






作者 | 大壮 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/28803001646
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『端到端自动驾驶』技术交流群
本文只做学术分享,如有侵权,联系删文
1. 从原始传感器数据到控制策略的端到端方法

端到端自动驾驶基本流程:
(1)子任务模型被更大规模的神经网络模型取代,最终即为端到端神经网络模型;
(2)由数据驱动的方式来解决长尾问题,取代rule-based的结构。
优点:
(1)直接输出控车指令,避免信息损失;
(2)具备零样本学习能力,更好解决OOD问题;
(3)数据驱动方式解决自动驾驶长尾问题;
(4)避免上下游模块误差的过度传导;
(5)模型集成统一,提升计算效率。
2. 完全端到端是怎么做的

评估指标
开环指标:

(2)碰撞率
闭环仿真:
(1)路线完成率(RC)路线完成的百分比
(2)违规分数(IS)衡量触发的违规行为
(3)驾驶分数(DS)表示驾驶进度和安全性
3. UniAD算法详解
3.1 算法动机

(1)跨模块信息丢失、错误积累和特征misalignment;
(2)负向传输;
(3)安全保障和可解释性方面;
(4)考虑模块较少。
3.2 开创性思路
(1)第一项全面研究自动驾驶领域包括感知、预测和规划在内的多种任务的联合合作的工作;
(2)以查询方式链接各模块的灵活设计;
(3)一种以决策为导向的端到端框架。
3.3 主体结构

特征提取,特征转换,感知模块(目标检测+多目标跟踪+建图部分,TrackFormer、MapFormer),预测模块(MotionFormer、OccFormer),规划模块(指令导航、Occ矫正轨迹)。
全景分割:对前景进行实例分割,对背景进行语义分割。
前景 thing queries --> 车道、边界和人行横道
背景 stuff queries --> 可行驶区域
3.4 损失函数
每个模块都有一个损失函数,第一阶段去训练Perception模块, ;第二阶段冻结Perception模块,去训练Perception和Prediction和Planning所有模块, 。
3.5 性能对比
消融实验证明各个模块都是不可或缺的,然后再去对比单个模块的性能。各个模块的对比这里不再展开。


4. VAD算法详解
跟UniAD一样,也是一个纯视觉方案
4.1 算法动机&开创性思路

(1)栅格化表示计算量大,并且缺少关键的实例级结构信息;
(2)矢量化表示,计算方面效率高。
4.2 主体结构

包括特征提取、特征转换、矢量化场景学习、规划模块;
4.3 损失函数
自车的预测轨迹和gt之间是一个模仿学习的过程,所以添加了一个模仿学习的loss, ,即轨迹与gt之间的回归误差。

总的loss的话,还需要加上地图重建的loss和每个agent运动预测的loss(位置预测、类别分类、多模态轨迹的预测和得分),当前自车轨迹与其他agent避免碰撞的loss,自车避免撞到边界的loss,自车与车道的方向一致的loss。
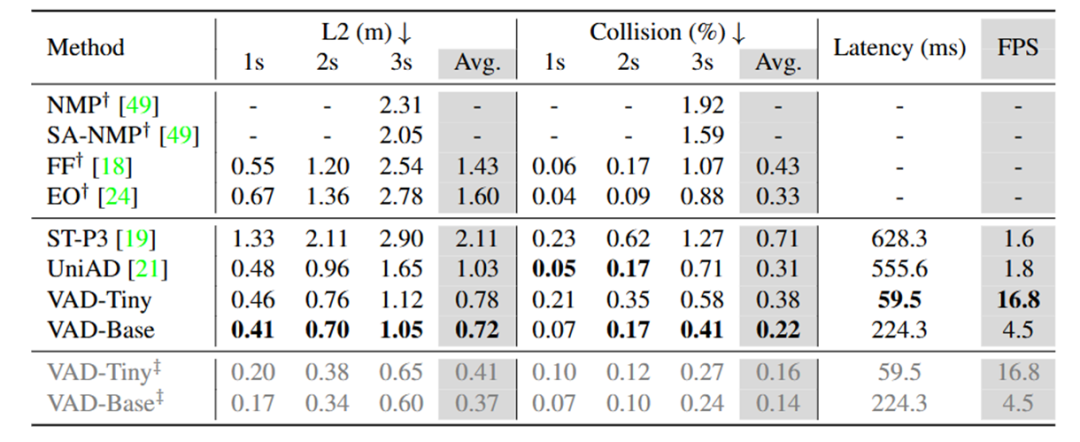
4.4 性能对比



4.5 VADv2优化了什么

自车在某个场景下可能有多个表现,但是模型训练出来,可能学到了一个中间轨迹,会导致与其他agent发生碰撞。

所以,(1)提出,在训练集中的这些轨迹应该赋予一个权重,以什么样的概率去学习,所以在训练集中计算轨迹概率分布去约束训练的情况;
(2)同时将训练集中的轨迹进行了最远点采样,作为轨迹词典,将其作为token给到transformer,从而提升规划模块的效果。
5. UAD算法详解
没有模块化和人工标注的

5.1 算法动机
(1)现存方法的标注和计算开销过大,所以本篇没有人工标注的需求
(2)感知模块的标注不是提升规划性能的关键,扩大数据量才是关键。只对数据量扩大但不增加标注成本。
5.2 开创性思路
(1)无监督代理任务
(2)自监督方向感知策略
5.3 主体结构

5.3.1 无监督的代理任务Angular Perception Pretext

输入是一个环视的图像,通过GroundingDINO(开集检测器,在训练集中10个类别的数据,但是验证集中有多出来的其他类别也要要求能检测出来),然后得到BEV特征,经过Dreaming Decoder得到预测结果与刚才说获取的标签去计算一个loss(二分类交叉loss)

用于对物体预测的Dreaming decoder的整体结构是:初始化K个角度的Query,BEV特征被分成了K个区域跟Query一一对应,经过GRU模块(用t-1时刻的Query和当前时刻t的特征F去计算当前时刻t的Query),用t时刻的特征和t时刻的Query做一个CrossAttention得到下一时刻的特征。即自回归的一种方式。Query之间对平均值和方差进行一个DreamingLoss,让其分布尽量相似。
5.3.2 利用方向感知的规划模块Direction Aware Planning
包含三个部分

(1)PlanningHead规划头(通过模仿学习来计算未来轨迹,对BEV特征进行旋转,过规划头得到响应的预测轨迹,然后GT也要旋转,两者得到一个模仿学习的loss。)
(2)Directional Augmentation方向增强(先对轨迹沿着车辆行驶方向划分为直行、左转、右转,然后通过这个预测头做一个三分类)

(3)Directional Consistency方向一致性(旋转后的特征得到的轨迹再旋转回去之后,跟之前的对比得到loss。)
5.4 损失函数
: 预测哪个扇形区域中是有物体的,对周围环境下障碍物信息的感知,二分类的交叉熵损失
: 对前后两帧之间的Query的分布做KL散度的Loss
: 模仿学习的loss
: 对控车信号的分类头(直行、左右转)的loss
: 方向一致性loss
5.5 性能对比




6. SparseDrive算法详解

6.1 算法动机
认为传统方法中BEV特征计算成本高
忽略了自车对周围代理的影响
场景信息是在agent周围提取,忽略了自车
运动预测和规划都是多模态问题,应该输出多种轨迹
6.2 开创性思路
探索了端到端自动驾驶的稀疏场景表示,并提出了一种以稀疏为中心的范式
修改了运动预测和规划之间的巨大相似性,提出了一种分层规划选择策略
6.3 主体结构

输入环视的6幅图像,输出是其他agent的预测和规划结果。
中途处理过程包括:特征提取、对称稀疏感知、平行运动规划三大模块。
在对称稀疏感知模块中,主要包含:稀疏检测、稀疏跟踪、稀疏在线建图任务,我们来具体看一下。

在平行运动规划器模块中:作者认为其他agent的轨迹预测和自车的轨迹预测应该是一个任务,并且是互相影响的。

6.4 损失函数
loss函数有:检测阶段的、map检测的、其他agent未来轨迹的、自车规划的、深度的loss
训练阶段分为两部分:stage1是从头开始训练对称稀疏感知模块,以学习稀疏场景表示;stage2是稀疏感知模块和并行运动规划器一起训练。
6.5 性能对比


7. ReasonNet算法详解
这是一个时序+多模态的方案,这篇论文对一些特殊的场景进行了考虑。
如图中,黄车视角中的红车被蓝车挡住,能否通过蓝车的行为来判断有红车的可能性。
7.1 算法动机
应该对驾驶场景的未来发展做出高保真的预测;
处理长尾分布中罕见不利事件,遮挡区域中未被发现但相关的物体。
7.2 开创性思路
提出一种新型的时间和全局推理网络,增加历史的场景推理,提高全局情景的感知性能;
提出一种新基准,由城市驾驶中各种遮挡场景所组成,用于系统性地评估遮挡事件。
7.3 主体结构
这篇文章是多模态的,所以其输入是图像输入和雷达点云的输入所组成的,输出是waypoints。
主体结构分为三个模块:
(1)感知模块,从Lidar和RGB数据中提取BEV特征;
(2)时间推理模块,处理时间信息并维护存储历史特征的存储库;
S用于计算存在Memory Bank中的历史特征和当前特征的相似度
(3)全局推理模块,捕获物体与环境之间的交互关系,以检测不利事件(如遮挡)并提高感知性能。
交互建模 ➡ 图注意网络(GAT)➡ 占据解码 ➡ 一致性损失
7.4 损失函数
首先是Preception模块,包括:Waypoints的回归loss,Traffic sign的分类loss,BEV Map分类+回归的loss;
二阶段有:一致性的loss,Traffic sign的loss,BEV Map的loss,占用图的loss。
7.5 性能对比
基于本文提出的新的benchmark叫做DOS benchmark:四种场景分别包含25种不同的情况,包括车辆和行人的遮挡,有间歇性遮挡和持续遮挡但有交互线索。


8. FusionAD算法详解
这是一篇多模态的方案,是在UniAD的基础上加入了点云数据,改造成了多模态的方案。
8.1 算法动机
(1)传统的模块化方法没办法支持梯度反传,会造成信息的丢失。
(2)UniAD只支持图像输入,不支持激光雷达信息。
8.2 开创性思路
(1)第一个统一的基于BEV多模态、多任务的端到端学习框架,重点关注自动驾驶的预测和规划任务;
(2)探索融合特征增强预测和规划任务,提出一个融合辅助模态感知预测和状态感知规划模块,称为FMSPnP。
8.3 主体结构
特征融合模块
预测模块
【名词解释】Anchor:在目标检测任务中,Anchor 是一种重要的概念,它指的是一组预定义的矩形框,这些框具有不同的尺寸、长宽比,用于在图像中表示潜在的目标对象。Anchor 的设计对于目标检测模型的性能至关重要,因为它们作为候选区域帮助模型更准确地定位和识别目标。
【名词解释】embed:通常指的是嵌入(embedding),它是一种将高维数据(如图像、文本或声音)转换为低维密集向量表示的方法。这些向量表示捕捉了数据的重要特征,通常用于机器学习模型的输入。例如,在自然语言处理中,单词或短语会被转换为词嵌入(word embeddings),这些嵌入能够捕捉单词的语义信息。在计算机视觉中,图像可以被转换为像素嵌入(pixel embeddings),这些嵌入包含了图像的视觉特征。
【名词解释】MLP:多层感知器(MLP,Multilayer Perceptron)是一种前馈人工神经网络模型,由多个神经元层组成,通常包括一个输入层、多个隐藏层和一个输出层。每个神经元会对输入数据进行加权求和,然后通过一个激活函数来引入非线性,使得 MLP 能够学习和模拟复杂的数据关系。
规划模块
新增一个自车信息的输入。
8.4 损失函数
与UniAD相比,将碰撞的loss进行了一个修改,在UniAD中的Lcol是预测的自车轨迹与其他agent的iou,这里的话,换成了预测的轨迹与其他车辆的轨迹沿中心点画一个圆,计算中心点的距离,以此来计算loss。
训练的时候,比UniAD多了一个阶段,stage1:BEV+感知;əstage2:冻结BEV+感知+预测+规划;əstage3:占用+规划+冻结其他部分。
8.5 性能对比
加入激光数据之后的性能比UniAD没加入激光的表现好。

9. Hydra-MDP算法详解
CVPR2024端到端自动驾驶挑战赛冠军+多模态方案,具备多个目标的多头蒸馏。
9.1 算法动机
比赛背景:(1)开环下的端到端驾驶有着各种问题;(2)nuScenes数据并非为规划设计,没有考虑到规划的一些场景;(3)NAVSIM对自车进行模拟,指标的计算考虑与其他车辆、道路的位置关系。
(1)轨迹回放带来的监督有限;
(2)推理时加不可微分的后处理。
我们先来对比下目前三种主流的方式:
第一种范式,我们之前讲的UAD、VAD都是这种范式,规划模块预测一个单模的规划输出;同时用于监督的也是一个单目标。具体来讲就是预测一条规划轨迹,并且这条规划轨迹的gt是由人驾的多个时刻的轨迹点来组成,大部分是用L2loss这种情况。
第二种范式,预测的轨迹是多模态的轨迹,监督它的目标是单一的目标,这个类似VADv2和SparseDrive这种方法,这种方法一般去监督与gt轨迹最近的一条轨迹。问题是这种轨迹是轨迹回放出来的,而不是车辆此时此刻走出来的轨迹,同一场景下,司机开的轨迹不一定是唯一和最优的,也就是说可能有好几条最优轨迹,但是如果只有一条司机开出来的轨迹作为gt进行轨迹的回归监督,监督是有限的,是弱监督。体现出了监督的有限性,而且没考虑到监督的安全、交通规则、舒适、效率。而且这个后处理模块,由于在后推理时用了感知模块的输入,当感知模块有问题的时候,信息传递就会出现误差累积,这个后处理模块本身是不可微分的,所以会造成信息的损失。
本文作者提出的新的范式,就是规划模块是多模的输出,同时,目标也是多样性的,即不仅是GT的轨迹也同时引入了更多的正样本,由不同的专家给出的。此外,将后处理的模块变成了可微分的用于训练的神经网络的模块,从而消除了第二种范式中由于不可微分而带来的信息损失的情况。
9.2 开创性思路
(1)引入了更多的正样本,由不同专家给出;
(2)感知真值引入规划模块用于训练。
9.3 主体结构

第一部分是感知的信息处理融合和提取,第二个模块是用前面得到的特征去解码出轨迹,最后一个模块是多目标学习范式部分。
感知模块用的Transfuser的baseline
轨迹解码器:计算不同的预测轨迹与GT轨迹的距离,这里用的是L2,用这个距离做softmax,然后去产生不同轨迹的得分情况,从而去监督得分。
多目标多头蒸馏模块:我们看到轨迹模仿学习之后的轨迹还过了其他的MLP,这就是其他头,它的目标也是不一样的,第一个是跟碰撞相关的,第二个是跟行驶区域相关的,第三个是跟舒适度相关的,也就是说不同的评判指标都有一个teacher,之前的模仿学习就是人类的teacher,那么这些teacher是怎么来的呢?怎么通过这些teacher来蒸馏的呢?我们看下作者是怎么去做的,首先我们得到规划词表Planning Vocabulary之后,对规划词表进行了一个模拟(用感知模块的GT进行训练的),有了这两个之后,我们就能算出来这些评估指标,从而计算每条轨迹的得分。总结一下就是对整个训练数据集的规划词汇进行离线模拟,在训练过程中引入每条轨迹的模拟分数的监督。

9.4 损失函数
训练阶段:感知损失+模仿学习损失+蒸馏损失;
推理阶段:由于模型不能完美拟合每一个独立的Teacher,不同的轨迹被分配不同的权重来计算最后的分数。
9.5 性能对比
其中,PDM-Closed的方法是2023年规划挑战赛的方案,用的是感知模块的输出结果作为输入去产生规划的路线,同时也加入了很多规则的手段。输入是感知模块的GT。
NC代表碰撞相关,DAC代表可行驶区域,EP衡量自车沿轨迹前进的距离,TTC代表碰撞时间,C代表舒适度相关,Score是利用这几个指标计算综合得到的评价结果。
可以看到,词表数量增加后,效果更好;只学整个PDM-Score不如单独分开几个teacher去学习更好;引入新的学习指标后,新指标对应的这栏表现会更好。

使用更大的backbone(骨干网络)会产生更好的规划性能;增大图像分辨率也可以提升性能。

自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









