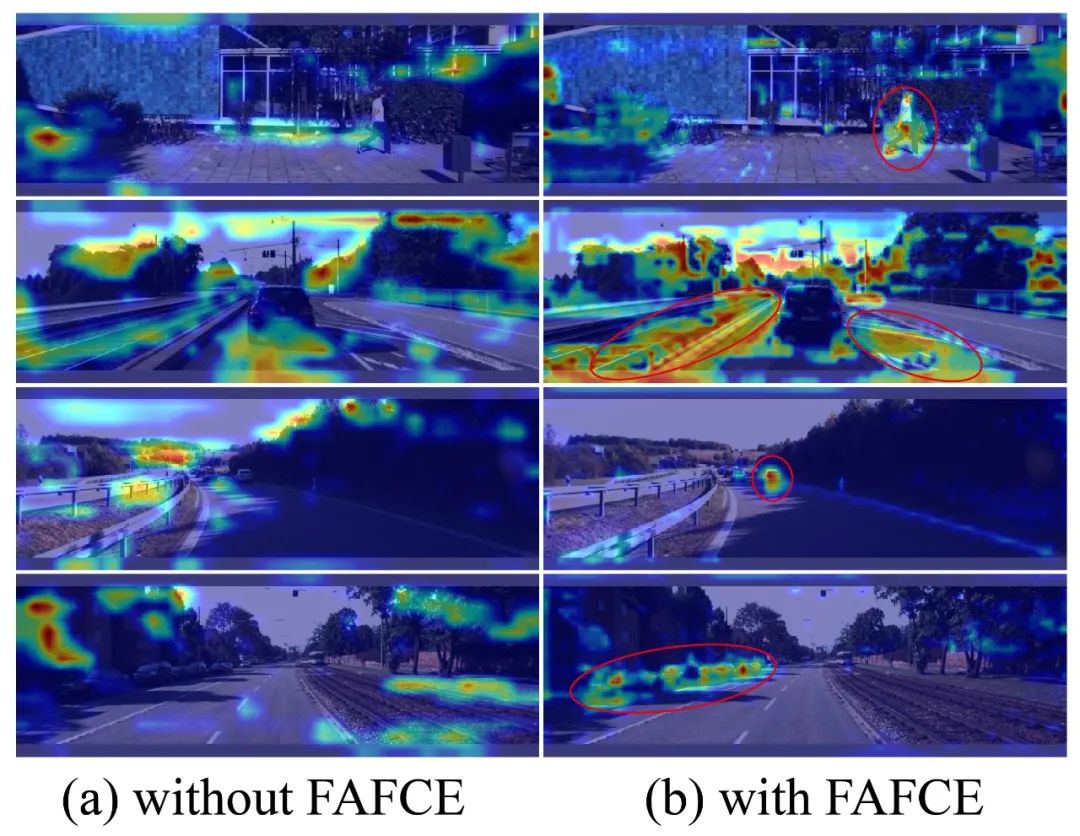
在图 6 的热力图对比中也可以直观地看出:
未使用 FAFCE 的模型注意力较为分散,关注区域模糊,容易导致目标定位不准确;
加入 FAFCE 后,注意力更集中于关键目标及其上下文区域,显著提升了模型对关键物体的识别能力。
✅ 这一变化说明 FAFCE 模块能够有效增强模型的上下文感知能力,提升注意力机制的集中性和判别性,从而提高目标检测的准确性,特别适用于自动驾驶等需要精细理解场景的任务。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









