



点击下方卡片,关注“具身智能之心”公众号
作者 | 具身智能之心 编辑 | 具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
一、写在前面
尽管近年来在多样化的机器人数据集上预训练的Vision-Language-Action(VLA)模型在仅有少量域内数据的情况下展现出了一定的泛化能力,但它们往往都依赖紧凑的动作预测模块(用于输出离散或连续动作)的做法,限制了对异质动作空间的适应性。为此,我们提出了 Dita,这是一个可扩展的模型框架,它利用 Transformer 架构,通过统一的多模态扩散过程直接对连续动作序列进行去噪。与以往那种依靠小型网络对多模态融合的embedding进行去噪不同,Dita 利用上下文条件,使得去噪后的动作能够与历史观测中原始的视觉标记实现细粒度对齐,从而明确建模了细微的动作变化和环境差别。
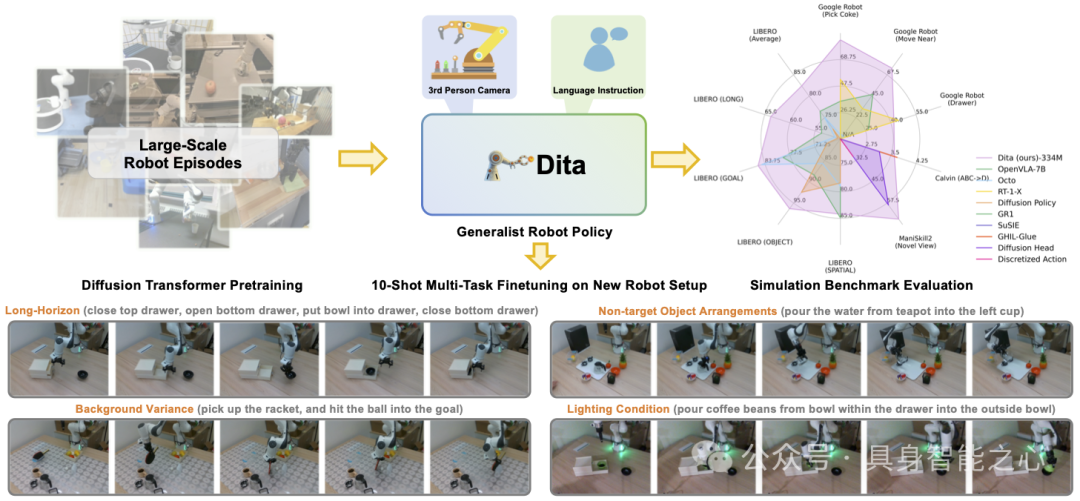
Dita通过Diffusion Transformer来进行动作去噪学习。通过这种方法,Dita 能够高效整合来自不同机器人平台、不同摄像机视角、观测场景、任务以及动作空间的数据集。这种协同效应不仅增强了模型对各种变化的鲁棒性,同时也促成了长程任务的成功执行。大量基准测试评估表明,在仿真环境中,Dita 可达到Sota或者相当水平的表现。值得注意的是,Dita 仅通过第三人称摄像头输入,并经 10-shot 微调后,就实现了对真实环境中环境变化和复杂长时程任务的稳健适应。此架构为通用机器人策略学习提供了一个多功能、轻量级且开源的基线。
项目主页:https://robodita.github.io/
视频展示:YouTube / Bilibili
二、领域介绍
传统的机器人学习范式通常依赖于为特定机器人和任务收集的大规模数据,但由于现实机器人硬件固有的局限性,采集用于通用任务的数据既费时又昂贵。目前,在自然语言处理和计算机视觉领域中,在大规模、丰富且与任务无关的数据集上预训练的基础模型,已经在零样本泛化任务和仅依赖极少的任务特定样本来解决下游任务方面展现出卓越的效能。这一现象说明:如果能够预训练一个基于异构机器人数据的通用机器人策略,并仅需极少监督进行微调,那么这将对实现真正泛化的VLA模型具有重要意义。然而,在涵盖多种传感器、动作空间、任务、摄像机视角和环境的广泛跨机体数据集上训练此类策略,依然是一个亟待解决的挑战。
在本文中,我们提出了 Dita,一种扩散Transformer策略 (DiT)。Dita充分利用了 Transformer 架构,从而确保了在大规模跨机体数据集上的可扩展性。它融合了上下文条件机制和因果 Transformer,能够自发对动作序列进行去噪,从而实现以图像标记直接作为条件的动作去噪,并赋予模型捕捉历史视觉观测中细微差别(例如动作细微变化)的能力。我们的目标是为通用机器人策略学习提供一个简洁、轻量(参数量为334M)且开源的基线模型。该模型结构简单但高效,在众多仿真基准测试中取得了最先进或具有竞争力的表现,并成功地泛化到新环境配置下的长时程任务——这些任务因背景、非目标物体排列以及光照条件的变化而呈现多样性,仅需利用 10-shot 的真实样本进行微调即可适应。值得一提的是,这一令人瞩目的性能完全依赖于单个第三人称摄像头输入,同时模型固有的灵活性也使得研究人员可以自由整合其他输入模态(例如腕部摄像头图像、目标图像预测、机器人状态、触觉反馈等)以供进一步研究。
三、方法与架构设计
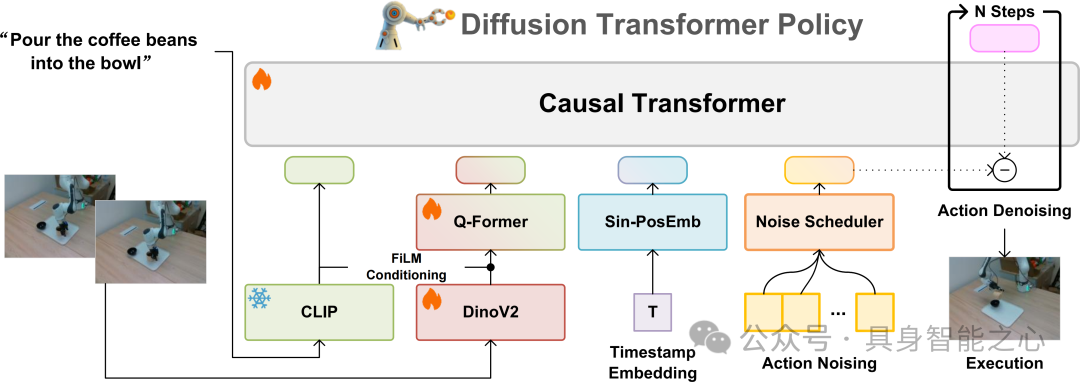
3.1 多模态输入与特征提取
语言输入:利用预训练且冻结的 CLIP 模型对自然语言指令进行编码。
图像输入:通过 DINOv2 模型提取图像特征。由于 DINOv2 训练数据与机器人数据存在差异,因此采用端到端的联合优化。同时引入 Q-Former 模块,结合 FiLM 条件化机制根据指令内容选择图像特征。
3.2 动作预处理与表示
将末端执行器的动作表示为7维向量(3维平移、3维旋转、1维夹爪状态)。
使用零填充使动作向量与图像和语言特征维度对齐。
在训练过程中,仅对7维动作向量加入噪声,通过扩散去噪优化模型。
3.3 Transformer架构的扩散模型
核心思想:利用Transformer架构的扩散模型对连续域上的动作序列进行去噪,而不是使用小型的去噪头网络或是单独对动作token进行去噪
核心思想:
上下文条件化:将语言、图像及时间戳嵌入与噪声化动作序列拼接,输入因果 Transformer 模型。
模型结构:采用类似 LLaMA 风格的结构,共 12 个自注意力层。模型总参数量334M,其中可训练参数约 221M。
训练目标:最小化噪声预测的均方误差(MSE),使模型学会从历史观察中恢复正确的动作变化(action delta)。
3.4 扩散过程与训练目标
训练时采用 DDPM 扩散目标,共加噪1000步。
推理时采用 DDIM 加速,仅需20步去噪即可获得准确动作预测。
每次去噪过程中,模型根据当前带噪动作和条件信息预测噪声向量,并按照预设噪声调度器更新动作,从而兼顾去噪效果与实时性。
3.5 数据集与预训练细节
采用Open X-Embodiment(OXE)跨平台数据集进行预训练,数据涵盖不同机器人平台、摄像头视角和任务场景。
通过动作归一化与过滤处理保证数据质量。
使用AdamW优化器,在32块NVIDIA A100 GPU上进行,总训练步数10万步,每块GPU的批大小为256。
四、仿真实验
Dita在多个仿真平台上进行了详细的性能评估,主要包括以下几个基准测试:
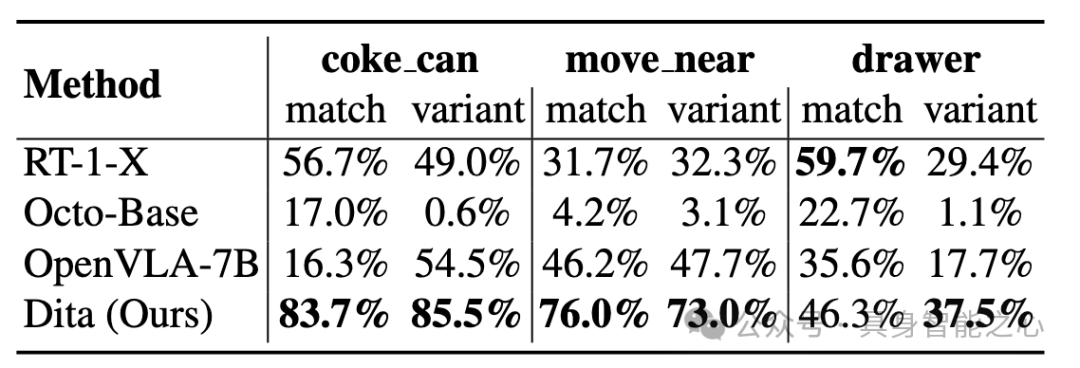
4.1 SimplerEnv
简介:Real-to-Sim 平台,用于测试模型在模拟环境中的零样本泛化能力。
实验任务:包括“拿起可乐罐”、“移动物体”、“开/关抽屉”等。
实验结果:Dita 在各项任务上均展现出高成功率,远超 RT-1-X、Octo-Base 与 OpenVLA 等方法,仅依靠第三人称图像输入便能捕捉背景、纹理、物体位置等多种变异情形,实现鲁棒控制。
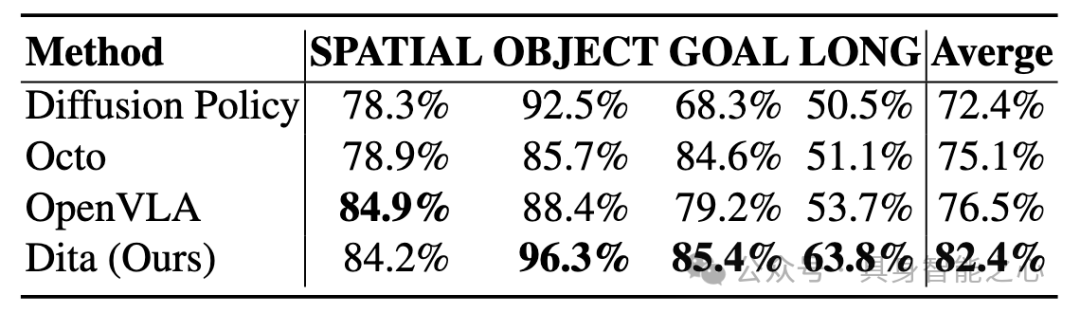
4.2 LIBERO
数据集构成:包含 LIBERO-SPATIAL、LIBERO-OBJECT、LIBERO-GOAL 以及长时程任务数据集 LIBERO-LONG。
实验结果:Dita 在大部分指标上领先于基线方法,特别是在长时程任务上提升明显,显示出较强的长时程规划与动作生成能力。
4.3 CALVIN
简介:主要考察机器人在长时程、语言条件任务下的表现,包含多个场景与复杂任务序列。
输入条件:仅使用单一静态 RGB 图像输入进行动作预测。
实验结果:Dita 不仅能完成长序列任务,其平均成功序列长度与其他方法相当甚至更优,证明了对长时程任务的有效建模能力。
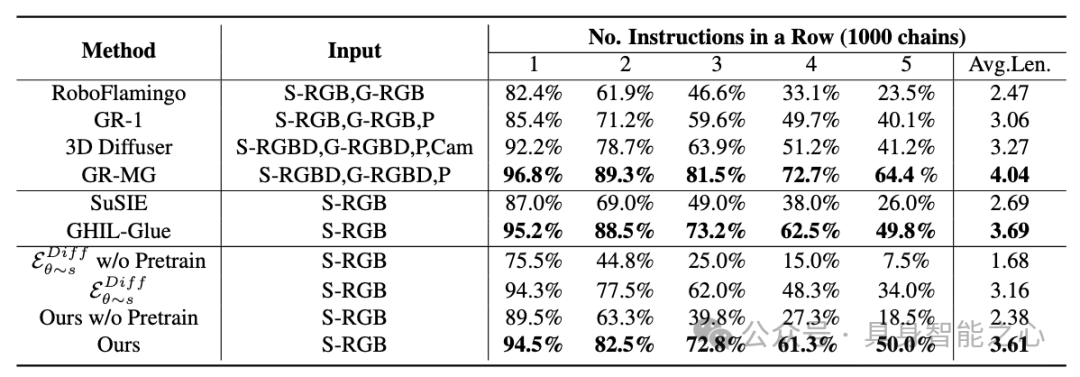
4.4 ManiSkill2
简介:用于评估机器人操作泛化能力的重要平台,涵盖多个任务家庭和上百万帧演示数据。
测试设置:构建新型摄像头视角泛化基准,随机采样不同视角生成大量轨迹数据。
实验结果:在 PickCube、StackCube、PickSingleYCB、PickClutterYCB 等任务上,Dita 的成功率明显优于使用离散化或传统扩散头方法的基线模型,证明了其在大规模、多样化数据下的优越性能。
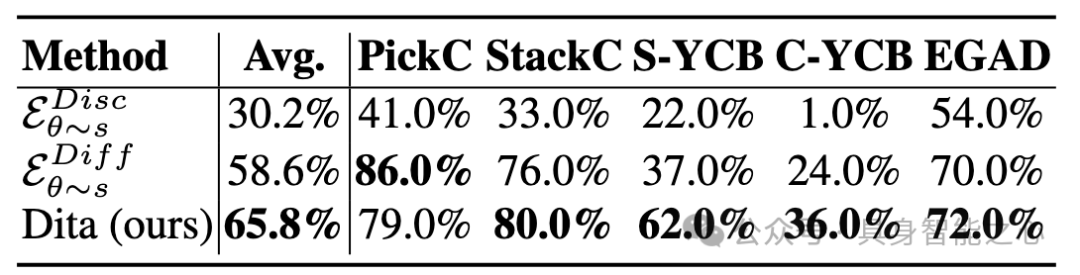
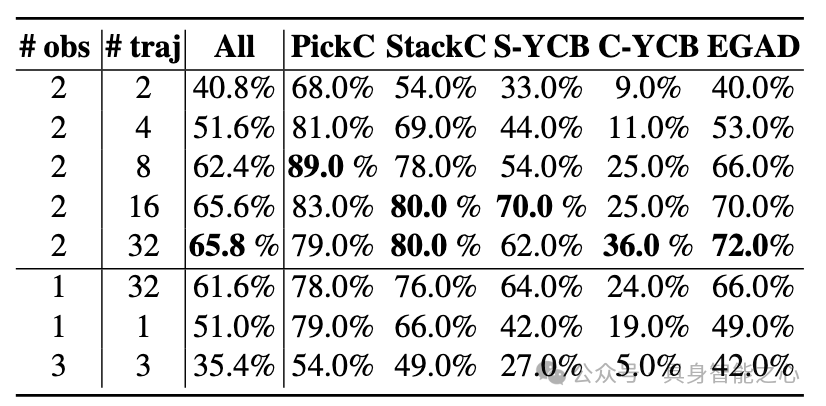
4.5 消融实验
历史观察帧数:使用两帧观察数据能平衡信息量与模型收敛问题,过多帧数会增加计算难度。
轨迹长度:增加轨迹长度有助于更好地预测未来状态,对复杂任务尤为重要。
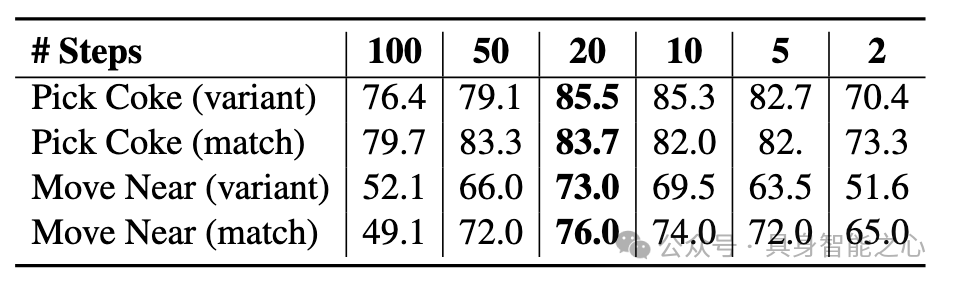
去噪步数:采用 DDIM 时,减少去噪步数(例如 10 步)不会显著影响性能,反而有助于降低过拟合风险并提高推理速度。
五、真实机器人实验
为了验证 Dita 在真实机器人场景下的泛化与适应能力,我们在实际机器人平台上进行了 10-shot 微调实验。真实机器人场景如下图所示,机械臂采用一个7-DOF的Franka Emika Panda机械臂并配以一个Robotiq 2F-85夹爪。RealSense D435i RGB-D摄像头在距离机械臂约1.5米处,以第三人称视角在每一次推理时捕捉场景的实时RGB图像。模型部署在装有NVIDIA A100 80G GPU的远端服务器上,每次推理后与运行ROS的台式计算机通信,并由此计算机进行机械臂控制。该系统以3Hz的控制频率运行。

5.1 任务设置
实际机器人实验设计了多个复杂任务,包括:
抓取与放置任务:如将香蕉或猕猴桃从桌面抓起并放入盒中(分两步执行)。
倾倒任务:如“将咖啡豆倒入碗中”或“将水从茶壶倒入杯中”,需精确控制旋转与倾斜动作。
堆叠任务:如堆叠三个碗或俄罗斯套娃,要求模型处理长时程连续操作。
拉推任务:如开关抽屉,考察连续拉推动作的预测能力。
超长程任务:如“打开上方的抽屉、拿物体放入下方的抽屉再关上下方的抽屉”,对模型规划能力和连续动作生成提出更高要求。
5.2 微调与优化
微调策略:利用仅 10 个样本进行快速微调,采用 LoRA 方案对可训练参数(约 11M,占总可训练参数的 5%)进行调整,同时辅以图像数据增强。
实验结果:在两步任务上,Dita 的整体成功率达到 63.8%,在长程任务中表现明显优于基线方法(如 Octo 和 OpenVLA)。模型不仅能准确完成抓取与插入操作,还能应对不同背景、物体摆放和光照条件下的环境变化,展现出极高的鲁棒性。
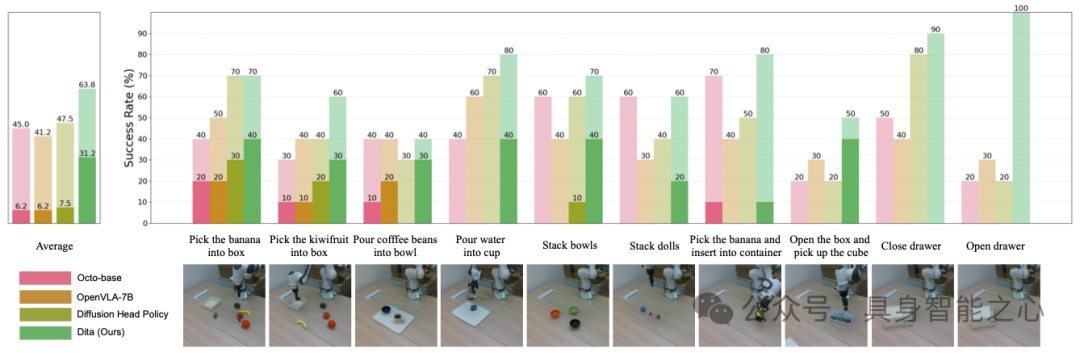
5.3 定性比较
对比实验视频与现场演示显示,其他基线方法往往在操作过程中出现位置偏差或理解错误(如抓取位置不准确、动作中途卡壳)。
Dita 能更准确捕捉手眼协调的细微差异,完成复杂 3D 旋转及多步操作任务,展示出明显的优势。

六、结论与展望
Dita 提出了一种全新的通用机器人策略架构,利用 Transformer 扩散模型和上下文条件化方法,有效解决了多模态输入条件下机械臂的连续动作生成的问题。其主要优势体现在以下几个方面:
模型设计简单高效
仅需单一第三人称摄像头输入,通过联合多模态特征提取与扩散去噪,模型结构紧凑(334M 参数)且易于扩展。强大的泛化能力
利用跨平台、跨任务的大规模数据(OXE 数据集)进行预训练,模型在 SimplerEnv、LIBERO、CALVIN、ManiSkill2 等仿真平台上均取得领先表现;通过 10-shot 微调,在真实机器人实验中展现出优异的适应能力。对长程任务的优秀建模
采用扩散模型直接对连续动作序列进行去噪,能够捕捉动作变化的细微差异,在多步骤、复杂操作任务上明显优于传统方法。鲁棒性与扩展性
大量消融实验表明,模型对输入观测长度、轨迹长度及去噪步数等关键参数具有良好的鲁棒性。架构设计允许方便地融合更多传感器输入(如腕部摄像头、机器人状态、触觉反馈等),为未来研究提供了较大灵活性。
总的来说,Dita 为通用机器人策略学习提供了一个干净、轻量且开源的基线模型,其优异的少样本适应能力与长程任务处理能力预示着未来在机器人控制、视觉语言交互等方向上具有广阔的应用前景。该方法不仅在仿真环境中取得显著进展,也在实际机器人平台上通过 10-shot 微调成功转移到复杂任务场景,展现了跨域泛化能力。未来,随着模型规模的进一步扩大和多模态输入的丰富,Dita 有望为构建更加通用、灵活的机器人控制系统奠定坚实基础。

【具身智能之心】技术交流群
具身智能之心是国内首个面向具身智能领域的开发者社区,聚焦大模型、视觉语言导航、VLA、机械臂抓取、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、机器人仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1000人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、大模型、视觉语言模型、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、强化学习全栈学习路线、具身智能感知学习路线、具身智能交互学习路线、视觉语言导航学习路线、触觉感知学习路线、多模态大模型学理解学习路线、多模态大模型学生成学习路线、大模型与机器人应用、机械臂抓取位姿估计学习路线、机械臂的策略学习路线、双足与四足机器人开源方案、具身智能与大模型部署等方向,涉及当前具身所有主流方向。
扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;


















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









