



作者 | 龙睛焕像师 编辑 | 龙哥读论文
点击下方卡片,关注“3D视觉之心”公众号
第一时间获取3D视觉干货
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
龙哥导读:
这项研究将3D高斯撒点技术与SE(3)运动表示相结合,解决了单目视频动态场景重建的长期难题,在3D追踪精度上比现有方法提升73%!不仅学术价值高,在AR/VR、自动驾驶等领域也有巨大应用潜力。
想象一下,用手机随便拍一段视频,就能自动重建出整个动态场景的3D模型,还能追踪每个物体的运动轨迹?这听起来像是科幻电影里的情节,但UC Berkeley和Google Research的研究团队刚刚把这个梦想变成了现实!
论文中的方法可以重建动态场景并渲染出不同时间点的视图:


这项名为"Shape of Motion"的技术,能从单目视频中重建出完整的4D场景(3D空间+时间维度)。最神奇的是,它不仅能看到物体的运动轨迹,还能从任意视角渲染出动态场景!
系统整体架构图展示了方法的创新之处:
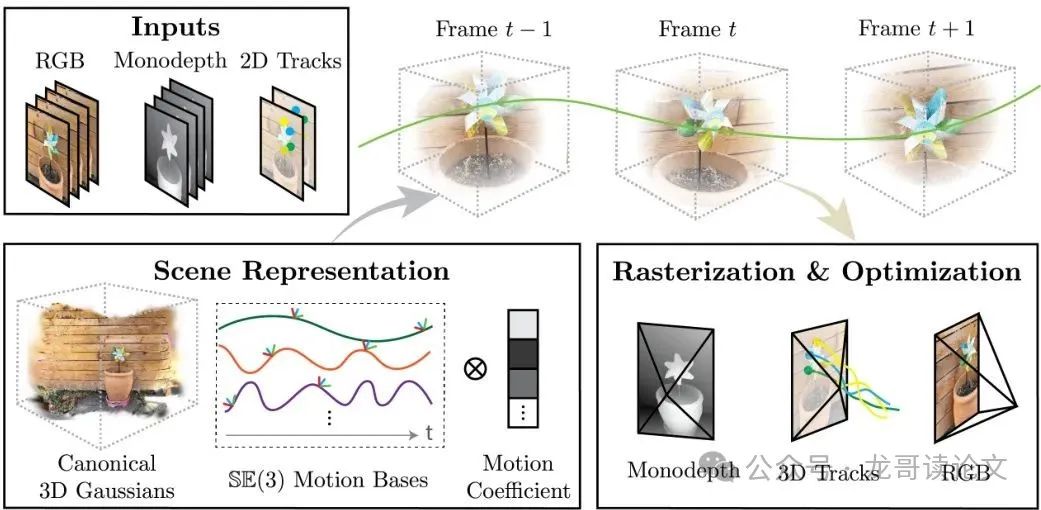
这项技术到底有多厉害?它能同时做到:1) 实时新视角合成;2) 全局一致的3D追踪;3) 处理复杂的动态场景。这可能会彻底改变影视特效、游戏开发、自动驾驶等多个行业的工作流程!
原论文信息如下:
论文标题:
Shape of Motion: 4D Reconstruction from a Single Video发表日期:
2024年07月作者:
Qianqian Wang, Vickie Ye, Hang Gao, Jake Austin, Zhengqi Li, Angjoo Kanazawa发表单位:
UC Berkeley, Google Research原文链接:
https://arxiv.org/pdf/2407.13764.pdf项目链接:
shape-of-motion.github.io

引言:单目视频的动态场景重建有多难?
想象一下,用手机随便拍一段视频,就能自动重建出整个动态场景的3D模型,还能追踪每个物体的运动轨迹?这听起来像是科幻电影里的情节,但UC Berkeley和Google Research的研究团队刚刚把这个梦想变成了现实!
传统的动态场景重建方法要么依赖多视角视频,要么需要深度传感器,要么只能在准静态场景下工作。而单目视频的动态场景重建,就像是在黑暗中用一只手摸大象——信息极度匮乏,问题高度病态。
SE(3)(Special Euclidean group in 3D space,三维特殊欧几里得群)是描述3D空间中刚体运动的数学表示,包括旋转和平移。而本文提出的方法巧妙地利用了SE(3)运动基底来表示场景运动。
核心贡献:Shape of Motion——4D重建新方法
这项名为"Shape of Motion"的技术,能从单目视频中重建出完整的4D场景(3D空间+时间维度)。最神奇的是,它不仅能看到物体的运动轨迹,还能从任意视角渲染出动态场景!
本方法的两大核心创新点:
1. 低维运动表示:利用一组紧凑的SE(3)运动基底来表示场景运动,每个点的运动都是这些基底的线性组合
2. 数据驱动先验整合:有效整合单目深度图和长距离2D轨迹等噪声监督信号,形成全局一致的动态场景表示
技术解析:3D高斯点与运动基底的秘密
本方法采用3D高斯点(3D Gaussians)作为场景表示的基本单元。与传统的NeRF等隐式表示不同,3D高斯点是显式的、可微的场景表示,能够实现实时渲染。
每个3D高斯点在规范帧t₀中的参数定义为g₀≡(μ₀,R₀,s,o,c),其中:
μ₀:规范帧中的3D均值
R₀:规范帧中的方向
s:尺度
o:不透明度
c:颜色
这些3D高斯点会随时间进行刚体变换,其运动轨迹通过一组共享的SE(3)运动基底来表示。这种表示方法既保持了灵活性,又通过共享基底实现了运动规律的低维约束。
动态场景表示的秘密武器
为了克服单目视频重建的欠约束问题,本方法巧妙地利用了多种数据驱动先验:
单目深度估计:使用现成的Depth Anything模型获取每帧的深度图
长距离2D轨迹:使用TAPIR模型获取前景像素的长距离2D轨迹
运动物体分割:使用Track-Anything获取每帧的运动物体掩码
这些先验信息虽然各自都有噪声,但通过精心设计的优化框架,能够被整合成一个全局一致的动态场景表示。这就像是用多个不准确的指南针,最终找到正确的北方!
优化过程全解析
优化过程就像拼装精密机械表⚙️——每个零件都要完美契合!方法首先获取三种关键输入:
运动物体掩码:用Track-Anything标注移动区域(只需用户点几下)
单目深度图:Depth Anything提供每帧深度线索
2D轨迹:TAPIR生成像素级长距离运动轨迹
初始化阶段选择包含最多3D轨迹的帧作为规范帧,动态高斯的运动基底通过加权Procrustes对齐算法初始化:
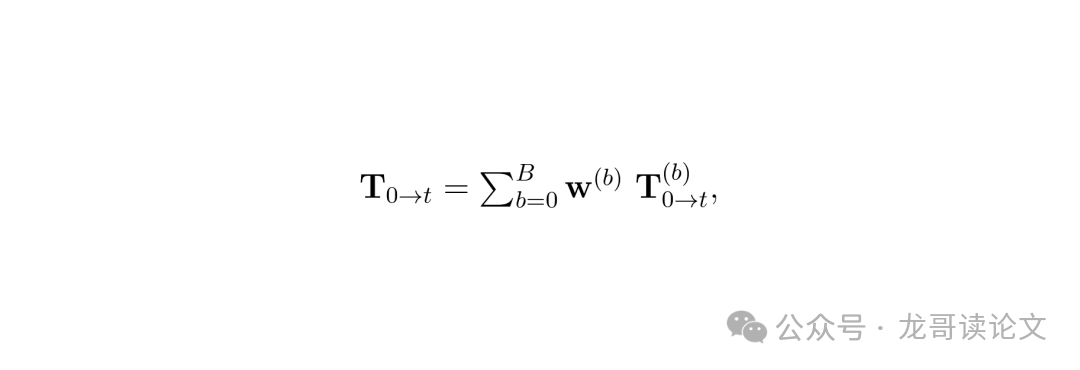
图:运动基底参数化公式,其中𝐓表示SE(3)变换,𝐰为权重系数
训练时采用双管齐下的损失函数:
重建损失:确保每帧渲染与输入一致
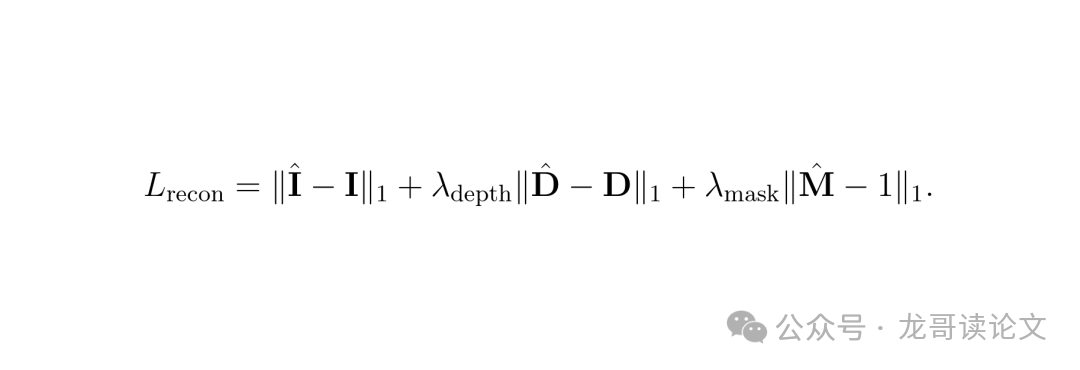
图:重建损失函数,包含RGB、深度和掩码约束
运动约束:通过2D轨迹和刚性损失保持运动一致性
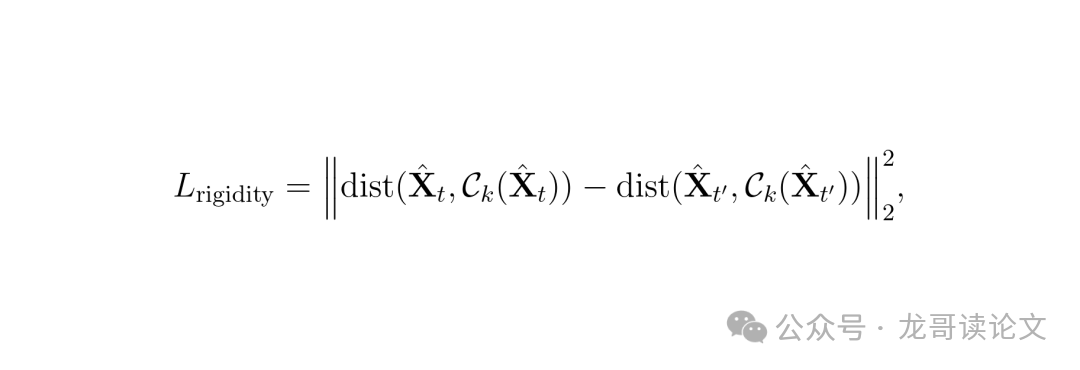
图:刚性损失确保局部结构在运动中保持稳定
硬件配置上,在A100 GPU上训练300帧视频仅需2小时,渲染速度可达40fps——实时性完胜传统NeRF方法!

实验结果:效果有多强?
在iPhone数据集上的结果堪称降维打击🚀!看这组对比数据:
*表格超出部分左右可以滑动
Method | 3D EPE↓ | 05↑D↑ | 10↑D↑ | AJ↑ | avg↑OA↑ | PSNR↑ | SSIM↑ |
|---|---|---|---|---|---|---|---|
T-NeRF [21] | - | - | - | - | - | 15.60 | 0.55 |
HyperNeRF [65] | 0.182 | 28.4 | 45.8 | 10.1 | 19.3 | 15.99 | 0.51 |
DynIBaR [52] | 0.252 | 11.4 | 24.6 | 5.4 | 8.7 | 13.41 | 0.48 |
Deformable-3D-GS [108] | 0.151 | 33.4 | 55.3 | 14.0 | 20.9 | 11.92 | 0.49 |
CoTracker+DA | 0.202 | 34.3 | 57.9 | 24.1 | 33.9 | - | - |
TAPIR+DA | 0.114 | 38.1 | 63.2 | 27.8 | 41.5 | - | - |
| Ours | 0.082 | 43.0 | 73.3 | 34.4 | 47.0 | 16.72 | 0.63 |
表1:iPhone数据集量化对比,本方法在3D追踪、2D追踪和新视角合成全面领先
73.3%的3D追踪准确率(10cm阈值)比第二名高出整整10个百分点,47%的2D追踪准确率更是碾压级表现!新视角合成的PSNR指标达到16.72,清晰度肉眼可见提升👇

图4:新视角合成效果对比(左:训练视角,绿框为不可见区域)
运动轨迹可视化更展现惊人优势——传统方法在旋转风车场景完全崩坏,而本方法轨迹平滑精准:

图3:3D运动轨迹对比(仅展示50帧片段)
在Kubric合成数据集上,3D追踪误差(EPE)低至0.16,比基线方法提升21%!运动系数PCA可视化直接暴露算法黑箱——不同颜色对应不同刚体运动组件:
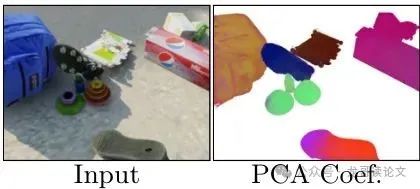
图6:运动系数的前三PCA分量(不同颜色代表不同刚体组件)
消融实验实锤关键技术价值:
*表格超出部分左右可以滑动
Ablation | EPE↓ | 05↑D↑ | 10↑D↑ |
|---|---|---|---|
Full Model | 0.082 | 43.0 | 73.3 |
Transl.Bases | 0.093 | 42.3 | 69.9 |
Per-Gaussian Transl. | 0.087 | 41.2 | 69.2 |
No SE(3) Init. | 0.111 | 39.3 | 65.7 |
No 2D Tracks | 0.141 | 30.4 | 57.8 |
表3:消融实验结果(数值越低/越高越好)
移除SE(3)运动基底导致性能下降15%,而去掉2D轨迹监督直接腰斩精度——证明双轨监督机制的必要性!

讨论与未来展望
当前方法存在四大阿喀琉斯之踵:
⏱️ 耗时优化:仍需每场景2小时训练,难实时流式处理
🔄 视角局限:大视角变化时缺失生成能力
📷 相机依赖:纹理缺失场景的位姿估计可能失败
✋ 人工干预:需用户标注运动物体掩码
未来突破方向已然清晰:
🚀 前馈网络:开发端到端模型直接输出4D重建
🧠 生成先验:融入扩散模型处理大视角变化
🤖 全自动分割:用SAM等模型替代人工标注
论文投稿后已有4篇相关研究涌现(如MoSCA、ModGS等),但都采用类似的优化框架。谁能率先突破实时4D重建,谁将主宰下一代视觉算法!
结论:Shape of Motion的无限可能
这项研究突破了单目动态重建的三重边界:
🌐 空间维度:首次实现全序列3D运动轨迹重建
⏳ 时间跨度:支持10秒以上的长时运动追踪
🎭 场景复杂度:处理多刚体运动的动态场景
当AR眼镜能实时重建运动物体轨迹,当自动驾驶系统精准预测行人运动路径,当电影特效摆脱昂贵的动捕设备——本文会记得这项研究点燃了4D视觉的革命火炬🔥
龙哥点评
论文创新性分数:★★★★☆
SE(3)运动基底+3D高斯的组合拳创新十足,但数据先验整合思路已有雏形
实验合理度:★★★★★
iPhone+Kubric双数据集验证,消融实验完整,对比基线选择全面
学术研究价值:★★★★★
开辟单目4D重建新范式,已被多篇后续研究引用
稳定性:★★★☆☆
依赖准确的相机位姿估计,纹理缺失场景易失效
【3D视觉之心】技术交流群
3D视觉之心是面向3D视觉感知方向相关的交流社区,由业内顶尖的3D视觉团队创办!聚焦三维重建、Nerf、点云处理、视觉SLAM、激光SLAM、多传感器标定、多传感器融合、深度估计、摄影几何、求职交流等方向。扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

扫码添加小助理进群
【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1500人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、VLA、VLN、Diffusion Policy、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、各类学习路线等,涉及当前具身所有主流方向。
扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;


















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









