




点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享Waymo LLC & UT Austin最新的工作!SceneDiffuser++:首个端到端生成式世界模型实现60秒城市级交通仿真!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Shuhan Tan等
编辑 | 自动驾驶之心
引言与背景
交通仿真的核心目标是通过大量合成仿真里程,补充有限的真实驾驶里程,以支持自动驾驶系统的测试与验证。理想状态下,一个生成式仿真城市(称为CitySim)应能基于城市地图和自动驾驶软件栈,无缝仿真从A点到B点的完整行程——不仅能生成初始场景、驱动动态代理(车辆、行人等),还能控制交通灯等环境因素,实现场景的全方面动态管理。
实现CitySim需要整合多项技术:场景生成(初始化场景)、代理行为建模(驱动场景动态)、遮挡推理、动态场景生成(代理的生成与移除)以及环境仿真(如交通灯控制)。现有技术在动态场景生成和环境仿真等方面关注较少,而SceneDiffuser++作为首个端到端生成式世界模型,通过单一损失函数训练,整合了上述所有需求,实现了城市级A到B点的完整仿真。
与主流的事件级仿真(通常短于10秒)不同,行程级仿真(trip-level)需要处理更长时间的动态变化:初始代理可能离开视野,新代理需无缝进入,交通灯状态需随路线动态更新,否则会出现“仿真漂移”(simulation drift)——即仿真场景与真实世界的偏差累积。SceneDiffuser++的核心价值在于解决这些行程级仿真的关键挑战。
核心挑战与创新点
行程级仿真的独特挑战
相比事件级仿真,行程级仿真面临三大核心挑战:
动态代理管理:代理需随时间自然生成(进入场景)和移除(离开场景),而非固定初始集合;
遮挡推理:代理可能被障碍物遮挡(occlusion)后重新出现(disocclusion),需准确建模可见性;
环境动态性:交通灯等环境因素的状态需随时间和位置动态变化,影响代理行为。
SceneDiffuser++解析
为应对这些挑战,SceneDiffuser++提出以下创新:
统一生成式世界模型:通过扩散模型(diffusion model)统一建模代理和交通灯等异质场景元素,无需拆分模块;
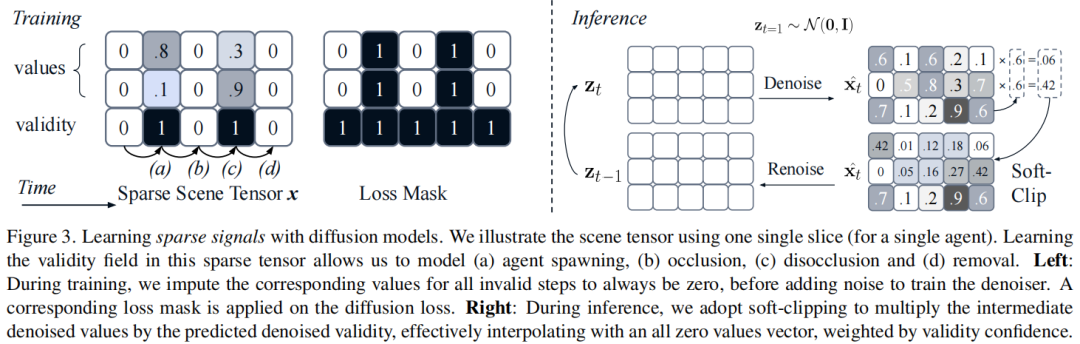
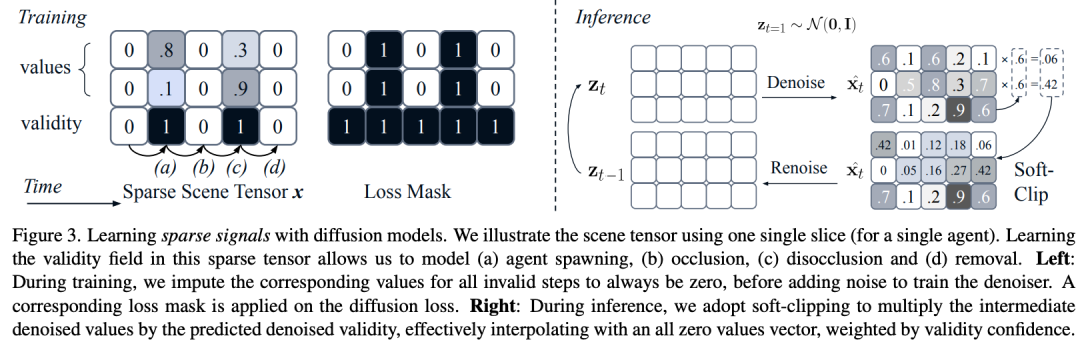
稀疏张量学习:引入“有效性通道”(validity channel),与代理的位置、大小等特征共同预测,实现代理生成、移除、遮挡的联合建模(图3);
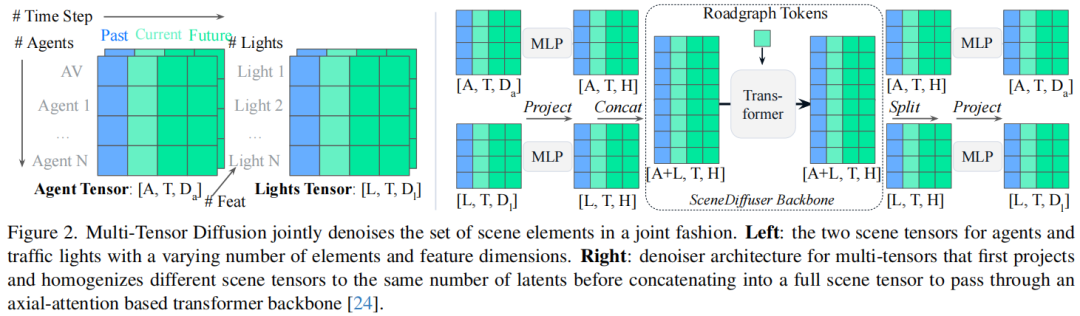
多张量扩散:将不同维度的场景元素(如代理和交通灯)投影到统一潜在空间,通过Transformer backbone处理,支持异质元素的联合仿真(图2);
soft clipping:推理时通过软剪辑策略稳定稀疏张量的生成,避免硬剪辑导致的不自然跳跃,确保代理生成/移除的平滑性。
方法详解
场景张量与多张量建模
SceneDiffuser++将场景表示为场景张量(scene tensor),其中每个元素(代理或交通灯)的特征包括:
代理:有效性(是否可见)、位置、大小、类型等;
交通灯:有效性、位置、状态(红/绿/黄等)。
多个场景张量(如代理张量和交通灯张量)构成多张量(multi-tensor),模型通过投影层将不同维度的张量转换为统一潜在维度,再通过Transformer进行联合去噪(denoising),最终还原为原始维度的场景元素(图2)。这种设计允许模型同时处理代理和交通灯等异质元素的动态变化。
扩散模型的训练与推理
SceneDiffuser++基于扩散模型原理:正向过程逐步向场景张量添加高斯噪声,反向过程通过去噪网络预测原始信号。训练时,对无效代理的特征(如被遮挡或未生成的代理)赋值为0,并通过损失掩码(loss mask)聚焦有效特征的学习;推理时,通过软剪辑将低有效性的代理特征压制为0,实现稀疏张量的稳定生成(图3)。
训练损失函数定义为:
其中, 为场景张量, 为上下文(如地图), 为扩散步骤, 为损失权重,模型通过该损失学习从含噪信号中恢复真实场景的能力。
任务建模
SceneDiffuser++将不同仿真任务统一为inpainting tasks:
行为预测(BP):已知历史步骤,预测未来步骤(掩码历史为1,未来为0);
场景生成(SceneGen):已知部分代理,预测其余代理(掩码已知代理为1,待预测为0);
控制掩码:通过随机0/1掩码增强模型的可控性。
实验验证
数据集与评估指标
实验基于WOMD-XLMap(扩展了地图范围的Waymo Open Motion Dataset),支持公里级路线的长时仿真。评估采用Jensen-Shannon(JS)散度,衡量仿真数据与真实数据的分布差异(值越低,仿真越真实),指标包括:
有效代理数量、生成/移除代理数量及距离;
离路率(offroad rate)、碰撞率;
平均速度、交通灯状态转换概率等。
核心结果
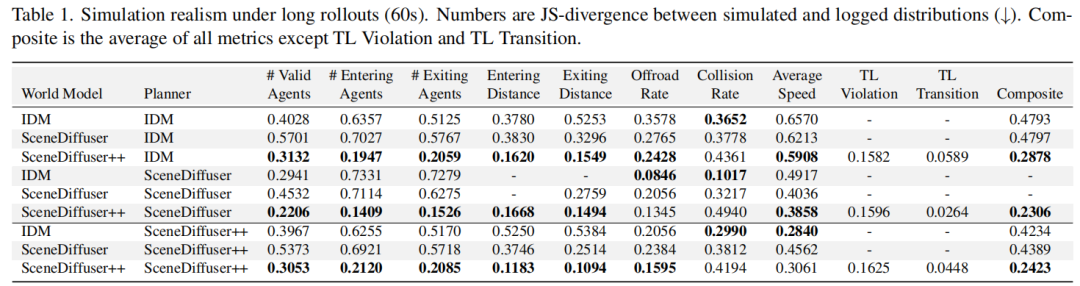
与IDM(基于规则的模型)和SceneDiffuser(前序扩散模型)相比,SceneDiffuser++在所有指标中表现更优:
代理生成与移除:生成/移除代理的数量和距离分布与真实数据更接近(JS散度更低),例如当IDM作为规划器时,SceneDiffuser++的“生成代理数量”JS散度为0.1947,远低于IDM的0.6357和SceneDiffuser的0.7027(表1);
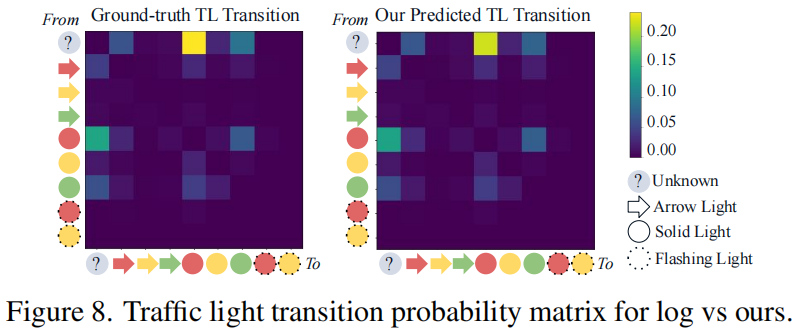
交通灯仿真:交通灯状态转换概率与真实数据高度一致(图8),而IDM和SceneDiffuser不支持交通灯仿真;
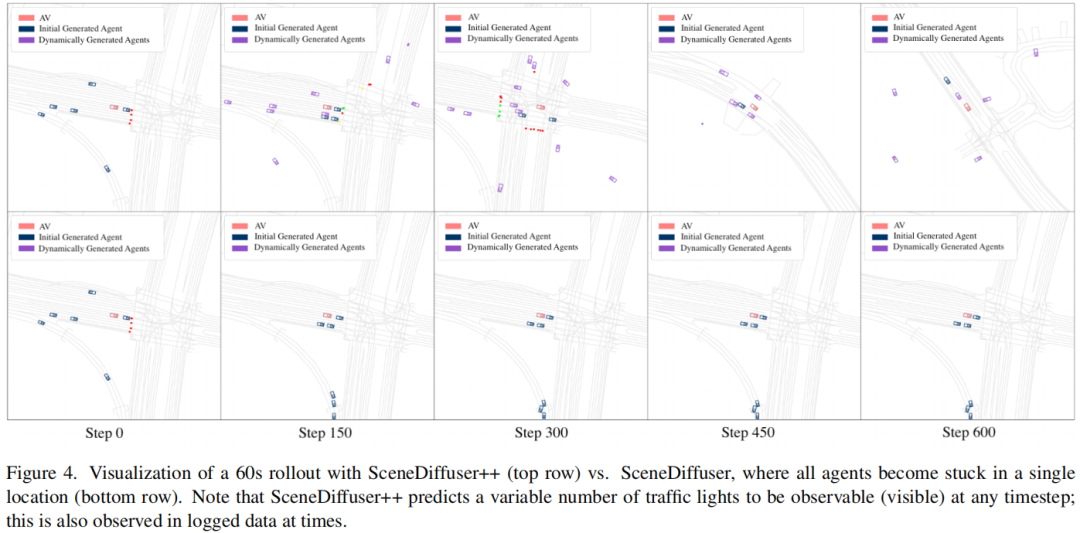
长时稳定性:60秒仿真中,SceneDiffuser++能保持代理动态性和交通灯合理性,而SceneDiffuser的代理会停滞在初始位置(图4)。
关键设计的有效性
软剪辑策略:在稀疏张量生成中,软剪辑的综合性能(如碰撞率、离路率)优于硬剪辑和无剪辑(表3);

重规划频率:更频繁的重规划(如每10步一次)能降低碰撞率,但可能影响代理生成的自然性(表2);
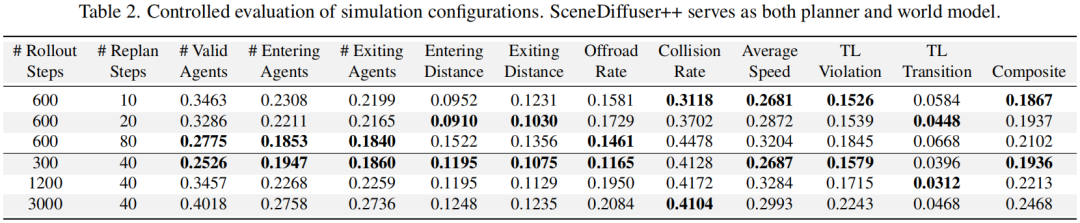
仿真时长:随仿真时长增加(30秒到300秒),误差累积导致部分指标下降,但代理生成/移除的位置合理性仍保持稳定(表2)。
结论与意义
SceneDiffuser++的核心贡献在于:
提出CitySim概念,明确行程级仿真的需求与挑战;
设计统一生成式框架,首次整合代理动态生成、遮挡推理和交通灯仿真;
通过稀疏张量学习和软剪辑,解决扩散模型在动态场景生成中的稳定性问题。
参考
[1] SceneDiffuser++: City-Scale Traffic Simulation via a Generative World Model
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 2391
2391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









